当前位置:网站首页>再有人问你数据库缓存一致性的问题,直接把这篇文章发给他
再有人问你数据库缓存一致性的问题,直接把这篇文章发给他
2022-07-06 09:07:00 【卡卡的Java架构笔记】
在之前的一篇文章《为什么会出现数据库和缓存不一致的问题》中,我们介绍过缓存和数据库会出现数据不一致的几种情况。
我们提到过,在数据库和缓存的操作过程中,可能存在”先写数据库,后删缓存”、”先写数据库,后更新缓存”、”先删缓存库,后写数据库”以及”先更新缓存库,后写数据库”这四种。
那么,到底是应该删除缓存好呢,还是更新缓存好呢?到底应该先操作数据库呢还是先操作缓存呢?哪种方案更好呢?又该如何选择呢?
本文就来展开分析一下。
删除还是更新
为了保证数据库和缓存里面的数据是一致的,很多人会很多人在做数据更新的时候,会同时更新缓存里面的内容。但是我其实告诉大家,应该优先选择删除缓存而不是更新缓存。
首先,我们暂时抛开数据一致性的问题,单独来看看更新缓存和删除缓存的复杂的的问题。
我们放到缓存中的数据,很多时候可能不只是简单的一个字符串类型的值,他还可能是一个大的JSON串,一个map类型等等。
举个栗子,我们需要通过缓存进行扣减库存的时候,你可能需要从缓存中查出整个订单模型数据,把他进行反序列化之后,再解析出其中的库存字段,把他修改掉,然后再序列化,最后再更新到缓存中。
可以看到,更新缓存的动作,相比于直接删除缓存,操作过程比较的复杂,而且也容易出错。
还有就是,在数据库和缓存的一致性保证方面,删除缓存相比更新缓存要更简单一点。
我们在《为什么会出现数据库和缓存不一致的问题》中介绍过的"写写并发"的场景中,如果同时更新缓存和数据库,那么很容易会出现因为并发的问题导致数据不一致的情况。如:
先写数据库,再更新缓存

先更新缓存,后写数据库:
但是,如果是做缓存的删除的话,在写写并发的情况下,缓存中的数据都是要被清除的,所以就不会出现数据不一致的问题。
但是,更新缓存相比删除缓存还是有一个小的缺点,那就是带来的一次额外的cache miss,也就是说在删除缓存后的下一次查询会无法命中缓存,要查询一下数据库。
这种cache miss在某种程度上可能会导致缓存击穿,也就是刚好缓存被删除之后,同一个Key有大量的请求过来,导致缓存被击穿,大量请求访问到数据库。
但是,通过加锁的方式是可以比较方便的解决缓存击穿的问题的。
总之,删除缓存相比较更新缓存,方案更加简单,而且带来的一致性问题也更少。所以,在删除和更新缓存之间,我还是偏向于建议大家优先选择删除缓存。
删除还是更新
在确定了优先选择删除缓存而不是更新缓存之后,留给我们的数据库+缓存更新的可选方案就剩下:"先写数据库后删除缓存"和"先删除缓存后写数据库了"。
那么,这两种方式各自有什么优缺点呢?该如何选择呢?
先写数据库
因为数据库和缓存的操作是两步的,没办法做到保证原子性,所以就有可能第一步成功而第二步失败。
而一般情况下,如果把缓存的删除动作放到第二步,有一个好处,那就是缓存删除失败的概率还是比较低的,除非是网络问题或者缓存服务器宕机的问题,否则大部分情况都是可以成功的。
还有就是,先写数据库后删除缓存虽然不存在"写写并发"导致的数据一致性问题,但是会存在"读写并发"情况下的数据一致性问题。
我们知道,当我们使用了缓存之后,一个读的线程在查询数据的过程是这样的:
1、查询缓存,如果缓存中有值,则直接返回
2、查询数据库
3、把数据库的查询结果更新到缓存中
所以,对于一个读线程来说,虽然不会写数据库,但是是会更新缓存的,所以,在一些特殊的并发场景中,就会导致数据不一致的情况。
读写并发的时序如下:
也就是说,假如一个读线程,在读缓存的时候没查到值,他就会去数据库中查询,但是如果自查询到结果之后,更新缓存之前,数据库被更新了,但是这个读线程是完全不知道的,那么就导致最终缓存会被重新用一个"旧值"覆盖掉。
这也就导致了缓存和数据库的不一致的现象。
但是这种现象其实发生的概率比较低,因为一般一个读操作是很快的,数据库+缓存的读操作基本在十几毫秒左右就可以完成了。
而在这期间,更好另一个线程执行了一个比较耗时的写操作的概率确实比较低。
先删缓存
那么,如果是先删除缓存后操作数据库的话,会不会方案更完美一点呢?
首先,如果是选择先删除缓存后写数据库的这种方案,那么第二步的失败是可以接受的,因为这样不会有脏数据,也没什么影响,只需要重试就好了。
但是,先删除缓存后写数据库的这种方式,会无形中放大前面我们提到的"读写并发"导致的数据不一致的问题。
因为这种"读写并发"问题发生的前提是读线程读缓存没读到值,而先删缓存的动作一旦发生,刚好可以让读线程就从缓存中读不到值。
所以,本来一个小概率会发生的"读写并发"问题,在先删缓存的过程中,问题发生的概率会被放大。
而且这种问题的后果也比较严重,那就是缓存中的值一直是错的,就会导致后续的所以命中缓存的查询结果都是错的!
延迟双删
那么,虽然先写数据后删除缓存的这种情况,可以大大的降低并发问题的概率,但是,根据墨菲定律,只要有可能发生的坏事,那就基本上会发生。越是庞大的系统发生的概率越高。
那么,有没有什么办法可以来解决一下这种情况带来的不一致的问题呢?
其实是有一个比较常见的方案的,在很多公司内用的也比较多,那就是延迟双删。
因为"读写并发"的问题会导致并发发生后,缓存中的数被读线程写进去脏数据,那么就只需要在写线程在写数据库、删缓存之后,延迟一段时间,在执行一把删除动作就行了。
这样就能保证缓存中的脏数据被清理掉,避免后续的读操作都读到脏数据。当然,这个延迟的时长也很讲究,到底多久来删除呢?一般建议设置1-2s就可以了。
当然,这种方案也是有一个弊端的,那就是可能会导致缓存中准确的数据被删除掉。当然这也问题不大,就像我们前面说过的,只是增加一次cache miss罢了
如何选择
前面介绍了几种情况的具体问题和解决方案,那么实际工作中应该如何选择呢?
我觉得主要还是根据实际的业务情况来分析。
比如,如果业务量不大,并发不高的情况,可以选择先删除缓存,后更新数据库的方式,因为这种方案更加简单。
但是,如果是业务量比较大,并发度很高的话,那么建议选择先更新数据库,后删除缓存的方式,因为这种方式并发问题更少一些。但是可能会引入加锁、延迟双删等更多机制,使得整个方案会更加复杂。
其实,先操作数据库,后操作缓存,是一种比较典型的设计模式——Cache Aside Pattern。
这种模式的主要方案就是先写数据库,后删缓存,而且缓存的删除是可以在旁路异步执行的。
这种模式的优点就是我们说的,他可以解决"写写并发"导致的数据不一致问题,并且可以大大降低"读写并发"的问题,所以这也是Facebook比较推崇的一种模式。
优化方案
Cache Aside Pattern 这种模式中,我们可以异步的在旁路处理缓存。其实这种方案在大厂中确实有的还蛮多的。
主要的方式就是借助数据库的binlog或者基于异步消息订阅的方式。
也就是说,在代码的主要逻辑中,先操作数据库就行了,然后数据库操作完,可以发一个异步消息出来。
然后再由一个监听者在接到消息之后,异步的把缓存中的数据删除掉。
或者干脆借助数据库的binlog,订阅到数据库变更之后,异步的清除缓存。
这两种方式都会有一定的延时,通常在毫秒级别,一般用于在可接受秒级延迟的业务场景中。
设计模式
前面介绍过了Cache Aside Pattern这种关于缓存操作的设计模式,那么其实还有几种其他的设计模式,也一起展开介绍一下:
Read/Write Through Pattern
在这两种模式中,应用程序将缓存作为主要的数据源,不需要感知数据库,更新数据库和从数据库的读取的任务都交给缓存来代理。
Read Through模式下,是由缓存配置一个读模块,它知道如何将数据库中的数据写入缓存。在数据被请求的时候,如果未命中,则将数据从数据库载入缓存。
Write Through模式下,缓存配置一个写模块,它知道如何将数据写入数据库。当应用要写入数据时,缓存会先存储数据,并调用写模块将数据写入数据库。
也就是说,这两种模式下,不需要应用自己去操作数据库,缓存自己就把活干完了。
Write Behind Caching Pattern
这种模式就是在更新数据的时候,只更新缓存,而不更新数据库,然后再异步的定时把缓存中的数据持久化到数据库中。
这种模式的优缺点比较明显,那就是读写速度都很快,但是会造成一定的数据丢失。
这种比较适合用在比如统计文章的访问量、点赞等场景中,允许数据少量丢失,但是速度要快。
没有银弹
《人月神话》的作者Fred Brooks在早年有一篇很著名文章《No Silver Bullet》 ,他提到:
在软件开发过程里是没有万能的终杀性武器的,只有各种方法综合运用,才是解决之道。而各种声称如何如何神奇的理论或方法,都不是能杀死“软件危机”这头人狼的银弹。
也就是说,没有哪种技术手段或者方案,是放之四海皆准的。如果有的话,我们这些工程师也就没有存在的必要了。
所以,任何的技术方案,都是一个权衡的过程,要权衡的问题有很多,业务的具体情况,实现的复杂度、实现的成本,团队成员的接受度、可维护性、容易理解的程度等等。
所以,没有一个"完美"的方案,只有"适合"的方案。
但是,如何能选出一个适合的方案,这里面就需要有很多的输入来做支撑了。希望本文的内容可以为你日后的决策提供一点参考!
边栏推荐
- 六月刷题02——字符串
- Write your own CPU Chapter 10 - learning notes
- CAPL脚本中关于相对路径/绝对路径操作的几个傻傻分不清的内置函数
- 五月刷题26——并查集
- Elk project monitoring platform deployment + deployment of detailed use (II)
- Nc29 search in two-dimensional array
- Summary of May training - from a Guang
- Tianmu MVC audit II
- 51单片机进修的一些感悟
- If a university wants to choose to study automation, what books can it read in advance?
猜你喜欢
If a university wants to choose to study automation, what books can it read in advance?

The 32-year-old fitness coach turned to a programmer and got an offer of 760000 a year. The experience of this older coder caused heated discussion
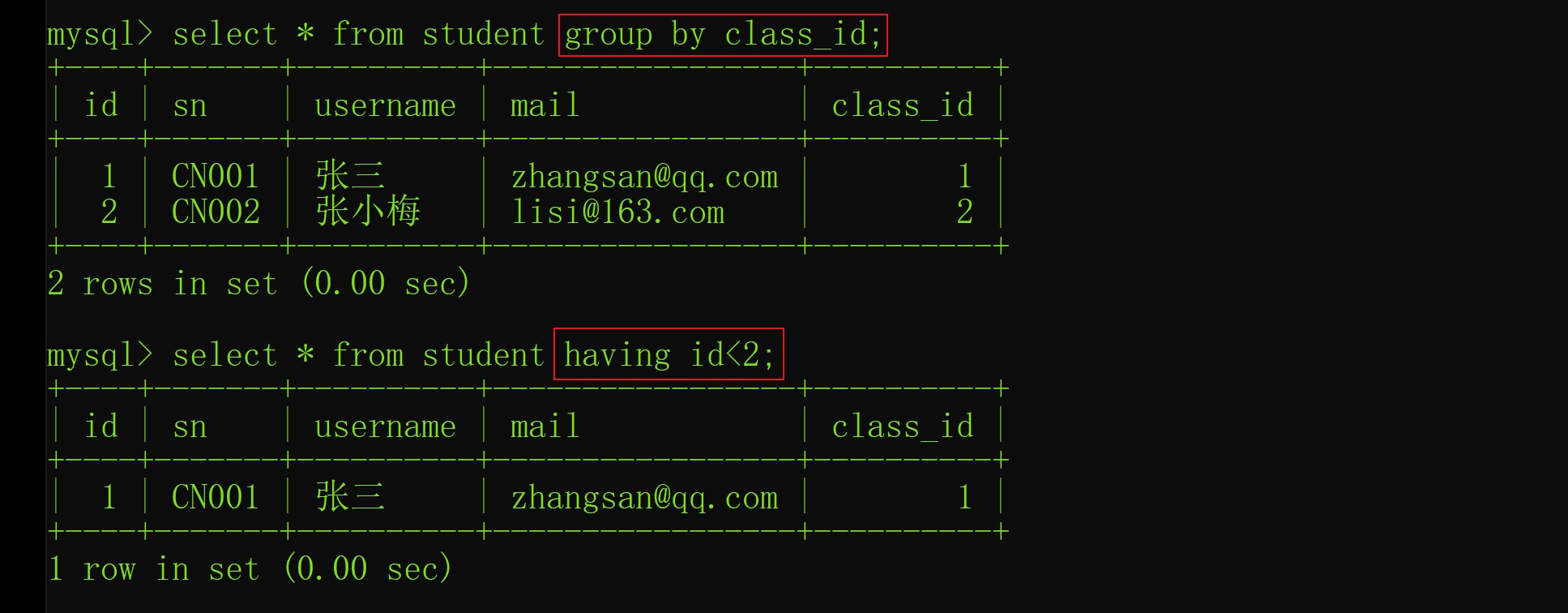
Interview shock 62: what are the precautions for group by?
华南技术栈CNN+Bilstm+Attention

嵌入式開發中的防禦性C語言編程
![[deep learning] semantic segmentation: paper reading: (2021-12) mask2former](/img/dd/fe2bfa3563cf478afe431ac87a8cb7.png)
[deep learning] semantic segmentation: paper reading: (2021-12) mask2former

一大波開源小抄來襲

MapReduce instance (VI): inverted index
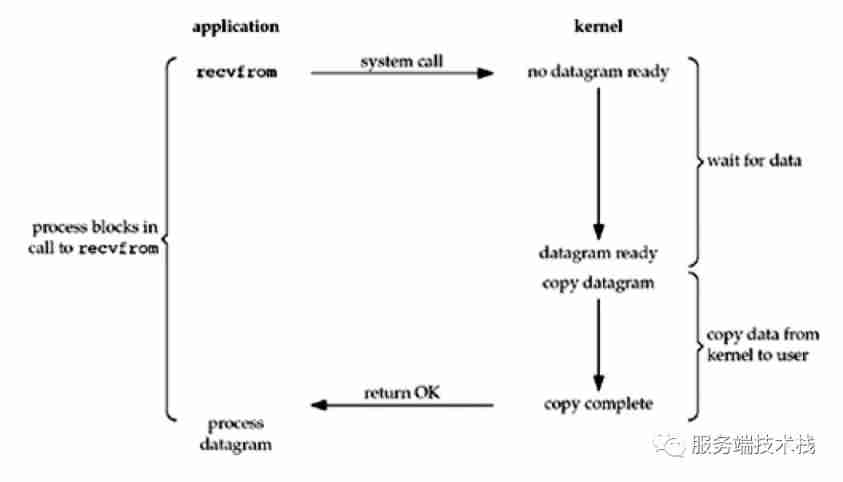
What you have to know about network IO model
Control the operation of the test module through the panel in canoe (primary)
随机推荐
068. Find the insertion position -- binary search
Learning SCM is of great help to society
Selection of software load balancing and hardware load balancing
Mexican SQL manual injection vulnerability test (mongodb database) problem solution
为什么大学单片机课上51+汇编,为什么不直接来STM32
五月刷题02——字符串
May brush question 01 - array
51单片机进修的一些感悟
Tianmu MVC audit I
零基础学习单片机切记这四点要求,少走弯路
在CANoe中通过Panel面板控制Test Module 运行(高级)
The replay block of canoe still needs to be combined with CAPL script to make it clear
六月刷题01——数组
A new understanding of RMAN retention policy recovery window
Can I learn PLC at the age of 33
Several ways of MySQL database optimization (pen interview must ask)
History of object recognition
嵌入式开发比单片机要难很多?谈谈单片机和嵌入式开发设计经历
What you have to know about network IO model
cmooc互联网+教育