当前位置:网站首页>Counter attack of noodles: redis asked 52 questions in a series, with detailed pictures and pictures. Now the interview is stable
Counter attack of noodles: redis asked 52 questions in a series, with detailed pictures and pictures. Now the interview is stable
2022-07-06 09:39:00 【Java domain】
Basics
1. Tell me what is Redis?

Redis It's based on key value pairs (key-value) Of NoSQL database .
More powerful than the general key value to the database ,Redis Medium value Support string( character string )、hash( Hash )、 list( list )、set( aggregate )、zset( Ordered set )、Bitmaps( Bitmap )、 HyperLogLog、GEO( Location of geographic information ) And other data structures , therefore Redis It can satisfy many application scenarios .
And because Redis Will store all data in memory , So its reading and writing performance is very excellent .
More Than This ,Redis The data in memory can also be saved to the hard disk in the form of snapshot and log , So in the event of a similar power failure or machine failure , Data in memory does not “ The loss of ”.
In addition to the above functions ,Redis Key expiration is also provided 、 Publish subscribe 、 Business 、 Assembly line 、Lua Additional functions such as scripts .
All in all ,Redis It is a powerful performance weapon .
2.Redis What can be used for ?

- cache
- This is a Redis Most widely used , Basically everything Web All apps will use it Redis As caching , To reduce data source pressure , Improve response time .
- Counter
Redis Natural support counting function , And the counting performance is very good , It can be used to record the number of views 、 Like and so on . - Ranking List
Redis Provides list and ordered set data structures , Reasonable use of these data structures can be very convenient to build a variety of ranking system . - Social networks
Fabulous / Step on 、 fans 、 Common friends / like 、 push 、 The drop-down refresh . - Message queue
Redis It provides publish subscribe function and blocking queue function , It can meet the general message queue function . - Distributed lock
Distributed environment , utilize Redis Implement distributed locks , It's also Redis Common applications .
Redis The application of is usually combined with the project to ask , Take the user service of an e-commerce project as an example :
- Token Storage : After the user logs in successfully , Use Redis Storage Token
- Login failure count : Use Redis Count , Login failed more than a certain number of times , Lock account
- Address cache : Cache provincial and urban data
- Distributed lock : Login in distributed environment 、 Registration and other operations plus distributed lock
- ……
3.Redis What are the data structures ?

Redis There are five basic data structures .
string
String is the most basic data structure . A value of type string can actually be a string ( Simple string 、 Complex string ( for example JSON、XML))、 Numbers ( Integers 、 Floating point numbers ), Even binary ( picture 、 Audio 、 video ), But the maximum value cannot exceed 512MB.
String mainly has the following typical usage scenarios :
- Caching function
- Count
- share Session
- The speed limit
hash
Hash type means that the key itself is a key value pair structure .
Hash mainly has the following typical application scenarios :
- Cache user information
- Cache object
list
list (list) Type is used to store multiple ordered strings . List is a more flexible data structure , It can act as a stack and a queue
The list mainly includes the following usage scenarios :
- Message queue
- The article lists
set
aggregate (set) Types are also used to hold multiple string elements , But it's not the same as the list type What it looks like is , Duplicate elements are not allowed in the collection , And the elements in the set are unordered .
The collection mainly includes the following usage scenarios :
- label (tag)
- Pay close attention to
sorted set
Elements in an ordered set can be ordered . But it's different from a list that uses index subscripts as sort criteria , It sets a weight for each element (score) Sort by .
The main application scenarios of ordered collection :
- User likes Statistics
- User sorting
4.Redis Why is it fast ?
Redis The speed of ⾮ Often fast , Standalone Redis Can ⽀ Support more than 100000 concurrent events per second , be relative to MySQL Come on , Performance is MySQL Of ⼏⼗ times . The main reasons for the speed are ⼏ spot :
- Completely based on memory operations
- send ⽤ Single thread , Avoid the consumption caused by thread switching and race state
- be based on ⾮ Obstructed IO Multiplex ⽤ Mechanism
- C language ⾔ Realization , Optimized data structure , be based on ⼏ A basic data structure ,redis Did ⼤ Quantity optimization , Extremely good performance ⾼
5. Can you tell me I/O Multiplexing ?
Quote Zhihu's last highly praised answer to explain what is I/O Multiplexing . Suppose you are a teacher , Give Way 30 Three students solve a problem , Then check if the students are doing it right , You have the following options :
- The first option : Check one by one in order , First check A, And then there was B, And then C、D... If a student gets stuck in the middle , The whole class will be delayed . This model is like , You do it one by one in a loop socket, No concurrency at all .
- The second option : You create 30 It's a split , Each doppelganger checks whether a student's answer is correct . This is similar to creating a process or... For each user - Thread processing connection .
- The third option , You stand on the platform and wait , The one who answers raises his hand . At this time C、D raise hands , That means they are finished with their questions , You go down and check in turn C、D The answer , Then go back to the podium and wait . here E、A Raise your hand again , And deal with it E and A.
The first is blocking IO Model , The third is I/O Reuse model .

Linux The system can be implemented in three ways IO Multiplexing :select、poll and epoll.
for example epoll The way is to put the user socket Corresponding fd Sign up for epoll, then epoll Help you monitor what socket There's a message on the phone , This avoids a lot of useless operations . At this time socket Non-blocking mode should be used .
such , The whole process is only going on select、poll、epoll These calls only block , Sending and receiving customer messages is not blocked , The entire process or thread is fully utilized , This is event driven , So-called reactor Pattern .
6. Redis Why did you choose single thread early ?
Official explanation :
https://redis.io/topics/faq

official FAQ Express , because Redis Is a memory based operation ,CPU Become Redis It's rare to see a bottleneck in the market ,Redis The most likely bottleneck is the size of memory or network constraints .
If you want to make the most of it CPU, You can start multiple computers on one machine Redis example .
PS: There is such an answer on the Internet , The official explanation of Tucao make complaints about it. , In fact, it is the historical reason , Developers hate multithreading , Later this CPU The problem of how to use it is left to the users .
meanwhile FAQ It's also mentioned in the book , Redis 4.0 Then it started to become multithreaded , Apart from the main route , It also has background threads dealing with slower operations , For example, cleaning up dirty data 、 The release of useless connections 、 Big Key And so on .
7.Redis6.0 What's going on with multithreading ?
Redis Don't you mean using single thread ? Yes? 6.0 Become multithreaded ?
Redis6.0 Multithreading is used to process data Read / write and protocol analysis , however Redis Carry out orders It's still single threaded .

Doing so ⽬ Because Redis The performance bottleneck is ⽹ Collateral IO⽽⾮CPU, send ⽤ Multithreading can improve IO The efficiency of reading and writing , from ⽽ As a whole ⾼Redis Performance of .
Persistence
8.Redis Persistence ⽅ What are the formulas ? What's the difference? ?
Redis Persistence ⽅ The case is divided into RDB and AOF Two kinds of .

RDB
RDB Persistence is to generate the current process data snapshot The process of saving to the hard disk , Trigger RDB The persistence process is divided into manual and automatic triggers .
RDB⽂ It's ⼀ A compressed ⼆ Base number ⽂ Pieces of , It can restore the state of the database at a certain time . because RDB⽂ The file is saved on the hard disk , So even Redis Collapse or exit , as long as RDB⽂ Pieces exist , Can ⽤ It restores the state of the restored database .
Manual trigger corresponds to save and bgsave command :

- save command : Block the current Redis The server , until RDB Until the process is complete , For instance with large memory, it will cause long-term blocking , Online environment is not recommended .
- bgsave command :Redis Process execution fork Action create subprocess ,RDB The persistence process is the responsibility of the subprocess , It will automatically end when it is finished . The blockage only happens in fork Stage , The average time is very short .
The following scenarios will automatically trigger RDB Persistence :
- Use save Related configuration , Such as “save m n”. Express m Data set exists in seconds n At the time of revision , Automatic triggering bgsave.
- If full replication is performed from a node , Automatic execution of master node bgsave Generate RDB File and send to slave
- perform debug reload Command reload Redis when , It will also trigger automatically save operation
- Execute by default shutdown On command , If it's not on AOF Persistence is performed automatically bgsave.
AOF
AOF(append only file) Persistence : Each write is logged as a separate log , Reexecute on reboot AOF The command in the file restores the data .AOF Its main function is to solve the real-time problem of data persistence , So far Redis The mainstream way of persistence .
AOF The workflow operation of : Command write (append)、 File synchronization (sync)、 File rewriting (rewrite)、 Restart loading (load)

The process is as follows :
1) All write commands are appended to aof_buf( buffer ) in .
2)AOF The buffer synchronizes the hard disk according to the corresponding policy .
3) With AOF The files are getting bigger , It needs to be done regularly AOF File rewriting , Compression reached Purpose .
4) When Redis When the server restarts , Can be loaded AOF File for data recovery .
9.RDB and AOF What are the advantages and disadvantages of each ?
RDB | advantage
- Only one compact binary dump.rdb, Great for backup 、 Full replication scenarios .
- Good disaster tolerance , You can put RDB The file is copied to a remote machine or file system , For disaster recovery .
- Fast recovery ,RDB Recovering data is much faster than AOF The way
RDB | shortcoming
- Low real time ,RDB It's persistence at intervals , There's no real-time persistence / Second persistence . If the event fails in this interval , Data will be lost .
- There are compatibility issues ,Redis There are multiple formats in the evolution process RDB edition , There is an old version Redis Cannot be compatible with the new version RDB The problem of .
AOF | advantage
- Good real-time ,aof Persistence can be configured appendfsync attribute , Yes always, Every command operation is recorded as aof Once in the file .
- adopt append Mode write file , Even if the server goes down , Can pass redis-check-aof Tools for data consistency .
AOF | shortcoming
- AOF File than RDB The file is big , And Slow recovery .
- Data aggregation When , Than RDB Low starting efficiency .
10.RDB and AOF How to choose ?
- Generally speaking , If you want to achieve something comparable to the database Data security , should Use two persistence functions at the same time . under these circumstances , When Redis It will be loaded prior to restart AOF File to restore the original data , Because in general AOF The data set saved by the file is better than RDB The data set of the file should be complete .
- If Can accept data loss within a few minutes , Then you can. Use only RDB Persistence .
- Many users only use AOF Persistence , But it's not recommended , Because of timing generation RDB snapshot (snapshot) Very convenient for data backup , also RDB Data set recovery is also faster than AOF Fast recovery , besides , Use RDB You can also avoid AOF programmatic bug.
- If you only need data to exist when the server is running , You can also use no persistence .
11.Redis Data recovery ?
When Redis Something went wrong , It can be downloaded from RDB perhaps AOF Recovering data in .
The recovery process is also very simple , hold RDB perhaps AOF File copy to Redis Under the data directory , If you use AOF recovery , Profile on AOF, Then start redis-server that will do .

Redis The process of loading data at startup :
- AOF Persistence is on and exists AOF When you file , Priority load AOF file .
- AOF Close or AOF When the file does not exist , load RDB file .
- load AOF/RDB After the document is successful ,Redis Successful launch .
- AOF/RDB When there is an error in the file ,Redis Failed to start and print error message .
12.Redis 4.0 Hybrid persistence for, you know ?
restart Redis when , We seldom use RDB To restore memory state , Because a lot of data will be lost . We usually use AOF Log replay , But replay AOF Log performance is relative RDB It's a lot slower , In this way Redis When the examples are large , It takes a long time to start .
Redis 4.0 To solve this problem , Brings a new persistence option —— Mix persistence . take rdb The content of the file and the incremental AOF Log files exist together . there AOF Logs are no longer full logs , It is From the beginning to the end of persistence The increment of this period of time AOF journal , Usually this part AOF The log is very small :

So in Redis When restarting , You can load rdb The content of , Then replay the increment AOF Log can completely replace the previous AOF Full file replay , The restart efficiency has been greatly improved .
High availability
Redis There are three main ways to ensure high availability : Master-slave 、 sentry 、 colony .
13. Master slave replication understand ?

Master slave copy , It means to put one Redis Server data , Copy to other Redis The server . The former is called Master node (master), The latter is called From the node (slave). And data replication is A one-way Of , From master to slave only .Redis Master slave replication support Master slave synchronization and From slave synchronization Two kinds of , The latter is Redis What's new in subsequent versions , To reduce the synchronization burden of the primary node .
Master-slave replication is the main function ?
- data redundancy : Master-slave replication realizes hot backup of data , It's a way of data redundancy beyond persistence .
- Fault recovery : When there is a problem with the master node , Can be served by a slave node , Fast fault recovery ( It's actually a redundancy of services ).
- Load balancing : On the basis of master-slave replication , Cooperate with the separation of reading and writing , Write service can be provided by the master node , Read service provided by slave node ( The write Redis Connect master node when data is applied , read Redis Apply connection from node when data ), Share server load . Especially in the situation of less writing and more reading , Sharing read load through multiple slave nodes , Can be greatly improved Redis Concurrency of servers .
- High availability cornerstone : In addition to the above functions , Master-slave replication can also be implemented by sentinels and clusters Basics , So master-slave replication is Redis High availability Foundation .
14.Redis There are several common topologies for master and slave ?
Redis The replication topology can support single-layer or multi-layer replication relationships , According to the topological complexity, it can be divided into the following three kinds : A master from 、 One master, many followers 、 Tree master slave structure .
1. One master and one slave structure
A master-slave structure is the simplest replication topology , It is used to provide failover support to the slave node when the primary node goes down .

2. One master multi slave structure
One master multi slave structure ( Also known as star topology ) So that the application side can use multiple slave nodes to realize read-write separation ( See the picture 6-5). For scenes where reading takes up a large proportion , The read command can be sent to the slave node to share the pressure of the master node .

3. Tree master slave structure
Tree master slave structure ( Also known as tree topology ) So that the slave node can not only copy the data of the master node , At the same time, it can continue to replicate to the next level as the master of other slave nodes . By introducing the replication middle layer , It can effectively reduce the load of the master node and the amount of data to be transmitted to the slave node .

15.Redis Do you understand the principle of master-slave replication ?
Redis The workflow of master-slave replication can be roughly divided into the following steps :

- Save master (master) Information
This step is only to save the master node information , Save the name of the master node ip and port. - Master slave connection
From the node (slave) After discovering a new master node , Will try to establish a network connection with the primary node . - send out ping command
Send from node after successful connection establishment ping Request for first communication , It mainly detects whether the network socket between master and slave is available 、 Whether the master node can accept the processing command . - Authority verification
If the master node requires password authentication , The slave node must have the correct password to pass the authentication . - Synchronize datasets
After the master-slave replication connection is in normal communication , The master node will send all the data held to the slave node . - Command continuous replication
Next, the master node continuously sends the write command to the slave node , Ensure master-slave data consistency .
16. Talk about the way of master-slave data synchronization ?
Redis stay 2.8 And above psync Command to complete master-slave data synchronization , The synchronization process is divided into : Full and partial replication .

Copy in full
Generally used in the first replication scenario ,Redis In the early days, only full replication was supported , It will send all the data of the master node to the slave node at one time , When the amount of data is large , It will cause a lot of overhead to the master-slave node and the network .
The complete operation process of full replication is as follows :

- send out psync Command to synchronize data , Because it's the first time to replicate , The slave node does not copy the offset and the master node's operation ID, So send psync-1.
- The master node is based on psync-1 It is resolved that the current copy is full , reply +FULLRESYNC Respond to .
- Receive the response data of the master node from the node to save and run ID And offset offset
- Master node execution bgsave preservation RDB File to local
- The master node sends RDB File to slave , Receive from the node RDB The file is stored locally and directly as the data file of the slave node
- For receiving from the node RDB From snapshot to receiving completion , The master node still responds to read and write commands , Therefore, the master node will save the write command data during this period in the copy client buffer , When loading from the node RDB After the document , The master node then sends the data in the buffer to the slave node , Ensure data consistency between master and slave .
- After receiving all the data from the master node, the slave node will clear its old data
- Start loading after clearing the data from the node RDB file
- Successfully loaded from node RDB after , If the current node is enabled AOF Persistence function , It will do it immediately bgrewriteaof operation , In order to ensure that after full replication AOF Persistent files are immediately available .
Partial reproduction
Part of the replication is mainly Redis An optimization measure for the high cost of full replication , Use psync{runId}{offset} Command implementation . When the slave node (slave) Copying master (master) when , If there is an abnormal situation such as network flash or command loss , The slave node will move to The master node requests to reissue the lost command data , If this part of data exists in the replication backlog buffer of the master node, it will be sent directly to the slave node , In this way, you can maintain the consistency of the master-slave node replication .

- When the network between the master and slave nodes is interrupted , If exceeded repl-timeout Time , The master node will think that the slave node fails and disconnects the replication connection
- The master node still responds to the command when the master-slave connection is interrupted , But the copy connection interrupt command cannot be sent to the slave node , However, there is a replication backlog buffer inside the primary node , You can still save the latest write command data , Default Max cache 1MB.
- When the master-slave network is restored , The slave node will connect to the master node again
- When the master-slave connection is restored , Since the slave node has previously saved its own copied offset and the operation of the master node ID. So I think of them as psync Parameters are sent to the master node , Partial copy operation required .
- The master node receives psync After the command, first check the parameters runId Is it consistent with itself , If one Cause , Note that the current primary node is copied before ; Then according to the parameters offset Find in the self replication backlog buffer , If the data after the offset exists in the buffer , Then send... To the slave node +CONTINUE Respond to , Indicates partial replication is possible .
- The master node sends the data in the replication backlog buffer to the slave node according to the offset , Make sure the master-slave copy is in normal state .
17. What are the problems with master-slave replication ?
Master-slave replication is good , But there are also some problems :
- Once the primary node fails , You need to manually promote a slave node to a master node , At the same time, you need to modify the address of the primary node of the application , You also need to command other slave nodes to copy the new master node , The whole process needs manual intervention .
- The write ability of the master node is limited by a single machine .
- The storage capacity of the primary node is limited by the single machine .
The first question is Redis High availability problem of , second 、 Three questions belong to Redis The distributed problem of .
18.Redis Sentinel( sentry ) Understand? ?
There is a problem with master-slave replication , Unable to complete automatic failover . So we need a solution to complete automatic failover , It is Redis Sentinel( sentry ).

Redis Sentinel , It consists of two parts , Sentinel nodes and data nodes :
- The sentinel node : The sentinel system consists of one or more sentinel nodes , Sentinel nodes are special Redis node , Don't store data , Monitor data nodes .
- Data nodes : Both master and slave nodes are data nodes ;
On the basis of replication , The Sentinels achieved Automated fault recovery function , The following is the official description of the sentinel function :
- monitor (Monitoring): The Sentry will constantly check whether the master and slave nodes are working properly .
- Automatic failover (Automatic failover): When Master node When not working properly , The Sentinels will start Automatic failover operations , It will fail one of the master nodes Upgrade from node to new master , And let the other slave node copy the new master node .
- Configuration provider (Configuration provider): When the client is initializing , Get the current... By connecting the sentinels Redis The primary node address of the service .
- notice (Notification): Sentinels can send failover results to clients .
among , Monitoring and automatic failover functions , So that the sentinel can detect the failure of the primary node in time and complete the transfer . And configure providers and notification functions , It needs to be reflected in the interaction with the client .
19.Redis Sentinel( sentry ) You know how it works ?
Sentinel mode is to monitor data nodes through sentinel nodes 、 Offline 、 Fail over .

- Time monitoring
Redis Sentinel The discovery and monitoring of each node are completed through three regular monitoring tasks : every other 10 second , Every Sentinel Nodes send to master and slave nodes info Command to get the latest topology every 2 second , Every Sentinel The node will Redis Data node's __sentinel__:hello Send this on channel Sentinel Node's judgment on the primary node and current Sentinel Node information every 1 second , Every Sentinel The node will move to the master node 、 From the node 、 rest Sentinel Node sends a ping Command to do a heartbeat test , To confirm whether these nodes are currently reachable - Subjective offline and objective offline
Subjective offline is when the sentinel node thinks that a node has a problem , The objective offline is that more than a certain number of sentinel nodes think there is a problem with the primary node .
- Subjective offline
Every Sentinel The nodes will be every 1 Second to primary 、 From the node 、 other Sentinel The node sends ping Command to do heartbeat detection , When these nodes exceed down-after-milliseconds No effective reply ,Sentinel The node will make a failure judgment on the node , This behavior is called subjective offline . - Objective offline
When Sentinel When the subjective offline node is the master node , The Sentinel Node will pass sentinel is- master-down-by-addr Command to other Sentinel The judgment of node query to master node , When more than <quorum> Number ,Sentinel The node believes that the primary node does have a problem , At this time Sentinel The node will make an objective offline decision
- The leader Sentinel Node election
Sentinel There will be a leader election between nodes , Choose one Sentinel The node acts as a leader for failover .Redis Used Raft The algorithm realizes the leader election . - Fail over
- Elected by leaders Sentinel Node is responsible for failover , The process is as follows :
- Select a node from the list of nodes as the new master node , This step is a relatively complicated one
- Sentinel The leader node will execute... On the selected slave node in the first step slaveof no one Command to make it the master
- Sentinel The leader node will send commands to the remaining slave nodes , Make them slaves of the new master
- Sentinel The node collection will update the original master node to the slave node , And keep an eye on it , When it is restored, command it to replicate the new master
20. The leader Sentinel Do you understand ?
Redis Used Raft The algorithm is The current leader election , The general flow is as follows :

- Every online Sentinel All nodes are qualified to be leaders , When it confirms the master node When offline , To others Sentinel The node sends sentinel is-master-down-by-addr command , Ask yourself to be a leader .
- Ordered Sentinel node , If you have not agreed to anything else Sentinel Node sentinel is-master-down-by-addr command , Will agree to the request , Otherwise, refuse .
- If it's time to Sentinel The node finds that its votes are greater than or equal to max(quorum, num(sentinels)/2+1), Then it will become a leader .
- If this process does not elect leaders , Going to the next election .
21. How the new master node is selected ?
Select the new master node , It can be divided into these steps :

- Filter :“ unhealthy ”( Subjective offline 、 Broken wire )、5 I didn't reply in seconds Sentinel section spot ping Respond to 、 Lost connection with master node more than down-after-milliseconds*10 second .
- choice slave-priority( From node priority ) The highest list of slave nodes , Return if present , If it doesn't exist, continue .
- Select the slave node with the largest copy offset ( The most complete copy ), If it exists, return to return , If it doesn't exist, continue .
- choice runid The smallest slave .
22.Redis Do you understand ?
As mentioned earlier, there are high availability and distributed problems between master and slave , Sentry solved the problem of high availability , Cluster is the ultimate solution , Solve the problems of high availability and distribution in one fell swoop .

- Data partition : Data partition ( Or data fragmentation ) It is the core function of cluster . Clusters spread data across multiple nodes , One side Break through the Redis The limit of single machine memory size , There's a huge increase in storage capacity ; On the other hand Each primary node can provide external read and write services , It greatly improves the response ability of the cluster .
- High availability : The cluster supports master-slave replication and master node Automatic failover ( Like a sentry ), When any node fails , Clusters can still provide external services .
23. How to partition data in a cluster ?
Distributed storage , To map the dataset to multiple nodes according to partition rules , There are three common data partition rules :

Scheme 1 : The node takes the remaining partition
The node takes the remaining partition , Very easy to understand , Using specific data , such as Redis Key , Or the user ID And so on , Responding to hash Value redundancy :hash(key)%N, To determine which node the data is mapped to .
But the biggest problem with the program is , When the number of nodes changes , Such as expanding or shrinking nodes , Data node mapping The system needs to be recalculated , It can lead to data re migration .

Option two : Consistent hash partition
Will the whole Hash The value space is organized into a virtual circle , Then cache the node's IP Address or host name Hash After taking the value , Put it on this ring . When we need to identify a Key Need to be When accessing to which node , First of all Key Do the same Hash Value , Determine the position on the ring , Then put it on the ring in a clockwise direction “ walk ”, The first cache node encountered is the node to be accessed .
For example, the following In this picture ,Key 1 and Key 2 Will fall into Node 1 in ,Key 3、Key 4 Will fall into Node 2 in ,Key 5 Fall into Node 3 in ,Key 6 Fall into Node 4 in .

Compared with node remainder, the biggest advantage of this method is that adding and deleting nodes only affect the hash ring Adjacent nodes , No impact on other nodes .
But it still has problems :
- Cache nodes are unevenly distributed over the ring , This will cause great pressure on some cache nodes
- When a node fails , All the accesses to be undertaken by this node will be moved to another node in sequence , It will exert force on the following node .
Option three : Virtual slot partition
This scheme Consistent hash partition based on , Introduced Virtual node The concept of .Redis Cluster uses this scheme , The virtual node is called Slot (slot). Slots are virtual concepts between data and actual nodes , Each actual node contains a certain number of slots , Each slot contains data with hash value in a certain range .

In a consistent hash partition where slots are used , Slots are the basic unit of data management and migration . Slots decouple data from actual nodes The relationship between , Adding or deleting nodes has little effect on the system . Take the picture above as an example , There are 4 Actual nodes , Suppose you assign 16 Slot (0-15);
- Slot 0-3 be located node1;4-7 be located node2; And so on ....
If delete at this time node2, Just put the slot 4-7 Redistribution is enough , Such as slot 4-5 Assigned to node1, Slot 6 Assigned to node3, Slot 7 Assigned to node4, The distribution of data in other nodes is still relatively balanced .
24. Can you talk about Redis The principle of clustering ?
Redis The cluster realizes the distributed storage of data through data partition , High availability through automatic failover .
Create cluster
Data partitioning is completed when the cluster is created .

Set nodes
Redis A cluster is usually composed of multiple nodes , The number of nodes shall be at least 6 To ensure a complete and highly available cluster . Each node needs to turn on configuration cluster-enabled yes, Give Way Redis Running in cluster mode .

Node handshake
Node handshake means that a batch of nodes running in cluster mode pass through Gossip Protocols communicate with each other , The process of perceiving each other . Node handshake is the first step for clusters to communicate with each other , Initiated by the client Make :cluster meet{ip}{port}. After the node handshake , One by one Redis Nodes form a multi node cluster .
Distribution slot (slot)
Redis The cluster maps all the data to 16384 In a groove . Each node corresponds to several slots , Only if the node has allocated slots , To respond to key commands associated with these slots . adopt cluster addslots Command to assign slots to nodes .

Fail over
Redis The failover of clusters is similar to that of sentinels , however Redis All nodes in the cluster should undertake the task of state maintenance .
Fault finding
Redis Nodes in the cluster pass through ping/pong Message implementation node communication , Every node in the cluster will send... To other nodes on a regular basis ping news , Receiving node reply pong Message in response . If in cluster-node-timeout Communication fails all the time , Then send section The point will think that the receiving node is faulty , Mark the receiving node as the subjective offline (pfail) state .

When a node judges the subjective offline of another node , The corresponding node state will follow the message propagation in the cluster . adopt Gossip Information dissemination , The nodes in the cluster continuously collect the offline reports of the failed nodes . When When more than half of the master nodes holding slots mark a node as a subjective offline . Trigger the objective offline process .

Fault recovery
After the failure node becomes objective offline , If the downline node is the master node holding the slot, it needs to be in it Select one of the nodes to replace it , So as to ensure the high availability of the cluster .

- Qualification check
Each slave node should check the last disconnection time with the master node , Determine whether it is qualified to replace the fault The primary node of . - Time to prepare for the election
When the slave node is eligible for fail over , Update the time when the fault election is triggered , Only when you reach the The follow-up process can only be executed after time . - Launch an election
When the timing task detection from the node reaches the fault election time (failover_auth_time) After arrival , Initiate the election process . - The election vote
The master node holding the slot handles the fault election message . The voting process is actually a leader election process , If there is N A main section holding slots Points represent N votes . Since the master node holding the slot in each configuration era can only vote for one From the node , So only one can get it from the node N/2+1 The votes of the , Make sure to find the only slave node . - Replace master
When enough votes are collected from the nodes , Trigger replace master operation .
Deploy Redis The cluster requires at least a few physical nodes ?
In the voting process , The failed master node is also counted in the number of votes , Suppose the size of nodes in the cluster is 3 Lord 3 from , Among them is 2 A master node is deployed on one machine , When this machine goes down , Because... Cannot be collected from node 3/2+1 A primary node vote will result in failover failure . This problem also applies to the fault discovery link . Therefore, when deploying a cluster, all primary nodes need to be deployed at least 3 A single point of failure can only be avoided on a physical machine .
25. Talk about the scaling of clusters ?
Redis Cluster provides flexible node expansion and contraction scheme , This can be done without affecting the external services of the cluster , Add nodes to the cluster for capacity expansion, or reduce the capacity of some offline nodes .

Actually , The key points of cluster capacity expansion and reduction , It lies in the corresponding relationship between slot and node , Capacity expansion and reduction are the migration of some slots and data to new nodes .
For example, the following cluster , Each node corresponds to several slots , Each slot corresponds to a certain amount of data , If you want to join 1 When a node wants to expand the cluster capacity , Some slots and contents need to be migrated to the new node through relevant commands .

Shrinkage is similar , First migrate the slot and data to other nodes , Then take the corresponding node offline .
Cache design
26. What is cache breakdown 、 Cache penetration 、 Cache avalanche ?
PS: This is the old stereotype of the Yellow calendar for many years , Be sure to understand .
Cache breakdown
A large number of concurrent visits key Expire at a certain time , Cause all requests to be typed directly in DB On .

solve ⽅ case :
- Lock update ,⽐ Such as request for inquiry A, Found no... In cache , Yes A This key Lock , At the same time, go to the database to query the data , Write ⼊ cache , Return to ⽤ Household , After this ⾯ The request can get the data from the cache .
- Write the expiration time combination in value in , Through asynchronous ⽅ Continuously refresh the expiration time , prevent ⽌ Such phenomena .
Cache penetration
Cache penetration refers to data that does not exist in both the query cache and the database , In this way, each request is directly called to the database , It's like the cache doesn't exist .

Cache penetration will cause non-existent data to be queried in the storage layer every time it is requested , Lost the significance of cache protection back-end storage .
Cache penetration may increase the back-end storage load , If a large number of storage layer null hits are found , Maybe there is a cache penetration problem .
Cache penetration can occur for two reasons :
- Own business code problem
- A malicious attack , Reptiles cause empty hits
There are two main solutions :
- Cache null / The default value is
One way is after a database miss , Save an empty object or default value to the cache , Then access the data , It gets it from the cache , This protects the database .

There are two major problems with caching null values :
- Null values are cached , It means that there are more keys in the cache layer , Need more memory space ( If it's an attack , The problem is more serious ), The more effective way is to set a shorter expiration time for this kind of data , Let it automatically remove .
- The data of cache layer and storage layer will be inconsistent for a period of time , It may have some impact on the business .
For example, the expiration time is set to 5 minute , If the storage layer adds this data at this time , Then there will be inconsistencies between the cache layer and the storage layer data in this period of time . At this time, you can use message queue or other asynchronous methods to clean up the empty objects in the cache .
- The bloon filter
In addition to caching empty objects , We can also store and cache before , Add a bloom filter , Do a layer of filtering .
The bloom filter will store whether the data exists , If you judge that the data is not, you can no longer , No access to storage .

Comparison of the two solutions :

Cache avalanche
some ⼀ All the time ⽣⼤ Large scale cache invalidation , For example, the cache service is down 、 A lot of key Expire at the same time , The result is ⼤ The quantity request comes in and calls directly to DB On , May cause the whole system to crash , It's called an avalanche .
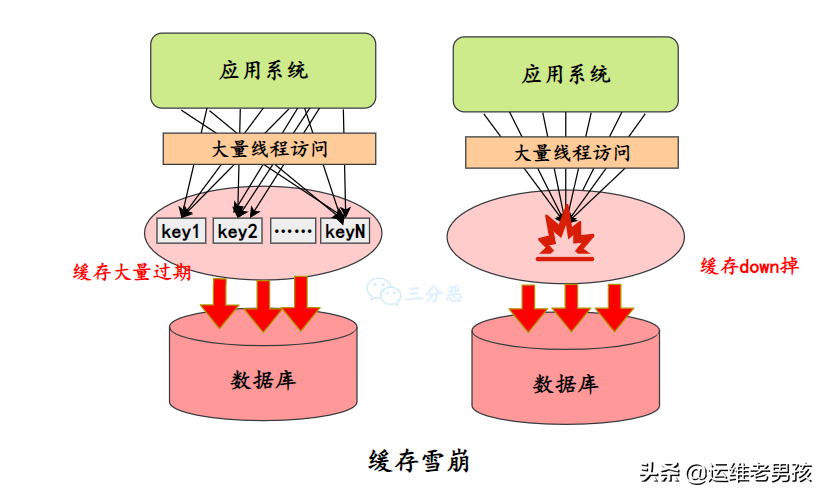
Cache avalanche is the most serious of the three cache problems , Let's see how to prevent and deal with .
- Improve cache availability
- Cluster deployment : Improve cache availability through clustering , You can use Redis Of itself Redis Cluster Or a third-party cluster scheme, such as Codis etc. .
- Multi level cache : Set up multi level cache , Based on the failure of the first level cache , Access the L2 cache , The expiration time of each level of cache is different .
- Expiration time
- Even expiration : To avoid a large number of caches expiring at the same time , You can put different key The expiration time is randomly generated , Avoid too concentrated expiration time .
- Hot data never expires .
- Fusing the drop
- Service failure : When the cache server goes down or the response times out , To prevent the whole system from avalanche , Temporarily stop business services from accessing the cache system .
- service degradation : When a large number of cache failures occur , And in the case of high concurrency and high load , Temporarily abandon requests for some non core interfaces and data within the business system , And go straight back to a prepared fallback( retreat ) Error handling information .
27. Can you talk about the bloom filter ?
The bloon filter , It is a continuous data structure , Each storage bit is a bit, namely 0 perhaps 1, To identify whether the data exists .
When storing data , Use K A different hash function maps this variable to bit Of the list K A little bit , Set them as 1.

We judge the cache key Whether there is , Again ,K Hash functions , Mapping to bit On the list K A little bit , Judgment is not 1:
- If it's not 1, that key non-existent ;
- If it's all 1, It just means key Possible .
Bloom filters also have some disadvantages :
- It has a certain error probability in judging whether the element is in the collection , Because the hash algorithm has a certain collision probability .
- Deleting elements... Is not supported .
28. How to ensure the of cache and database data ⼀ Sexual nature ?
according to CAP theory , On the premise of ensuring availability and partition fault tolerance , There is no guarantee of consistency , Therefore, the absolute consistency between cache and database is impossible , Only the final consistency between the cache and the database can be saved as much as possible .
Choose the appropriate cache update strategy
1. Delete cache instead of update cache
When a thread to cache key When writing , If other threads come in to read the database , What you read is dirty data , There is a problem of data inconsistency .
By comparison , Deleting the cache is much faster than updating the cache , It takes a lot less time , The probability of reading dirty data is also much lower .

- Check the data first , Post deletion cache
Change the database first or delete the cache first ? That's a problem .
Update data , It may take more than a hundred times as long to delete the cache . The corresponding... Does not exist in the cache key, When the database has not finished updating , If a thread comes in to read data , And write to the cache , So after the update is successful , This key It's just dirty data .
without doubt , Delete cache first , More database , In cache key The time that doesn't exist is longer , There is a greater probability that dirty data will be generated .

At present, the most popular cache read-write strategy cache-aside-pattern Is to use the first change database , Then delete the cache .
Cache inconsistency handling
If the concurrency is not particularly high , Highly cache dependent , In fact, the inconsistency of certain procedures is acceptable .
But if the requirements for consistency are high , Then we have to find a way to ensure that the cache is consistent with the data in the database .
There are two common reasons for inconsistency between cache and database data :
- cache key Delete failed
- Concurrency causes dirty data to be written

Message queuing guarantees key Be deleted
Message queues can be introduced , To delete key Or delete the failed key Lose all message queues , Using the retry mechanism of message queue , Retry deleting the corresponding key.

This scheme looks good , The disadvantage is that it is intrusive to business code .
Database subscription + Message queuing guarantees key Be deleted
You can use a service ( Like Ali's canal) To monitor the database binlog, Get the data to be operated .
Then use a public service to get the information from the subscription program , Delete the cache .

This approach reduces intrusion into the business , But in fact, the complexity of the whole system is increased , Suitable for large factories with complete infrastructure .
Delay double deletion to prevent dirty data
There's another situation , When the cache does not exist , Dirty data written , In this case, delete the cache first , More frequently occurs under the cache update strategy of the database , The solution is to delay double deletion .
In short , After deleting the cache for the first time , After a while , Delete cache again .

The delay time setting in this way needs to be carefully considered and tested .
Set the cache expiration time to find out
This is a simple but useful way , Set a reasonable expiration time for the cache , Even if the cache data is inconsistent , It won't be inconsistent forever , When the cache expires , Naturally, it will return to unity .
29. How to ensure the consistency between local cache and distributed cache ?
PS: This question is rarely asked in an interview , But it is very common in practical work .
In daily development , We often use two-level cache : Local cache + Distributed cache .
The so-called local cache , Is the memory cache of the corresponding server , such as Caffeine, Distributed caching is basically using Redis.
So here comes the question , How to keep data consistent between local cache and distributed cache ?

Redis cache , The database is updated , Directly delete the cached key that will do , Because for application systems , It is a centralized cache .
But local cache , It's decentralized , Scattered on various nodes of distributed services , It is impossible to delete the local cache through the request of the client key, So we have to find a way to notify all nodes of the cluster , Delete the corresponding local cache key.

You can use message queuing :
- use Redis Of itself Pub/Sub Mechanism , All nodes in the distributed cluster subscribe to delete local cache channels , Delete Redis Cached nodes , A colleague publishes a message to delete the local cache , After subscribers subscribe to the message , Delete the corresponding local key.
however Redis Your publication subscription is not reliable , There is no guarantee that the deletion will succeed . - Introduce professional message queue , such as RocketMQ, Ensure the reliability of the message , But it increases the complexity of the system .
- Set the appropriate expiration time to find out , The local cache can set a relatively short expiration time .
30. How to deal with heat key?
What is heat Key?
The so-called heat key, It's about the frequency of visits key.
such as , Hot news events or goods , This kind of key There are usually heavy traffic visits , For storing this kind of information Redis Come on , It's no small pressure .
If Redis Cluster deployment , heat key It may cause the imbalance of the overall flow , Individual nodes appear OPS Too big a situation , In extreme cases, hot spots key Even more than Redis What it can bear OPS.
How to deal with heat key?

Antipyretic key To deal with , The key is to focus on hot spots key Monitoring of , Hot spots can be monitored from these ends key:
- client
The client is actually a distance key“ lately ” The place of , because Redis The command is issued from the client , For example, set the global dictionary on the client (key And the number of calls ), Every time you call Redis On command , Use this dictionary to record . - agent
image Twemproxy、Codis These agent-based Redis Distributed architecture , All client requests are completed through the proxy , You can collect statistics on the agent side . - Redis Server side
Use monitor Command statistics hotspot key Many developers and operation and maintenance personnel first thought of ,monitor The command can monitor Redis All commands executed .
As long as the heat is monitored key, Antipyretic key It's easy to deal with :
- Heat up key Break up to different servers , Lower pressure ⼒
- Add ⼊⼆ Level cache , Load hot ahead of time key Data into memory , If redis Downtime ,⾛ Memory query
31. How to warm up the cache ?
The so-called cache preheating , Is to brush the data in the database into the cache in advance , There are usually these methods :
1、 Directly write a cache refresh page or interface , Manual operation when online
2、 Not a lot of data , It can be loaded automatically when the project starts
3、 Scheduled task refresh cache .
32. hotspot key The reconstruction ? problem ? solve ?
When developing, we usually use “ cache + Expiration time ” The strategy of , It can speed up data reading and writing , And ensure the regular update of data , This model can basically meet most of the needs .
But if there are two problems at the same time , There may be big problems :
- At present key It's a hot spot key( For example, a popular entertainment news ), The amount of concurrency is very large .
- Rebuilding the cache cannot be done in a short time , It could be a complex calculation , For example, complicated SQL、 many times IO、 Multiple dependencies, etc . In the moment of cache failure , There are a lot of threads to rebuild the cache , Cause the back-end load to increase , It might even crash the app .
How to deal with it ?
It's not very complicated to solve this problem , The key to solving the problem is :
- Reduce the number of cache rebuilds .
- The data is as consistent as possible .
- Less potential danger .
Therefore, the following methods are generally adopted :
- The mutex (mutex key)
This method allows only one thread to rebuild the cache , Other threads wait for the thread to rebuild the cache to finish , Get the data from the cache again . - Never expire
“ Never expire ” It has two meanings :
- At the cache level , It's true that the expiration time is not set , So there will be no hot spots key Problems after expiration , That is to say “ Physics ” Not overdue .
- From a functional point of view , For each value Set a logical expiration time , When it is found that the logical expiration time is exceeded , Will use a separate thread to build the cache .
33. Bottomless hole problem ? How to solve ?
What is a bottomless hole problem ?
2010 year ,Facebook Of Memcache The node has reached 3000 individual , Bearing the TB Level cache data . But developers and operators have found a problem , In order to meet the business requirements, a large number of new Memcache node , But we find that the performance is not improved, but decreased , At that time, this This phenomenon is called caching “ Bottomless pit ” The phenomenon .
So why does this happen ?
In general, adding nodes makes Memcache colony The performance should be stronger , But that's not the case . Because the key value database usually uses hash function, it will key Map to each node , cause key The distribution of has nothing to do with the business , However, due to the continuous growth of data volume and access volume , As a result, a large number of nodes need to be added for horizontal expansion , This results in the distribution of key values to more Node , So whether it's Memcache still Redis Distributed , Batch operations usually need to get... From different nodes , Compared with single machine batch operation, only one network operation is involved , Distributed batch operations involve multiple network times .
How to optimize the bottomless hole problem ?
First analyze the bottomless hole problem :
- A batch operation of the client will involve multiple network operations , This means that batch operations will increase with the number of nodes , It's going to take longer .
- More network connections , It also has a certain impact on the performance of nodes .
Common optimization ideas are as follows :
- Optimization of the command itself , For example, optimize operation statements, etc .
- Reduce the number of network communications .
- Reduce access costs , For example, the client uses long connection / Connection pool 、NIO etc. .
Redis Operation and maintenance
34.Redis How to deal with insufficient memory ?
Redis There are several ways to deal with insufficient memory :
- Modify the configuration file redis.conf Of maxmemory Parameters , increase Redis Available memory
- Or by order set maxmemory Dynamically set the upper memory limit
- Modify the memory obsolescence policy , Free memory space in time
- Use Redis Cluster pattern , Expand horizontally .
35.Redis What are your expired data recovery strategies ?
Redis There are mainly 2 An expired data recovery strategy :

Lazy deletion
Lazy delete refers to when we query key It's only when key Into the ⾏ testing , If the expiration time has been reached , Delete . obviously , He has ⼀ One disadvantage is that if these expired key Not interviewed , Then he will ⼀ straight ⽆ The law was deleted ,⽽ And ⼀ Direct occupation ⽤ Memory .
Delete periodically
Periodic deletion means Redis every other ⼀ For a period of time, do ⼀ Secondary inspection , Delete ⾥⾯ The expiration date of key. Because it's impossible for all key To do a poll to delete , therefore Redis Will take... At random every time ⼀ some key To check and delete .
36.Redis What are the memory overflow controls / Memory retirement strategy ?
Redis Memory used up to maxmemory The upper limit will trigger the corresponding overflow control strategy ,Redis Six strategies are supported :

- noeviction: The default policy , No data will be deleted , Reject all writes and return Return the client error message , this when Redis Only respond to read operations .
- volatile-lru: according to LRU Algorithm delete set timeout property (expire) Key , straight Until there is enough space . If there is no key object to delete , Back to noeviction Strategy .
- allkeys-lru: according to LRU Algorithm delete key , Whether or not the timeout property is set for the data , Until there is enough space .
- allkeys-random: Randomly delete all keys , Until there is enough space .
- volatile-random: Randomly delete expiration key , Until there is enough space .
- volatile-ttl: According to the ttl attribute , Delete data that is about to expire recently . If No, , Back to noeviction Strategy .
37.Redis Blocking ? How to solve ?
Redis happening , You can check from the following aspects :

- API Or the use of data structure is unreasonable
- Usually Redis Execute commands very fast , But using commands unreasonably , It may cause slow execution , Lead to blocking , For high concurrency scenarios , We should try to avoid the complexity of executing algorithms on large objects More than O(n) The order of .
- The processing of slow queries is divided into two steps :
- Slow query found : slowlog get{n} Command can get the latest Of n Slow query commands ;
- After discovering the slow query , Slow queries can be optimized in two directions :
1) Modify to a command with low algorithm complexity , Such as hgetall Change it to hmget etc. , Ban keys、sort Waiting for life Make 2) Adjust large objects : Reduce large object data or split large objects into multiple small objects , Prevent one command from operating too much data . - CPU The problem of saturation
- Single threaded Redis Only one can be used when processing commands CPU. and CPU Saturation means Redis Single core CPU The utilization rate is close to 100%.
- In this case , The processing steps are generally as follows :
- Judge the present Redis Whether the concurrency has reached the limit , You can use the statistics command redis-cli-h{ip}-p{port}--stat Get current Redis usage
- If Redis Tens of thousands of requests +, So it's probably Redis Of OPS It's the limit , Cluster aquatic products should be expanded to share OPS pressure
- If only a few hundred thousand , Then you have to check the use of commands and memory
- Persistence related blocking
- For those with persistence enabled Redis node , It is necessary to check whether it is blocking caused by persistence .
- fork Blocking
fork Operation occurred in RDB and AOF When rewriting ,Redis Main thread call fork The operation produces shared Memory subprocesses , The child process rewrites the persistent file . If fork Operation itself takes too long , The main thread must be blocked . - AOF Brush disc blocked
When we turn on AOF When persistent , Generally, the file is swiped once a second , Background threads pair AOF File do fsync operation . When the hard disk pressure is too high ,fsync The operation needs to wait stay , Until writing is complete . If the main thread finds that the fsync Successfully exceeded 2 second , in order to Data security it blocks until the background thread executes fsync Operation is completed . - HugePage Write blocking
For opening Transparent HugePages Of operating system , The unit of copied memory pages caused by each write command is 4K Turn into 2MB, Magnified 512 times , Slow down the execution time of write operation , Causes a large number of write operations to slow queries .
38. Big key Do you understand the problem ?
Redis In use , Sometimes there are big key The situation of , such as :
- Single, simple key Stored value It's big ,size exceed 10KB
- hash, set,zset,list Too many elements are stored in ( In 10000 )
Big key What problems will it cause ?
- Increased client time , Even overtime
- Right big key Conduct IO In operation , It will seriously occupy bandwidth and CPU
- cause Redis Data skew in the cluster
- Active delete 、 Passive deletion, etc , It can cause obstruction
How to find big key?
- bigkeys command : Use bigkeys The command parses... In a traversal manner Redis All in the instance Key, And return the overall statistics and the data in each data type Top1 The big Key
- redis-rdb-tools:redis-rdb-tools By Python Written to analyze Redis Of rdb Tools for snapshot files , It can be rdb Snapshot file generation json File or generate reports to analyze Redis Details of the use of .
How to deal with big key?

- Delete big key
- When Redis The version is greater than 4.0 when , You can use UNLINK The command safely deletes large files Key, This command can be used in a non blocking manner , Gradually clean up incoming Key.
- When Redis Version less than 4.0 when , Avoid blocking commands KEYS, It's a proposal to pass SCAN Command to perform an incremental iterative scan key, Then judge to delete .
- Compress and split key
- When vaule yes string when , It's hard to split , Use serialization 、 The compression algorithm will key The size of is controlled within a reasonable range , But both serialization and deserialization are more time consuming .
- When value yes string, After compression, it is still large key, It needs to be split , A big key Divided into different parts , Record the of each section key, Use multiget And other operations to achieve transaction reading .
- When value yes list/set Is equal to the collection type , Slice according to the estimated data scale , Different elements are divided into different pieces after calculation .
39.Redis Common performance problems and solutions ?
- Master It's best not to do any persistence work , Includes memory snapshots and AOF Log files , In particular, do not enable memory snapshots for persistence .
- If the data is critical , Some Slave Turn on AOF The backup data , The policy is to synchronize once per second .
- For master-slave replication speed and connection stability ,Slave and Master Preferably on the same LAN .
- Try to avoid adding slave databases on the main database with high pressure .
- Master call BGREWRITEAOF rewrite AOF file ,AOF It's going to take up a lot of when you rewrite it CPU And memory resources , Lead to service load Too high , Temporary suspension of service .
- in order to Master The stability of , Master and slave replication do not use graphical structures , It is more stable to use one-way linked list , That is, the master-slave relationship is :Master<–Slave1<–Slave2<–Slave3…, Such a structure is also convenient to solve the problem of single point of failure , Realization Slave Yes Master Replacement , That is to say , If Master Hang up , It can be used immediately Slave1 do Master, The other is constant .
Redis application
40. Use Redis How to implement asynchronous queues ?
We know redis Support many kinds of data structures , So how to use redis As an asynchronous queue ?
Generally, there are several ways :
- Use list As a queue ,lpush Production news ,rpop News consumption
This way, , Consumer dead cycle rpop Consume messages from the queue . But this way , Even if there is no message in the queue , There will be rpop, It can lead to Redis CPU Consumption of .

It can be handled by letting consumers sleep , But this will also lead to the problem of message delay .
- Use list As a queue ,lpush Production news ,brpop News consumption
brpop yes rpop Blocking version of ,list When it's empty , It will keep blocking , until list There is a value in or timeout .

This method can only realize one-to-one message queue .
- Use Redis Of pub/sub To publish the news / subscribe
Release / Subscription mode can 1:N The news release of / subscribe . The publisher publishes the message to the specified channel (channel), All clients subscribing to the corresponding channel can receive messages .

But this method is not reliable , It does not guarantee that subscribers will receive messages , No message storage .
therefore , The general implementation of asynchronous queue is still handed over to professional message queue .
41.Redis How to implement delay queue ?
- Use zset, Using sorting to achieve
have access to zset This structure , Use the set timestamp as score Sort , Use zadd score1 value1 .... The command can produce messages all the way into memory . recycling zrangebysocre Query all pending tasks that meet the criteria , The queue task can be executed in a loop .

42.Redis Do you support transactions ?
Redis Provides a simple transaction , But it's for business ACID Your support is not complete .
multi An order represents the beginning of a business ,exec The order represents the end of the transaction , The commands between them are executed in atomic order :
Copy code
127.0.0.1:6379> multi
OK
127.0.0.1:6379> sadd user:a:follow user:b
QUEUED
127.0.0.1:6379> sadd user:b:fans user:a
QUEUED
127.0.0.1:6379> sismember user:a:follow user:b
(integer) 0
127.0.0.1:6379> exec 1) (integer) 1
2) (integer) 1
Redis How things work , It's all instructions in exec Not before , It's cached in
In a transaction queue on the server , Once the server receives exec Instructions , The entire transaction queue is opened , After execution, all instructions are returned at one time .

because Redis The execution of commands is single threaded , So this set of commands is executed sequentially , And will not be interrupted by other threads .
Redis What are the points for attention in business ?
The points to be noted are :
- Redis Transaction does not support rollback , Unlike MySQL It's the same thing , Either all or none ;
- Redis When the server executes a transaction , Will not be interrupted by command requests from other clients . The commands of other clients will not be executed until all transaction commands are executed .
Redis Why does transaction not support rollback ?
Redis The transaction of does not support rollback .
If there is a syntax error in the executed command ,Redis Will fail to execute , These problems can be captured and solved at the procedural level . But if there are other problems , Will continue to execute the remaining commands .
The reason for this is that rollback requires a lot of work , If rollback is not supported, you can Keep it simple 、 Fast features .
43.Redis and Lua Do you understand the use of scripts ?
Redis The transaction function of is relatively simple , In normal development , You can use Lua Script to enhance Redis The order of .
Lua Scripts can bring these benefits to developers :
- Lua Script in Redis It's atomic execution , No other commands are inserted during execution .
- Lua Scripts can help developers and operators create their own customized commands , And you can put this Some orders reside in Redis In the memory , Realize the effect of reuse .
- Lua Scripts can package multiple commands at one time , Effectively reduce network overhead .
For example, this paragraph is very ( bad ) the ( Big ) Dian ( Street, ) The second kill system uses lua Deduction Redis Inventory script :
Copy code
-- Inventory is not preheated
if (redis.call('exists', KEYS[2]) == 1) then
return -9;
end;
-- Second kill commodity inventory exists
if (redis.call('exists', KEYS[1]) == 1) then
local stock = tonumber(redis.call('get', KEYS[1]));
local num = tonumber(ARGV[1]);
-- The remaining stock is less than the requested quantity
if (stock < num) then
return -3
end;
-- Deducting the inventory
if (stock >= num) then
redis.call('incrby', KEYS[1], 0 - num);
-- Deduction succeeded
return 1
end;
return -2;
end;
-- Second kill commodity inventory does not exist
return -1;
44.Redis Do you understand the pipeline ?
Redis Provide three ways to package and send multiple commands from the client to the server for execution :
Pipelining( The Conduit ) 、 Transactions( Business ) and Lua Scripts(Lua Script ) .
Pipelining( The Conduit )
Redis Pipeline is the simplest of the three , When the client needs to execute multiple redis On command , Multiple commands to be executed can be sent to the server through the pipeline at one time , Its function is to reduce RTT(Round Trip Time) Impact on performance , For example, we use nc Command sends two instructions to redis Server side .
Redis After the server receives multiple commands sent by the pipeline , Will always carry out orders , And cache the execution results of the command , Until the last command is executed , The execution results of all commands are returned to the client at one time .

Pipelining The advantages of
In terms of performance , Pipelining There are two advantages :
- Saved RTT: Package multiple commands and send them to the server at one time , Reduce the number of network calls between the client and the server
- Reduced context switching : When the client / When the server needs to read and write data from the network , Will produce a system call , System calls are very time-consuming operations , The program is designed to switch from user state to kernel state , The process of switching from kernel state to user state . When we execute 10 strip redis When ordered , It will happen 10 Context switching from secondary user state to kernel state , But if we use Pipeining Package multiple commands into one and send them to the server at one time , There will only be one context switch .
45.Redis Implementation of distributed lock, understand ?
Redis The goal of distributed lock is to achieve in Redis There's one in it “ Maokeng ”, When other processes are going to take over , I found someone squatting there , You have to give up or try again later .
- V1:setnx command
Zhankeng is generally used setnx(set if not exists) Instructions , Only one client is allowed to occupy the pit . First come, first take , Run out of , Call again del Command the release of the pit .

Copy code
> setnx lock:fighter true
OK
... do something critical ...
> del lock:fighter
(integer) 1
But there's a problem , If there is an exception in the middle of logic execution , May lead to del The instruction was not called , This will lead to a deadlock , The lock will never be released .
- V2: Lock timeout release
So after getting the lock , Add an expiration time to the lock , such as 5s, In this way, even if there is an exception in the middle, it can guarantee 5 Seconds later the lock will automatically release .

Copy code
> setnx lock:fighter true
OK
> expire lock:fighter 5
... do something critical ...
> del lock:fighter
(integer) 1
But there are still problems with the above logic . If in setnx and expire The server process suddenly hangs up , It may be because the machine is powered down or killed by man , It will lead to expire Not implemented , It can also cause deadlock .
The root of this problem is setnx and expire It's two instructions, not atomic instructions . If the two instructions can be executed together, there will be no problem .
- V3:set Instructions
The question is Redis 2.8 Resolved in version , This version adds set Extension parameters of the instruction , bring setnx and expire Instructions can be executed together .

Copy code
set lock:fighter3 true ex 5 nx OK ... do something critical ... > del lock:codehole
The above instruction is setnx and expire Atomic instructions put together , This is a perfect distributed lock .
Of course, the actual development , No one will write the command of distributed lock by themselves , Because there are professional wheels ——Redisson.
The underlying structure
This part is deeper , If it wasn't written on the resume Redis, I shouldn't ask much .
46. say something Redis Underlying data structure ?
Redis Yes Dynamic string (sds)、 Linked list (list)、 Dictionaries (ht)、 Skip list (skiplist)、 Set of integers (intset)、 Compressed list (ziplist) And other underlying data structures .
Redis These data structures are not used to directly implement key value pair database , Instead, an object system is created based on these data structures , To represent all key-value.

The mapping relationship between our commonly used data types and codes :

Take a brief look at the underlying data structure , If you have a good grasp of data structure , Understanding these structures should not be particularly difficult :
- character string :redis Not directly make ⽤C language ⾔ Traditional string representation ,⽽ yes ⾃⼰ The implementation is called simple dynamic string SDS Abstract type of .
- C language ⾔ String does not record ⾃ I'm not ⻓ Degree information ,⽽SDS And then it saved ⻓ Degree information , This will get the string ⻓ The time of degrees is determined by O(N) Down to O(1), At the same time, it can avoid buffer overflow and reduce the number of modified strings ⻓ The number of memory reallocations required for a degree .

- Linked list linkedlist:redis The list is the ⼀ Two way ⽆ Linked list structure , A lot of publish subscribe 、 The slow query 、 The monitor function is to make ⽤ To the linked list to achieve , The node of each linked list consists of ⼀ individual listNode Structure to express , Each node has a pointer to the front node and the post node , At the same time, the front and rear nodes of the header node point to NULL.

- Dictionaries dict:⽤ An abstract data structure that holds key value pairs .Redis send ⽤hash Table as the underlying implementation , A hash table can have multiple hash table nodes , Each hash table node stores a key value pair in the dictionary .
Each dictionary has two hash surface , For peacetime use ⽤ and rehash Make timely ⽤,hash Watch makes ⽤ Chain address method to solve key conflicts , Assigned to the same ⼀ Multiple key value pairs at multiple index locations form ⼀ A one-way list , In the face of hash Table entry ⾏ When expanding or shrinking capacity , For the sake of service ⽤ sex ,rehash The process is not ⼀ Once completed ,⽽ It's progressive . - Skip list skiplist: A jump table is the underlying implementation of an ordered set ⼀,Redis In the implementation of ordered set keys and the internal structure of cluster nodes ⽤ To the jump table .Redis Jump watch by zskiplist and zskiplistNode form ,zskiplist⽤ Save jump table information ( Header 、 Tail node 、⻓ Degree, etc ),zskiplistNode⽤ Is used to represent the jump node of the table , The layer of each hop table node ⾼ All are 1-32 The random number , At the same time ⼀ In a jump list , Multiple nodes can contain the same score , However, the member object of each node must be unique ⼀ Of , Nodes are divided according to their scores ⼤⼩ Sort , If the scores are the same , According to the of the member object ⼤⼩ Sort .
- Set of integers intset:⽤ A collection abstract data structure that holds integer values , There will be no repeating elements , The bottom layer is implemented as an array .
- Compressed list ziplist: Compressed lists are designed to save memory ⽽ Developed sequential data structure , It can contain any number of nodes , Each node can save ⼀ An array of bytes or integer values .

47.Redis Of SDS and C What's the advantage of medium string ?
C The language uses a length of N+1 To represent the length of N String , And the last element of the character array is always \0, This simple string representation Do not conform to the Redis On strings in security 、 Efficiency and functional requirements .

C There may be something wrong with the language string ?
Such a simple data structure may cause the following problems :
- The complexity of obtaining string length is high : because C Do not save the length of the array , You need to traverse the entire array every time , The time complexity is O(n);
- Can't put an end to out of buffer / Memory leak The problem of : C Another problem caused by string not recording its own length is that it is easy to cause buffer overflow (buffer overflow), For example, when string splicing , new
- C character string Only text data can be saved → because C A string in a language must conform to some encoding ( such as ASCII), For example, in the middle '\0' It may be judged as an early terminated string and cannot be recognized ;
Redis How to solve ? advantage ?

To put it simply Redis How to solve :
- Increase more len Represents the length of the current string : So you can get the length directly , Complexity O(1);
- Automatically expand space : When SDS When a string needs to be modified , First of all, with the help of len and alloc Check whether the space meets the requirements for modification , If there's not enough space ,SDS Will automatically expand space , Avoid images. C Overflow in string operation ;
- Effectively reduce the number of memory allocation :C String will change the size of the underlying array and cause reallocation when increasing or clearing operations are involved ,SDS Used Space preallocation and Inert space release Mechanism , The simple understanding is that each time you expand it, it's multiple distribution , In shrinkage, it is also reserved first and not returned formally OS;
- Binary security :C Language strings can only hold ascii code , For the picture 、 Audio and other information cannot be saved ,SDS It's binary safe , Write what read what , No filtering or restriction ;
48. How the dictionary is realized ?Rehash Understand? ?
The dictionary is Redis The most frequent composite data structure appears in the server . except hash Structure data will be used outside the dictionary , Whole Redis All of the database key and value It also makes up a Global dictionary , And the ones with expiration dates key It's also a dictionary .( Stored in RedisDb In the data structure )
What is the structure of the dictionary ?
Redis The dictionary in is equivalent to Java Medium HashMap, The internal implementation is similar , Use hash and operation to calculate the subscript position ; adopt " Array + Linked list " The chain address method of To resolve hash conflicts , At the same time, this structure also absorbs the advantages of two different data structures .

How did the dictionary expand ?
The dictionary structure contains Two hashtable, Usually there is only one hash table ht[0] Valuable , During the expansion , hold ht[0] In the value of the rehash To ht[1], Then proceed Progressive type rehash —— The so-called progressive rehash, It means this rehash The action is not a one-off 、 Done centrally , It's a lot of times 、 Completed gradually .
After the move ,h[1] Replace h[0] Store dictionary elements .
49. How the jump table is realized ? principle ?
PS: Jump table is a structure that is often asked .
Skip list (skiplist) Is an ordered data structure , It maintains multiple pointers to other nodes in each node , So as to achieve the purpose of fast access to nodes .

Why use jump tables ?
First , because zset To support random insertion and deletion , So it It is not appropriate to use arrays to implement , On the sorting problem , It's easy for us to think of Red and black trees / Balance tree This kind of tree structure , Why? Redis Without such structures ?
- Performance considerations : In the case of high concurrency , The tree structure needs to perform something similar to rebalance This may involve the operation of the whole tree , Relatively speaking, the change of jump table only involves local ;
- Implementation considerations : With the same complexity as a red black tree , Jump tables are easier to implement , It also looks more intuitive ;
Based on the above considerations ,Redis be based on William Pugh After making some improvements, we adopted Skip list Such a structure .
The essence is to solve the search problem .
How to implement the jump table ?
There are these elements in the node of the jump table :
- layer
Jump table node level Arrays can contain multiple elements , Each element contains a pointer to other nodes , Programs can use these layers to speed up access to other nodes , Generally speaking , The number of layers is more than a month , The faster you can access other nodes . - Every time you create a new jump table node , The program is based on the power law , Randomly generate an interval between 1 and 32 The value between is taken as level Size of array , This is the size of the layer “ Height ”
- Forward pointer
Each layer has a forward pointer to the end of the table (level[i].forward attribute ), Used to access nodes from header to footer . - Let's look at the jump table from the head to the end , Traverse the path of all nodes :
- span
The span of the layer is used to record the distance between two nodes . Span is used to calculate rankings (rank) Of : In the process of finding a node , Add up the spans of all the layers visited along the way , The result is the ranking of the target node in the jump table . - For example, find , The score is 3.0、 Member objects are o3 The nodes of , The level of experience along the way : The search process only goes through one layer , And the span of the layer is 3, So the ranking of the target node in the jump table is 3.
- Scores and members
The score of the node (score attribute ) It's a double Floating point number of type , All nodes in the jump table are sorted according to the score from small to large . - Member object of node (obj attribute ) It's a pointer , It points to a string object , The string object holds this SDS value .
50. Compress the list to understand ?
The compressed list is Redis To save memory And a data structure used , It is a sequential data structure composed of a series of special coded continuous memory .
A compressed list can contain any number of nodes (entry), Each node can hold a byte array or an integer value .

The compressed list consists of these parts :
- zlbyttes: Record the number of bytes of memory occupied by the entire compressed list
- zltail: Record how many bytes from the end node of the compressed list to the starting address of the compressed list
- zllen: Record the number of nodes contained in the compressed list
- entryX: List nodes
- zlend: Used to mark the end of a compressed list

51. Quick list quicklist Understand? ?
Redis Earlier versions store list The list data structure uses compressed lists ziplist And ordinary two-way linked list linkedlist, That is to say, when there are few elements, use ziplist, Use when there are many elements linkedlist.
But considering that the additional space of the linked list is relatively high ,prev and next The hands are going to take up 16 Bytes (64 Bit operating system occupation 8 Bytes ), In addition, the memory of each node is allocated separately , Will fragment the furniture memory , Affect memory management efficiency .
later Redis The new version (3.2) The list data structure has been transformed , Use quicklist Instead of ziplist and linkedlist,quicklist It is a new data structure that comprehensively considers the time efficiency and space efficiency .
quicklist from list and ziplist Combined , It is a result of ziplist A two-way linked list that acts as a node .

Other questions
52. If Redis There are 1 One hundred million key, Among them is 10w individual key It starts with a fixed known prefix , How to find them all ?
Use keys The command can scan out the key list . But be careful keys Instructions can cause threads to block for a period of time , Online services will pause , Until the command is executed , Service can be restored . It can be used at this time scan Instructions ,scan The instruction can extract the specified pattern without blocking key list , But there is a certain probability of repetition , In the client to do a duplicate can , But the overall time spent will be more than the direct use of keys Commander .
If this article helps you , Don't forget to give me a 3 even , give the thumbs-up , forward , Comment on ,
I'll see you next time ! Learn more JAVA Knowledge and skills ( Get the original ), Follow up with private bloggers (666)
边栏推荐
- Redis之哨兵模式
- QML control type: menu
- 软件负载均衡和硬件负载均衡的选择
- One article read, DDD landing database design practice
- Mapreduce实例(五):二次排序
- Mapreduce实例(十):ChainMapReduce
- Full stack development of quartz distributed timed task scheduling cluster
- Global and Chinese market for annunciator panels 2022-2028: Research Report on technology, participants, trends, market size and share
- 基于B/S的医院管理住院系统的研究与实现(附:源码 论文 sql文件)
- MapReduce instance (V): secondary sorting
猜你喜欢
Design and implementation of online shopping system based on Web (attached: source code paper SQL file)
基于B/S的医院管理住院系统的研究与实现(附:源码 论文 sql文件)
基于WEB的网上购物系统的设计与实现(附:源码 论文 sql文件)
Redis之哨兵模式

The five basic data structures of redis are in-depth and application scenarios

Reids之删除策略
Sentinel mode of redis
Compilation of libwebsocket
解决小文件处过多

运维,放过监控-也放过自己吧
随机推荐
Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"
[Chongqing Guangdong education] reference materials for nine lectures on the essence of Marxist Philosophy in Wuhan University
[deep learning] semantic segmentation: thesis reading (neurips 2021) maskformer: per pixel classification is not all you need
[Yu Yue education] reference materials of power electronics technology of Jiangxi University of science and technology
Global and Chinese market of appointment reminder software 2022-2028: Research Report on technology, participants, trends, market size and share
Redis之哨兵模式
基于B/S的影视创作论坛的设计与实现(附:源码 论文 sql文件 项目部署教程)
Lua script of redis
[Yu Yue education] Wuhan University of science and technology securities investment reference
一文读懂,DDD落地数据库设计实战
CAP理论
Basic usage of xargs command
[Yu Yue education] reference materials of complex variable function and integral transformation of Shenyang University of Technology
Global and Chinese market of linear regulators 2022-2028: Research Report on technology, participants, trends, market size and share
一大波開源小抄來襲
六月刷题01——数组
Redis之Geospatial
Mapreduce实例(八):Map端join
Global and Chinese markets of SERS substrates 2022-2028: Research Report on technology, participants, trends, market size and share
[deep learning] semantic segmentation - source code summary