当前位置:网站首页>[deep learning] semantic segmentation: paper reading: (CVPR 2022) mpvit (cnn+transformer): multipath visual transformer for dense prediction
[deep learning] semantic segmentation: paper reading: (CVPR 2022) mpvit (cnn+transformer): multipath visual transformer for dense prediction
2022-07-06 09:30:00 【sky_ Zhe】
Here's the catalog title
0 details
The paper :MPViT : Multi-Path Vision Transformer for Dense Prediction
Code : Code
Note reference :
ppt Summary
A detailed version
A detailed version 2
1 Abstract
For tasks :
Intensive computer vision tasks ( For example, object detection and segmentation ) Effective multi-scale feature representation is needed , To detect or classify objects or areas with different sizes .
In the field of semantic segmentation , There are objects of different scales , At the same time, the requirement of edge segmentation is accurate to the pixel level .
VIT for dense predictions:
Vision Transformer(ViT) A simple multi-stage structure is constructed ( That is, fine to rough ), Used to use single scale patch Multiscale representation of . However ViT The variant focuses on reducing the quadratic complexity of self attention , Less attention is paid to building effective multi-scale representation .
MPVIT summary :
- Different from the existing Transformer Perspective , Explore Multiscale path embedding And multi-path structure , Put forward Multi-path Vision Transformer(MPViT).
Therefore, the author of this paper focuses on the multi-scale and multi-path of the image , adopt The image is divided into blocks at different scales and their multi-path structure , Improved image segmentation Transformer Accuracy of .
effect :
MPVit The image can be divided into multiple scales at the same time , Combined with the well-designed serialization module ( The purpose is Transform sequences of different scales into vectors of the same length ), Build a parallel multi-path structure , It realizes the simultaneous use of different scales of the image .
The process :
By using overlapping convolutional patch embedding Flatten it into different sizes token, Adjust the filling of convolution properly / Features with the same sequence length are generated after the stride . Embed multiple sizes at the same time patch features .
then , Will be different scales of Token Enter... Independently through multiple paths Transformer encoders, And aggregate the generated features , Thus, fine and rough feature representation can be realized at the same feature level .
stay Feature aggregation In the step , Introduced a global-to-local feature interaction(GLI) The process , This process Combine convolution local features with Transformer Connect the global features of , At the same time, the local connectivity and Transformer Global context for .
2 Main work
- A method with Multi-scale embedding method of multi-path structure , It is used to represent the fine and rough features of intensive prediction tasks at the same time .
- It introduces Global to local feature interaction (GLI), At the same time, using the local connectivity of convolution and Transformer To represent features in a global context .
- Performance is better than the most advanced vit, At the same time, there are fewer parameters and fewer operations .
3 Network structure
First of all, do the input image Convolution feature extraction ,
Then it is mainly divided into four Transformer Stage , As shown in the left column ,
The middle column is the expansion analysis diagram of two small blocks in each stage ,
The right column is for the multipath module Transformer( Including local convolution ) And the diagram of the global information module .
ViT Use single scale patch embedding And single path transformer Encoder
The process :
MPViT By overlapping convolution, features of the same size are compared with features of different sizes patch While embedding .
Multiscale patch The embedded , Flatten it into different sizes by overlapping convolution token, Adjust the filling of convolution properly / Features with the same sequence length are generated after the stride .
then , From different scales token It is sent to Transformer Encoding , Perform global self-care .
Generated features are then aggregated , Thus, fine and rough feature representation can be achieved at the same feature level .
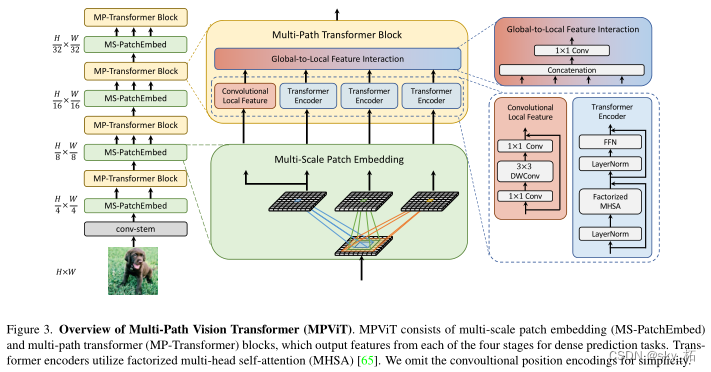
The goal is to explore A powerful backbone network for intensive forecasting , Therefore, a multi-level architecture is built .
say concretely , A four stage feature hierarchy is constructed , Used to generate feature maps of different scales .
They output intensive prediction tasks in four stages , At each stage, the author comments on the proposed Multi-scale Patch Embedding(MS-PatchEmbed) and Multi-path Transformer(MP-Transformer) Stack blocks .
because The multi-level architecture has higher resolution Characteristics , So it essentially requires more computation .
therefore , Because of its linear complexity , We used for the whole model including Factorzed Self attention Of Transformer( Factored bull self attention ) Encoder .
3.1 Conv-stem
This module consists of two 3×3 Convolution composition , The feature extraction and scale reduction of the picture can be carried out without losing significant information
The input image size is :H×W×3,
Two layer convolution : Using two 3×3 Convolution of , The channels are C2/2,C2,stride by 2,
Output image : The size of the generated feature is H/4×W/4×C2, among C2 by stage 2 Channel size .
explain :
1. After every convolution is Batch Normalization And a Hardswish Activation function .
2. from stage 2 To stage 5, At each stage of the proposed Multi-scale Patch Embedding(MS-PatchEmbed) and Multi-path Transformer(MP-Transformer) Stack blocks .
3.2 Multi-Scale Patch Embedding
Multiscale Patch Embedding The structure is as follows , For input characteristic graph , Convolution kernels of different sizes are used to obtain characteristic information of different scales ( The paper is written like this , But the convolution kernel in the source code is 3), In order to reduce the parameters , Use 3x3 The convolution kernel is superimposed to increase the receptive field to 5x5、7x7 Receptive field of convolution nucleus , At the same time, the depth separable convolution is used to reduce the parameters .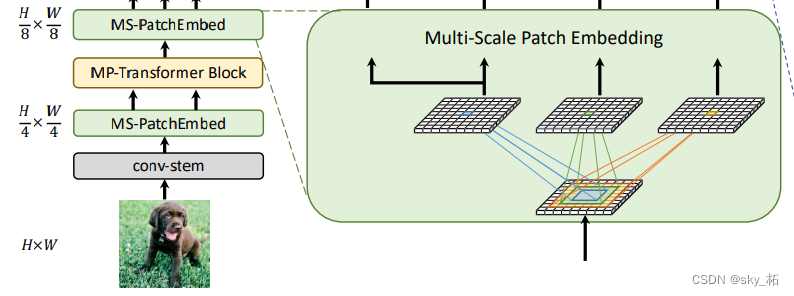
The input image :
stage i The input of X, Through one k×k Of 2D Convolution ,s by stride,p by padding.
Output Of token map F The height and width of the are as follows :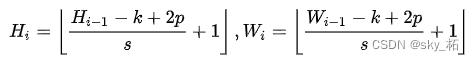
By changing stride and padding To adjust token The sequence length of , That is, different block sizes can have the same size output .
therefore , We Parallel convolution block embedding layers with different core sizes are constructed , For example, the sequence length is the same, but the block size can be 3×3,5×5,7×7
for example , Pictured 1 Shown , Can generate Same sequence length , Different sizes vision token,patch The sizes are 3×3,5×5,7×7.
practice :
- Because stacking the same size convolution can improve the receptive field and have fewer parameters ,
Choose two consecutive 3×3 Convolution layer construction 5×5 Feel the field , Three methods are used 3×3 Convolution construction 7×7 Feel the field - about triple-path structure , Use three consecutive 3×3 Convolution , The channel size is C’,padding by 1, The stride is s, among s When reducing the spatial resolution, it is 2, Otherwise 1.
therefore , Given conv-stem Output X, adopt MS-PatchEmbed You can get the same size as H/s x C/s x C Characteristics of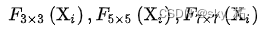
explain : - In order to reduce model parameters and computational overhead , use 3×3 Depth separates the convolution , Include 3×3 Deep convolution and 1×1 Point convolution .
- After every convolution is Batch Normalization And a Hardswish Activation function .
next , Different sizes token embedding features Input to transformer encoder in .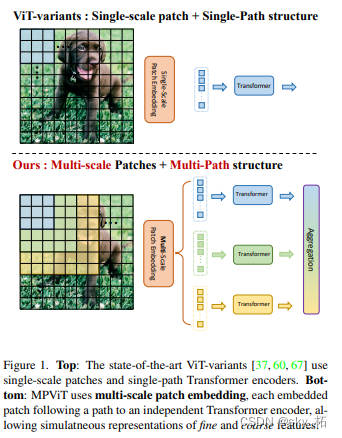
3.3 Multi-path Transformer
reason :
Transformer Medium self-attention Can capture long-term dependencies ( That is, the global context ), But it is likely to ignore every patch Structural information and local relations in .
contrary ,cnn We can use the local connectivity in translation invariance , bring CNN When classifying visual objects , More dependent on texture , Not shape .
therefore ,MPViT In a complementary way CNN And Transformer Combine .
form :
The following multipath Transformer And local feature convolution , above Global-to-Local Feature Interaction.
Carry out self attention in the feature of multi-path ( Local convolution ) After calculation and global context information interaction , All features will make a Concat After activating the function, enter the next stage .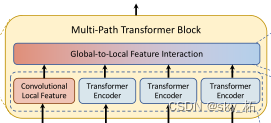
3.3.1 Multipath Transformer And local feature convolution
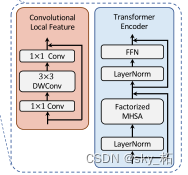
Transformer We can pay attention to the long-distance Correlation , However, convolution network can better extract the local context features of the image , Therefore, the author adds these two complementary operations at the same time , Realize this part .
- Transformer
Because the author uses self attention in each image block , And there are multiple paths , Therefore, in order to reduce the calculation pressure , The author used CoaT The effective factor decomposition self attention ( Reduce complexity to linear ):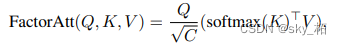
- CNN
To represent local features L, A depthwise residual bottleneck block, Include 1×1 Convolution 、3×3 Deep convolution and 1×1 Convolution and residual connection .
In three Transformer There is a convolution operation on the left side of the module , In fact, it is through the locality of convolution , Introduce the local context of the image into the model , These contextual information can make up for Transformer Insufficient understanding of local semantics .
CoaT Factor decomposition self attention
original transformer in attention Calculation method of :
One query to n individual key - value pair , This query With everyone key - value pair Do inner product , Will produce n A similarity value . Pass in softmax obtain n Nonnegative 、 Sum for 1 The weight value of .
output in value The weight of = Inquire about query And corresponding key The similarity
It is usually realized by inner product , Used to measure each key For each query Impact size ofhold softmax The weight value obtained And value matrix V Multiply obtain attention Output .
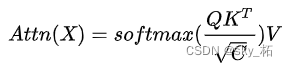
N、C respectively tokens Quantity and sum embedding dimension .
Factorized Attention Mechanism:
- In the original calculation attention In the process of , The space complexity is O(NN), The time complexity is O(NN*C),
- To reduce complexity , Be similar to LambdaNet In the practice ( Sum with an identity function softmax Attention decomposition mechanism :), take attention The method of is changed to the following form
- By using 2 Function to decompose it , And calculate the number 2 Matrix multiplication (key and value) To approximate softmax attention map:
- In order to normalize the effect, the scale factor Under the root c One third is added back , With better performance .
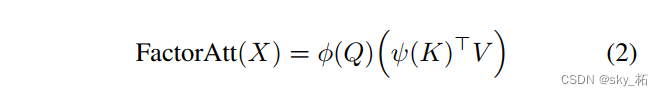
First, the spatial complexity becomes O(NC), Time complexity becomes O(NCC),
Note the reason for the decrease in the amount of calculation here :
MS Patch Embedding The output feature map has high resolution , therefore N Far greater than C. because N>>C, So the complexity is reduced to the original C/N times .
On the other hand, we are calculating the original attention It can be clearly explained attention Is the similarity between the current location and other locations ,
But in factor attn The calculation process of is not very easy to explain , And the inner product process is lost . although FactorAttn Not right attn Direct approximation of , But it is also a generalized attention mechanism query,key and value
Depth separates the convolution
Conventional convolution operation
- Every channel Images and filter Do convolution , Then merge each channel .
- For one 5×5 Pixels 、 Three channels (shape by 5×5×3), after 3×3 The convolution layer of the convolution kernel ( Suppose the number of output channels is 4, Then convolution kernel shape by 3×3×3×4, Final output 4 individual Feature Map, If there is same padding Then the size is the same as the input layer (5×5), If not, the dimension becomes 3×3
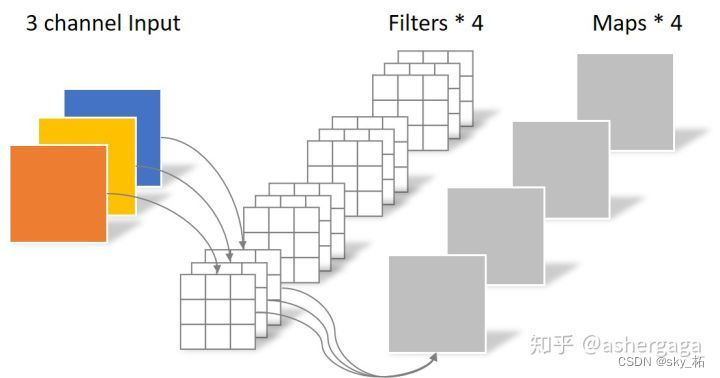
The convolution layer consists of 4 individual Filter, Every Filter Contains 3 individual Kernel, Every Kernel The size is 3×3.
Therefore, the number of parameters of the convolution layer can be calculated by the following formula :
N_std = 4 × 3 × 3 × 3 = 108
DWconv- Depth separates the convolution -Depthwise Separable Convolution
It is a network composed of a two-part convolution .
The main purpose is to reduce the amount of convolution parameters .
The first part is depthwise conv , A convolution of sub channels Each convolution kernel corresponds to input Every channel of
The second part is pointwise conv, It makes the first part independent featuremap The combination generates a newChannel by channel convolution
Different convolution kernels are applied to in_channels Every channel of the
Depthwise Convolution Of A convolution kernel is responsible for a channel , A channel is convoluted by only one convolution kernel
a sheet 5×5 Pixels 、 Three channel color input picture (shape by 5×5×3),
Depthwise Convolution First, after the first convolution operation ,DW Completely in a two-dimensional plane . The number of convolution kernels is the same as the number of channels in the upper layer ( The channel corresponds to the convolution kernel one by one ).
So a three channel image is generated after operation 3 individual Feature map( If there is same padding Then the size is the same as that of the input layer 5×5), As shown in the figure below .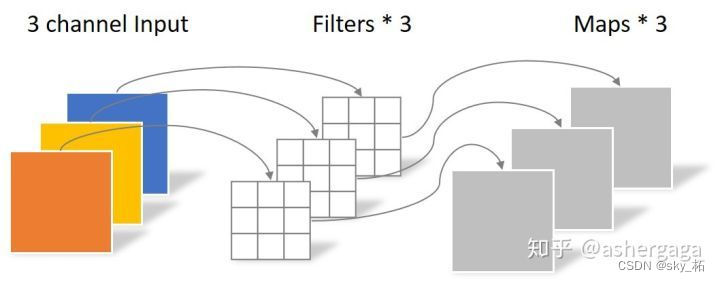
among One Filter Contains only one file of size 3×3 Of Kernel, The number of parameters of the convolution part is calculated as follows :
N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution After completion Feature map The number is the same as the number of channels in the input layer , Can't expand Feature map.
And this operation convolutes each channel of the input layer independently **, There is no effective use of different channels in the same spatial location feature Information .**
( Because the characteristics of each layer above are separated There is no effective use of the effective information of different layers in the same spatial location , So there is the second part )
Therefore need Pointwise Convolution To separate these Feature map Combine to create a new Feature map
- Point by point convolution
Pointwise Convolution The operation of is very similar to the conventional convolution operation , The size of its convolution kernel is 1×1×M,M Is the number of channels on the upper layer .
So the convolution operation here will Take the next step map Weighted combination in depth direction , Generate a new Feature map. There are several convolution kernels and there are several outputs Feature map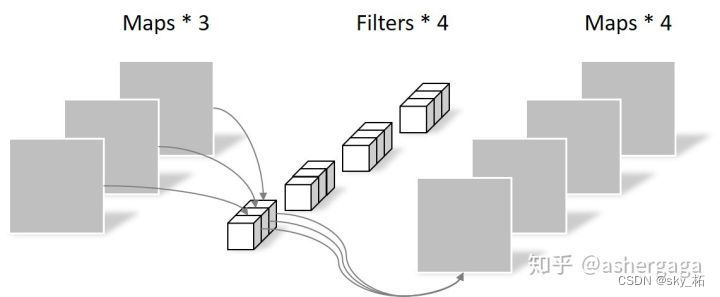
Because of the use of 1×1 Convolution mode , The number of parameters involved in convolution in this step can be calculated as :
N_pointwise = 1 × 1 × 3 × 4 = 12
after Pointwise Convolution after , Also output 4 Zhang Feature map, The output dimension is the same as that of conventional convolution
Parameter comparison
Take a look back. , The number of parameters of conventional convolution is :
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution The parameters of are obtained by adding the two parts :
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
Same input , Also get 4 Zhang Feature map,Separable Convolution The number of parameters is about 1/3.
therefore , On the premise of the same parameter quantity , use Separable Convolution The number of neural network layers can be deeper .
3.3.2Global-to-Local Feature Interaction

effect
Aggregate local features and global features :
Perform by concatenation 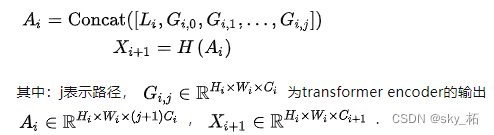
We have made a Concat And carried on 1×1 Convolution (H(·) It is a function of learning and feature interaction ), At the same time, the module inputs Transformer And the convolution operation of extracting local context , Therefore, it can be considered as the feature fusion of the global and local semantics of the image extracted at this stage , Make full use of the information of the image .
4 experiment - Semantic segmentation
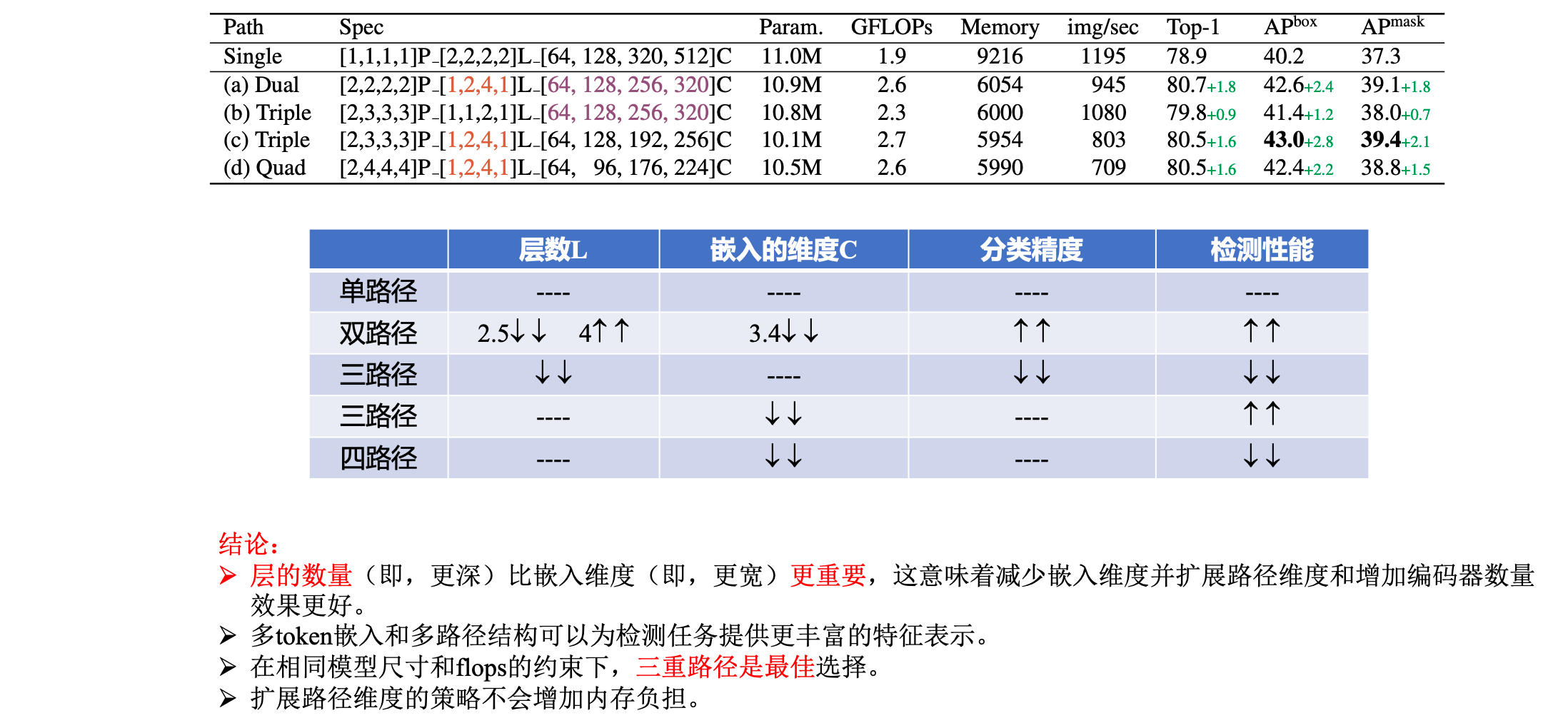
Increasing the number of paths requires reducing the number of channels C Or the number of layers L( namely ,transformer encoder The number of ).
By reducing C instead of L, From single path ( namely CoaT-Lite baseline) Extended to triple-path. In ablation studies , Verified the reduction C Less than L Get better performance ( See table 5).
because stage2 The feature resolution is high , This leads to higher calculation cost , The author in stage2 Lieutenant general triple-path The number of paths of the model is set to 2. from stage3 Start , The three path model has 3 Paths .
triple-path The model shows better performance in intensive prediction tasks . therefore , Based on triple-path Structural MPViT Model
Parameter setting :
Use upernet As a segmentation method , And will ImageNet-1k In the process of the training MPViTs Integrated into the supernet in .
Next , For a fair comparison , Training models 160k Sub iteration , Batch size is 16, Use AdamW[38] Optimizer , The learning rate is 6e-5, The weight decays to 0.01.
Use standard single scale protocols to report performance . Use mmseg[11] Library implementation mpvit
result :
And others Swin-T、Focal-T and XCiT-S12/16 comparison ,mpvits Performance of (48.3%) Higher , Respectively +3.8%、+2.5% and +2.4%. Interestingly ,mpvit It also exceeds the larger models , Such as Swin-S/B, XCiT-S24/16, -M24/16, -S24/8 and Focal-S. Besides ,mpvitb Performance is better than recent ( And bigger )SOTA transformer Focal-B[67]. These results suggest that ,MPViT Its multi-scale embedding and multi-path structure make it have diverse feature representation capabilities 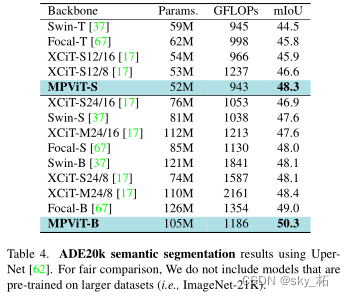
The figure above shows ADE20K Performance comparison on split tasks , You can see from it :
- MPViT Superior to other similar size ViT programme ;
- MPViT-S With 48.3% The index of has greatly surpassed Swin-T、Focal-T as well as XCiT-S12/16;
- MPViT-B With 50.3% The index of exceeds the recent SOTA programme Focal-B.
5 summary
The author mainly made the following contributions :
- The use of multi-scale information is realized through multi-path parallel design
- adopt Deep convolution operation realizes the utilization of global context (Mask2Former It also has the same structure )
- The effect of multi-scale and multi-path model under different scales and number of paths is explored through comparative experiments
边栏推荐
- Redis之主从复制
- Global and Chinese market of appointment reminder software 2022-2028: Research Report on technology, participants, trends, market size and share
- Heap (priority queue) topic
- Redis之哨兵模式
- AcWing 2456. 记事本
- 基于B/S的网上零食销售系统的设计与实现(附:源码 论文 Sql文件)
- 美团二面:为什么 Redis 会有哨兵?
- Pytest's collection use case rules and running specified use cases
- Global and Chinese market for annunciator panels 2022-2028: Research Report on technology, participants, trends, market size and share
- Advance Computer Network Review(1)——FatTree
猜你喜欢
DCDC power ripple test
![[oc]- < getting started with UI> -- common controls - prompt dialog box and wait for the prompt (circle)](/img/af/a44c2845c254e4f48abde013344c2b.png)
[oc]- < getting started with UI> -- common controls - prompt dialog box and wait for the prompt (circle)
Parameterization of postman
基于B/S的网上零食销售系统的设计与实现(附:源码 论文 Sql文件)
Improved deep embedded clustering with local structure preservation (Idec)
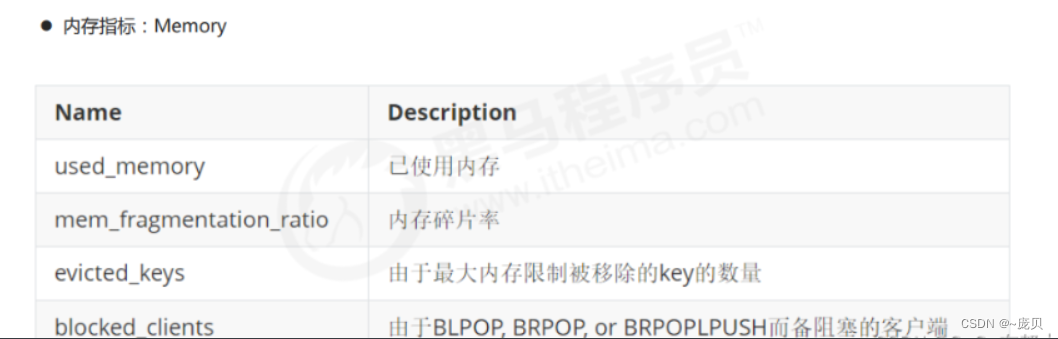
Redis之性能指标、监控方式
![[OC foundation framework] - string and date and time >](/img/75/e20064fd0066810135771a01f54360.png)
[OC foundation framework] - string and date and time >
![[OC foundation framework] - [set array]](/img/b5/5e49ab9d026c60816f90f0c47b2ad8.png)
[OC foundation framework] - [set array]
Design and implementation of online snack sales system based on b/s (attached: source code paper SQL file)
Design and implementation of online shopping system based on Web (attached: source code paper SQL file)
随机推荐
What is an R-value reference and what is the difference between it and an l-value?
I-BERT
Global and Chinese markets of SERS substrates 2022-2028: Research Report on technology, participants, trends, market size and share
The order of include header files and the difference between double quotation marks "and angle brackets < >
Kratos ares microservice framework (II)
Redis之哨兵模式
Meituan Er Mian: why does redis have sentinels?
五层网络体系结构
go-redis之初始化連接
Master slave replication of redis
发生OOM了,你知道是什么原因吗,又该怎么解决呢?
基于B/S的影视创作论坛的设计与实现(附:源码 论文 sql文件 项目部署教程)
Seven layer network architecture
[three storage methods of graph] just use adjacency matrix to go out
Kratos战神微服务框架(二)
Redis之性能指标、监控方式
Kratos ares microservice framework (III)
Selenium+Pytest自动化测试框架实战(下)
Redis core configuration
Redis之持久化实操(Linux版)