当前位置:网站首页>[three storage methods of graph] just use adjacency matrix to go out
[three storage methods of graph] just use adjacency matrix to go out
2022-07-06 09:09:00 【Easenyang】
Preface :
When storing graphs , Most of us think of using adjacency matrix at the first time , But sometimes it may not solve our problems well , We should consider using other storage methods .
Figure of the storage :
One 、 sketch
All operations on graphs need to be based on a stored graph , The storage structure of the graph must be an orderly structure , It can make the program locate nodes quickly u u u and v v v The edge of ( u u u, v v v), We generally use 3 A data structure storage diagram :
Adjacency matrix 、 Adjacency list and Chain forward star
Two 、 storage
1. Adjacency matrix :
Adjacency matrix storage is based on two-dimensional array :
int[][] g = new int[N+1][N+1];
use g[i][j] Represents a node u u u To v v v A weight ,g[i][j] = INF Express i i i and j j j There's no limit
For undirected graphs :g[i][j] = g[j][i];
For digraphs :g[i][j] != g[j][i];
for instance :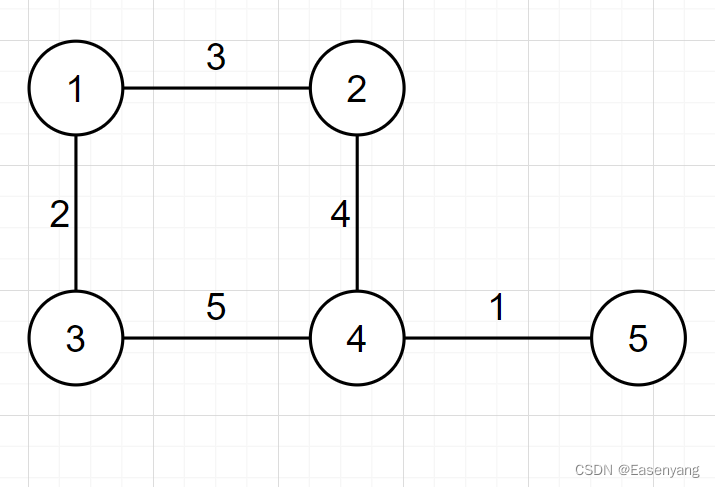
For the storage of this graph , node 1 and 2 A weight of 3, Order g[1][2] = g[2][1] = 3, node 2 and 5 There's no limit , Order g[2][5] = g[5][2] = INF.
The common practice is to initialize the weights between all nodes as INF, Then update the weights between points according to the graph
advantage :
Suitable for dense map ; The coding is very short ; Storage of opposite sides 、 Inquire about 、 Updating and other operations are fast and simple , It only takes one step to access and modify
shortcoming :
- Storage complexity O ( V 2 ) O(V^2) O(V2) Too high . If used to store sparse graphs , A lot of space will be wasted . For example, the figure above ,5 Nodes ,10 side (g[ i ][ j ] and g[ j ][ i ] Count two sides ), but g[5][5] The space of is 25. When the node of the graph V=10000 when , Space for 100MB, More than common ACM Space limitation of competition questions , The graph of onemillion points is ACM Questions are very common
- In general , Cannot store duplicate edges .( u u u, v v v) There may be two or more sides between , Their weights are different , It can't be merged
2. Adjacency list
For large-scale sparse graphs , Generally, adjacency tables are used to store . In short, store the adjacent edges of each point , In this way, the graph can be stored .
We can define one edge Class to represent edges , And define 3 A variable from, to, w. Respectively representing the side The starting point 、 End and A weight .
class edge {
int from, to, w; // The starting point of the edge 、 End point and weight
public edge(int a, int b, int c) {
// Construction method
this.from = a;
this.to = b;
this.w = c;
}
}
Then define a set to store the adjacent edges of each point . It should be noted that ,c++ Dynamic arrays can be used in vector Store adjacent edges
struct edge{
int from, to, w;// The starting point , End , A weight
edge(int a, int b, int c){
from=a; to=b; w=c;
}
};
vector<edge> e[N];// Dynamic array stores adjacent edges
and Java You cannot create generic arrays directly :ArrayList<edge>[] lists = new ArrayList<edge>[N]; This is wrong . We can consider the way of storing sets :
List<List<edge>> list = new ArrayList<>();
for (int i = 0; i <= N; i++) {
list.add(new ArrayList<>());// First assign an empty set of adjacent edges to each point
}
To visit i The adjacent side of the point , Can pass list.get(i) return i Set of adjacent edges of points
for instance :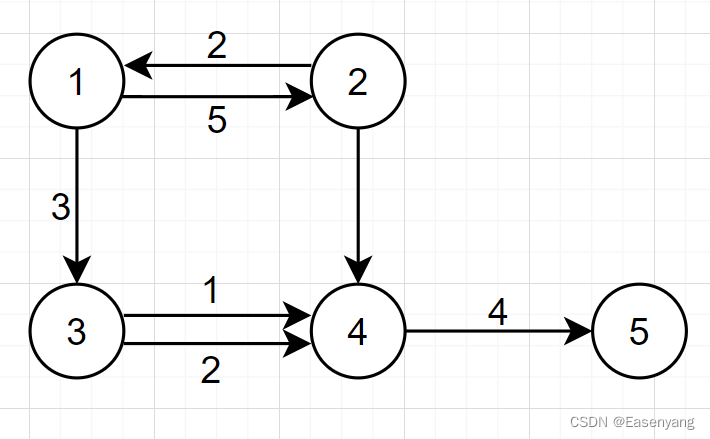
For the storage of this graph , Double edge , But it doesn't affect , Because we operate the side , node 3 and 4 The two sides of are respectively new Two edge object , Then add the adjacent edge set of the corresponding node :
edge e1 = new edge(3,4,1);
edge e2 = new edge(3,4,2)
list.get(3).add(e1); // First obtain the adjacent edge set of the corresponding node , Then put the adjacent edges into the set
list.get(3).add(e2)
The storage of other edges is the same
advantage :
High storage efficiency , Just need a space proportional to the number of sides , The storage complexity is O ( V + E ) O(V + E) O(V+E), Almost the optimal complexity , And it can Store heavy edges
shortcoming :
Programming is more troublesome than adjacency matrix , Access and modification are also slow
3. Chain forward star :
Using adjacency table to store graph is very space saving , General large pictures are also enough , If space is extremely tight , We can consider a more compact way of storing pictures : Chain forward star .
It is an improvement of adjacency table , Don't use sets ( Or an array ) To store all adjacent edges of a point , Directly store an adjacent side , Then the adjacent edge points to the next adjacent edge , By analogy . Its implementation can be based on several one-dimensional arrays .
- Store all points The first adjacent side Array of :
int[] head = new int[N+1](N Is the number of points ) - Store the current side Next adjacent side Array of :
int[] next = new int[M+1](M It's the number of sides ) - Store the current side is To which point Array of :
int[] e = new int[M+1] - Store side A weight Array of :
int[] w = new int[M+1]
for instance :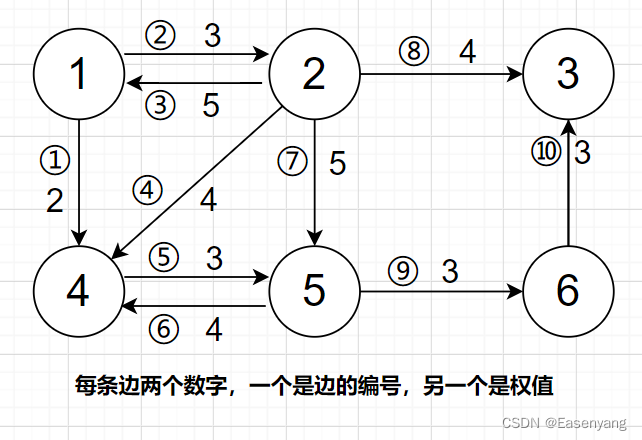
The storage of each array is as follows :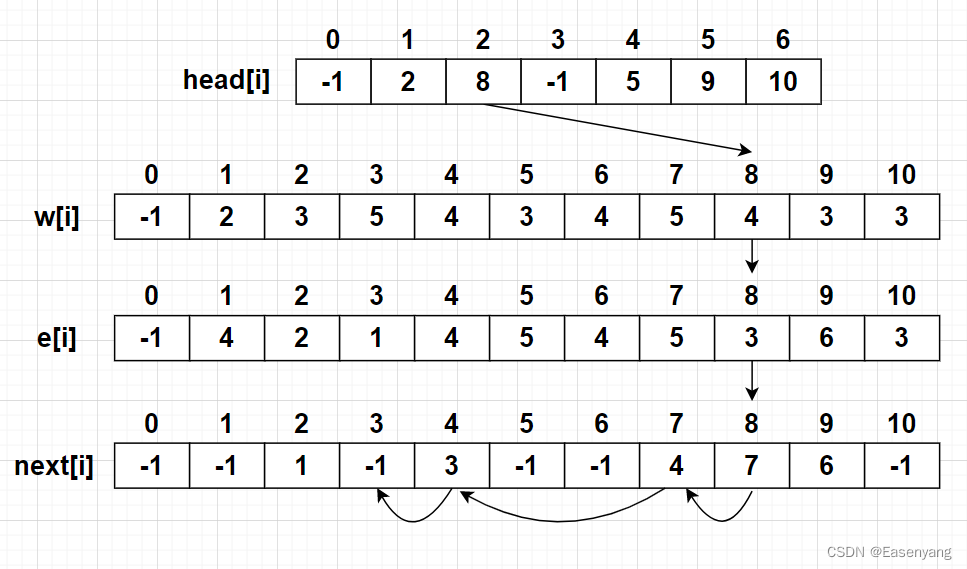
Analysis node 2 The storage ,head[2] = 8 Express 2 The first adjacent side of node No. is 8 Border No ,e[8] = 3 Express 8 The point from the No. side is 3,next[8] = 7 Express 8 The adjacent side of side number is 7, Then look for it 7 The adjacent side of the number side , And so on , Until one side has no adjacent side , namely next[i]=-1. Finally find the node 2 Next to ( 8 , 7 , 4 , 3 ) (8,7,4,3) (8,7,4,3), adopt w[8],w[7],w[4],w[3], You can find the weight of its adjacent edge head[i] = -1 Express i The node has no edge to other points , That is, you can't go to any point next[i] = -1 Express i The next adjacent edge does not exist
initialization :
Arrays.fill(head, -1); // The first adjacent edge of each initial point is -1
Arrays.fill(w, -1); // Initialize the weight of each side to -1
Arrays.fill(e, -1); // Initialize the end point of each side to -1
Arrays.fill(next, -1); // Initialize the next adjacent edge of each edge to -1
Store an edge Code for :
public static void add(int u, int v, int k) {
//u Starting point ,v It's the end ,k Is the weight
//cnt Which side is the record currently stored
w[cnt] = k; // Store the weight of the edge
e[cnt] = v; // Set the ending point in front as v
ne[cnt] = h[u]; // Update the next adjacent edge of the current edge to u Click the old current adjacent edge
h[u] = cnt++; // to update u The first adjacent edge of the point
}
With the help of nodes 2 Of head[2] Change to understand code :
head[2]: -1、3、4、7、8, Final direction 8 Border No , And then we can go through next[8] Go find 7 No. adjacent side , Re pass next[7] Go find 4 No. adjacent side , next next[4] find 3 No. adjacent side ,next[3] = -1, It means there is no adjacent side .
Look again Visit all adjacent edges of a point Code for :( Suppose the access node 2)
for (int j = head[2]; j != -1; j = next[j])
System.out.println(j); //j It's the node 2 An adjacent side number of
With the help of the above idea, we can find the elements of the graph . In this way, the Chain forward star How to store
Chained forward stars have the same advantages and disadvantages as adjacency lists , But it is better than adjacency table in space storage
therefore , Different requirements for graph problems , We should learn to flexibly use the corresponding storage methods , It is necessary to firmly grasp these three storage methods .
If it helps you , Please support the third company , thank you !!!
边栏推荐
- Using C language to complete a simple calculator (function pointer array and callback function)
- BN folding and its quantification
- Computer graduation design PHP Zhiduo online learning platform
- Advanced Computer Network Review(3)——BBR
- Different data-driven code executes the same test scenario
- How to effectively conduct automated testing?
- I-BERT
- LeetCode41——First Missing Positive——hashing in place & swap
- 【文本生成】论文合集推荐丨 斯坦福研究者引入时间控制方法 长文本生成更流畅
- [OC foundation framework] - [set array]
猜你喜欢

Advance Computer Network Review(1)——FatTree

CUDA实现focal_loss
LeetCode:498. 对角线遍历

Opencv+dlib realizes "matching" glasses for Mona Lisa

BMINF的後訓練量化實現

What is MySQL? What is the learning path of MySQL

Improved deep embedded clustering with local structure preservation (Idec)
Cesium draw points, lines, and faces

使用latex导出IEEE文献格式
![[OC]-<UI入门>--常用控件-提示对话框 And 等待提示器(圈)](/img/af/a44c2845c254e4f48abde013344c2b.png)
[OC]-<UI入门>--常用控件-提示对话框 And 等待提示器(圈)
随机推荐
使用latex导出IEEE文献格式
pytorch查看张量占用内存大小
What are the common processes of software stress testing? Professional software test reports issued by companies to share
What is an R-value reference and what is the difference between it and an l-value?
【剑指offer】序列化二叉树
How to intercept the string correctly (for example, intercepting the stock in operation by applying the error information)
Compétences en mémoire des graphiques UML
[OC foundation framework] - string and date and time >
Notes 01
LeetCode:剑指 Offer 48. 最长不含重复字符的子字符串
Pytest's collection use case rules and running specified use cases
随手记01
LeetCode:劍指 Offer 42. 連續子數組的最大和
Cesium draw points, lines, and faces
CUDA implementation of self defined convolution attention operator
Leetcode: Jianzhi offer 04 Search in two-dimensional array
BN折叠及其量化
IJCAI2022论文合集(持续更新中)
SimCLR:NLP中的对比学习
【shell脚本】——归档文件脚本