当前位置:网站首页>MapReduce工作机制
MapReduce工作机制
2022-07-06 09:01:00 【棱镜7】
目录
1. Map Task工作机制
1.1 概述
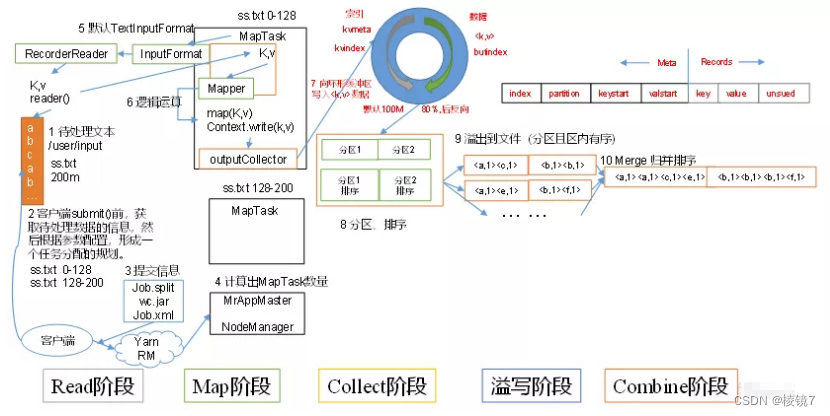
inputFile通过split被切割为多个split文件,通过RecordReader按行读取内容给map函数(自己写的处理逻辑的方法),数据被map处理完之后交给OutputCollect收集器,对其结果key进行分区,每个map task都有一个内存缓冲区(环形缓冲区)存放map的输出结果,当缓冲区达到溢写比时(0.8)需要将缓冲区的数据以一个临时文件的方式溢写到磁盘(将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序),当整个map task结束后再对磁盘中产生的临时文件做合并,生成最终的正式输出文件,然后等待reduce task的拉去。
1.2 详细步骤
- 读取数据组件 InputFormat (默认 TextInputFormat) 会通过getSplits 方法对输入目录中的文件进行逻辑切片规划得到 block,有多少个 block 就对应启动多少个 MapTask。
- 将输入文件切分为 block 之后,由 RecordReader 对象 (默认是LineRecordReader) 进行读取,以 \n 作为分隔符, 读取一行数据, 返回<key,value>, Key 表示每行首字符偏移值,Value 表示这一行文本内容
- 读取 block 返回 <key,value>, 进入用户自己继承的 Mapper 类中,执
行用户重写的 map 函数,RecordReader 读取一行这里调用一次 - Mapper 逻辑结束之后,将 Mapper 的每条结果通过 context.write 进行
collect 数据收集。在 collect 中,会先对其进行分区处理,默认使用
HashPartitioner。 - 接下来,会将数据写入内存,内存中这片区域叫做环形缓冲区(默认 100M),缓冲区的作用是 批量收集 Mapper 结果,减少磁盘 IO 的影响。我们的Key/Value 对以及 Partition 的结果都会被写入缓冲区。当然,写入之前,Key 与 Value 值都会被序列化成字节数组
- 当环形缓冲区的数据达到溢写比列(默认 0.8),也就是 80M 时,溢写线程启动,需要对这 80MB 空间内的 Key 做排序 (Sort)。排序是 MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
- 合并溢写文件,每次溢写会在磁盘上生成一个临时文件 (写之前判断是否有 Combiner),如果 Mapper 的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当整个数据处理结束之后开始对磁盘中的临时文件进行 Merge 合并,因为最终的文件只有一个写入磁盘,并且为这个文件提供了一个索引文件,以记录每个 reduce 对应数据的偏移量
Combiner: Mapreduce中的Combiner就是为了避免map任务和reduce任务之间的数据传输⽽设置的,Hadoop允许⽤户针对map task的输出指定⼀个合并函数。即为了减少传输到Reduce中的数据量。它主要是为了削减Mapper的输出从⽽减少⽹络带宽和Reducer之上的负载。
2. Reduce Task工作机制
2.1 详细步骤
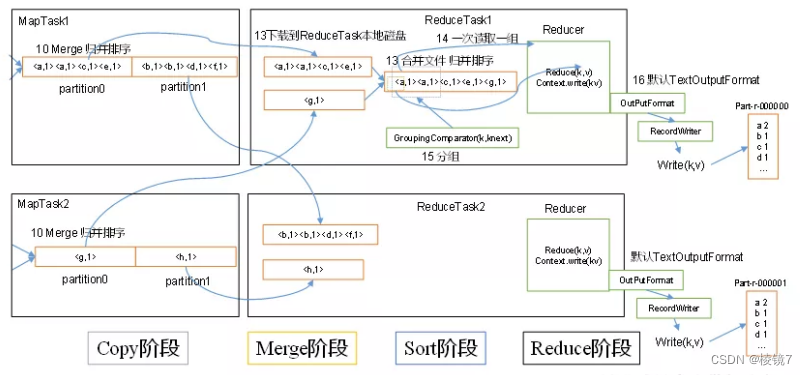
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
3. Shuffle工作机制
shuffle 阶段分为四个步骤:依次为:分区,排序,规约,分组,其中前三个步骤在 map 阶段完成,最后一个步骤在 reduce 阶段完成。
shuffle 是 Mapreduce 的核心,它分布在 Mapreduce 的 map 阶段和 reduce阶段。一般把从 Map 产生输出开始到 Reduce 取得数据作为输入之前的过程称作 shuffle
3.1 Shuffle阶段的数据压缩机制
在 shuffle 阶段,可以看到数据通过大量的拷贝,从 map 阶段输出的数据,都要通过网络拷贝,发送到 reduce 阶段,这一过程中,涉及到大量的网络 IO,如果数据能够进行压缩,那么数据的发送量就会少得多。
hadoop 当中支持的压缩算法:
gzip、bzip2、LZO、LZ4、Snappy,这几种压缩算法综合压缩和解压缩的速率,谷歌的 Snappy 是最优的,一般都选择 Snappy 压缩。
4. 在写MR时,什么情况下可以使用规约
规约(combiner)是不能够影响任务的运行结果的局部汇总,适用于求和类,不适用于求平均值。combiner 和 reducer 的区别在于运行的位置,combiner 是在每一个 maptask 所在的节点运行, Reducer 是接收全局所有 Mapper 的输出结果
边栏推荐
- Intel Distiller工具包-量化实现1
- 自定义卷积注意力算子的CUDA实现
- Global and Chinese markets for modular storage area network (SAN) solutions 2022-2028: Research Report on technology, participants, trends, market size and share
- Advanced Computer Network Review(3)——BBR
- [shell script] - archive file script
- Global and Chinese market of electric pruners 2022-2028: Research Report on technology, participants, trends, market size and share
- Improved deep embedded clustering with local structure preservation (Idec)
- Advanced Computer Network Review(4)——Congestion Control of MPTCP
- 【shell脚本】——归档文件脚本
- 数字人主播618手语带货,便捷2780万名听障人士
猜你喜欢

Redis之核心配置
Advanced Computer Network Review(5)——COPE

Intel distiller Toolkit - Quantitative implementation 1
BN folding and its quantification

Opencv+dlib realizes "matching" glasses for Mona Lisa

Redis之Lua脚本

Redis之连接redis服务命令

requests的深入刨析及封装调用

Post training quantification of bminf
![[oc foundation framework] - < copy object copy >](/img/62/c04eb2736c2184d8826271781ac7e3.png)
[oc foundation framework] - < copy object copy >
随机推荐
Simclr: comparative learning in NLP
【shell脚本】——归档文件脚本
The five basic data structures of redis are in-depth and application scenarios
Global and Chinese market of appointment reminder software 2022-2028: Research Report on technology, participants, trends, market size and share
Redis之连接redis服务命令
IDS cache preheating, avalanche, penetration
Advance Computer Network Review(1)——FatTree
Mathematical modeling 2004b question (transmission problem)
Pytest parameterization some tips you don't know / pytest you don't know
Advanced Computer Network Review(5)——COPE
[three storage methods of graph] just use adjacency matrix to go out
Booking of tourism products in Gansu quadrupled: "green horse" became popular, and one room of B & B around Gansu museum was hard to find
基于B/S的影视创作论坛的设计与实现(附:源码 论文 sql文件 项目部署教程)
BN折叠及其量化
Advanced Computer Network Review(3)——BBR
Kratos战神微服务框架(二)
xargs命令的基本用法
CUDA realizes focal_ loss
[oc]- < getting started with UI> -- learning common controls
go-redis之初始化連接