当前位置:网站首页>MapReduce instance (IV): natural sorting
MapReduce instance (IV): natural sorting
2022-07-06 09:33:00 【Laugh at Fengyun Road】
MR Realization Natural ordering
Hello everyone , I am Fengyun , Welcome to my blog perhaps WeChat official account 【 Laugh at Fengyun Road 】, In the days to come, let's learn about big data related technologies , Work hard together , Meet a better self !
Process analysis
Map、Reduce Tasks Shuffle The process diagram of and sorting is as follows :
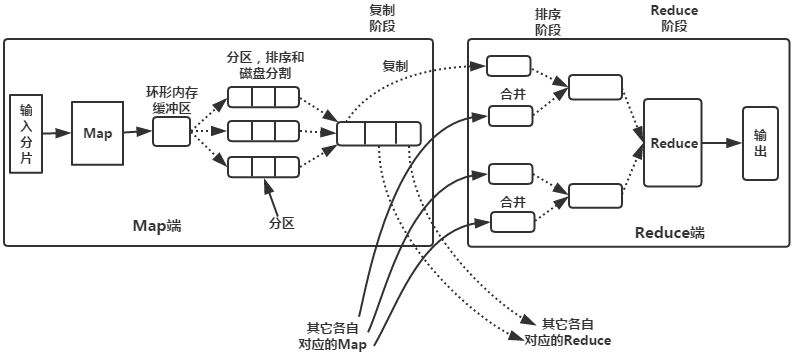
Process analysis :
1.Map End :
(1) Each input slice will have one map Tasks to deal with , By default , With HDFS The size of a piece of ( The default is 64M) For a piece , Of course, we can also set the block size .map The output will be temporarily put in a ring memory buffer ( The size of the buffer defaults to 100M, from io.sort.mb Attribute control ), When the buffer is about to overflow ( The default is buffer size 80%, from io.sort.spill.percent Attribute control ), An overflow file is created in the local file system , Write the data in this buffer to this file .
(2) Before writing to disk , Thread first according to reduce The number of tasks divides the data into the same number of partitions , That's one reduce The task corresponds to the data of a partition . This is done to avoid some reduce The task is assigned to a large amount of data , And some of them reduce The task was assigned very little data , There's not even a data embarrassment . In fact, partitioning is about data hash The process of . then Sort the data in each partition , If you set Combiner, The results after sorting are Combine operation , The goal is to write as little data as possible to disk .
(3) When map When the task outputs the last record , There may be a lot of overflow files , You need to merge these files . In the process of merging, there will be continuous sorting and combine operation , There are two purposes :① Minimize the amount of data written to disk each time .② Minimize the amount of data transmitted over the network in the next replication phase . Finally, it is merged into a partitioned and sorted file . In order to reduce the amount of data transmitted by the network , You can compress the data here , As long as mapred.compress.map.out Set to true That's all right. .
(4) Copy the data in the partition to the corresponding reduce Mission . Someone might ask : How does the data in the partition know its corresponding reduce Which is it ? Actually map The mission has been with his father TaskTracker Keep in contact , and TaskTracker And all the time JobTracker Keep your heart beating . therefore JobTracker The macro information of the whole cluster is saved in . as long as reduce The task is to JobTracker Get the corresponding map The output position is ok Oh. .
Come here ,map End analysis is finished . What is that Shuffle Well ?Shuffle The Chinese meaning is “ Shuffle ”, If we look at it this way : One map Data generated , Result passed hash Process partitions are assigned to different reduce Mission , Is it a process of shuffling data ?
2.Reduce End :
(1)Reduce It will receive different map Data from the mission , And each map The data is all in order . If reduce The amount of data received by the end is quite small , And it is stored directly in memory ( The buffer size is determined by mapred.job.shuffle.input.buffer.percent Attribute control , Represents the percentage of heap space used for this purpose ), If the amount of data exceeds a certain proportion of the buffer size ( from mapred.job.shuffle.merge.percent decision ), Then the data is merged and overflowed to the disk .
(2) As the number of overflow files increases , Background threads will merge them into a larger, ordered file , This is done to save time for later merges . In fact, no matter in map End or end reduce End ,MapReduce It's sort over and over again , Merge operation , Now I finally understand why some people say : The order is hadoop Soul .
(3) During the process of merging, a lot of intermediate files will be produced ( Written to disk ), but MapReduce It will make the data written to the disk as little as possible , also The result of the last merge was not written to disk , It's a direct input to reduce function .
be familiar with MapReduce Everyone knows : The order is MapReduce The natural characteristics of ! When the data reaches reducer Before ,MapReduce The framework has sorted these data by pressing the key . But before you use it , First you need to understand its default collation . It is according to key Value for sorting , If key For encapsulated int by IntWritable type , that MapReduce Match... To the size of the number key Sort , If Key To encapsulate String Of Text type , that MapReduce The characters will be sorted in data dictionary order .
Understand the details , We knew we should use encapsulation int Of Intwritable Type data structure , That is to say map here , Convert the fields to be sorted in the read data into Intwritable type , And then as a key Value of output ( Fields that are not sorted are treated as value).reduce I got <key,value-list> after , Will input key As output key, And according to value-list The number of elements in the determines the number of outputs .
Code writing
stay MapReduce By default, the data is sorted . It is according to key Value for sorting , If key To encapsulate int Of IntWritable type , that MapReduce Will match... According to the size of the number key Sort , If Key To encapsulate String Of Text type , that MapReduce The characters will be sorted in data dictionary order . In this case, we use the first ,key Set to IntWritable type , among MapReduce The procedure is mainly divided into Mapper Part and Reducer part .
Mapper Code
public static class Map extends Mapper<Object,Text,IntWritable,Text>{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
String arr[]=line.split("\t");
num.set(Integer.parseInt(arr[1]));
goods.set(arr[0]);
context.write(num,goods);
}
}
stay map End use Hadoop After the default input method , Will input value Value to use split() Method interception , Convert the number of clicks field to be sorted into IntWritable Type and set to key, goods id Field set to value, And then directly output <key,value>.map Output <key,value> We have to go through shuffle Same process key All that's worth value Gather to form <key,value-list> Later to reduce End .
Reducer Code
public static class Reduce extends Reducer<IntWritable,Text,IntWritable,Text>{
private static IntWritable result= new IntWritable();
// Declare objects result
public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text val:values){
context.write(key,val);
}
}
}
reduce Termination received <key,value-list> after , Will input key Copy directly to the output key, use for Loop traversal value-list And set the elements inside as output value, And then <key,value> Output one by one , according to value-list The number of elements in determines the number of outputs .
Complete code
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class OneSort {
public static class Map extends Mapper<Object , Text , IntWritable,Text >{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
String arr[]=line.split("\t");
num.set(Integer.parseInt(arr[1]));
goods.set(arr[0]);
context.write(num,goods);
}
}
public static class Reduce extends Reducer< IntWritable, Text, IntWritable, Text>{
private static IntWritable result= new IntWritable();
public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text val:values){
context.write(key,val);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
Job job =new Job(conf,"OneSort");
job.setJarByClass(OneSort.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in=new Path("hdfs://localhost:9000/mymapreduce3/in/goods_visit1");
Path out=new Path("hdfs://localhost:9000/mymapreduce3/out");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
-------------- end ----------------
WeChat official account : Below scan QR code or Search for Laugh at Fengyun Road Focus on 
边栏推荐
- Leetcode problem solving 2.1.1
- 小白带你重游Spark生态圈!
- Kratos战神微服务框架(二)
- Pytest parameterization some tips you don't know / pytest you don't know
- [Chongqing Guangdong education] reference materials for nine lectures on the essence of Marxist Philosophy in Wuhan University
- Design and implementation of online shopping system based on Web (attached: source code paper SQL file)
- 为拿 Offer,“闭关修炼,相信努力必成大器
- Design and implementation of film and television creation forum based on b/s (attached: source code paper SQL file project deployment tutorial)
- Different data-driven code executes the same test scenario
- CAP理论
猜你喜欢

Opencv+dlib realizes "matching" glasses for Mona Lisa
基于B/S的网上零食销售系统的设计与实现(附:源码 论文 Sql文件)

Different data-driven code executes the same test scenario

Advance Computer Network Review(1)——FatTree

Redis core configuration
![[shell script] - archive file script](/img/50/1bef6576902890dfd5771500414876.png)
[shell script] - archive file script
Mapreduce实例(五):二次排序
Intel distiller Toolkit - Quantitative implementation 3
leetcode-14. Longest common prefix JS longitudinal scanning method
Nacos installation and service registration
随机推荐
[Yu Yue education] reference materials of power electronics technology of Jiangxi University of science and technology
Once you change the test steps, write all the code. Why not try yaml to realize data-driven?
Advanced Computer Network Review(5)——COPE
发生OOM了,你知道是什么原因吗,又该怎么解决呢?
英雄联盟轮播图手动轮播
Intel distiller Toolkit - Quantitative implementation 3
Go redis initialization connection
Global and Chinese market of electronic tubes 2022-2028: Research Report on technology, participants, trends, market size and share
Appears when importing MySQL
英雄联盟轮播图自动轮播
The order of include header files and the difference between double quotation marks "and angle brackets < >
Global and Chinese markets for modular storage area network (SAN) solutions 2022-2028: Research Report on technology, participants, trends, market size and share
Redis之Geospatial
Global and Chinese markets of SERS substrates 2022-2028: Research Report on technology, participants, trends, market size and share
Kratos ares microservice framework (I)
Global and Chinese markets for hardware based encryption 2022-2028: Research Report on technology, participants, trends, market size and share
【shell脚本】使用菜单命令构建在集群内创建文件夹的脚本
Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"
基于B/S的影视创作论坛的设计与实现(附:源码 论文 sql文件 项目部署教程)
Global and Chinese market for annunciator panels 2022-2028: Research Report on technology, participants, trends, market size and share