当前位置:网站首页>[deep learning] semantic segmentation: paper reading: (2021-12) mask2former
[deep learning] semantic segmentation: paper reading: (2021-12) mask2former
2022-07-06 09:30:00 【sky_ Zhe】
Here's the catalog title
details
The paper :Masked-attention Mask Transformer for Universal Image Segmentation
Code :
official - Code
Code
video :
b Station paper explanation
Note reference :
The translated version
Abstract
Mask2Former stay MaskFormer On the basis of ,
- Added masked attention Mechanism ,
- In addition, it has also adjusted decoder Part of the self-attention and cross-attention The order of ,
- The use of importance sampling To speed up training .
The improvement of this article ** Mainly mask attention also high-resolution features,** It is essentially a pyramid , The rest is about training optimization On the improvement , Can improve training speed 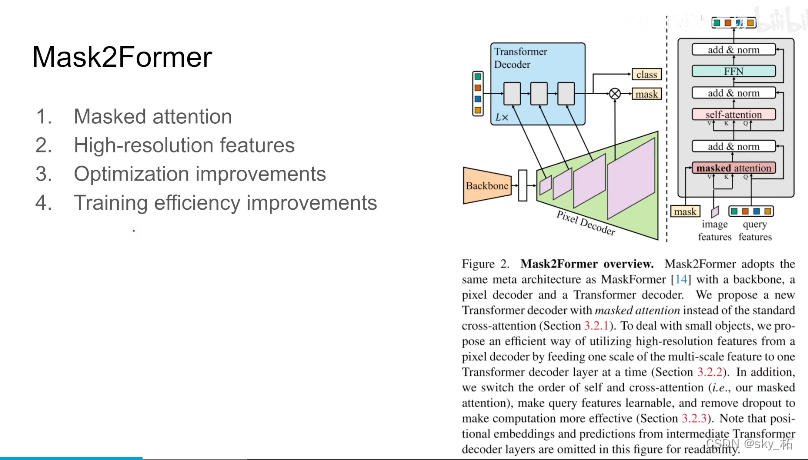
masked attention
We know decode There's a masked attention Of , Is to control which two token Can produce attention.
Here the author uses a bold assumption , It's us Doing it embeding When , We just need foreground These areas , Between them attention That's all right. , That is, it was maskformer inside , Each pixel and the whole image do attention, So now this pixel , Only those in the same category as yourself , It's all the same qurey The pixel , Between them attention.
This is the relative of this article maskformer The main difference , The core contribution .
The specific term ,maskformer inside q,k Come in , there k,value Well , All from images feature Come inside ,q It's from before query feature From inside , In this work , Introduced mask, Actually this mask That is, each q, Here is a q Represents a category , Every q Corresponding mask, stay mask These pixels inside , They do each other attention, More than , In other words, we don't think this kind of pixel , Don't do it attention.
stay decoder In structure ,image features It's from pixel decoder From inside , According to it, extract each pixel value,k. that query feature Different from the previous work ,maskformer Inside is 0, Here is something to learn vector. They do it first mask attention.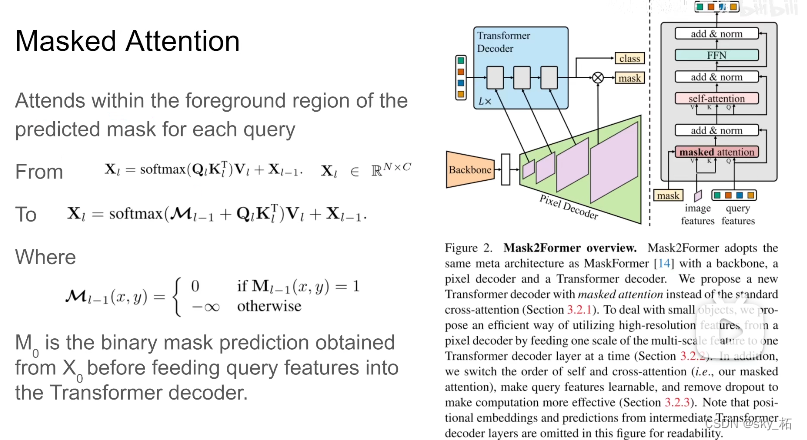
This mask How did it happen , In retrospect , stay maskformer inside , Every q come out . adopt mlp Produce a embeding, According to this embeding And again pixel embeding combination , You get about mask Of prediction , So this mask Namely mask2former decoder Input from mask, That is, for the first 0 Layer of decoder Come on , We haven't passed transformer decoder, First of all, put these qurey Deliver to mlp inside , Then predict this mask come out , Then we are doing decoder, Just go down one layer at a time , For example, after the first floor , We have new query, So the same , new query Deliver to mlp inside . Make one mask come out , Then add new image feature, Why new , Let's talk about , Then repeat decoder The process is fine , Then this is the core mask attention principle .
Why? query feature No more zero It is a learning frature, Because in the past decoder Before , According to these feature Predict a mask, Then this is a necessary change 、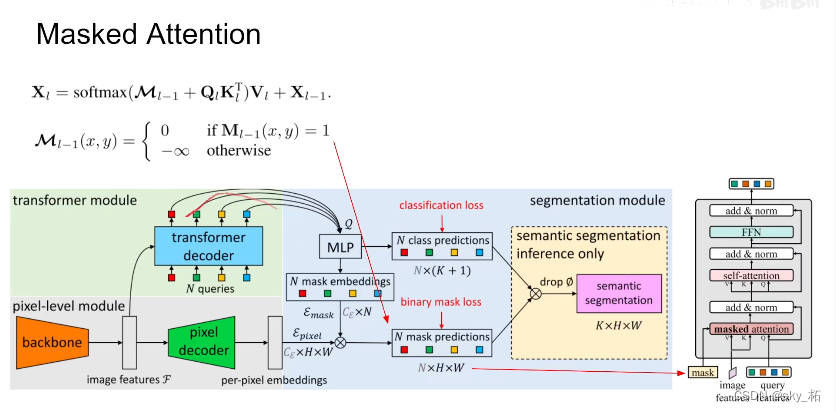
High-resolution features
The essence is the image pyramid , Here the author chooses the original image 32 One of the points ,16 One of the points ,8 One third of the three scale image feature Well , Deliver to decoder, That's the first floor 32 One third scale , Finish the first floor decoder obtain query, Then the second floor ,16 One third scale , Do the same again decoder, Then repeat the three-tier structure , repeat L Time , such as L yes 3, that decoder Is punctuated with 9 A structure like this .
And for every resolution What do you mean , The first is a sine position embeding, It also introduces 1 x C And learnable scale-level embeding, To control each chanel Of scale, What about this one , Is how the author should deal with high-resolution feature
What about after the pyramid , And then focus on , In the original maskformer above d What details have been adjusted .
classical decoder, Do it first token Between self-attention , And then doing this With image feature Introduced k,vaiue Of mask attention.
The author changed the order here , Because if you are right first query Between doing self attention, It doesn't have any image information , It makes no sense to do so , So here the author changed the orderSecond change .query feature It's learnable , Because I want to use query feature To predict the mask, So now query feature It's learnable
The third is dropout It will affect the performance of the model , At the same time, let the training speed slow down , So directly dropout Get rid of
Besides that , In order to increase the efficiency of training , Use sampling points to replace the whole mask. Simply put, it is the original calculation loss, It's a whole picture , Every pixel , His maks Is the shape right , Is his classification right , A whole picture , It takes up a lot of memory , And it's inefficient .
Here, the author randomly sampled several points , Use sampling method , It is equivalent to using fewer pixels , Come and go to form loss, This can greatly save the memory we use when training each graph 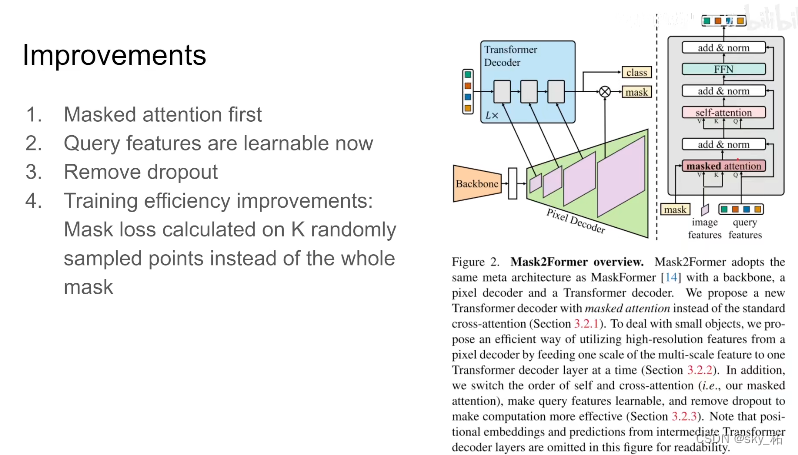
Detailed introduction
Note reference :
Detailed notes
author : Big pull
link :https://www.zhihu.com/question/503340099/answer/2256299264
source : You know
1, First look at the title , This is called Universal Image Segmentation, It should mean thinking Use one model To model all segmentation tasks : Semantic segmentation , Instance segmentation and panoramic segmentation . Different from some before Unified Segmentation(Max-Deeplab, K-Net, Maskformer), What the author wants to express is that they model Sure beat COCO The latest on each segmentation task on STOA, This is them teaser Point of view .
2, Next is the model itself ,Mask2Former Is based on MaskFormer Of .
In retrospect MaskFormer, Take panoramic segmentation as an example ,MaskFormer be based on DETR Of setting,
- Removed DETR Inside Heavy Segmentation Head and box prediction, Add an extra pixel decoder Out segmentation feature,
- And then use DETR Medium Output object query and segmentation feature Go straight out mask Classification and segmentation of ,
The main insight yes MaskFormer It is proved that only mask classification That's enough , Gives a concise solid Of baseline.
however MaskFormer There are two problems that have not been solved ,
- One is 300 epoch Training efficiency of ,
- One is the large overhead of video memory and Computing .
therefore , author ** Based on the above problems and the initial motivation(** One model obtains three different segmentation tasks STOA), Several improvements are proposed , In saving training time and cost At the same time, it can improve performance .
The first is masked attention, Compared with the previous cross attention, This one's inside attention affinity Is a sparse attention, The general idea is a little similar to Sparse-RCNN in Yes Query Feature Of ROI align and K-Net Medium MaskGrouping Wait for the operation , Only for object Of region do attention.
Look at the code , there Mask0 Is made up of an extra Learnable query features ProducedThe second improvement is It was used multi scale Characteristics of , The author used something similar to Deformable DETR decoder End settings , stay decoder End uses multi scale Feature input of attention. This step is for ascension small object Of segmentation Help a lot .1/8 Although the characteristics are the best , But it's not enough efficient.
The third improvement is some simple and effective designs :
The first is to use something similar to PointRend in Point supervision method to reduce the overhead of video memory , Another advantage of this is that you can train more model, So look at the author's code , They use more decoder(9 individual >6 individual ) To iterate more scale(3 individual scale).
The second is to replace cross attention and self attention Location and removal dropout wait .
Besides, compared with before MaskFormer, there pixel decoder It's using Deformable DETR To integrate the characteristics of different layers .pixel decoder The enhancement of can be seen on AP The impact is greater , My guess is still small object Of seg promote .
边栏推荐
- MapReduce工作机制
- 为什么要数据分层
- [OC foundation framework] - [set array]
- The order of include header files and the difference between double quotation marks "and angle brackets < >
- 数据建模有哪些模型
- Redis之核心配置
- [shell script] use menu commands to build scripts for creating folders in the cluster
- Selenium+Pytest自动化测试框架实战
- 七层网络体系结构
- 基于WEB的网上购物系统的设计与实现(附:源码 论文 sql文件)
猜你喜欢

Intel distiller Toolkit - Quantitative implementation 1

Mapreduce实例(八):Map端join
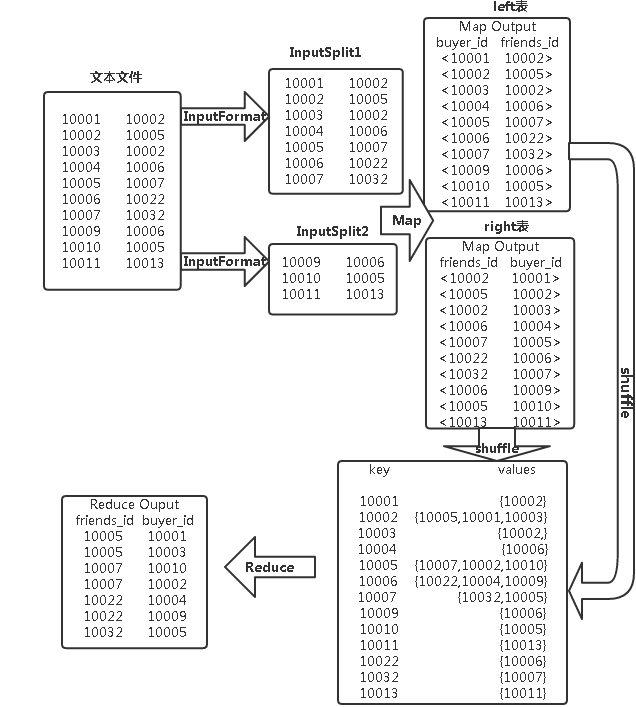
Mapreduce实例(七):单表join
Mapreduce实例(六):倒排索引
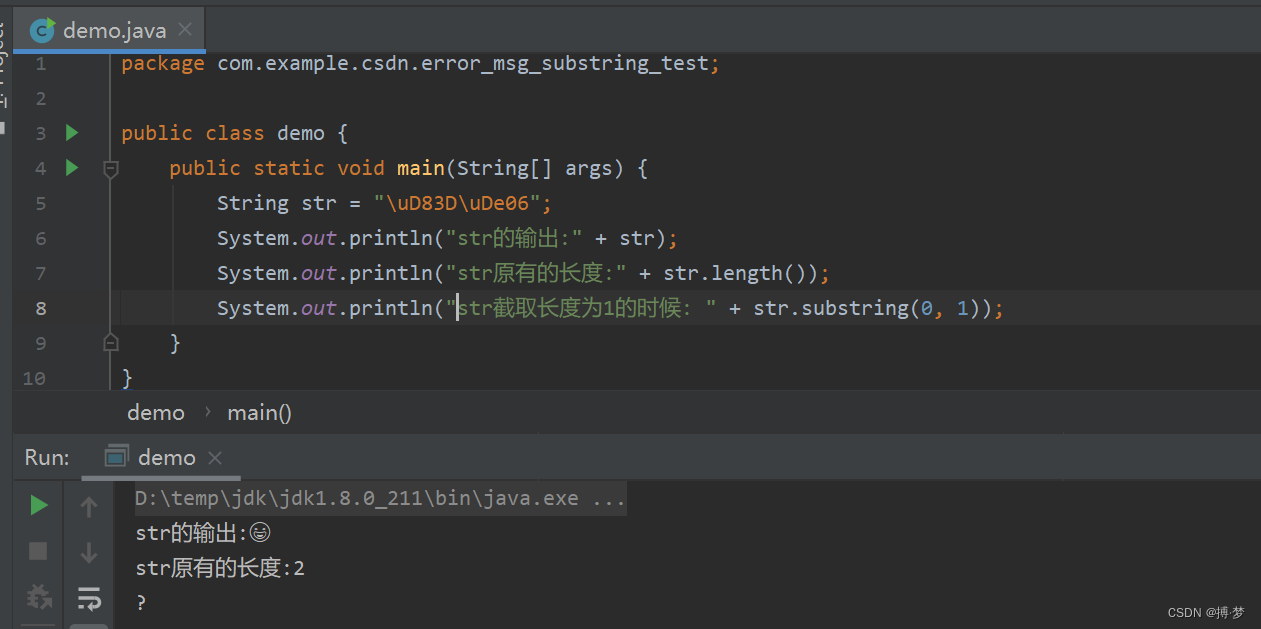
How to intercept the string correctly (for example, intercepting the stock in operation by applying the error information)
![[oc]- < getting started with UI> -- common controls uibutton](/img/4d/f5a62671068b26ef43f1101981c7bb.png)
[oc]- < getting started with UI> -- common controls uibutton

An article takes you to understand the working principle of selenium in detail
工作流—activiti7环境搭建
英雄联盟轮播图自动轮播

Lua script of redis
随机推荐
CAP理论
QDialog
One article read, DDD landing database design practice
Kratos战神微服务框架(二)
What is MySQL? What is the learning path of MySQL
Selenium+Pytest自动化测试框架实战
[oc]- < getting started with UI> -- common controls - prompt dialog box and wait for the prompt (circle)
leetcode-14. Longest common prefix JS longitudinal scanning method
发生OOM了,你知道是什么原因吗,又该怎么解决呢?
Global and Chinese market of electronic tubes 2022-2028: Research Report on technology, participants, trends, market size and share
Global and Chinese market of appointment reminder software 2022-2028: Research Report on technology, participants, trends, market size and share
go-redis之初始化连接
七层网络体系结构
Global and Chinese market of linear regulators 2022-2028: Research Report on technology, participants, trends, market size and share
Advance Computer Network Review(1)——FatTree
Persistence practice of redis (Linux version)
Intel distiller Toolkit - Quantitative implementation 1
基于WEB的网上购物系统的设计与实现(附:源码 论文 sql文件)
Selenium+Pytest自动化测试框架实战(下)
Mapreduce实例(八):Map端join