当前位置:网站首页>评估方法的优缺点
评估方法的优缺点
2022-07-06 09:11:00 【一曲无痕奈何】
1、过拟合:当学习器把训练样本学的太好,很可能把已经训练的样本特点当做了所有潜在样本都会有的一般性质,这样就会导致泛华能力下降(泛化能力指学习的模型应用在未知的样本中的能力)。
2、欠拟合:指学习能力低下,认为很一般的特点都是所有的特点。
评估方法:
- 留出法:若训练集包含绝大多数样本,则训练出的样本可能就接近想要的训练模型,但是由于测试集较小,评估结果可能就不够准确,基本划分的数据集的模式:2:1,4:1前面分别用做训练,后面的用作测试。
- 交叉验证法:等分,分层采样,取均值,缺陷则是:在数据集较大开销太大,花费时间较多。
- 自助法:循环从整体数据中取放进样例中,又放回的抽取,最终初始数据有0.368的样本未出现,用于测试。自助法能从初始数据集中出现的样本用于测试,这样的测试也称为包外估计。优点:自助法在数据集较小,难以有效划分训练\测试集时候很有用,能从初始数据集中产生多个不同的训练集,缺点:但是改变了数据集分布,这会引入估计偏差。
但是在初始数据量足够时候,留出法和交叉验证法更常用。
调参与最终参数模型:
调参的一般准则:对每个参数选定一个范围和一个变化的步长,这是这是在计算开销与性能的折中方案。
性能度量:衡量模型泛华能力的度量,性能不仅取决于算法和数据,还决定任务需求。
回归任务最常用的性能度量:均方误差。
查全率 (TP/(TP+FN))、查准率(TP/(TP+FP)):TP真正例 FP假正例 TN真反例 FN假反例。
F1是基于查全率与查准率的调和平均定义的:2*TP/(样例总数+TP-TN)
ROC:受试工作特征。 横轴TPR(真正例)=TP/(TP+FN),纵轴FPR(假正例):FP/(TN+FP)。
规范化:将不同变化范围的值映射到相同固定范围内,常见的是[0,1],也称归一化。
偏差:期望输出与真实标记的差别,刻画学习算法本身的拟合能力。
泛化误差可分解为偏差、方差(度量了同样大小训练集的变动所导致的学习性能的变化吗,刻画了数据扰动所造成的影响)、与噪声(表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界)之和。
边栏推荐
- Southwest University: Hu hang - Analysis on learning behavior and learning effect
- MySQL learning diary (II)
- MySQL实战优化高手06 生产经验:互联网公司的生产环境数据库是如何进行性能测试的?
- MySQL combat optimization expert 07 production experience: how to conduct 360 degree dead angle pressure test on the database in the production environment?
- 华南技术栈CNN+Bilstm+Attention
- 16 医疗挂号系统_【预约下单】
- Vh6501 Learning Series
- A new understanding of RMAN retention policy recovery window
- MySQL实战优化高手08 生产经验:在数据库的压测过程中,如何360度无死角观察机器性能?
- 好博客好资料记录链接
猜你喜欢
Not registered via @EnableConfigurationProperties, marked(@ConfigurationProperties的使用)
软件测试工程师必备之软技能:结构化思维
华南技术栈CNN+Bilstm+Attention
如何搭建接口自动化测试框架?
宝塔的安装和flask项目部署
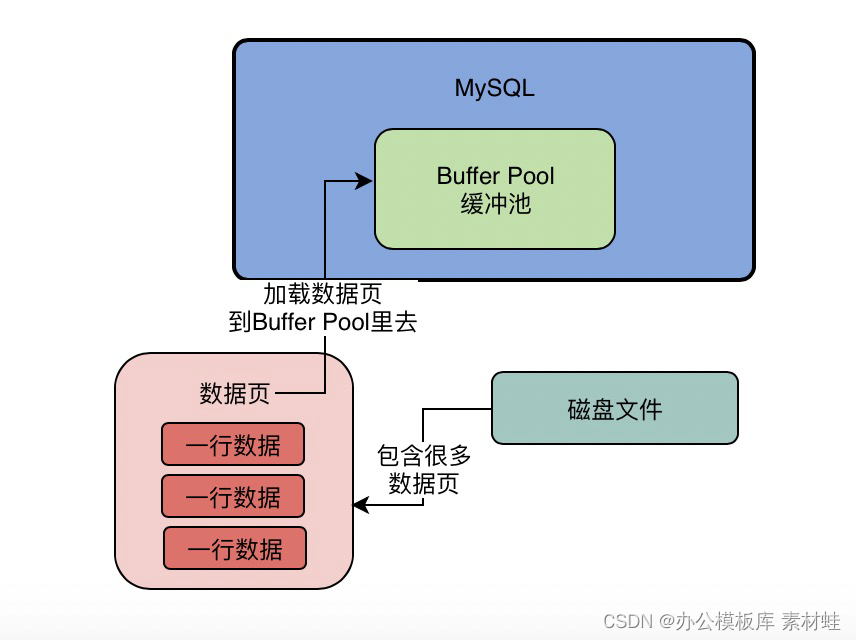
MySQL combat optimization expert 12 what does the memory data structure buffer pool look like?
Control the operation of the test module through the panel in canoe (Advanced)
MySQL实战优化高手12 Buffer Pool这个内存数据结构到底长个什么样子?
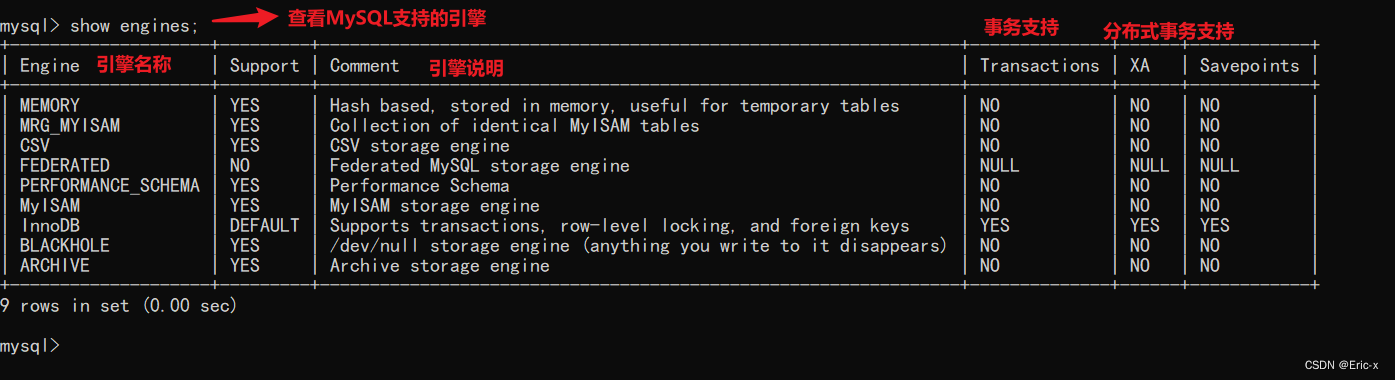
MySQL的存储引擎
Contest3145 - the 37th game of 2021 freshman individual training match_ B: Password
随机推荐
What should the redis cluster solution do? What are the plans?
Super detailed steps to implement Wechat public number H5 Message push
A new understanding of RMAN retention policy recovery window
Target detection -- yolov2 paper intensive reading
Technology | diverse substrate formats
17 medical registration system_ [wechat Payment]
MySQL实战优化高手11 从数据的增删改开始讲起,回顾一下Buffer Pool在数据库里的地位
Solve the problem of remote connection to MySQL under Linux in Windows
华南技术栈CNN+Bilstm+Attention
实现以form-data参数发送post请求
颜值爆表,推荐两款JSON可视化工具,配合Swagger使用真香
[one click] it only takes 30s to build a blog with one click - QT graphical tool
14 医疗挂号系统_【阿里云OSS、用户认证与就诊人】
Flash operation and maintenance script (running for a long time)
Time complexity (see which sentence is executed the most times)
How to make shell script executable
如何搭建接口自动化测试框架?
Jar runs with error no main manifest attribute
13 medical registration system_ [wechat login]
Contest3145 - the 37th game of 2021 freshman individual training match_ C: Tour guide