当前位置:网站首页>Implementation of crawling web pages and saving them to MySQL using the scrapy framework
Implementation of crawling web pages and saving them to MySQL using the scrapy framework
2022-07-07 15:17:00 【1024 questions】
Hello everyone , In this issue, abin will share with you Scrapy Crawler framework and local Mysql Use . Today, the web page ah bin crawled is Hupu Sports Network .
(1) Open Hupu Sports Network , Analyze the data of the web page , Use xpath Positioning elements .

(2) After the first analysis of the web page, start creating a scrapy Reptile Engineering , Execute the following command at the terminal :
“scrapy startproject huty( notes :‘hpty’ Is the name of the crawler project )”, Get the project package shown in the figure below :

(3) Enter into “hpty/hpty/spiders” Create a crawler file called ‘“sww”, Execute the following command at the terminal : “scrapy genspider sww” (4) After the first two steps , Edit the crawler files related to the whole crawler project . 1、setting Editor of the document :
The gentleman agreement was originally True Change it to False.

Then open this line of code that was originally commented out .

2、 Yes item File for editing , This file is used to define data types , The code is as follows :
# Define here the models for your scraped items## See documentation in:# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass HptyItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() players = scrapy.Field() The team = scrapy.Field() ranking = scrapy.Field() Average score = scrapy.Field() shooting = scrapy.Field() Three-point percentage = scrapy.Field() Free throw percentage = scrapy.Field()3、 Edit the most important crawler files ( namely “hpty” file ), The code is as follows :
import scrapyfrom ..items import HptyItemclass SwwSpider(scrapy.Spider): name = 'sww' allowed_domains = ['https://nba.hupu.com/stats/players'] start_urls = ['https://nba.hupu.com/stats/players'] def parse(self, response): whh = response.xpath('//tbody/tr[not(@class)]') for i in whh: ranking = i.xpath( './td[1]/text()').extract()# ranking players = i.xpath( './td[2]/a/text()').extract() # players The team = i.xpath( './td[3]/a/text()').extract() # The team Average score = i.xpath( './td[4]/text()').extract() # score shooting = i.xpath( './td[6]/text()').extract() # shooting Three-point percentage = i.xpath( './td[8]/text()').extract() # Three-point percentage Free throw percentage = i.xpath( './td[10]/text()').extract() # Free throw percentage data = HptyItem( players = players , The team = The team , ranking = ranking , Average score = Average score , shooting = shooting , Three-point percentage = Three-point percentage , Free throw percentage = Free throw percentage ) yield data4、 Yes pipelines File for editing , The code is as follows :
# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interfacefrom cursor import cursorfrom itemadapter import ItemAdapterimport pymysqlclass HptyPipeline: def process_item(self, item, spider): db = pymysql.connect(host="Localhost", user="root", passwd="root", db="sww", charset="utf8") cursor = db.cursor() players = item[" players "][0] The team = item[" The team "][0] ranking = item[" ranking "][0] Average score = item[" Average score "][0] shooting = item[" shooting "] Three-point percentage = item[" Three-point percentage "][0] Free throw percentage = item[" Free throw percentage "][0] # Three-point percentage = item[" Three-point percentage "][0].strip('%') # Free throw percentage = item[" Free throw percentage "][0].strip('%') cursor.execute( 'INSERT INTO nba( players , The team , ranking , Average score , shooting , Three-point percentage , Free throw percentage ) VALUES (%s,%s,%s,%s,%s,%s,%s)', ( players , The team , ranking , Average score , shooting , Three-point percentage , Free throw percentage ) ) # Commit transaction operations db.commit() # Close cursor cursor.close() db.close() return item(5) stay scrapy After the frame is designed , Come first mysql Create a file called “sww” The database of , Create a database named “nba” Data sheet for , The code is as follows : 1、 Create database
create database sww;2、 Create data table
create table nba ( players char(20), The team char(10), ranking char(10), Average score char(25), shooting char(20), Three-point percentage char(20), Free throw percentage char(20));3、 You can see the structure of the table by creating the database and data table :

(6) stay mysql After creating the data table , Return to the terminal again , Enter the following command :“scrapy crawl sww”, The result
This is about using Scrapy The frame crawls the web page and saves it to Mysql This is the end of the article on the implementation of , More about Scrapy Crawl the web page and save the content. Please search the previous articles of SDN or continue to browse the relevant articles below. I hope you will support SDN in the future !
边栏推荐
猜你喜欢

Stm32cubemx, 68 sets of components, following 10 open source protocols
![[deep learning] image hyperspectral experiment: srcnn/fsrcnn](/img/84/114fc8f0875b82cc824e6400bcb06f.png)
[deep learning] image hyperspectral experiment: srcnn/fsrcnn
Niuke real problem programming - day18

Apache多个组件漏洞公开(CVE-2022-32533/CVE-2022-33980/CVE-2021-37839)

【跟着江科大学Stm32】STM32F103C8T6_PWM控制直流电机_代码
CTFshow,信息搜集:web14
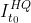
时空可变形卷积用于压缩视频质量增强(STDF)
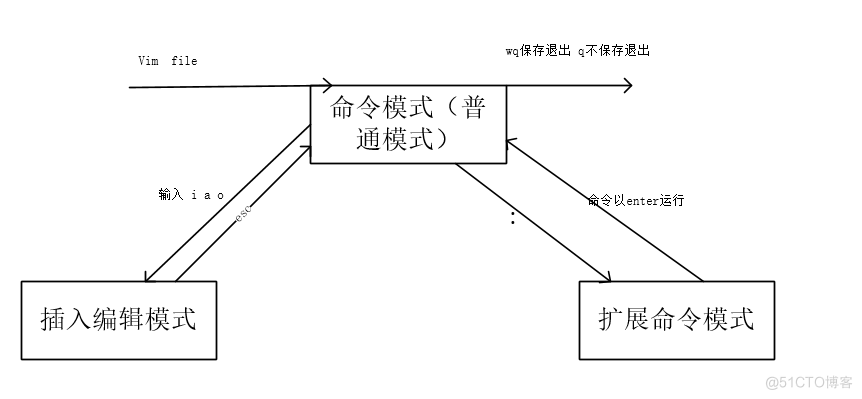
15、文本编辑工具VIM使用
银行需要搭建智能客服模块的中台能力,驱动全场景智能客服务升级

Guangzhou Development Zone enables geographical indication products to help rural revitalization
随机推荐
Jetson AGX Orin CANFD 使用
Niuke real problem programming - Day9
How does the database perform dynamic custom sorting?
[data mining] visual pattern mining: hog feature + cosine similarity /k-means clustering
[deep learning] semantic segmentation experiment: UNET network /msrc2 dataset
FFmpeg----图片处理
【原创】一切不谈考核的管理都是扯淡!
有一头母牛,它每年年初生一头小母牛。每头小母牛从第四个年头开始,每年年初也生一头小母牛。请编程实现在第n年的时候,共有多少头母牛?
上半年晋升 P8 成功,还买了别墅!
Used by Jetson AgX Orin canfd
智汀不用Home Assistant让小米智能家居接入HomeKit
Niuke real problem programming - Day17
Discussion on CPU and chiplet Technology
[follow Jiangke University STM32] stm32f103c8t6_ PWM controlled DC motor_ code
What are PV and UV? pv、uv
Bye, Dachang! I'm going to the factory today
Briefly describe the working principle of kept
Unity之ASE实现全屏风沙效果
什麼是數據泄露
[deep learning] image hyperspectral experiment: srcnn/fsrcnn