当前位置:网站首页>[network] channel attention network and spatial attention network
[network] channel attention network and spatial attention network
2022-07-06 04:18:00 【Hard working yuan】
CBAM: Address of thesis
Purpose :
Convolution is to extract features by mixing the information of channel and space dimensions . In terms of attention ,SE Only pay attention to channel attention , Did not consider spatial attention . therefore , This paper proposes CBAM—— A convolution module that focuses on both channels and spatial attention , It can be used for CNNs Architecture , To improve feature map The ability to express the characteristics of .Network structure :
Main network structure
CAM and SAM Structure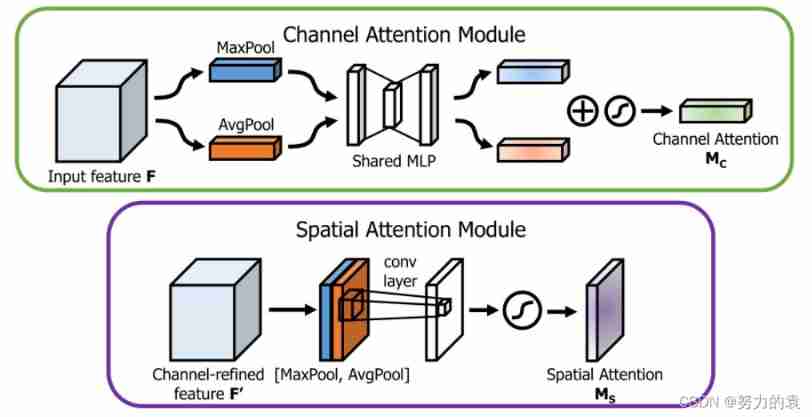
CAM: The channel attention mechanism is to learn the weighting coefficient of a different channel , At the same time, all areas are considered
SAM: Spatial attention mechanism is to learn the coefficients of different areas of the whole picture , All channels are considered at the same time .
Pytorch Code implementation :
import torch from torch import nn class ChannelAttention(nn.Module): def __init__(self, in_planes, ratio=16): super(ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False) self.relu1 = nn.ReLU() self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out) class SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() self.register_buffer() def forward(self, x): avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1) x = self.conv1(x) return self.sigmoid(x)Reference resources :https://blog.csdn.net/oYeZhou/article/details/116664508
边栏推荐
- Fundamentals of SQL database operation
- 【HBZ分享】云数据库如何定位慢查询
- 颠覆你的认知?get和post请求的本质
- Crawler notes: improve data collection efficiency! Use of proxy pool and thread pool
- BOM - location, history, pop-up box, timing
- asp. Core is compatible with both JWT authentication and cookies authentication
- Easyrecovery靠谱不收费的数据恢复电脑软件
- Global and Chinese market of plasma separator 2022-2028: Research Report on technology, participants, trends, market size and share
- Tips for using dm8huge table
- Benefits of automated testing
猜你喜欢
Fedora/REHL 安装 semanage
Practical development of member management applet 06 introduction to life cycle function and user-defined method
Query the number and size of records in each table in MySQL database
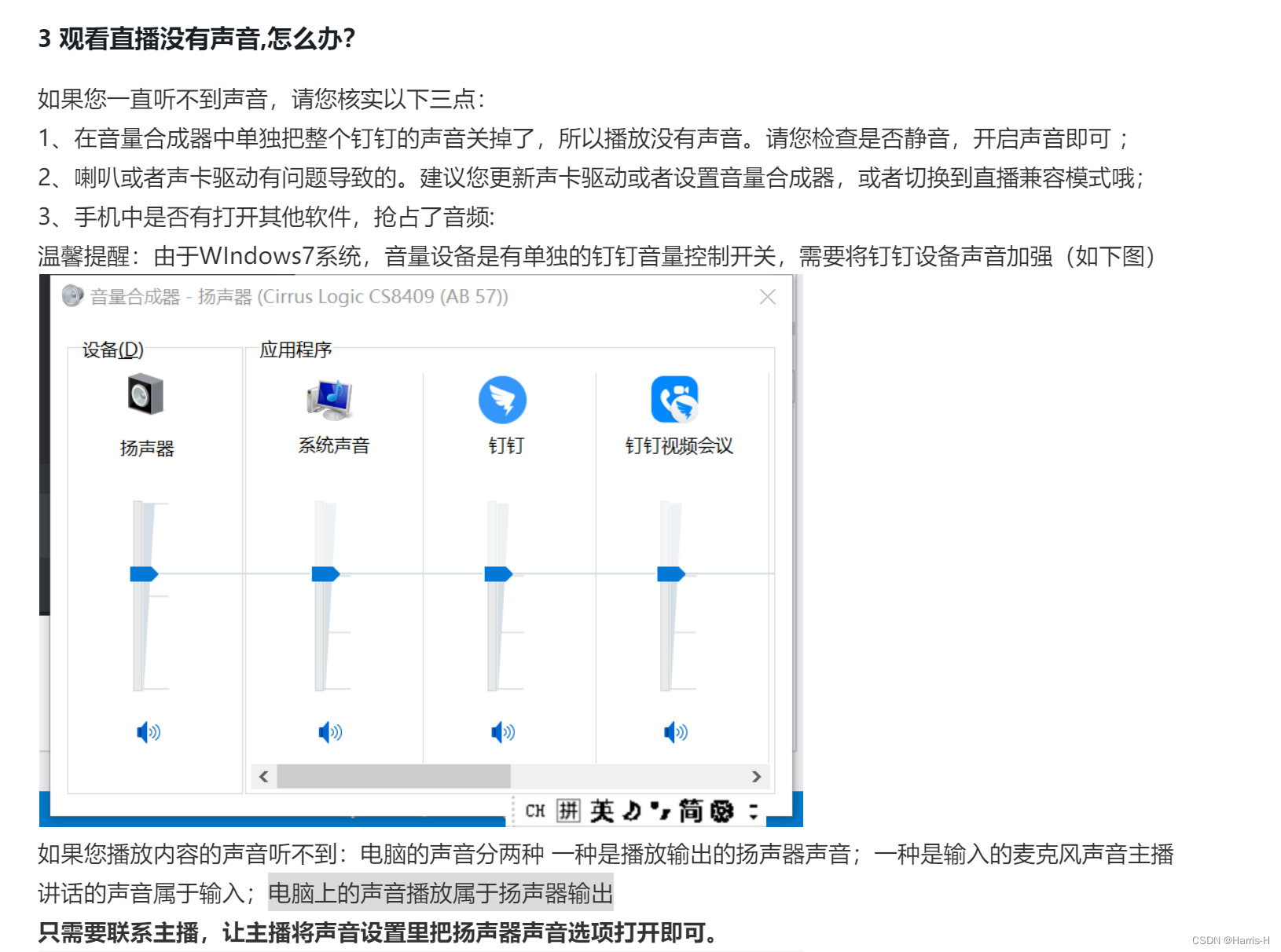
How does computer nail adjust sound
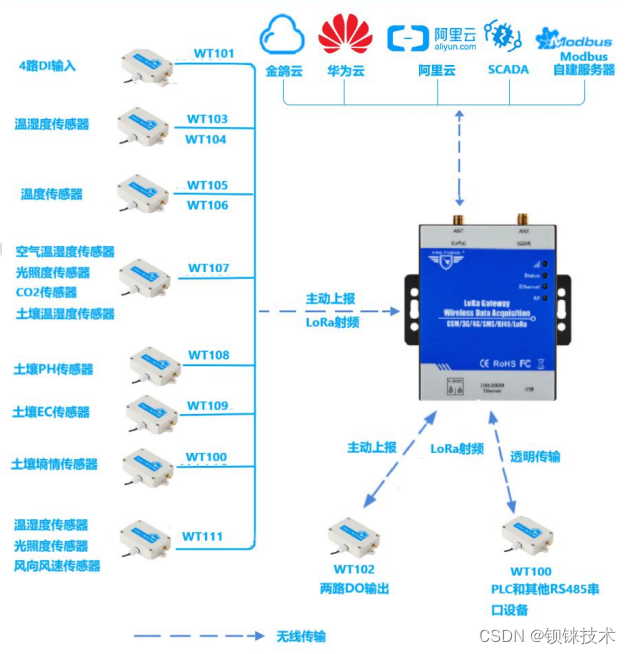
Lora gateway Ethernet transmission
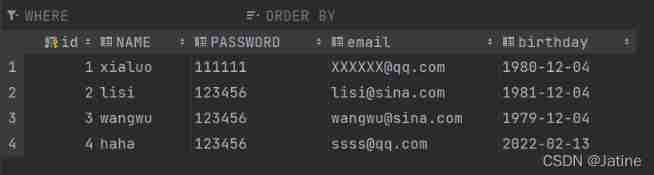
MySQL learning record 13 database connection pool, pooling technology, DBCP, c3p0
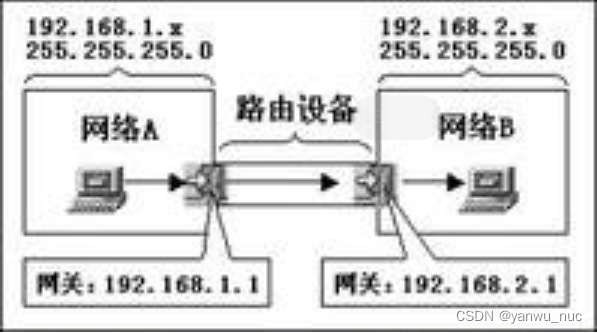
What is the difference between gateway address and IP address in tcp/ip protocol?
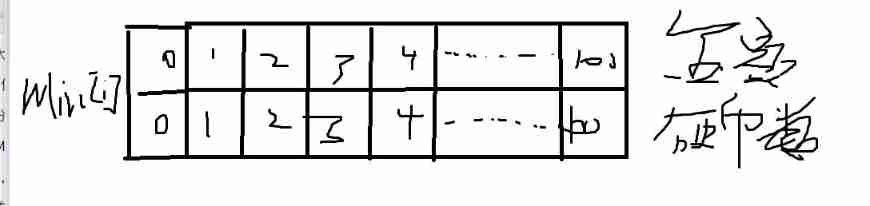
About some basic DP -- those things about coins (the basic introduction of DP)
查询mysql数据库中各表记录数大小
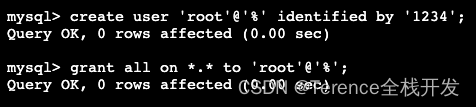
MySql數據庫root賬戶無法遠程登陸解决辦法
随机推荐
MLAPI系列 - 04 - 网络变量和网络序列化【网络同步】
729. My schedule I (set or dynamic open point segment tree)
P2022 有趣的数(二分&数位dp)
Basic use of MySQL (it is recommended to read and recite the content)
1291_ Add timestamp function in xshell log
[face recognition series] | realize automatic makeup
Patent | subject classification method based on graph convolution neural network fusion of multiple human brain maps
题解:《单词覆盖还原》、《最长连号》、《小玉买文具》、《小玉家的电费》
Tips for using dm8huge table
Script lifecycle
Ipv4中的A 、B、C类网络及子网掩码
拉格朗日插值法
Redis (replicate dictionary server) cache
How to solve the problem of slow downloading from foreign NPM official servers—— Teach you two ways to switch to Taobao NPM image server
Guitar Pro 8.0最详细全面的更新内容及全部功能介绍
解决“C2001:常量中有换行符“编译问题
Solution to the problem that the root account of MySQL database cannot be logged in remotely
Lambda expression learning
1008 circular right shift of array elements (20 points)
[leetcode question brushing day 33] 1189 The maximum number of "balloons", 201. The number range is bitwise AND