当前位置:网站首页>Data processing methods - smote series and adasyn
Data processing methods - smote series and adasyn
2022-07-06 04:09:00 【Code Taoist】
brief introduction
Unbalanced dataset refers to the extremely unbalanced sample size of each category of the dataset . A case study of dichotomous problems , Suppose that the number of samples of the positive class is much larger than that of the negative class , Usually, the proportion of most samples is close to 100:1 The data in this case is called unbalanced data . The learning of unbalanced data requires learning useful information in unevenly distributed data sets .
The processing methods of unbalanced data sets are mainly divided into two aspects :
1、 From a data perspective , The main method is sampling , It is divided into undersampling and oversampling and some corresponding improvement methods .
2、 From the perspective of Algorithm , Considering the cost difference of different misclassification cases, the algorithm is optimized , Mainly based on cost sensitive learning algorithm (Cost-Sensitive Learning), The representative algorithms are adacost;
In addition, the problem of unbalanced data sets can be considered as a classification (One Class Learning) Or anomaly detection (Novelty Detection) problem , The representative algorithms are One-class SVM.
SMOTE series
SMOTE
SMOTE(Synthetic Minority Oversampling Technique) Synthesis of a few oversampling techniques , It is an over sampling algorithm improved on the basis of random sampling . Select a sample from a few samples xi. secondly , By sampling magnification N, from xi Of K Random selection among nearest neighbors N Samples xzi. Last , In turn, it's xzi and xi Randomly synthesize new samples , The synthesis formula is as follows :
$$xn=xi+beta(x{zi}-xi)$$
Address of thesis
SMOTE: Synthetic Minority Over-sampling Technique
Borderline SMOTE
Borderline SMOTE Is in SMOTE Based on the improved oversampling algorithm , The algorithm only uses a few class samples on the boundary to synthesize new samples , So as to improve the category distribution of samples .
Borderline SMOTE The sampling process is to divide a small number of samples into 3 class , Respectively Safe、Danger and Noise,Safe, More than half of the samples are minority samples ;Danger: More than half of the samples around are most types of samples , As a sample on the boundary ;Noise: The samples are surrounded by most types of samples , Considered noise , As shown in the middle of the picture C Last , For tables only Danger A few classes of samples are oversampled .
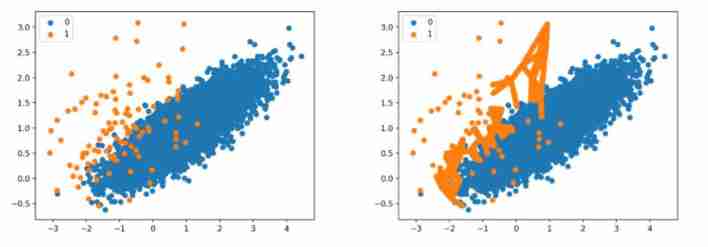
Address of thesis
Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning
ADASYN series
ADASYN
ADASYN (adaptive synthetic sampling) Adaptive synthetic sampling , And Borderline SMOTE be similar , Give different weights to different minority samples , So as to generate different numbers of samples .
step
- Calculate the number of samples to be synthesized , The formula is as follows :
$$G=left(m{l}-m{s}right) times beta$$
among , $m{text { 丨 }}$ Number of samples for most classes , $m{s}$ Is the number of samples of a few classes , $beta in[0,1]$ random number , if $beta$ be equal to 1 , The positive and negative ratio after sampling is $1: 1$ .
- Calculation K Most classes in the nearest neighbors account for , The formula is as follows :
$$r{i}=Delta{i} / K$$
among , $Delta{i}$ by $K$ Number of samples of most classes in nearest neighbors , $i=1,2,3, ldots ldots, m{s}$
- Yes ri Standardization , The formula is as follows :
$$hat{r}{i}=r{i} / sum{i=1}^{m{s}} r_{i}$$
- According to the sample weight , Calculate the number of new samples to be generated for each minority sample , The formula is as follows :
$$g=hat{r}_{i} times G$$
- according to $g$ Calculate the number of samples to be generated for each small number of samples , according to SMOTE The algorithm generates samples , The formula is as follows :
$$s{i}=x{i}+left(x{z i}-x{i}right) times lambda$$
among , $mathrm{s}{i}$ For synthetic samples , $mathrm{x}{i}$ It is the second in a few samples $i$ Samples , $mathrm{x}{mathrm{z} i}$ yes $mathrm{x}{mathrm{i}}$ Of K Randomly select a minority sample from the nearest neighbors $lambda in[0,1]$ The random number .
Address of thesis
ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning
边栏推荐
- 深入浅出node模板解析错误escape is not a function
- 2/12 didn't learn anything
- Redis (replicate dictionary server) cache
- 绑定在游戏对象上的脚本的执行顺序
- 《2022年中国银行业RPA供应商实力矩阵分析》研究报告正式启动
- AcWing 243. A simple integer problem 2 (tree array interval modification interval query)
- asp. Core is compatible with both JWT authentication and cookies authentication
- 1291_Xshell日志中增加时间戳的功能
- Esp32 (based on Arduino) connects the mqtt server of emqx to upload information and command control
- Record an excel xxE vulnerability
猜你喜欢
DM8 archive log file manual switching

Database, relational database and NoSQL non relational database
![Cf464e the classic problem [shortest path, chairman tree]](/img/6b/65b2dc62422a45cc72f287c38dbc58.jpg)
Cf464e the classic problem [shortest path, chairman tree]

MySQL master-slave replication
![[Key shake elimination] development of key shake elimination module based on FPGA](/img/47/c3833c077ad89d4906e425ced945bb.png)
[Key shake elimination] development of key shake elimination module based on FPGA
MySQL about self growth
Practical development of member management applet 06 introduction to life cycle function and user-defined method

颠覆你的认知?get和post请求的本质
After five years of testing in byte, I was ruthlessly dismissed in July, hoping to wake up my brother who was paddling

Interface idempotency
随机推荐
User datagram protocol UDP
After five years of testing in byte, I was ruthlessly dismissed in July, hoping to wake up my brother who was paddling
How to execute an SQL statement in MySQL
Solution to the problem that the root account of MySQL database cannot be logged in remotely
MySQL learning record 13 database connection pool, pooling technology, DBCP, c3p0
asp. Core is compatible with both JWT authentication and cookies authentication
图应用详解
颠覆你的认知?get和post请求的本质
The Research Report "2022 RPA supplier strength matrix analysis of China's banking industry" was officially launched
查询mysql数据库中各表记录数大小
MLAPI系列 - 04 - 网络变量和网络序列化【网络同步】
Basic use of MySQL (it is recommended to read and recite the content)
Thread sleep, thread sleep application scenarios
Prime Protocol宣布在Moonbeam上的跨链互连应用程序
Brief tutorial for soft exam system architecture designer | general catalog
【FPGA教程案例11】基于vivado核的除法器设计与实现
PTA tiantisai l1-078 teacher Ji's return (15 points) detailed explanation
Fundamentals of SQL database operation
Scalpel like analysis of JVM -- this article takes you to peek into the secrets of JVM
简易博客系统