当前位置:网站首页>图应用详解
图应用详解
2022-07-06 04:04:00 【ZNineSun】
文章目录
图的应用主要包括:最小生成(代价)树、最短路径、拓扑排序和
关键路径,在数据结构中占据着比较重要的地位,其中里面涉及到很多的算法,也很重要,希望大家能够通过本文尽数掌握。
1.最小生成树
在了解最小生成树之前,大家应该先知道什么叫生成树?
生成树:所有顶均由边链接在一起,但不存在回路的图。
生成树具有以下特点:
- 多一条边会出现回路
- 少一条边会出现链接不到的顶点
- 一个图可以有许多棵不同的生成树
如下图所示: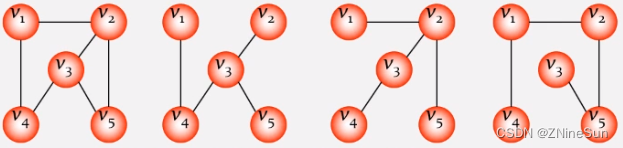
知道了什么叫生成树了,在了解一下什么叫最小生成树
1.2 最小生成树
给定一个无向网络,则该网的所有生成树中,使得各边权值之和最小的那棵生成树称为该网的最小生成树,也叫最小代价生成树。
1.3 最小生成树用途
- 欲在 n 个城市间建立通信网,在 n 个城市应铺 n-1 条线路;
- 但因为每条线路都会相对应的经济成本,而 n 个城市最多有 n*(n-1)/2 条线路,那么,如何选择 n-1 条线路,使总费用最少?
1.4 如何构建最小生成树
构建最小生成树的的算法主要有两个,Prim算法、Kruskal算法,他们都是基于贪心算法的策略,我下面一一讲解一下。
1.4.1 Prim算法
初始时从图中任意取一个顶点加入树T,此时树中只有一个顶点,之后选择一个与当前T中顶点集合距离最近的顶点,并将该顶点和相应的边加入T,每次操作后T中的顶点数和边数都增加1,依次类推,直至图中所有的顶点都加入T中,整体过程如下图所示: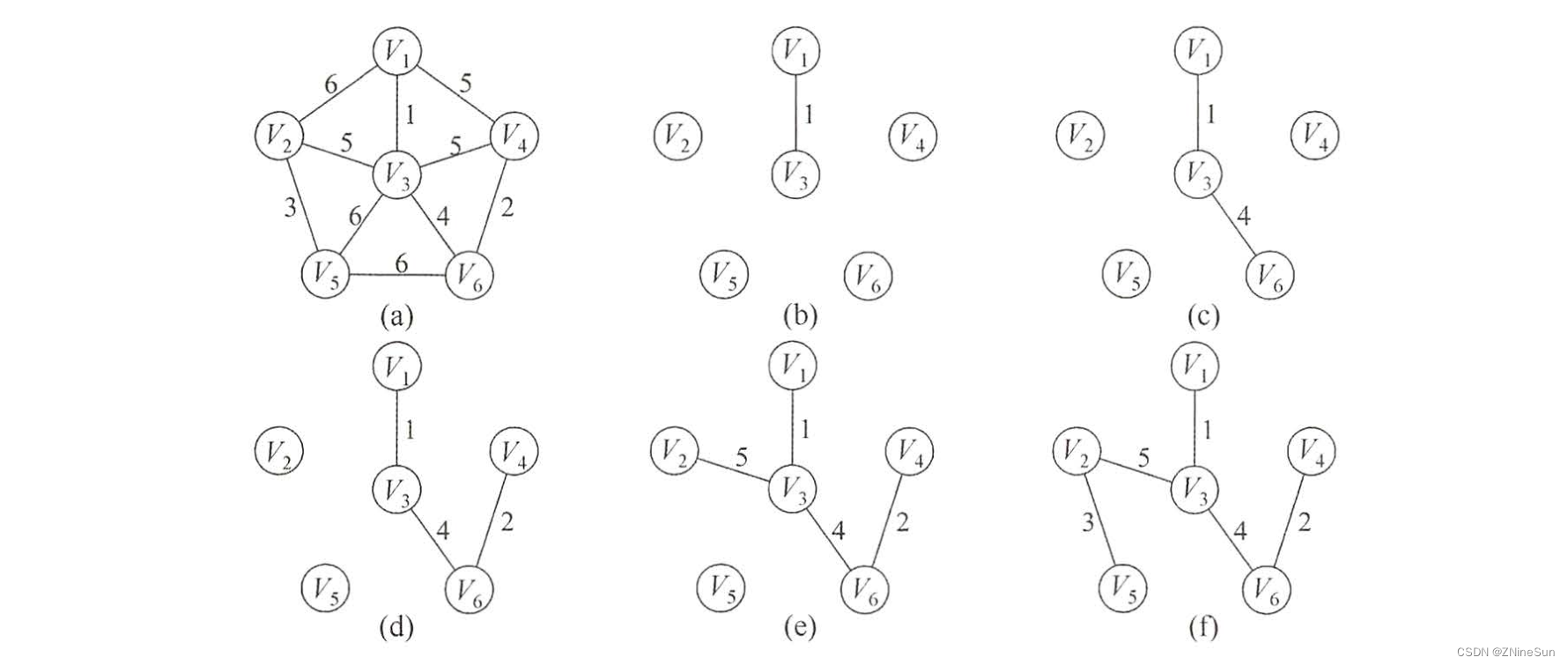
代码实现如下:(Java版)
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/** * Prim算法的思想是任取途中一个顶点i作为起始点,并将其加入到S集合中。从V-S(V表示所有顶点)的集合中 * 选取一条到S集合的顶点最短的边。例如S集合中有(1,2)两个顶点,V-S集合中有(4,5,6)三个顶点,那么 * 取(1,4) (1,5) (1,6) (2,4) (2,5) (2,6)这六条边中的最小值,如果(1,4)这条边的权值最小,那么 * 将4这个顶点加入S中。依次类推,直到S的数量等于所有顶点的数量n。 */
public class Prim {
//flag标记选取了哪一条路径,例如:flag[1][2] = true则表明从1到2这个路径已经被选取
//数据c[i][j]表示从i到j的权值,n表示一个有多少个顶点
public void prim(int[][] c, int n,boolean[][] flag) {
List<Integer> list = new ArrayList<>();
int start = 0,end = 0,min = Integer.MAX_VALUE;
//标记选取了哪一条路径,例如:flag[1][2] = true则表明从1到2这个路径已经被选取
//起始点设为0,下面遍历找出从0出发的最短路径
for (int i = 1; i < n; i++) {
if (c[0][i] < min){
start = 0;
end = i;
min = c[0][1];
}
}
list.add(0);
//将(0,i)权值最小的边的顶点加入到list中
list.add(end);
//标记一下已取的路径
flag[0][end] = true;
while (list.size() != n){
min = Integer.MAX_VALUE;
//从V-S(V表示所有顶点)的集合中选取一条到S集合的顶点最短的边
for (Integer i: list) {
for (int j = 0 ; j < n; j++){
if (!flag[i][j] && !list.contains(j) && c[i][j] < min){
start = i;
end = j;
min = c[i][j];
}
}
}
flag[start][end] = true;
list.add(end);
}
}
}
Prim算法的时间复杂度为O(|V|^2),不依赖于|E|),因此它适用于求解边稠密的图的最小生成树。
虽然采用其他方法能改进 Prim 算法的时间复杂度,但增加了实现的复杂性。
1.4.2 KrusKal算法
与Prim算法从顶点开始扩展最小生成树不同,Kruskal (克鲁斯卡尔)算法是一种按权值的递增次序选择合适的边来构造最小生成树的方法。
此处我不在文字介绍过程,文字比较复杂难懂,我们直接通过流程图来看: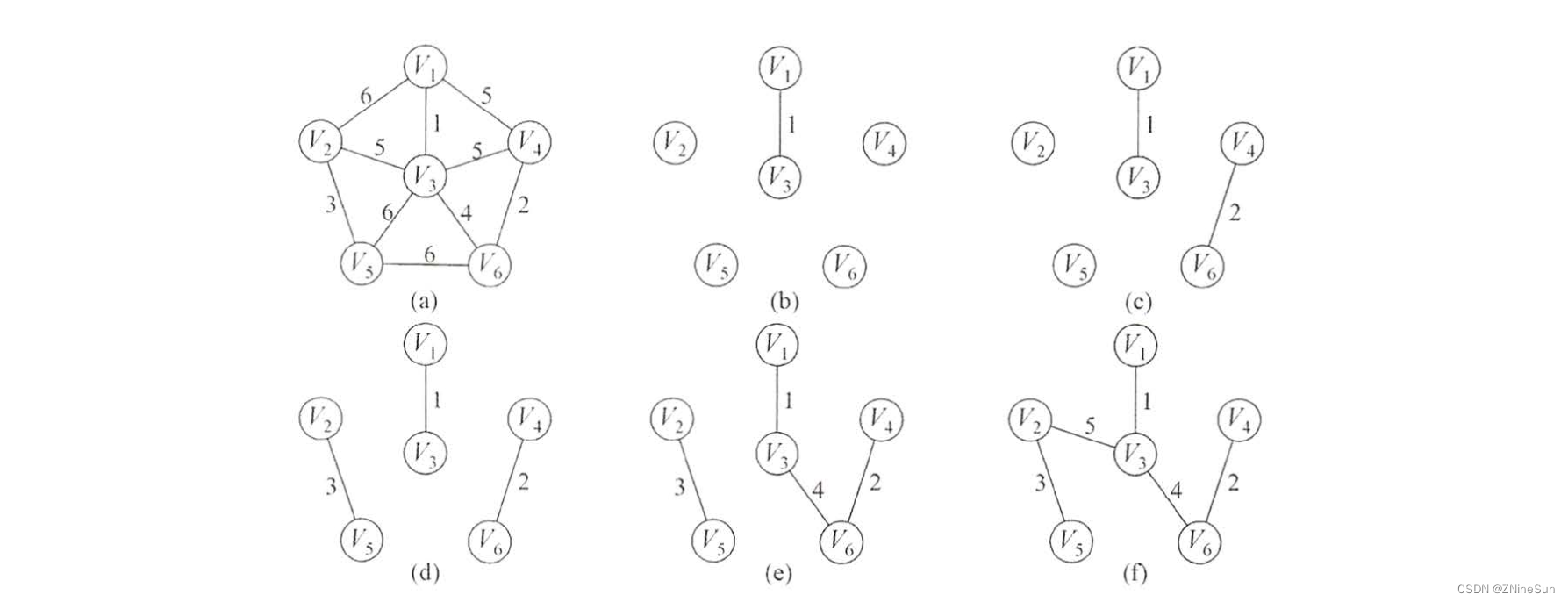
从上图我们可以看出,每次都是选择出代价最小的边。
根据图的相关性质,若一条边连接了两棵不同树中的顶点,则对这两棵树来说,它必定是连通的,将这条边加入森林中,完成两棵树的合并,
直到整个森林合并成一棵树。
通常在Kruskal 算法中,采用堆来存放边的集合,因此每次选择最小权值的边只需O(log|E|)的时间。此外,由于生成树T中的所有边可视为一个等价类,因此每次添加新的边的过程类似于求解等价类的过程,由此可以采用并查集的数据结构来描述T,从而构造T的时间复杂度为O(Elog|E|)。因此,Kruskal算法适合于边稀疏而顶点较多的图。
ps:相关文章推荐
2.最短路径
我们可能知道广度优先搜索可以查找最短路径,广度优先不知道的我大概说一下,广度优先搜索其本质就是层次遍历,同时广度优先搜索查找最短路径只是对无权图而言的。
当图是带权图时,把从一个顶点v0到图中其余任意一个顶点v1的一条路径(可能不止一条)所经过边上的权值之和,定义为该路径的带权路径长度,把带权路径长度最短的那条路径称为最短路径。
求解最短路径的算法通常都依赖于一种性质,即两点之间的最短路径也包含了路径上其他顶点间的最短路径。
带权有向图G的最短路径问题一般可分为两类:
- 一是单源最短路径
即求图中某一顶点到其他各顶点的最短路径,可通过经典的Dijkstra(迪杰斯特拉)算法求解; - 二是求每对顶点间的最短路径
可通过Floyd(弗洛伊德)算法来求解。
2.1 Dijkstra求解单源最短路径问题
Dijkstra 算法设置一个集合S记录已求得的最短路径的顶点,初始时把源点v0加入S,集合S每并入一个新顶点v,都要修改源点v0到集合V-S中顶点当前的最短路径长度值(这里可能不太好理解?没关系,等下就会清楚)。
我们还是老规矩,先从算法的流程入手: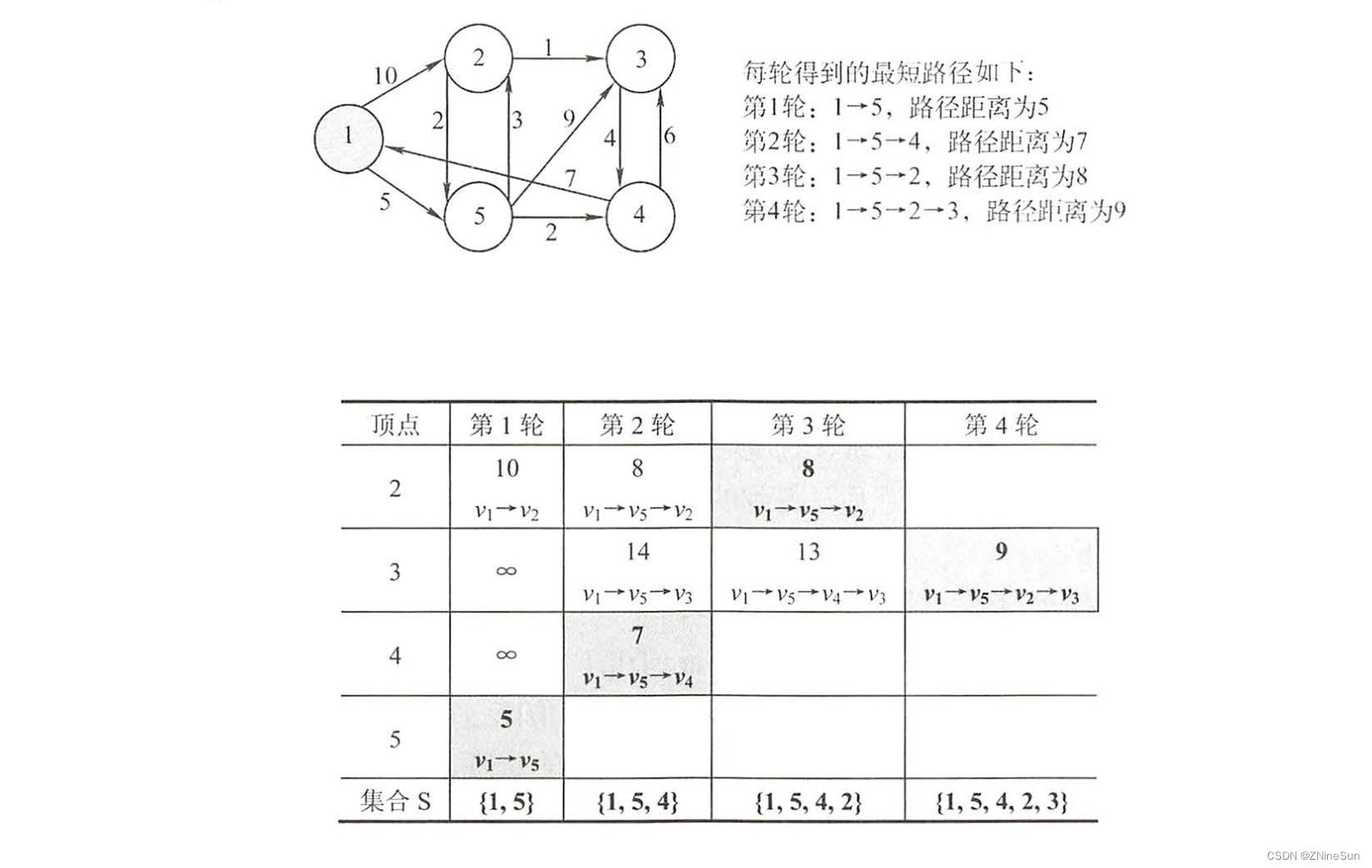
我们从上图可以看出,每一轮都会选出一个最短路径,然后把顶点加入到集合S里。
- 第一轮:v1->v5最短,S里有:{v1,v5}
- 第二轮:把所有v1,v5能到达的结点都要考虑进来,并选择一个最短的路径,从图中能看出v1->v5->v4是第二轮的最短路径,此时再把v4加入到集合S,此时S里有:{v1,v5,v4}
- 第三轮:把所有v1,v5,v4能到达的结点都要考虑进来,并选择一个最短的路径,从图中能看出v1->v5->v2是第三轮的最短路径,此时再把v2加入到集合S,此时S里有:{v1,v5,v4,v2}
- 第四轮,把所有v1,v5,v4,v2能到达的结点都要考虑进来,并选择一个最短的路径,从图中能看出v1->v5->v2->v3是第四轮的最短路径,此时再把v3加入到集合S,此时S里有:{v1,v5,v4,v2,v3}
至此节点全部加入了进来。
从上面的过程我们也不难看出,Dijkstra算法也是基于贪心策略的。
3.拓扑排序
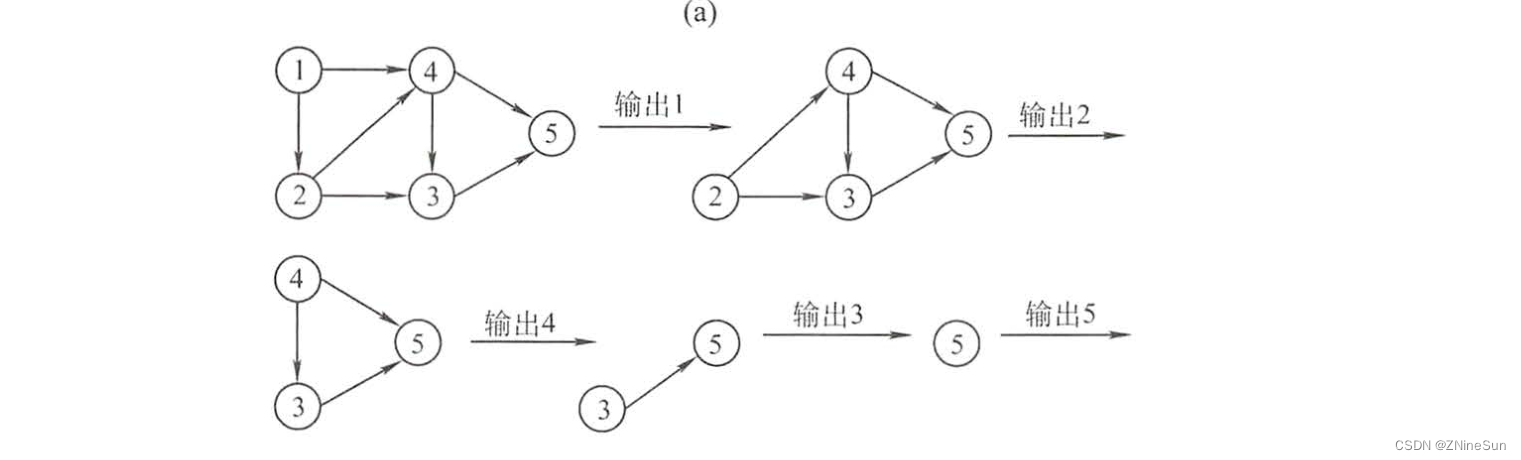
上图很清楚的描述了拓扑排序的过程,即每次挑选一个入度为0的点输出,然后删除该顶点,和以它为起点的有向边。
4.关键路径
在AOE 网中,有些活动是可以并行进行的。从源点到汇点的有向路径可能有多条,并且这些路径长度可能不同。完成不同路径上的活动所需的时间虽然不同,但是只有所有路径上的活动都已完成,整个工程才能算结束。因此,从源点到汇点的所有路径中,具有最大路径长度的路径称为关键路径,而把关键路径上的活动称为关键活动。
完成整个工程的最短时间就是关键路径的长度,即关键路径上各活动花费开销的总和。这是因为关键活动影响了整个工程的时间,即若关键活动不能按时完成,则整个工程的完成时间就会延长。因此,只要找到了关键活动,就找到了关键路径,也就可以得出最短完成时间。
我们先看几个定义,可能你现在看着这些 定义比较晦涩难懂,没有关系,我一会通过一个例子帮大家理解一下。
- 事件vK的最早发生时间:ve(k)
ve(k)=Max{ve(j)+Weight(vj,vk)}
其中:vk是为 vj的后继结点,Weight(vj,vk)是vj-vk的权重
是不是很难理解,没关系,你只需要记住是用最大值就好
- 时间vk的最迟发生时间:vl(k)
vl(k)=Min{vl(j)-Weight(vk,vj)}
同样 你只要记住我们要求vl,需要用到最小值
- 活动ai的最早开始时间e(i)
它是指该活动弧的起点所表示的事件的最早发生时间。若边<vk,vj>表示活动a;,则有e(i)= ve(k)。 - 活动ai的最迟开始时间l(i)
它是指该活动弧的终点所表示事件的最迟发生时间与该活动所需时间之差。若边<vk, vj>表示活动ai,则有l(i)= vl(j) - Weight(vk,vj) - 一个活动ai的最迟开始时间l(i)和其最早开始时间e(i)的差额d(i)=l(i)-e(i)
di只要为0,就是关键路径的一部分
是不是看懵啦,不要着急,你先只需要知道这五个名词就可以啦。
给出一个AOE网,计算该AOE的关键路径: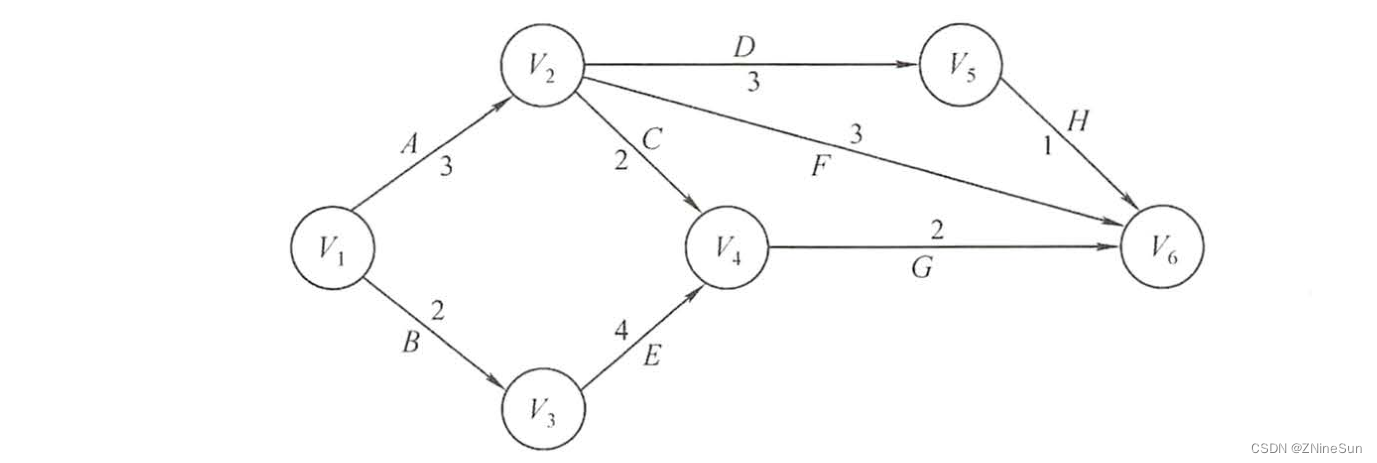
我们首先计算ve,在通过ve计算vl
这些值都是怎么计算的呢?
我们先来看看ve的计算过程,还记得我上面说过计算ve要用最大值,所以
- v2表示:v1->v2路径的最大值,从图中我们可以看出只有A这一条路径,路径权重为3,所以表格中的数据为3
- v3表示:v1->v3路径权重的最大值,很明显v1->v3也只有一条路径B,权重为2,所以结果为2
- v4表示:v1->v4路径权重最大值,v1->v4的路径有:v1->v2->v4(权重结果为:5)、v1->v3->v4(权重结果为:6),取最大值,所以结果为6
- v5表示:v1->v5路径权重最大值,v1->v5的路径有:v1->v2->v5,只有这一条,所以结果为6
- v6表示:v1->v6路径权重的最大值,v1->v6的路径有v1->v2->v5->v6(权重总和:7)、v1->v2->v6(权重总和:6)、v1->v2->v4->v6(权重总和:7)、v1->v3->v4->v6(权重总和:8),取最大值8,所以最终结果为8
有没有很简单了,好,我们在接着看看vl怎么计算的,计算vl我们需要倒着看,即从v6开始看,vl(6)=ve(6)=8直接填进去
- v5:v5->v6只有一条路径H,所以结果为8-1=7
- v4:v4->v6只有一条路径G,所以结果为8-2=6
- v3:v3->v6也只有一条路径及v3->v4->v6,所以结果为8-2-4=2
- v2:v2->v6:v2->v5->v6(8-1-3=4)、v2->v6(8-3=5)、v2->v4->v6(8-2-2=4)取最小值,所以结果为4
- v1:v1->v2->v5->v6(8-1-3-3=1)、v1->v2->v6(8-3-3=2)、v1->v2->v4->v6(8-2-3-3=0)、v1->v3->v4->v6(8-2-4-2=0),取最小值0,所以最终结果为0
接下来利用我们刚刚计算出的ve和vl继续计算e(i)、l(i)、d(i)
我们先看看e(i)怎么计算的
- A:是v1->v2之间的路径,所以e(A)=ve(v1)=0
- B:是v1->v3之间的路径,所以e(B)=ve(v1)=0
- C:是v2->v4之间的路径,所以e=ve(v2)=3
- D:是v2->v5之间的路径,所以e(D)=ve(v2)=3
- E:是v3->v4之间的路径,所以e(E)=ve(v3)=2
- F:是v2->v6之间的路径,所以e(F)=ve(v2)=3
- G:是v4->v6之间的路径,所以e(G)=ve(v4)=6
- H:是v5->v6之间的路径,所以e(H)=ve(v5)=6
是不是so easy!!!我们的任务还没结束,继续看l(i)怎么求得。
- A:是v1->v2之间的路径,所以l(A)=vl(v2)-Weight(A)=4-3=1
- B:是v1->v3之间的路径,所以l(B)=vl(v3)-Weight(B)=2-2=0
- C:是v2->v4之间的路径,所以l=vl(v4)-Weight=6-2=4
- D:是v2->v5之间的路径,所以l(D)=vl(v5)-Weight(D)=7-3=4
- E:是v3->v4之间的路径,所以l(E)=vl(v4)-Weight(E)=6-4=2
- F:是v2->v6之间的路径,所以l(F)=vl(v6)-Weight(F)=8-3=5
- G:是v4->v6之间的路径,所以l(G)=vl(v6)-Weight(G)=8-2=6
- H:是v5->v6之间的路径,所以l(H)=vl(v6)-Weight(H)=8-1=7
现在就差d(i),d(i)没啥好说的,直接让l(i)-e(i)即可
最终我们只要找到d(i)=0的边:B、E、G
所对应的路径为:v1->v3->v4->v6
边栏推荐
- 80% of the diseases are caused by bad living habits. There are eight common bad habits, which are both physical and mental
- 登录mysql输入密码时报错,ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: NO/YES
- Serial port-rs232-rs485-ttl
- AcWing 243. A simple integer problem 2 (tree array interval modification interval query)
- asp. Core is compatible with both JWT authentication and cookies authentication
- 2/10 parallel search set +bfs+dfs+ shortest path +spfa queue optimization
- Ethernet port &arm & MOS &push-pull open drain &up and down &high and low sides &time domain and frequency domain Fourier
- 脚本生命周期
- 【FPGA教程案例12】基于vivado核的复数乘法器设计与实现
- Security xxE vulnerability recurrence (XXe Lab)
猜你喜欢

Blue Bridge Cup - Castle formula

How does technology have the ability to solve problems perfectly
lora网关以太网传输
【按鍵消抖】基於FPGA的按鍵消抖模塊開發
AcWing 243. A simple integer problem 2 (tree array interval modification interval query)
在 .NET 6 中使用 Startup.cs 更简洁的方法

综合能力测评系统
Le compte racine de la base de données MySQL ne peut pas se connecter à distance à la solution
Redis (replicate dictionary server) cache
After five years of testing in byte, I was ruthlessly dismissed in July, hoping to wake up my brother who was paddling
随机推荐
C#(二十七)之C#窗体应用
MySQL master-slave replication
math_极限&微分&导数&微商/对数函数的导函数推导(导数定义极限法)/指数函数求导公式推导(反函数求导法则/对数求导法)
2/10 parallel search set +bfs+dfs+ shortest path +spfa queue optimization
Ybtoj coloring plan [tree chain dissection, segment tree, tarjan]
简易博客系统
Prime Protocol宣布在Moonbeam上的跨链互连应用程序
Class A, B, C networks and subnet masks in IPv4
mysql关于自增长增长问题
Viewing and verifying backup sets using dmrman
【leetcode】1189. Maximum number of "balloons"
如何修改表中的字段约束条件(类型,default, null等)
P2648 make money
No qualifying bean of type ‘......‘ available
[analysis of variance] single factor analysis and multi factor analysis
Cf603e pastoral oddities [CDQ divide and conquer, revocable and search set]
Benefits of automated testing
Database, relational database and NoSQL non relational database
User experience index system
Differential GPS RTK thousand search