当前位置:网站首页>JVM的手术刀式剖析——一文带你窥探JVM的秘密
JVM的手术刀式剖析——一文带你窥探JVM的秘密
2022-07-06 03:39:00 【十叶知秋】
文章目录
一、JVM的执行流程
- 程序在执行之前先要把java代码转换成字节码(class文件)
- JVM 首先需要把字节码通过一定的方式类加载器(ClassLoader) 把文件加载到内存中运行时数据区(Runtime Data Area)
- 字节码文件是 JVM 的一套指令集规范,并不能直接交个底层操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine)将字节码翻译成底层系统指令再交由CPU去执行
- 这个过程中需要调用其他语言的接口本地库接口(Native Interface)来实现整个程序的功能,这就是这4个主要组成部分的职责与功能。
图解如下:
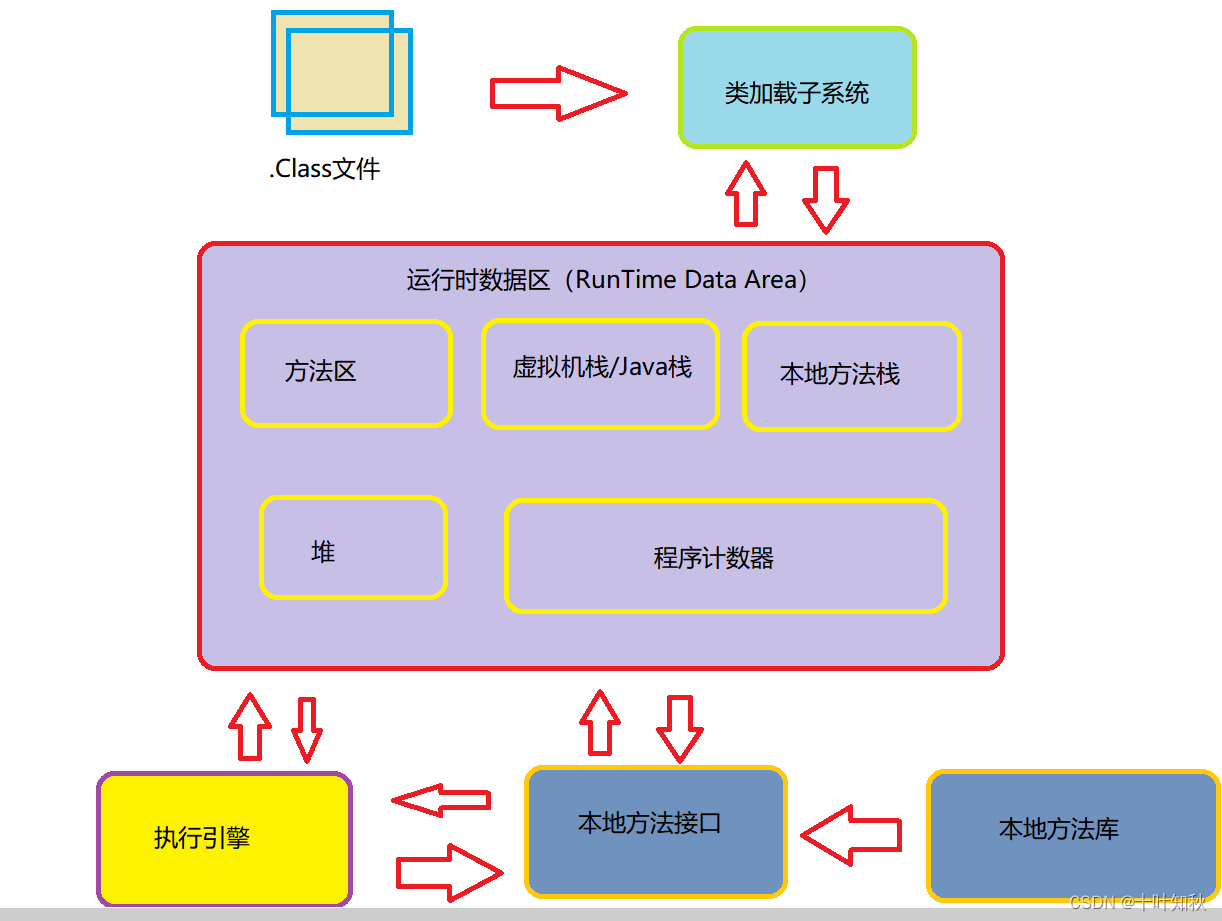
可以看到,JVM主要是通过四个部分来执行Java程序的:
- 类加载器(ClassLoader)
- 运行时数据区(Runtime Data Area)
- 执行引擎(Execution Engine)
- 本地库接口(Native Interface)
下面分别详细介绍这些内容。
二、 JVM 运行时数据区
JVM 运行时数据区域也叫内存布局,但需要注意的是它和 Java 内存模型((Java Memory Model,简称JMM)完全不同,属于完全不同的两个概念。
从下图我们可以看到,这个运行时数据区有五大部分组成,分别是方法区、虚拟机栈、本地方法栈、堆、程序计数器。
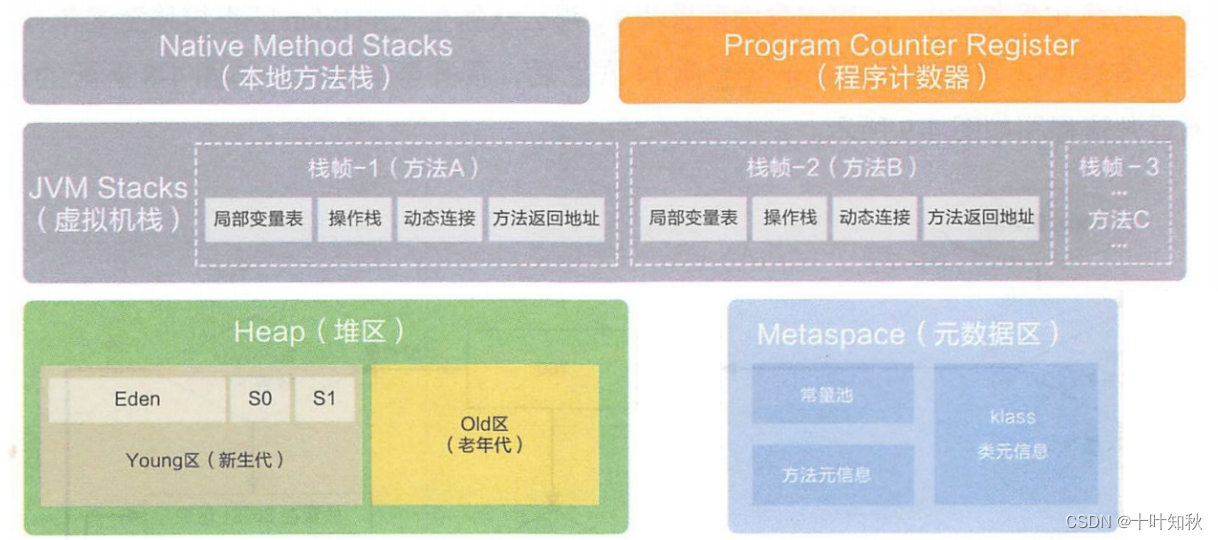
下面一一介绍这五部分具体干啥的。这里先插入一个知识点——线程私有。
由于JVM的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现,因此在任何一个确定的时刻,一个处理器(多核处理器则指的是一个内核)都只会执行一条线程中的指令。因此为了切换线程后能恢复到正确的执行位置,每条线程都需要独立的程序计数器,各条线程之间计数器互不影响,独立存储。我们就把类似这类区域称之为"线程私有"的内存。
1.程序计数器(线程私有)
作用:
内存中最小的区域,保存了下一条指令的具体在哪。
这里面的指令就是字节码,当程序运行的时候,JVM就会把这些字节码加载起来,放到内存中,然后程序就会一条一条地把这些指令(字节码)从内存中取出来,放到CPU上执行。
正是上述这个原因,才需要记住当前执行到哪一条指令了,因此需要程序计数器来记录。
而我们的计算机大脑CPU是并发式的执行程序,需要负责所有的线程。而操作系统是以线程为单位进行调度执行的,每个线程都得记录自己的执行位置,因此,每个线程都会分配有一个程序计数器。
如果当前线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是一个Native方法,这个计数器值为空。
2.栈(线程私有)
作用:
简单来说就是存放局部变量和方法调用信息。每次调用一个新的方法,都会涉及到一次“入栈”的操作,每次执行完一个方法,都会涉及到“出栈”的操作。栈也是每个线程都有一份。
举个例子: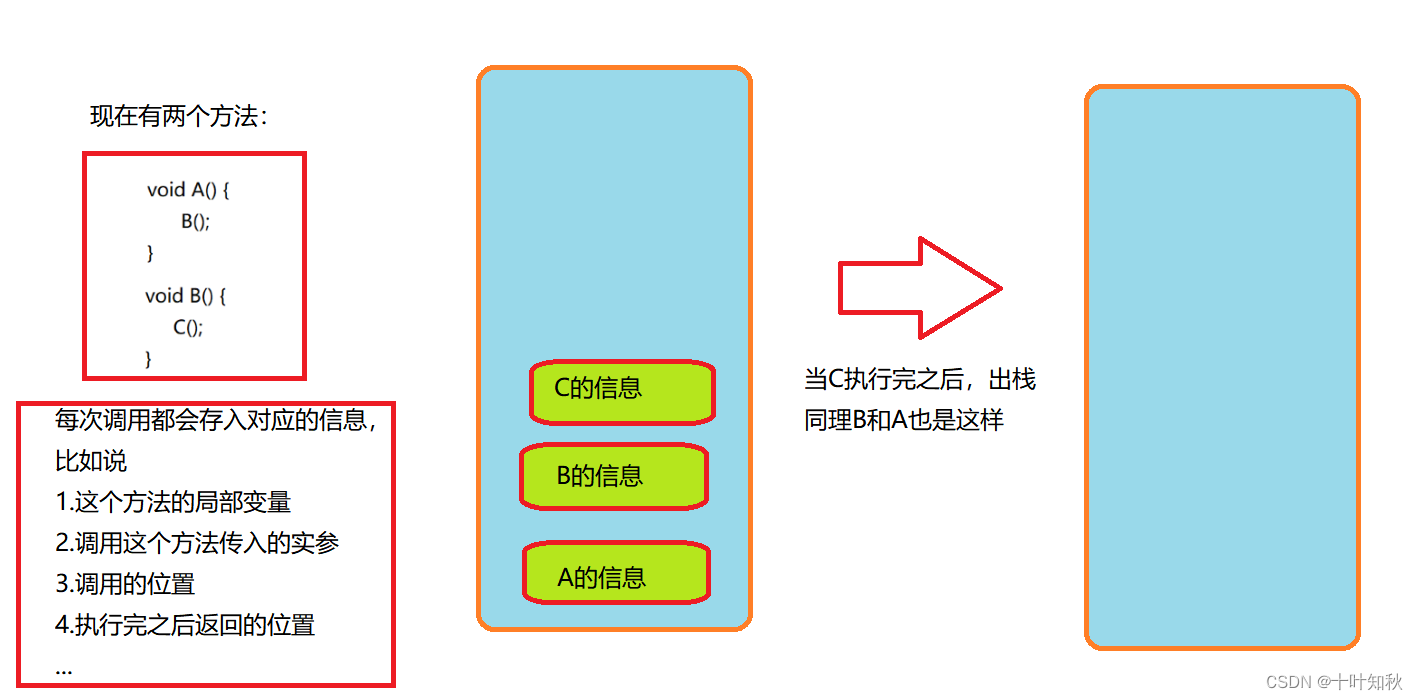
上面的一个一个绿色块,我们称之为“栈帧”。每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息(实际上就是上图左下角框框的内容)。咱们常说的堆内存、栈内存中,栈内存指的就是虚拟机栈。
学术一点来解释:
- 局部变量表: 存放了编译器可知的各种基本数据类型(8大基本数据类型)、对象引用。局部变量表
所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变
量空间是完全确定的,在执行期间不会改变局部变量表大小。简单来说就是存放方法参数和局部变
量。 - 操作栈:每个方法会生成一个先进后出的操作栈。
- 动态链接:指向运行时常量池的方法引用。
- 方法返回地址:PC 寄存器的地址
实际上,栈的空间是比较小的,尽管在JVM中可以配置栈空间的大小,但是一般来说也就是几M到几十M,因此栈是很可能会满的,这个时候就是栈溢出了。
这里的栈分为Java虚拟机栈和本地方法栈。 Java 虚拟机栈是给 JVM 使用的,而本地方法栈是给本地方法使用的。二者区别不大。
3.堆(线程共享)
堆的作用:
程序中创建的所有对象都在保存在堆中。
一个进程堆只有一份,多个线程共同用一个堆。当我们new一个对象的时候,这个new出来的对象就在堆上,并且对象的成员变量也在堆上。而局部变量在栈上。
堆里面分为两个区域:新生代和老生代,新生代放新建的对象,当经过一定 GC (垃圾回收)次数之后还存活的对象会放入老生代。新生代还有 3 个区域:一个 Endn + 两个 Survivor(S0/S1)。
4.方法区(线程共享)
方法区的作用:
用来存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据的。
.java 文件运行时会被执行成 .class文件 (二进制字节码),.class 会被加载到内存中,也就被JVM构造成了类对象(加载的过程就称为"类加载")
这里的类对象,就是放到方法区中。
我们的类对象就描述了这个类长啥样,包括类的名字是啥,里面有哪些成员,有哪些方法,每个成员叫啥名字是啥类型, 是public还是private,每个方法叫啥名字,是啥类型, 是public还private,方法里面包含的指令…
类对象里还有个很重要的东西,静态成员。static修饰的成员,成为了"类属性"。而普通的成员,叫做“实例属性"。
三、JVM 类加载
简单来说:类加载其实就是设计一个运行时环境的重要核心功能。Java能够一次编译到处运行,重要的一环就是类加载。
1.类加载的执行流程
对于一个类来说,它的生命周期是:加载,连接,初始化,使用,卸载。其中连接包含有:验证,准备、解析三个部分。
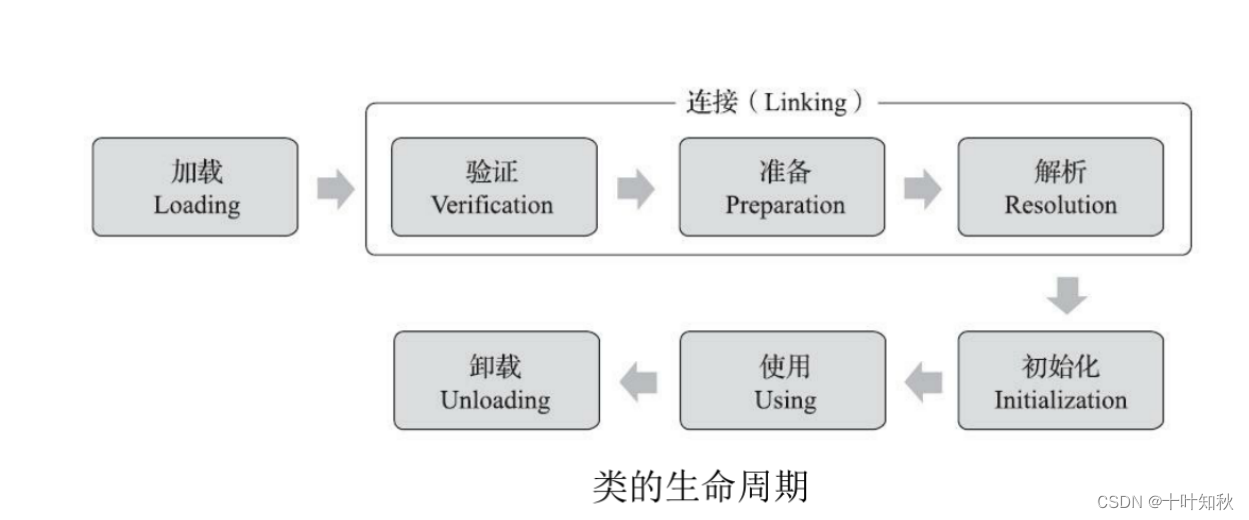
对于上图,前5 步是固定的顺序并且也是类加载的过程,其中中间的 3 步我们都属于连接,所以对于类加载来说总共分为以下几个步骤:
- 加载
- 连接
(1) 验证
(2)准备
(3)解析 - 初始化
1.1. 加载(Loading)
【注意】“加载”(Loading)不是个“类加载”(Class Loading),二者是不同的。“加载”(Loading)阶段是整个“类加载”(Class Loading)过程中的一个阶段。
在 加载(Loading)阶段,Java虚拟机需要完成以下三件事情:
- 通过一个类的全限定名,来获取定义此类的二进制字节流
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据结构的访问入口。
1.2.验证(Verification)
验证是连接阶段的第一步,这一阶段的目的是确保Class文件的字节 流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。如果发现这里读到的数据格式不符合规范,就会类加载失败,并且抛出异常。
验证选项:
- 文件格式验证
- 字节码验证
- 符号引用验证…
1.3. 准备(Preparation)
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段。
1.4. 解析(Resolution)
解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
.class文件中,常量是集中放置的,每个常量有一个编号。.class文件的结构体里初始情况下只是记录了编号.就需要根据编号找到对应的内容,填充到类对象中。
1.5.初始化(Initializing)
初始化阶段,Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程。
2.经典面试题
写出下面程序运行的结果: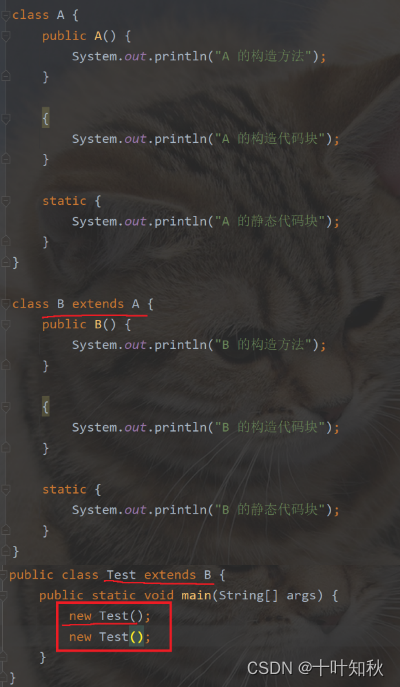
解题思路:
- 类加载阶段会进行静态代码块的执行.要想创建实例,势必要先进行类加载
- 静态代码块只是类加载阶段执行一次
- 构造方法和构造代码块,每次实例化都会执行,构造代码块在构造方法前面
- 父类执行在前,子类执行在后
- 咱们的程序是从main开始执行.main这里是Test的方法.因此要执行main,就需要先加载Test.
因此答案:
3.双亲委派模型
双亲委派模型是类加载中的一个环节,这个环节处于Loading阶段的(
双亲委派模型,描述的就是JVM中的类加载器,如何根据类的全限定名( java.lang.String )找到.class文件的过程。
JVM里提供了专门的对象,叫做类加载器,负责进行类加载.当然找文件的过程也是类加载器来负责的。class文件,可能放置的位置有很多.有的要放到JDK目录里,有的放到项目目录里,还有的在其他特定位置…
因此,JVM里面提供了多个类加载器,每个类加载器负责一个片区。默认的类加载器,主要是3个:
- BootStrapClassLoader:负责加载标准库中的类(String,ArrayList, Random, Scanner…)
- ExtensionClassLoader:负责加载JDK扩展的类.(现在很少会用到)
- ApplicationClassLoader:负责加载当前项目目录中的类
程序猿还可以自定义类加载器,来加载其他目录中的类,比如Tomcat就自定义了类加载器,用来专门加载webapps 里面的.class 。
简单来说:
双亲委派模型,就描述了这个找目录过程,也就是上述类加载器是如何配合的。
3.1.什么是双亲委派模型
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
步骤:
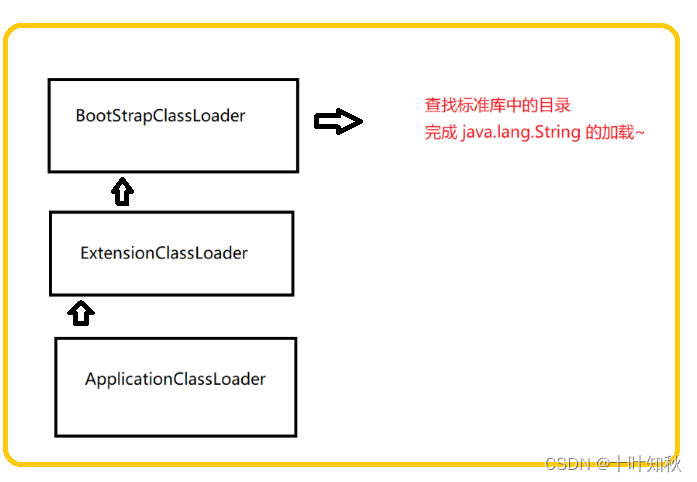
- 考虑加载java.lang.String
a.程序启动,先进入ApplicationClassLoader类加载器
b.ApplicationClassLoader就会检查下,它的父加载器是否已经加载过了.如果没有,就调用父类加载器ExtensionClassLoaderc. ExtensionClassLoader也会检查下,它的父加载器是否加载过了.如果没有,就调用父类加载器BootStrapClassLoader
d. BootStrapClassLoader 也会检查下,它的父加载器是否加载过,自己没有父亲于是自己扫描自己负责的目录
e.java.lang.String这个类在标准库中能找到.直接由BootStrapClassLoader负责后续的加载过程.查找环节就结束了。
- 考虑加载自己写的Test类~
a.程序启动,先进入ApplicationClassLoader类加载器
b.ApplicationClassLoader就会检查下,它的父加载器是否已经加载过了.如果没有,就调用父类加载器ExtensionClassLoaderc. ExtensionClassLoader也会检查下,它的父加载器是否加载过了.如果没有,就调用父类加载器BootStrapClassLoader
d.BootStapGlss.oader 也会检查下,它的父加载器是否加载过,自己没有父亲。于是自己扫描自己负责的目录。没扫描到!回到子加载器继续扫描
e. ExtensionClassLoader 也扫描自己负责的目录,也没扫描到,回到子加载器继续扫描.
f. ApplicationClassLoader 也扫描自己负责的目录,能找到Test类,于是进行后续加载.查找目录的环节结束.
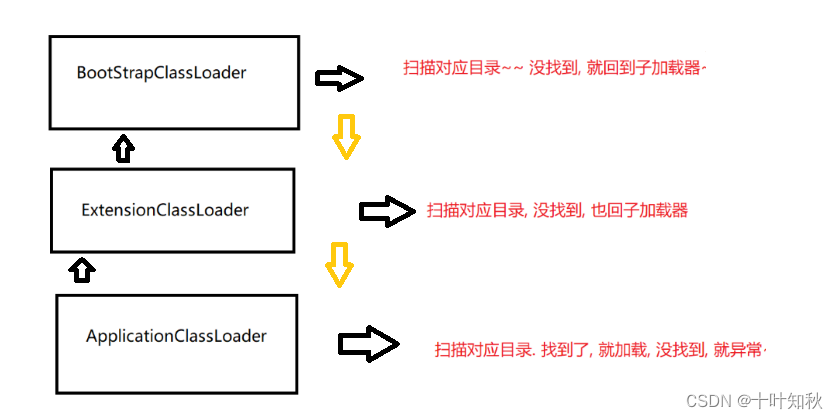
上述的这一套查找规则,就被称为“双亲委派模型”。
3.2.双亲委派模型的优点
- 避免重复加载类:比如 A 类和 B 类都有一个父类 C 类,那么当 A 启动时就会将 C 类加载起来,那么在 B 类进行加载时就不需要在重复加载 C 类了。
- 安全性:使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改,如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object 类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,而有些 Object 类又是用户自己提供的因此安全性就不能得到保证了。
完!
边栏推荐
- The next industry outlet: NFT digital collection, is it an opportunity or a foam?
- BUAA喜鹊筑巢
- [American competition] mathematical terms
- [risc-v] external interrupt
- C language judgment, ternary operation and switch statement usage
- Deep parsing pointer and array written test questions
- 【RISC-V】外部中断
- 1. New project
- How do we make money in agriculture, rural areas and farmers? 100% for reference
- An article about liquid template engine
猜你喜欢
Tomb. Weekly update of Finance (February 7 - February 13)
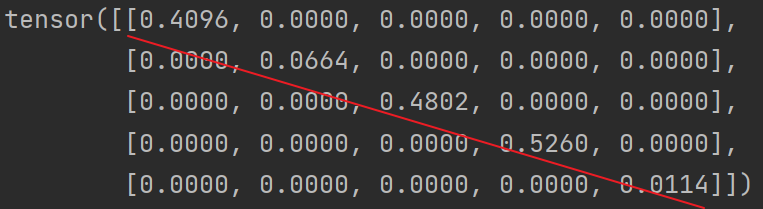
Pytorch基础——(1)张量(tensor)的初始化

Schnuka: 3D vision detection application industry machine vision 3D detection
![[optimization model] Monte Carlo method of optimization calculation](/img/e6/2865806ffbbfaa8cc07ebf625fcde6.jpg)
[optimization model] Monte Carlo method of optimization calculation
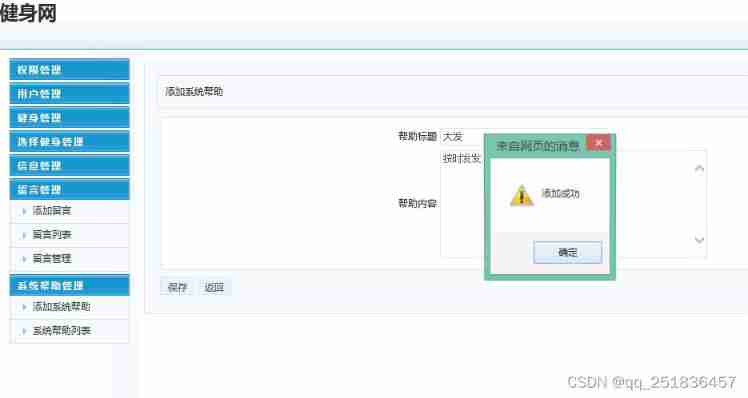
Computer graduation project asp Net fitness management system VS development SQLSERVER database web structure c programming computer web page source code project
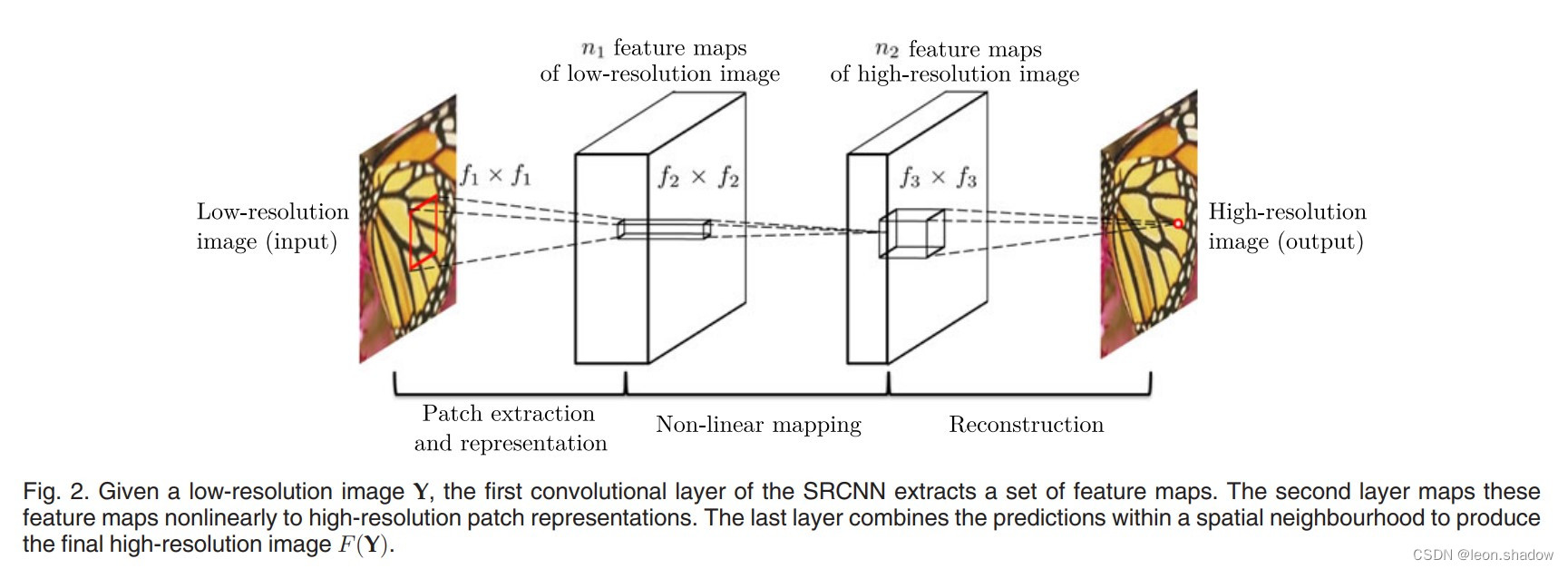
Image super resolution using deep revolutionary networks (srcnn) interpretation and Implementation

Esbuild & SWC: a new generation of construction tools

Svg drag point crop image JS effect
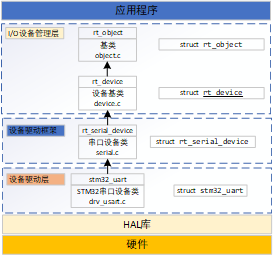
3.1 detailed explanation of rtthread serial port device (V1)
LTE CSFB test analysis
随机推荐
Svg drag point crop image JS effect
Image super resolution using deep revolutionary networks (srcnn) interpretation and Implementation
[practice] mathematics in lottery
svg拖动点裁剪图片js特效
JS音乐在线播放插件vsPlayAudio.js
Schnuka: what is visual positioning system and how to position it
Getting started with applet cloud development - getting user search content
Restful style
[American competition] mathematical terms
C language judgment, ternary operation and switch statement usage
SAP ALV颜色代码对应颜色(整理)
指针笔试题~走近大厂
[slam] lidar camera external parameter calibration (Hong Kong University marslab) does not need a QR code calibration board
Schnuka: visual positioning system working principle of visual positioning system
Four logs of MySQL server layer
Failure causes and optimization methods of LTE CSFB
Suggestions for new engineer team members
User perceived monitoring experience
[rust notes] 18 macro
Indicator system of KQI and KPI