当前位置:网站首页>Image super resolution using deep revolutionary networks (srcnn) interpretation and Implementation
Image super resolution using deep revolutionary networks (srcnn) interpretation and Implementation
2022-07-06 03:27:00 【leon. shadow】
Image super-resolution using deep convolutional networks(SRCNN)
One 、 summary
Network structure
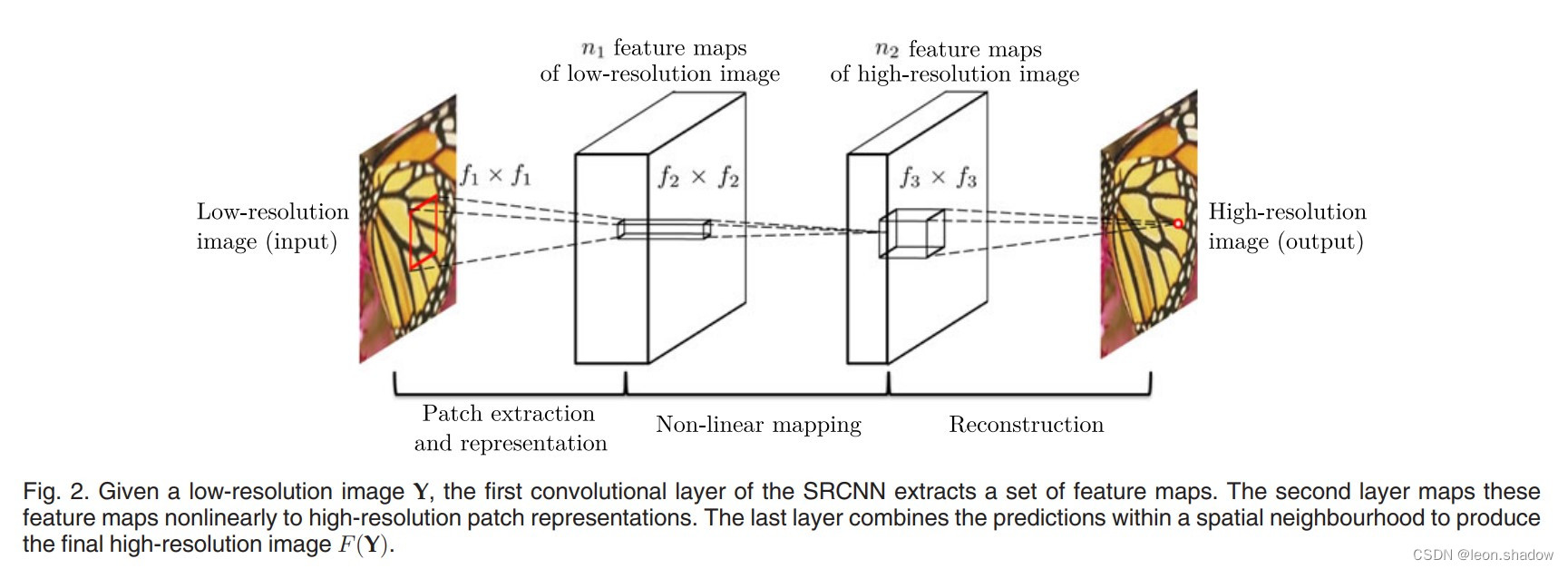
SRCNN The network structure is relatively simple , It is a three-layer convolution network , Activation function selection Relu.
- The first convolution : Realize the extraction of image features .( The number of convolution kernels is 64, The size is 9)
- The second convolution : Nonlinear mapping of features extracted from the first layer convolution .( The number of convolution kernels is 32, The size is 1[ original text ])
- The third convolution : Reconstruct the mapped features , Generate high resolution images ..( The number of convolution kernels is 1, The size is 5)
The evaluation index
PSNR( Peak signal to noise ratio ):PSNR The bigger the value is. , The better the reconstruction .
import numpy
import math
def psnr(img1, img2):
mse = numpy.mean( (img1 - img2) ** 2 )
if mse == 0:
return 100
PIXEL_MAX = 255.0
return 20 * math.log10(PIXEL_MAX / math.sqrt(mse))
Why only train YCbCr Of Y passageway ?
The image is converted into YCbCr Color space , Although the network only uses brightness channels (Y). then , The output of the network merges interpolated CbCr passageway , Output the final color image . We chose this step because we are not interested in color changes ( Stored in CbCr Information in the channel ) But only its brightness (Y passageway ); The fundamental reason is that compared with color difference , Human vision is more sensitive to brightness changes .
Loss function
The loss function is the mean square error (MSE)
1×1 The function of convolution ?
- Realize the change of dimension ( Increase or decrease dimension )
- Realize cross channel interaction and information integration
- Reduce computation
- It can achieve the effect equivalent to the full connection layer
Two 、 Code
model.py
from torch import nn
class SRCNN(nn.Module):
def __init__(self, num_channels=1):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 64, kernel_size=9, padding=9 // 2)
self.conv2 = nn.Conv2d(64, 32, kernel_size=5, padding=5 // 2)
self.conv3 = nn.Conv2d(32, num_channels, kernel_size=5, padding=5 // 2)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.conv3(x)
return x
In order to avoid boundary effect, the original text did not add padding, Instead, when calculating the loss value, only the pixels in the central area are calculated . The original text is not added padding, The size of the original drawing has passed srcnn Three-layer convolution of , The resolution will become smaller .
3、 ... and 、 experiment
Compare the convolution kernel size (filter size)、 Number of convolution nuclei (filter numbers) Experiment on the effect of restoration
Conclusion : The more convolution kernels , That is, the higher the dimension of the eigenvector , The better the experimental effect , But it will affect the speed of the algorithm , Therefore, comprehensive consideration is needed ; The larger the convolution kernel size of the other three convolution layers , The experimental effect will be slightly better , It will also affect the speed of the algorithm .
Compare the network layers (layer numbers) Experiment on the effect of restoration
Conclusion : Not the deeper the network , The better the result. , The opposite is true . The author also gives an explanation : because SRCNN There is no pooling layer and full connectivity layer , As a result, the network is very sensitive to initial parameters and learning rate , The result is that it is very difficult to converge during network training , Even if it converges, it may stop at the bad local minimum (bad local minimum) It's about , And even if you train enough time , Learned filter The dispersion of parameters is not good enough .
Experiment on the effect of channel on restoration
Conclusion :RGB Channel joint training is the best ;YCbCr Under the channel ,Cb、Cr Channels are basically not helpful for performance improvement , Based on Y The training effect of channel is better .
Four 、 Conclusion
SRCNN Propose a lightweight end-to-end network SRCNN To solve the super score problem , Indeed, at that time, it achieved better performance than traditional methods 、 Faster effect , In addition, the author will be based on SC( Sparse coding ) The super division method of is understood as a form of convolutional neural network , Are all highlights worth reading .
5、 ... and 、 Address of thesis
Address of thesis :https://arxiv.org/abs/1501.00092
边栏推荐
- 1.16 - check code
- 暑期刷题-Day3
- Princeton University, Peking University & UIUC | offline reinforcement learning with realizability and single strategy concentration
- Introduction to DeNO
- Svg drag point crop image JS effect
- Erreur de la carte SD "erreur - 110 whilst initialisation de la carte SD
- Eight super classic pointer interview questions (3000 words in detail)
- MPLS experiment
- 遥感图像超分辨重建综述
- 施努卡:什么是视觉定位系统 视觉系统如何定位
猜你喜欢

Pointer written test questions ~ approaching Dachang
【概念】Web 基础概念认知
Edcircles: a real time circle detector with a false detection control translation
![[slam] lidar camera external parameter calibration (Hong Kong University marslab) does not need a QR code calibration board](/img/07/973722bf484b374f752177dfc48ef5.png)
[slam] lidar camera external parameter calibration (Hong Kong University marslab) does not need a QR code calibration board
Who is the winner of PTA
Cubemx 移植正点原子LCD显示例程
![[risc-v] external interrupt](/img/9d/eb1c27e14045d9f1f690f4a7f5c596.jpg)
[risc-v] external interrupt
Force buckle 1189 Maximum number of "balloons"
真机无法访问虚拟机的靶场,真机无法ping通虚拟机
js凡客banner轮播图js特效
随机推荐
2022工作中遇到的问题四
1003 emergency (25 points), "DIJ deformation"
适合程序员学习的国外网站推荐
Leetcode problem solving -- 98 Validate binary search tree
Esbuild & SWC: a new generation of construction tools
Eight super classic pointer interview questions (3000 words in detail)
1、工程新建
Tidb ecological tools (backup, migration, import / export) collation
How to do function test well
three.js网页背景动画液态js特效
2. GPIO related operations
遥感图像超分辨率论文推荐
Pytorch load data
Pelosi: Congress will soon have legislation against members' stock speculation
How to write compile scripts compatible with arm and x86 (Makefile, cmakelists.txt, shell script)
Force buckle 1189 Maximum number of "balloons"
JS音乐在线播放插件vsPlayAudio.js
NR modulation 1
2.2 STM32 GPIO operation
11. Container with the most water