当前位置:网站首页>Résumé des méthodes de reconnaissance des caractères ocr
Résumé des méthodes de reconnaissance des caractères ocr
2022-07-06 03:02:00 【GOAI】
OCRIntroduction à la technologie de reconnaissance de texte:
1️⃣OCRTechnologie de reconnaissance de texte chapitre 1:OCRRésumé de la technologie de reconnaissance de texte(Un.)
2️⃣OCRTechnologie de reconnaissance de texte chapitre 2:OCRRésumé de la technologie de reconnaissance de texte(2.)
3️⃣OCRTechnologie de reconnaissance de texte chapitre 3:OCRRésumé de la technologie de reconnaissance de texte(Trois)
4️⃣OCRChapitre 4 de la série sur les techniques de reconnaissance des caractères:OCRRésumé de la technologie de reconnaissance de texte(Quatre)
5️⃣OCRTechnologie de reconnaissance de texte chapitre 5:OCRRésumé de la technologie de reconnaissance de texte(Cinq)
OCR Résumé des articles classiques dans le domaine de la reconnaissance de texte :
1️⃣OCR Description détaillée de la thèse classique de reconnaissance de texte
OCR Résumé des méthodes de reconnaissance des caractères
Cueillir Oui.: La reconnaissance de texte peut convertir de grandes quantités de données non structurées en données structurées , Pour soutenir une variété d'applications innovantes de l'intelligence artificielle , Est l'une des branches de la vision informatique , Sa tâche est de reconnaître le contenu textuel d'une image , En général, l'entrée provient d'une zone de texte d'image coupée à partir d'une zone de texte détectée. .Ces dernières années, Le modèle d'algorithme de reconnaissance de texte basé sur l'apprentissage profond a obtenu de bons résultats , Le processus n'a pas besoin de traitement des caractéristiques et peut réaliser la reconnaissance de texte de scène complexe , L'effet est meilleur que la méthode traditionnelle de reconnaissance des caractères , Devenir progressivement le principal moyen de recherche et d'application de la reconnaissance des caractères . Cet article présente principalement un aperçu de la technologie de reconnaissance de texte basée sur l'apprentissage profond , Classifier et résumer l'algorithme classique de reconnaissance de texte courant , .Discuter de l'évolution et de la tendance de la recherche dans le domaine de la reconnaissance des caractères à l'avenir .
Mots clés:OCR,Apprentissage profond,Reconnaissance de scène,CTC
1.Introduction
Les mots sont des pensées humaines 、 Vecteur indispensable du patrimoine intellectuel et culturel , C'est aussi un important vecteur d'échange d'informations humaines et de perception du monde . L'ère de l'information sur Internet génère chaque jour un grand nombre de factures 、Formulaire、 Données relatives aux documents , À ce stade, il est nécessaire d'utiliser la technologie de reconnaissance de texte pour extraire et saisir , Les données électroniques jouent un rôle important dans l'amélioration de l'efficacité de la production des entreprises. .Technologie de reconnaissance de texte(optical character recognition,OCR) Il s'agit de l'utilisation de la technologie optique et de la technologie informatique pour détecter les mots dans les images. , Puis reconnaître le contenu du texte dans l'image , Est l'une des branches de la vision informatique [1]. Le concept 1929 Par des scientifiques allemands Tausheck Premier dépôt et dépôt d'un brevet , Après près d'un siècle de développement ,OCR La reconnaissance de texte a donné de bons résultats dans tous les domaines . Il existe de nombreux scénarios d'application de la reconnaissance de texte , Identification des documents 、 Identification des panneaux routiers 、Reconnaissance des plaques d'immatriculation、 Identification du numéro industriel, etc. , Actuellement en traitement médical 、 L'éducation et d'autres industries sont largement utilisées , Son traitement d'image numérique intégré 、 Connaissance théorique de l'infographie et de l'intelligence artificielle , De plus en plus au centre de l'attention dans le domaine de l'intelligence artificielle .La traditionOCR La technologie de reconnaissance, bien qu'elle ait atteint un niveau élevé de précision dans des scénarios spécifiques aux caractères imprimés , Cependant, il est éclairé dans des scènes complexes 、Forme、 Le flou et d'autres problèmes conduisent à une faible précision de reconnaissance .Ces dernières années, Avec l'apprentissage profond devenant la dernière tendance dans le domaine de l'apprentissage automatique et de l'intelligence artificielle , Le modèle d'algorithme de reconnaissance de texte basé sur l'apprentissage profond a obtenu de bons résultats , Le processus n'a pas besoin de traitement des caractéristiques et peut réaliser la reconnaissance de texte de scène complexe , L'effet est meilleur que la méthode traditionnelle de reconnaissance des caractères , Devenir progressivement le principal moyen de recherche et d'application de la reconnaissance des caractères .
2. Situation actuelle de la recherche sur la reconnaissance des caractères fondée sur l'apprentissage profond
La traditionOCR La reconnaissance de texte est un processus qui considère la reconnaissance de caractère de la ligne de texte comme une tâche d'apprentissage Multi - étiquettes .Comme le montre la figure1Comme indiqué, Son processus de reconnaissance est le prétraitement de l'image (Grisement de l'image couleur、Traitement binaire、Images Détection de l'angle de changement 、 Traitement correctif, etc. )、 Mise en page (Détection en ligne droite、 Détection de l'inclinaison )、 Segmentation du positionnement des caractères 、Les caractères Identification、 Récupération de la mise en page 、Post - traitement、 Équivalence scolaire . Reconnaissance traditionnelle des caractères Vous devez d'abord localiser la zone de texte , Corriger le texte en pente positionné et diviser le texte en un seul texte , Ensuite, utilisez les caractéristiques humaines HOGOuCNNCaractéristiques, Reconnaissance des mots en combinaison avec le modèle de classification , Enfin, sur la base du Modèle linguistique statistique ( Comme la chaîne de Markov cachée ,HMM) Ou des règles pour corriger les erreurs sémantiques , C'est - à - dire le post - traitement des règles linguistiques .La traditionOCR L'algorithme de reconnaissance de texte est principalement basé sur la technologie de traitement d'image ( Comme une projection 、Gonflement、Rotation, etc)Et l'apprentissage automatique statistique(Adaboot、SVM) Réalisation de l'extraction de texte d'image [2], Il est principalement utilisé pour une seule couleur de fond 、 Reconnaissance d'images de documents simples à haute résolution .

Fig.1 Flux des méthodes traditionnelles de reconnaissance des caractères
Dans un scénario complexe ,La traditionOCR La précision d'identification est difficile à satisfaire aux exigences d'application pratique , Et basé sur l'apprentissage profond OCR Meilleure performance que les méthodes traditionnelles [3]. .La reconnaissance de texte basée sur l'apprentissage en profondeur utilise la capacité d'algorithme du modèle , Remplacer les méthodes manuelles traditionnelles , Détecter automatiquement la catégorie et l'emplacement du texte , Reconnaître automatiquement le contenu du texte en fonction des informations textuelles de l'emplacement correspondant . La plupart des algorithmes actuels de reconnaissance de l'apprentissage en profondeur comprennent la correction d'image 、Extraction des caractéristiques、 Prévision des séquences, etc. , Le processus d'identification est illustré dans le diagramme. 2Comme indiqué.
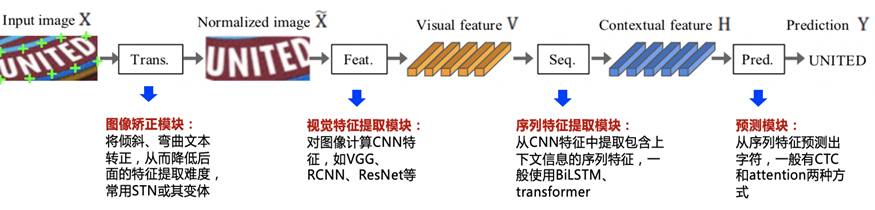
Fig.2 Processus de reconnaissance des caractères dans l'apprentissage profond courant
2006 Année Hinton Présentation“Apprentissage profond”Début du concept[4], Les méthodes de recherche sur l'apprentissage profond commencent à être largement utilisées dans divers domaines industriels . Avec le développement de la technologie de l'intelligence artificielle au cours des dernières années , La reconnaissance de texte basée sur l'apprentissage profond devient progressivement la technologie dominante appliquée , À l'heure actuelle, de bons résultats ont été obtenus dans le domaine de la reconnaissance des caractères. [5]. Cours de développement de la reconnaissance de texte en apprentissage profond ,Comme le montre la figure3Comme indiqué.
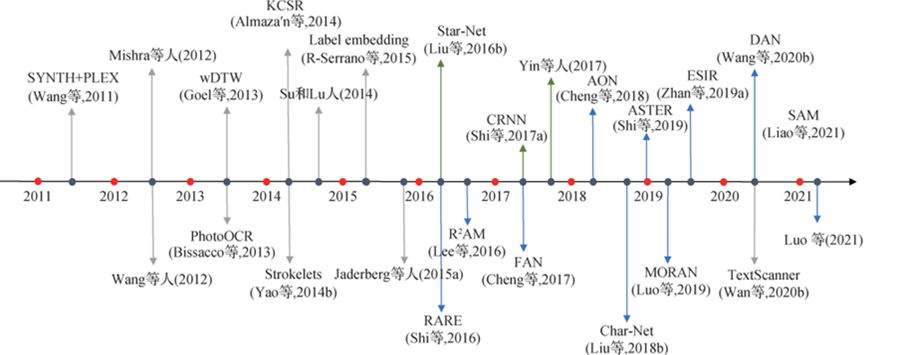
Fig.3 Développement de la technologie de reconnaissance des caractères
Il existe actuellement deux types d'algorithmes de reconnaissance de texte pour l'apprentissage en profondeur ,Basé surCTC[6] Algorithme basé sur AttentionAlgorithmes, La différence est principalement dans la phase de décodage . Le premier est d'accéder à la séquence générée par le codage CTC Décoder, Ce dernier est une séquence connectée à un module de réseau neuronal cyclique pour le décodage cyclique .En outre, Et basé sur la segmentation 、Basé surTransformer Et des méthodes de reconnaissance de texte de bout en bout .
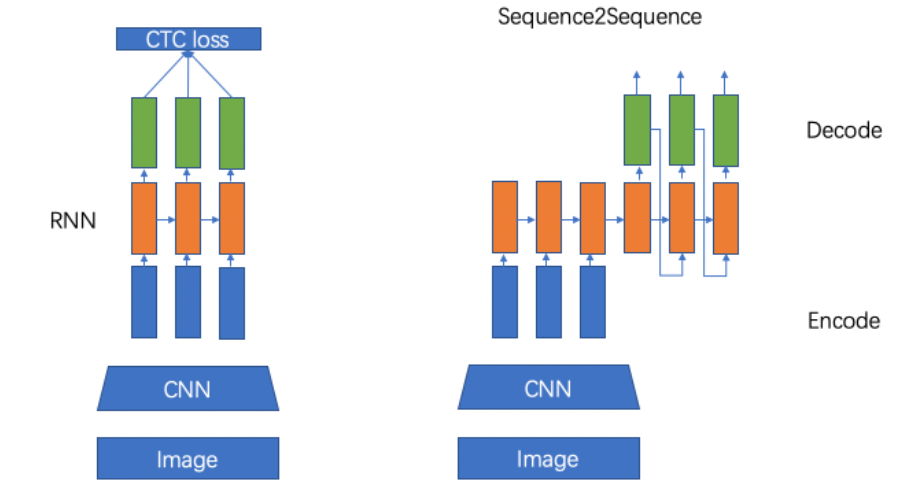
2.1 Basé surCTCAlgorithme
Classification chronologique du connectionisme (connectionist temporal classification,CTC) Les mécanismes sont généralement utilisés au stade de la prévision ,CTC En additionnant les probabilités conditionnelles, CNN Ou RNN Caractéristiques de sortie converties en séquences de chaînes . L'application de la technologie de reconnaissance de texte peut résoudre le problème de l'alignement des textes séquentiels , C'est - à - dire s'assurer que la séquence de texte prévue correspond à la séquence de texte réelle ,Même longueur.
En tant qu'algorithme classique de reconnaissance de texte , L'équipe de Bai Xiang et d'autres 2016 Proposer un algorithme de reconnaissance de texte CRNN[7],Réseau neuronal convolutif、 Réseau neuronal cyclique et CTC Combinaison de fonctions de perte , Pour résoudre le problème de la reconnaissance de séquence basée sur l'image , En particulier, la reconnaissance du texte de la scène .Par exemple:Fig.4Comme indiqué,CRNNModèle Introduction de deux directions LSTM(Long Short-Term Memory)[8] Utilisé pour améliorer la modélisation contextuelle ,Et à traversCTC Fonction de perte pour la reconnaissance de séquence de longueur indéterminée de bout en bout , L'algorithme n'a besoin que d'étiquettes de niveau de mot de base et d'images d'entrée pour réaliser la formation du modèle , Devenir l'un des cadres les plus populaires dans le domaine de la reconnaissance de texte .
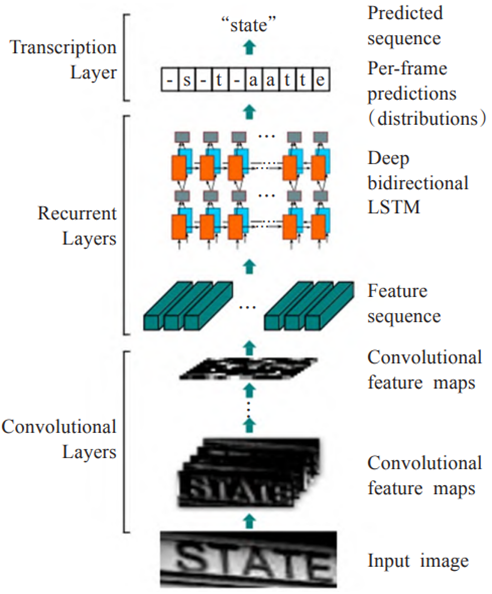
Fig.4 CRNNStructure du réseau
Considérant queCRNN Obtenir de bons résultats dans le domaine de la reconnaissance de texte , Amélioration de l'algorithme de base des générations futures ,FaceBook Amélioration proposée par l'entreprise CTCAlgorithmesRosetta[9], Son modèle CRNNAméliorer sur la base, Le modèle est composé d'un réseau de convolution complet et CTCComposition, Meilleure reconnaissance des ensembles de données en anglais .En outre,Gao[10]Utilisation par d'autresCNN Substitution de convolution LSTM, Moins de paramètres , Amélioration des performances précision égale . Les deux algorithmes ci - dessus ont un très bon effet sur le texte des règles , Mais en raison des limites de la conception du réseau , Il est difficile de résoudre la tâche de reconnaissance de texte irrégulière de flexion et de rotation avec ce type de méthode [11].Pour résoudre ces problèmes,, Certains chercheurs ont proposé une série d'algorithmes améliorés basés sur les deux types d'algorithmes ci - dessus. [12][13].
2.2 Basé surAttentionMéthode
La reconnaissance irrégulière des scènes textuelles est la principale orientation de la recherche dans le domaine de la reconnaissance textuelle. . En tant que méthode principale de reconnaissance de texte ,Basé surAttention La méthode peut réaliser la reconnaissance irrégulière du texte , Son contenu n'est souvent pas horizontal , Et il y a des virages 、Occlusion、Problèmes flous, etc.[14].Basé surAttention La méthode de reconnaissance des caractères basée sur le codage - Structure du réseau de décodage , L'image d'entrée principale passe par le réseau neuronal convolutif , Utilisation du réseau neuronal cyclique RNN Traitement séquentiel , Accorder plus de poids aux données cibles et aux données connexes , Qui fait que le décodeur “Attention.” L'ensemble correspond aux données cibles , Obtenir des informations détaillées , Réalisation d'une représentation vectorielle rationnelle des séquences d'entrée plus longues . InAttention Avant la méthode ,RARE[15] Algorithme proposé une méthode de correction du texte irrégulier , Reconnaissance de texte robuste avec correction automatique , L'ensemble du réseau est divisé en deux parties principales , Un réseau de transformation spatiale STN(Spatial Transformer Network) Et une base surSequence2Squence Réseau d'identification . L'image texte irrégulière est corrigée par le module STN,ParTPS(Thin-Plate-Spline) Image transformée en direction horizontale , Cette transformation peut corriger la flexion dans une certaine mesure 、 Texte de la transformation de transmission , Après correction, il est envoyé au réseau d'identification des séquences pour le décodage. .
Après l'apparition de la méthode de correction ,R2AM[16] Algorithme pour la première fois Attention Introduction d'un champ de reconnaissance de texte , Le modèle extrait d'abord les caractéristiques codées de l'image d'entrée par la couche de convolution récursive , Ensuite, utilisez les statistiques linguistiques au niveau des caractères apprises implicitement pour passer à travers RNN Décoder les caractères de sortie . Introduit dans le processus de décodage Attention Mécanisme de sélection des caractéristiques douces , Pour mieux utiliser les caractéristiques de l'image ,Plus conforme à l'intuition humaine. La méthode basée sur la correction a une bonne mobilité ,En plus de ce qui précèdeRARECette catégorie est basée surAttentionEn dehors de la méthode,STAR-Net[17] Appliquer le module de correction à la base CTCSur l'algorithme,Par rapport à la traditionCRNN Il y a aussi de bonnes améliorations .Shi[18]A proposé une approche basée surAttention Un cadre de codec pour reconnaître le texte .Comme le montre la figure5Comme indiqué, L'algorithme extrait les caractéristiques par couche de convolution , Accès au réseau neuronal circulant bidirectionnel , Capacité d'apprendre un modèle de langage de niveau de caractère caché dans une chaîne à partir des données de formation , La reconnaissance du texte des règles peut être réalisée .
Module intégré de correction de texte et AttentionMéthodes, Bai Xiang Team et al. [18] Un nouveau modèle classique de reconnaissance de texte est proposé ASTER.Comme le montre la figure6Comme indiqué, L'algorithme prend la forme d'un cadre de codage et de décodage ,Introduction en premierSTN Module réseau correctif pour le prétraitement du texte , Union postérieure Attention Réaliser l'alignement des caractéristiques sur les informations de l'étiquette .Parmi eux,Intégrer les réseaux correctionnels et les réseaux d'identification pour former un réseau de bout en bout, Maintenant largement utilisé dans la reconnaissance de texte de scène irrégulière .Parce queASTER Il a montré une bonne performance dans la résolution de la tâche de reconnaissance de texte de scène irrégulière , Mais les méthodes basées sur la correction sont souvent limitées par les caractéristiques géométriques des caractères , Et le modèle est plus sensible au bruit de fond .
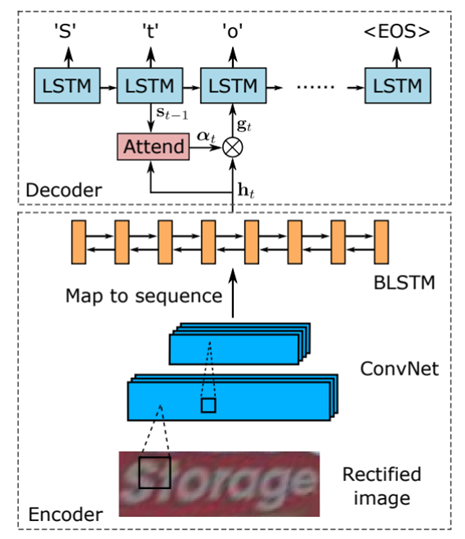
Fig.6 ASTERStructure du réseau
Pour surmonter ces problèmes ,LuoEt al.[19] Un réseau d'attention corrective Multi - objectifs est proposé. (multi-object rectified attention network,MORAN),Comme le montre la figure7Comme indiqué, Sa structure est basée sur un réseau de correction multi - objectifs et Attention Structure du réseau de reconnaissance des séquences du mécanisme , Le réseau de correction est un réseau de correction au niveau des pixels , Le réseau n'est pas géométriquement limité , Plus de flexibilité dans la transformation , Peut parfaitement traiter le problème de la reconnaissance irrégulière du texte .

Fig.6 MORANStructure du réseau
Il y a beaucoup d'algorithmes qui suivent Attention Domaines à explorer et à mettre à jour ,Par exempleSAR[20]Oui.1D attentionExtension à2D attentionAllez., Module de correction mentionné RAREEst également basé surAttentionMéthode, La preuve expérimentale est basée sur AttentionPar rapport àCTC La méthode a une bonne amélioration de précision .ChengEt al.[21] Un réseau d'attention focalisé est proposé FAN, Pour le traitement de pixels bas / Quand une image complexe , L'approche fondée sur le mécanisme d'attention n'a pas donné de bons résultats , C'est principalement parce que le réseau d'attention ne peut pas concentrer avec précision le Centre d'attention des caractères dans cette image particulière au centre de la zone cible correspondante. , Les centres d'attention peuvent être détectés et corrigés par un réseau de focalisation , Résoudre efficacement le problème de la déviation de l'attention .
En résumé,Bien queCRNN+CTC Obtenir de bons résultats dans la reconnaissance de texte long , Mais il ne peut résoudre que le problème unidimensionnel de la reconnaissance des séquences , Et lorsque la déformation de la ligne de texte est grande ,CTC L'effet de reconnaissance sera grandement affecté .EtSeq2Seq+AttentionComment identifier, Bien qu'il puisse en principe résoudre le problème de la reconnaissance des séquences bidimensionnelles ,Mais limité parRNNLes limites du réseau dans la reconnaissance des longues séquences,Etseq2seq Le mécanisme de s érie de S / s conduit à une mauvaise performance dans la reconnaissance de texte à longue séquence et l'efficacité de fonctionnement [22]. Pour surmonter ces problèmes ,2019 Rente lianwen Team et al. [23] Un algorithme de reconnaissance de séquence basé sur la perte d'entropie croisée est proposé ACE.Comme le montre la figure7Comme indiqué,ACE La méthode de décodage de l'algorithme est différente de CTCEtAttention, Son signal de surveillance est en fait une sorte de faible surveillance , Ignorer la correspondance des dimensions des caractères dans l'étiquette , Aucune information sur la séquence , Attention au nombre de fois où les caractères apparaissent , Obtenir des résultats comparables à ceux des principales technologies d'identification à faible complexité .ACE Les pertes sont supérieures en termes de complexité temporelle et spatiale à CTCPertes, Et peut être utilisé pour la reconnaissance de Texte multiligne , Résoudre les problèmes des deux méthodes ci - dessus d'un autre point de vue .
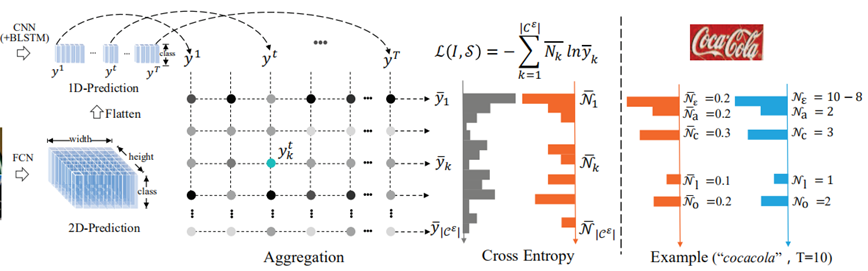
Fig.7 ACE Diagramme de structure de l'algorithme
2020Année,Hu[24] Et d'autres ont proposé un nouvel algorithme de reconnaissance de texte fusionné GTC, Basé sur AttentionEtCTC Deux façons de fusionner ,UtilisationAttentionC'est exact.CTC Superviser et guider l'alignement ,Ça marche.CRNN Le manque de capacité du réseau à se concentrer sur les régions locales ,GTC Le modèle transmet les caractéristiques extraites séparément dans CTC Décodeur et indicateur d'attention .Adhésion simultanéeGCN Amélioration de la capacité d'expression du modèle par le réseau neuronal de convolution graphique , L'effet expérimental est meilleur que les méthodes ci - dessus .
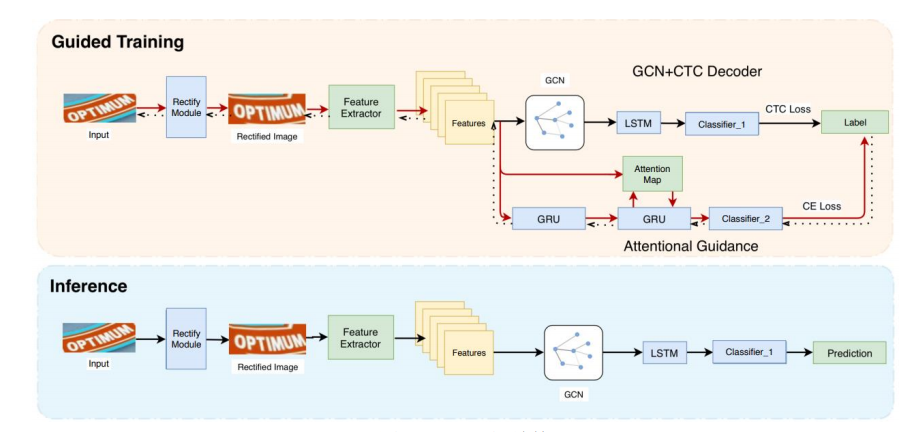
Basé surAttentionRésumé de la méthodologie
2.3 Approche fondée sur la segmentation
L'approche fondée sur la segmentation consiste à considérer les caractères d'une ligne de texte comme des individus distincts , Par rapport à la reconnaissance après correction de toute la ligne de texte , Il est plus facile d'identifier les caractères individuels séparés [25]. Tentative de localiser chaque position de caractère à partir de l'image texte saisie , Et le classificateur de caractères est utilisé pour obtenir les résultats de reconnaissance , Simplifier les problèmes globaux complexes en problèmes locaux , Il a un bon effet dans un scénario de texte irrégulier , Cependant, cette méthode nécessite une annotation au niveau du caractère , Il est difficile d'obtenir des données .Lyu[26] Un modèle de segmentation des mots pour la reconnaissance des mots est proposé. , Le modèle utilise, dans sa partie d'identification, une méthode basée sur FCNMéthode.Documentation[27] Examen de la reconnaissance des textes du point de vue bidimensionnel , Attention aux caractères de conception FCN Pour résoudre les problèmes de reconnaissance de texte , Lorsque le texte est plié ou fortement déformé , Cette méthode a un meilleur résultat de localisation pour les textes réguliers et irréguliers .
2022Année, Kim Lian Wen [28] Et d'autres ont proposé un nouvel algorithme de reconnaissance de texte de bout en bout basé sur l'absence de segmentation , Le résultat est un modèle de réseau neuronal complet , Formation conjointe combinant des modules d'apprentissage faiblement supervisés avec des informations contextuelles . Une nouvelle méthode d'apprentissage faiblement supervisée est proposée. , Permettre au réseau de s'entraîner uniquement à l'aide d'annotations transcrites , Vous pouvez éviter les commentaires de segmentation de caractères , L'effet de reconnaissance de l'ensemble de données textuelles manuscrites est meilleur que celui de l'algorithme de reconnaissance non délimité ci - dessus. ,Structure comme indiqué dans la figure8Comme indiqué.
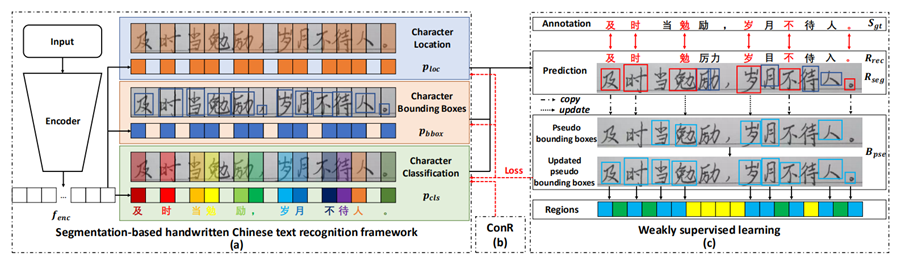
Fig.8 Schéma de structure de l'algorithme de reconnaissance sans séparation
2.4Basé surTransformerMéthode
Avec TransformerDéveloppement rapide, Validation du domaine de classification et d'essai Transformer Efficacité dans les tâches visuelles . Par exemple, dans la section reconnaissance du texte des règles ,CNN Il y a des limites à la modélisation à long terme ,Transformer La structure résout ce problème , Il se concentre sur l'information globale dans l'extracteur de fonctionnalités , Et peut remplacer le supplément LSTMModule de modélisation contextuelle.
Yu DAttendez.2020 Un nouvel algorithme de cadre de formation de bout en bout SRN[29].Comme le montre la figure9Comme indiqué,SRN Par l'épine dorsale 、 Module d'incitation visuelle parallèle (PVA Proposer un module d'attention parallèle )、 Module de raisonnement sémantique global (GSRM) Et un décodeur de fusion sémantique visuelle (VSFD)Composition en quatre parties, Vous pouvez utiliser l'ordre de lecture comme requête , Rendre le calcul indépendant du temps , Sortie parallèle finale caractéristiques visuelles alignées pour toutes les étapes de temps .SRNUtilisation de l'algorithmeTransformerDeEncoder En tant que module sémantique , Fusion de l'information visuelle et sémantique de l'image , En occlusion 、 Le texte irrégulier, comme le flou, a un bon effet de reconnaissance .NRTRAlgorithmes[30] Proposer une utilisation complète Transformer La structure encode et décode les images d'entrée , Extraction de caractéristiques à l'aide de couches simples , Vérification de la reconnaissance du texte Transformer Efficacité de la structure .
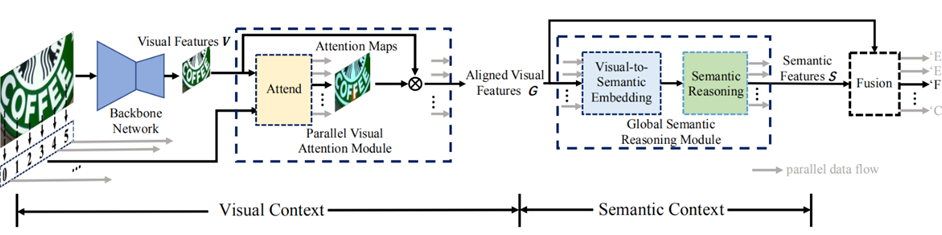
Fig.9 SRN Schéma de structure de l'algorithme
2.5 Méthode d'identification de bout en bout
Les méthodes de reconnaissance de bout en bout permettent le partage d'informations sur la détection et la reconnaissance de textes , Et peut être optimisé conjointement , Le raisonnement global est plus rapide que la cascade . Les modèles formés de bout en bout peuvent apprendre des caractéristiques d'image plus riches , Un seul réseau est nécessaire ,Saisissez une image, Résultats de la détection et de l'identification en même temps , Peut économiser du temps efficacement .STN-OCR[31] Le réseau intégrera la détection et l'identification , La reconnaissance de texte de bout en bout est possible . Le réseau utilise une approche semi - supervisée pour la formation , Aucune information sur l'emplacement du texte n'est requise , L'ensemble du système offre une formation de bout en bout . Méthode de reconnaissance de texte de bout en bout FOTS[32], Réseau de localisation de texte rapide ,ApplicationRoI Rotate Le module réalise la combinaison de la détection et de la reconnaissance , Reconnaissance de texte rapide et efficace .Mask TextSpotter[33] Tirer parti d'un processus d'apprentissage de bout en bout simple et lisse , Détection et reconnaissance précises du texte par segmentation sémantique .En outre, Cette méthode traite des instances textuelles de formes irrégulières (Par exemple, Texte courbe ) Aspects supérieurs à la méthode précédente .ABCNet[34] Le réseau est un réseau de détection et de reconnaissance de texte de scène de bout en bout , Pour la première fois, le réseau adapte de façon adaptative le texte de forme arbitraire à l'aide d'une courbe de Bessel paramétrique , Son coût de calcul est négligeable ,Parmi euxBezierAlign La couche peut extraire avec précision les caractéristiques de convolution et améliorer considérablement la précision de reconnaissance , Plus lisse et plus rapide lors de la détection de texte Multi - directionnel et multi - échelle , Reconnaissance de texte en temps réel ,Sa structure est illustrée à la figure10Comme indiqué.
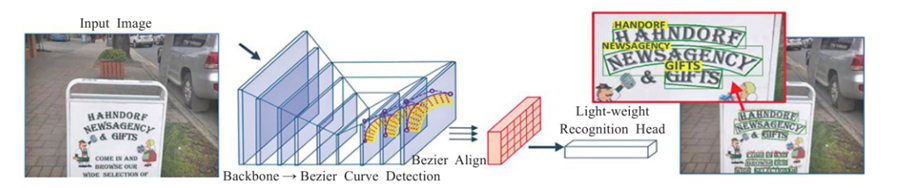
Fig.10 ABCNet Schéma de structure de l'algorithme
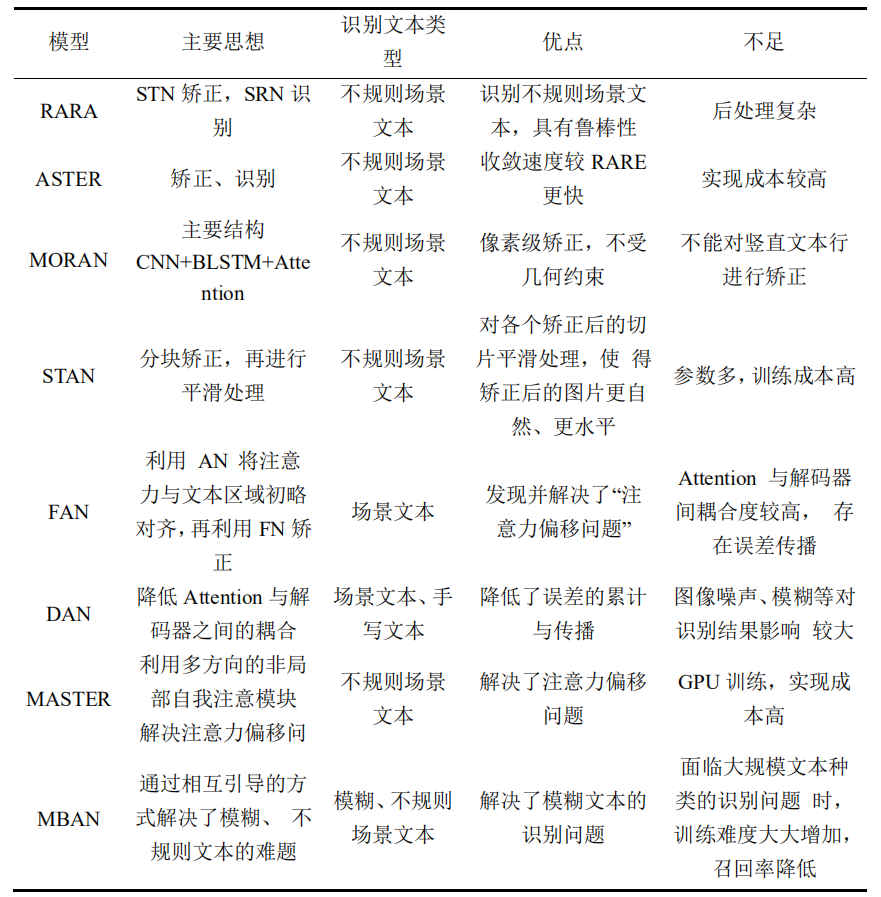
Texte des règles basé sur l'apprentissage profond ci - dessus 、 Texte irrégulier 、 Reconnaissance de texte de bout en bout , Cet article résume les principales méthodes de reconnaissance des caractères et les documents représentatifs dans divers domaines. ,Comme indiqué dans le tableau1Comme indiqué.
Tableau1 Résumé des principales méthodes de reconnaissance des caractères
Catégorie d'algorithme | Principales idées | Principaux documents | ||
Algorithmes traditionnels | Fenêtre coulissante、Extraction de caractères、Planification dynamique | |||
CTC | Basé surCTCMéthode, Séquence non alignée ,Identification rapide | CRNN,Rosetta | ||
Attention | Basé surattentionMéthode, Appliquer au texte non conventionnel | RARE,DAN,PREN | ||
CTC+Attention | IntégrationCTCEtAttentionLa pensée | GTC | ||
Transformer | Basé surtransformerMéthode | SRN,NRTR,Master,ABINet | ||
Correction | Le module de correction apprend les limites du texte et les corrige horizontalement | RARE,ASTER,SAR | ||
Diviser | Approche fondée sur la segmentation , Extraire la position du caractère pour la classification | TextScanner, Mask TextSpotter | ||
3. Ensembles de données de reconnaissance de texte et indicateurs d'évaluation
Reconnaissance de texte sa tâche est de reconnaître le contenu du texte dans l'image , En général, l'entrée provient d'une zone de texte d'image coupée à partir d'une zone de texte détectée. [35]. Selon le scénario réel , Les ensembles de données de reconnaissance de texte peuvent généralement être divisés en deux catégories: la reconnaissance régulière du texte et la reconnaissance irrégulière du texte. , Les résultats de la classification sont présentés dans la figure ci - dessous. 11Comme indiqué.
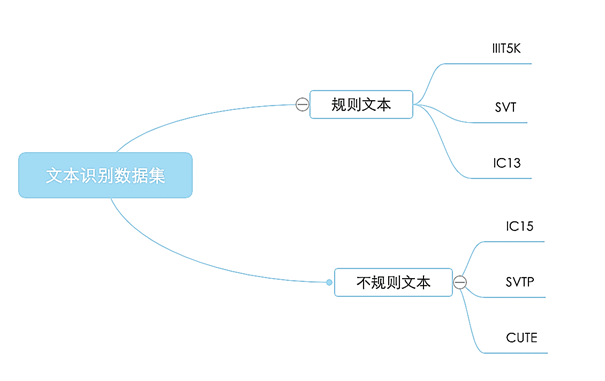
Fig.11 Classification des ensembles de données de texte régulier et irrégulier
Les différents algorithmes de reconnaissance sont généralement comparés entre les deux ensembles de données publics susmentionnés. , Classification actuelle des ensembles d'évaluation en anglais . La reconnaissance du texte des règles se réfère principalement à la police imprimée 、 Numériser le texte et d'autres scènes , Pensez que le texte est approximativement horizontal , Les ensembles de données représentatifs comprennent principalement: IC13[36]、SVT[37]、IIIT5K[38]Attendez.. La reconnaissance irrégulière du texte apparaît dans la scène naturelle , Et en raison de la courbure du texte 、Orientation、 La déformation et d'autres aspects sont très différents , Le texte n'est souvent pas horizontal , Il y a des virages 、Occlusion、Problèmes flous, etc., Les ensembles de données représentatifs sont: IC15 [39]、COCO-Text[40]、SVTP[41]、CUTE [42]Attendez.. Identifier l'ensemble de données pour le texte approprié , Il est essentiel de trouver des méthodes d'identification appropriées. . Chaque ensemble de données correspond à un OCR Identifier les méthodes de traitement , Chaque méthode a également un ensemble de données approprié . Différentes méthodes d'acquisition d'images , Les ensembles de données de caractères peuvent être divisés en trois catégories : Ensemble de données d'images de caractères collectées dans un environnement naturel 、 Ensemble de données d'image de caractères manuscrits 、 Jeux de données d'images de caractères composés par différentes polices d'ordinateur , Y compris l'ensemble de données textuelles chinoises ICDAR2019-LSVT[43]、ICDAR2019-ReCTS[44]、CTW[45]、ShopSign[46]Attendez.; Les ensembles de données textuelles composites comprennent: Synth90K[47]、SynthText[48]、SynthAdd[49]Attendez..
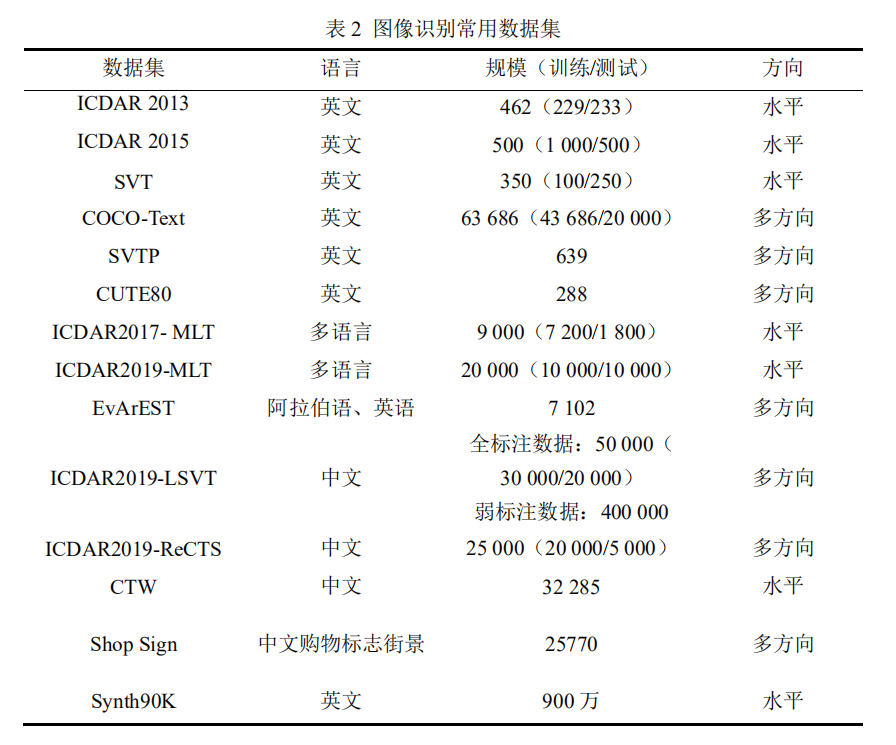
Cet article résume et organise l'information des ensembles de données de reconnaissance de texte communs , Inclure des ensembles de données textuelles communs en chinois et en anglais comme indiqué dans le tableau 2Comme indiqué.

4. Développement de la technologie de reconnaissance des caractères et tendances de la recherche
Pour l'instant, Le développement de la technologie de reconnaissance des caractères basée sur l'apprentissage profond est relativement mature ,Dans l'éducation、 Largement utilisé dans l'industrie médicale , Mais en raison du manque actuel d'ensembles de données Open Source , L'amélioration de l'algorithme de reconnaissance est limitée [50]. Dans l'identification des scénarios , Les gens ont besoin de plus en plus de reconnaissance de texte dans des scènes complexes ; Les tendances futures de la recherche sur la reconnaissance des caractères se reflètent principalement dans les aspects suivants: :
(1) Reconnaissance de texte de scènes complexes
L'apprentissage profond présente des avantages naturels dans le domaine de la reconnaissance des caractères , Bien que les problèmes qui peuvent être résolus deviennent de plus en plus complexes , Mais il y a aussi des problèmes qui doivent être résolus. , Par exemple, la performance de détection du texte dense et irrégulier est encore bien inférieure à celle du texte horizontal de détection. . Surtout dans les scènes manuscrites , Comme la reconnaissance de la formule mathématique manuscrite 、 Des études telles que l'identification des langues minoritaires revêtent une grande importance [51][52].Deuxièmement,, Comment dans une scène naturelle 、Des scènes complexes( Comme un caractère déformé 、Chevauchement)、 Scénarios multilingues ( Une feuille contient plusieurs mots en même temps ) Détection et reconnaissance de texte , Résoudre les problèmes de positionnement et de prétraitement des caractères , Amélioration de la précision de l'identification , Est l'orientation de la recherche future sur la reconnaissance des caractères [53].
(2)Échantillon zéro、Apprentissage avec peu d'échantillons(Zero-shot[54]/Few-shot[55])
Combinaison de l'apprentissage par échantillon zéro ou de l'apprentissage par petit échantillon dans le processus de reconnaissance de texte , Informations sémantiques contextuelles fédérées , Est l'une des tendances de recherche les plus populaires dans le développement futur de la technologie de reconnaissance de caractères . En particulier dans l'étude de la reconnaissance des livres anciens , En n'ajoutant pas ou moins de caractères d'identification pertinents à l'échantillon d'entraînement , Combiner plusieurs informations auxiliaires , Fusion de modèles visuels avec des informations sémantiques contextuelles , Catégories partielles pour la mise en œuvre ( Comme les caractères simplifiés ) Reconnaissance de la formation des échantillons , Extension à l'identification de nouvelles catégories ( Comme les caractères traditionnels )Échantillons, Permet à la machine de reconnaître des mots inconnus .
(3) Dimensions des ensembles de données à grande échelle et des jeux de caractères
L'ensemble de données est la clé de l'amélioration de l'algorithme de reconnaissance de texte , Influence directe sur l'identification finale . À l'heure actuelle, les ensembles de données textuelles open source sont rares dans le domaine de la reconnaissance de texte. .D'un côté, Les entreprises considèrent les données commerciales pertinentes comme privées , Rendre public ;D'un autre côté, L'ensemble de données de reconnaissance de texte directionnel dans le domaine universitaire est limité par des conditions manuelles et techniques , Réduit la taille des données .Donc,, À l'avenir, nous aurons besoin de plus d'ensembles de données textuelles à grande échelle traités à partir de sources ouvertes , D'une part, nous pouvons essayer d'augmenter les données par l'algorithme de corrélation d'amélioration des données ;D'un autre côté,Peut passerGANGénérer un réseau de confrontation[56] Générer des images de polices multiples , Amélioration de la performance et de la généralisation du modèle d'algorithme de reconnaissance .
5.Conclusions
Cet article présente principalement un aperçu de la technologie de reconnaissance de texte basée sur l'apprentissage profond , Classifier et résumer l'algorithme classique de reconnaissance de texte courant , Énumérer les idées et les contributions des documents classiques .Tout d'abord,, Cet article présente la base de la reconnaissance des règles textuelles CTCEt sur la baseAttention、Transformer Et Segmentation , Résumer l'algorithme de bout en bout .Enfin, Discussion sur le développement et la tendance de la recherche dans le domaine de la reconnaissance des caractères .La traditionOCRJusqu'à présent, La plupart des scénarios simples ont été résolus et fonctionnent bien ,Mais dans Quelques scènes complexes ,La traditionOCR La précision d'identification est difficile à satisfaire aux exigences d'application pratique .Basé sur l'apprentissage profondOCR Meilleure performance que les méthodes traditionnelles , Avec le développement de la technologie de l'intelligence artificielle au cours des dernières années , La reconnaissance de texte basée sur l'apprentissage profond devient progressivement la technologie dominante appliquée , À l'heure actuelle, de bons résultats ont été obtenus dans le domaine de la reconnaissance des caractères. , Son orientation future s'étendra progressivement à un plus grand nombre 、 Scénarios plus complexes , Intégration de travaux multidisciplinaires , Rendre la technologie de reconnaissance de texte plus mature dans l'application de l'intelligence artificielle . En tant que moteur de l'apprentissage profond , Les données jouent un rôle crucial , Par conséquent, l'ensemble de données à grande échelle open source est également au centre de l'amélioration de l'effet de reconnaissance de texte à ce stade. .En plus, Dans l'application de la reconnaissance de texte , Nous devons introduire des modèles plus légers , Assurer une certaine précision tout en augmentant la vitesse d'entraînement du modèle , Permet un déploiement rapide de son système côté serveur .
Références
- Liu weihong . Situation actuelle et importance de la numérisation des livres anciens chinois [J]. Livres et renseignements , 2009 (4): 134-137
- Jiang Wei, Chang Chong Sheng , Yin Xucheng . Aperçu de la détection de texte de scène basée sur l'apprentissage profond [J].Journal of Electronics, 2019, 47(5): 1152.
- Liu yanju , Yixinhai , Li Yange , Zhang huiyu , Liu yanzhong . Résumé de l'application de l'apprentissage profond à la reconnaissance de texte de scène [J].Ingénierie informatique et applications,2022,58(04):52-63.
- A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
- Kim Lian Wen , Zhong zhuoyao et al. . Examen de l'application de l'apprentissage profond à la reconnaissance manuscrite des caractères chinois [J].Journal of Automation2016,42(8):1125-1141.
- Graves, Alex, et al.Connectionist temporal classification: labelling unsegmented sequence data withrecurrent neural networks. In ICML, 2006.
- Shi B, Bai X,Yao C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition[J]. ieee transactions on pattern analysis & machine intelligence, 2016, 39(11):2298-2304.
- F. A. Gers, N. N. Schraudolph, and J. Schmidhuber. Learning precise timing with LSTM recurrent networks. JMLR,3:115–143, 2002.
- Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 71–79. ACM, 2018.
- Gao, Yunze, et al. Reading scene text with attention convolutional sequence modeling. arXiv preprint arXiv:1709.04303, 2017.
- Wang Deqing , Wushour et al. . Aperçu de la recherche sur la technologie de reconnaissance de texte de scène [J]. Ingénierie informatique et applications, 2020, 56(18): 1-15.
- Niu Xiaoming , Piccolin , Tang Jun . Résumé de la technologie de reconnaissance graphique et textuelle [J].Chinese stereology and Image Analysis, 2019, 25(3):241-256.
- Ganji . Recherche sur la reconnaissance manuscrite des caractères et les algorithmes connexes [D].University of Chinese Academy of Sciences( Computer Science and Technology of Chinese Academy of Sciences École d'art ),2021.DOI:10.44196/d.cnki.gjskx.2021.000003.
- Shi B, Wang X, Lyu P, et al. Robust scene text recognition with automatic rectification[C]// Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 4168-4176.
- Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.
- Star-Net Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spa- tial transformer networks. In Advances in neural information processing systems, pages 2017–2025, 2015.
- Baoguang Shi, Mingkun Yang, XingGang Wang, Pengyuan Lyu, Xiang Bai, and Cong Yao. Aster: An attentional scene text recognizer with flexible rectification. IEEE transactions on pattern analysis and machine intelligence, 31(11):855–868, 2018.
- F. A. Gers, N. N. Schraudolph, and J. Schmidhuber. Learning precise timing with LSTM recurrent networks. JMLR,3:115–143, 2002.
- Luo C, Jin L, Sun Z. A multi-object rectified attention network for scene text recognition[J]. Pattern Recognition, 2019, 90: 109-118.
- Li H, Wang P, Shen C, et al. Show, attend and read: A simple and strong baseline for irregular text recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 8610-8617.
- Cheng Z, Bai F, Xu Y, et al. Focusing attention: Towards accurate text recognition in natural images[C]//Proceedings of the IEEE international conference on computer vision. 2017: 5076-5084.
- Lee C Y , Osindero S . Recursive Recurrent Nets with Attention Modeling for OCR in the Wild[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE, 2016.
- Xie Z, Huang Y, Zhu Y, et al. Aggregation cross-entropy for sequence recognition[C] //Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA, 2019: 6538-6547
- Hu W, Cai X, Hou J, et al. Gtc: Guided training of ctc towards efficient and accurate scene text recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(07): 11005-11012.
- Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.
- P. Lyu, C. Yao, W. Wu, S. Yan, and X. Bai. Multi-oriented scene text detection via corner localization and region segmentation. In Proc. CVPR, pages 7553–7563, 2018.
- Liao M, Zhang J, Wan Z, et al. Scene text recognition from two-dimensional perspective[C] //Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 8714-8721.
- Peng D, Jin L, Ma W, et al. Recognition of Handwritten Chinese Text by Segmentation: A Segment-annotation-free Approach[J]. IEEE Transactions on Multimedia, 2022.
- Yu D, Li X, Zhang C, et al. Towards accurate scene text recognition with semantic reasoning networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12113-12122.
- Sheng F, Chen Z, Xu B. NRTR: A no-recurrence sequence-to-sequence model for scene text recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 781-786.
- Bartz C, Yang H, Meinel C. STN-OCR: A single neural network for text detection and text recognition[J]. arXiv preprint arXiv:1707.08831, 2017.
- Liu X, Liang D, Yan S, et al. Fots: Fast oriented text spotting with a unified network[C] //Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 5676-5685.
- Lyu P, Liao M, Yao C, et al. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 67-83.
- Liu Y, Chen H, Shen C, et al. Abcnet: Real-time scene text spotting with adaptive bezier-curve network[C]//proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 9809-9818.
- Zhang Huaping , Huang Chen . Recherche sur la technologie de reconnaissance des caractères [J].Technologie de l'Internet des objets,2018,8(08):17-19.DOI:10.16667/j.issn.2095- 1302.2018.08.002.
- Karatzas D, Shafait F, Uchida S, et al. ICDAR 2013 robust reading competition[C]//2013 12th International Conference on Document Analysis and Recognition. IEEE, 2013: 1484-1493.
- Wang K, Babenko B, Belongie S. End-to-end scene text recognition[C]//2011 International conference on computer vision. IEEE, 2011: 1457-1464.
- Yasmeen U, Shah J H, Khan M A, et al. Text detection and classification from low quality natural images[J]. 2020.
- Karatzas D, Gomez-Bigorda L, Nicolaou A, et al. ICDAR 2015 competition on robust reading[C]// international conference on document analysis IEEE, 2015: 1156-1160.
- Veit A, Matera T, Neumann L, et al. Coco-text: Dataset and benchmark for text detection andrecognition in natural images[J]. arXiv preprint arXiv:1601.07140, 2016
- Phan T Q, Shivakumara P, Tian S, et al. Recognizing text with perspective distortion in naturalscenes[C]//Proceedings of the IEEE International Conference on Computer Vision. 2013: 569-576.
- Risnumawan A, Shivakumara P, Chan C S, et al. A robust arbitrary text detection system for natural scene images[J]. Expert Systems with Applications, 2014, 41(18): 8027-8048.
- Sun Y, Ni Z, Chng C K, et al. ICDAR 2019 competition on large-scale street view text with partial labeling-RRC-LSVT[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1557-1562.
- Zhang R, Zhou Y, Jiang Q, et al. Icdar 2019 robust reading challenge on reading chinese text onsignboard[C]//2019 international conference on document analysis and recognition (ICDAR). IEEE, 2019: 1577-1581.
- Yuan T L, Zhu Z, Xu K, et al. A large chinese text dataset in the wild[J]. Journal of Computer Science and Technology, 2019, 34(3): 509-521.
- Zhang C, Ding W, Peng G, et al. Street view text recognition with deep learning for urban sceneunderstanding in intelligent transportation systems[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22(7): 4727-4743.
- Jaderberg M, Simonyan K, Vedaldi A, et al. Synthetic data and artificial neural networks for natural scene text recognition[J]. arXiv preprint arXiv:1406.2227, 2014.
- Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2315-2324.
- Li H, Wang P, Shen C, et al. Show, attend and read: A simple and strong baseline for irregular text recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 8610-8617.
- Bai Wenrong . Recherche sur la reconnaissance manuscrite en ligne des caractères mongols [D].Inner Mongolia University,2007.
- Luyan . AI Application de la technologie de reconnaissance des caractères à la numérisation des archives d'urbanisme [J].Innovation scientifique et technologique,2022(14):54-57
- Chen X, Jin L, Zhu Y, et al. Text recognition in the wild: A survey[J]. ACM Computing Surveys (CSUR), 2021, 54(2): 1-35.
- Romera-Paredes B, Torr P. An embarrassingly simple approach to zero-shot learning[C] //International conference on machine learning. PMLR, 2015: 2152-2161.
- Sung F, Yang Y, Zhang L, et al. Learning to compare: Relation network for few-shot learning[C] //Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 1199-1208.
- Karras T, Laine S, Aittala M, et al. Analyzing and improving the image quality of stylegan[C] //Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 8110-8119.
Classification des méthodes de détection et de reconnaissance des textes de scène



边栏推荐
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 24
- How to improve the enthusiasm of consumers when the member points marketing system is operated?
- ReferenceError: primordials is not defined错误解决
- 故障分析 | MySQL 耗尽主机内存一例分析
- CobaltStrike-4.4-K8修改版安装使用教程
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 17
- DDoS "fire drill" service urges companies to be prepared
- Deeply analyze the chain 2+1 mode, and subvert the traditional thinking of selling goods?
- [kubernetes series] learn the exposed application of kubernetes service security
- Jenkins basic knowledge ----- detailed explanation of 03pipeline code
猜你喜欢
My C language learning records (blue bridge) -- files and file input and output

I sorted out a classic interview question for my job hopping friends
RobotFramework入门(三)WebUI自动化之百度搜索
CobaltStrike-4.4-K8修改版安装使用教程
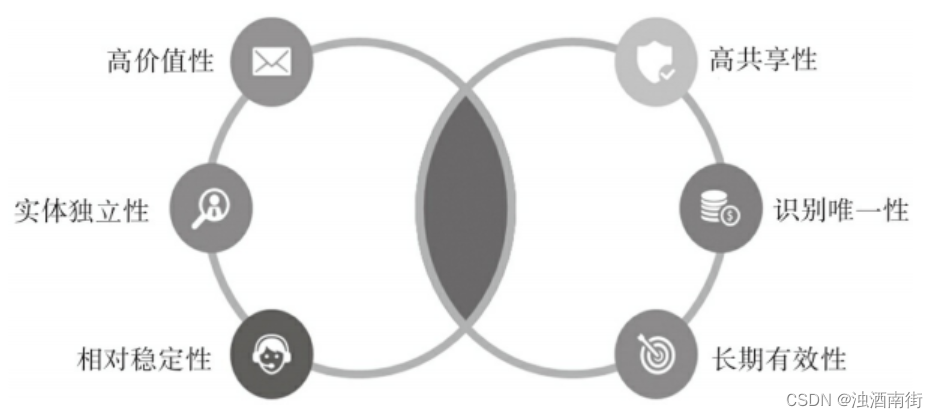
如何精准识别主数据?
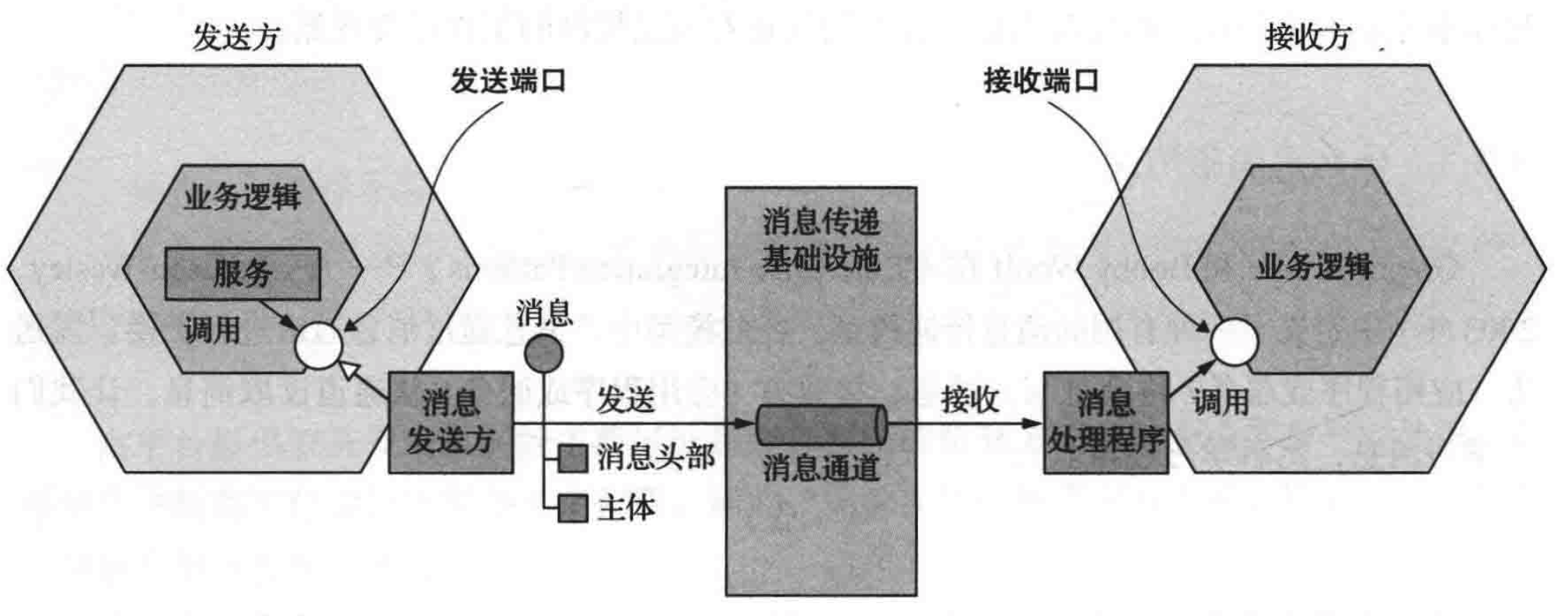
微服务间通信
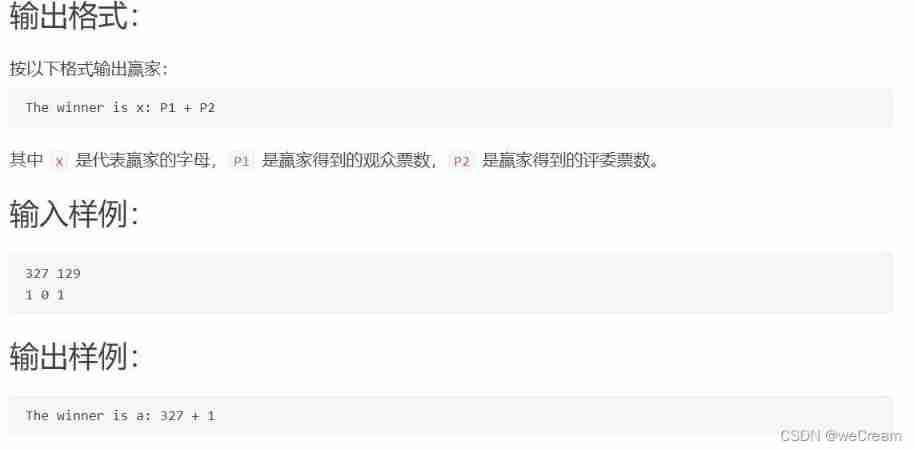
Who is the winner of PTA
![[Yu Yue education] basic reference materials of digital electronic technology of Xi'an University of Technology](/img/47/e895a75eb3af2aaeafc6ae76caafe4.jpg)
[Yu Yue education] basic reference materials of digital electronic technology of Xi'an University of Technology
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 11](/img/6a/398d9cceecdd9d7c9c4613d8b5ca27.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 11
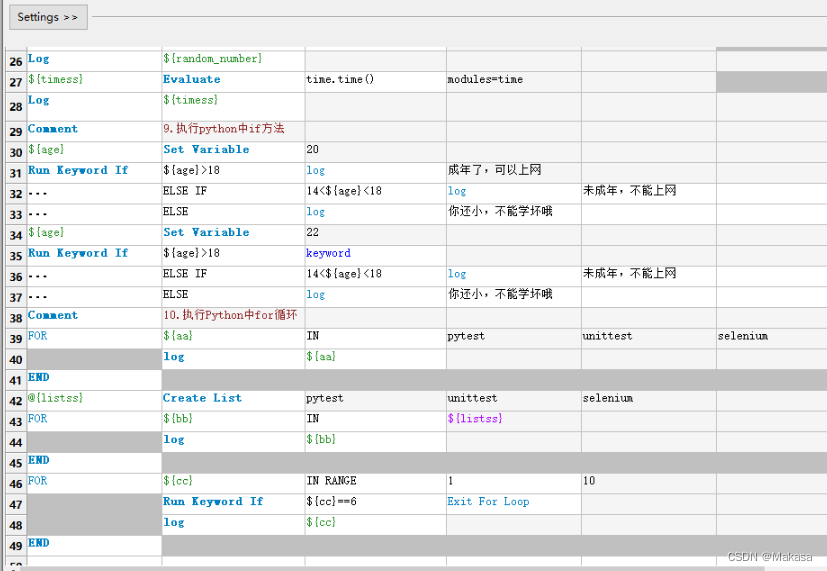
Introduction to robotframework (I) brief introduction and use
随机推荐
How to accurately identify master data?
How to improve the enthusiasm of consumers when the member points marketing system is operated?
#PAT#day10
纯Qt版中国象棋:实现双人对战、人机对战及网络对战
I sorted out a classic interview question for my job hopping friends
Add one to non negative integers in the array
Pure QT version of Chinese chess: realize two-man, man-machine and network games
Is there a completely independent localization database technology
Microsoft speech synthesis assistant v1.3 text to speech tool, real speech AI generator
【若依(ruoyi)】启用迷你导航栏
OCR文字識別方法綜述
CSP date calculation
Universal crud interface
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 11
[kubernetes series] learn the exposed application of kubernetes service security
主数据管理理论与实践
OCR文字识别方法综述
Era5 reanalysis data download strategy
C language - Blue Bridge Cup - promised score
【若依(ruoyi)】设置主题样式