当前位置:网站首页>Teach you to build your own simple BP neural network with pytoch (take iris data set as an example)
Teach you to build your own simple BP neural network with pytoch (take iris data set as an example)
2022-07-06 03:21:00 【LTA_ ALBlack】
* Catalog *
Constructors : Establish a network
Preface : Why do you want to write this blog
I learned a while ago MASP I came into contact with Python Of torch library , I understand Python The convenience and convenience of building a network , I want to imitate and build my own simple network , It is convenient for you to consult and study .
And I imitated the teacher's before BP Neural network code (BP Pure source code ) I wrote an article on self-study BP Blog of neural network :
be based on Java Self study notes of machine learning ( The first 71-73 God :BP neural network )_LTA_ALBlack The blog of -CSDN Blog Be careful : This article is 50 The day after Java Self study note expansion , The content is no longer the content of basic data structure, but various classical algorithms in machine learning . This part of the blog is more convenient to understand , The output of self knowledge is significantly reduced , If there is any mistake, please correct it !https://blog.csdn.net/qq_30016869/article/details/124902680 It also takes time Collate the activation function and Modular BP neural network , But anyway , Pure code without wheels is still troublesome , But with wheels, a lot of content becomes simple . and torch Itself is compatible GPU Accelerated , It is very suitable for large networks , So I feel it is necessary to use torch Rewrite the code at that time , At the same time, I also sort out the modularity I wrote at that time BP Encountered in the network ReLU Activation function The problem of .
Of course, the most important thing is to provide reference for my future neural network compilation , torch It's very convenient , With this blog , I should be able to set up a basically correct network soon !
Data sets
@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
@DATA
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
...
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
...
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
6.3,2.9,5.6,1.8,Iris-virginica
6.5,3.0,5.8,2.2,Iris-virginicairis Is a relatively simple data set , Indicates the kind of flowers , altogether 3 label , It is a simple three categories ( Please distinguish between multiple labels ), So we can get the basic label matrix :
[[1,0,0]
[1,0,0]
[1,0,0]
[1,0,0]
...
[0,1,0]
[0,1,0]
[0,1,0]
[0,1,0]
...
[0,0,1]
[0,0,1]
[0,0,1]
[0,0,1]]If it is multi label , Each label line " 1 " The number of is not fixed
Then I wrote a very simple reading iris Code for , For other data sets, write your own reader Well , In fact, many standard datasets are in the form of standard labels or data matrices .mat The document reflects , The code written at that time may be more representative .
import re
import numpy as np
class Dataset:
trainingSet: np.array
trainingLabelSet: np.array
testingSet: np.array
testingLabelSet: np.array
def __init__(self, fileName, trainingSetProportion):
'''
Construction
:param fileName: File path and name
:param trainingSetProportion: Percentage of training data in total data
'''
dataSet = []
labelSet = []
file = open(fileName, 'r', encoding='utf-8')
filecontent = file.read()
classList = []
for i in filecontent.split('\n'):
if len(i) == 0:
continue
if i[0] == '@' and i.find('class') != -1:
innerStr = re.findall(r'[{](.*?)[}]', i)
classList = innerStr[0].split(',')
continue
if i[0] in ['%','@']:
continue
rowStr = i.split(',')
dataSet.append(rowStr[0:4])
tempList = []
for className in classList:
tempList.append(int(className == rowStr[-1]))
labelSet.append(tempList)
# convert to numpy
tempDataSetNumpy = np.array(dataSet, dtype=np.float32)
tempLabelSetNumpy = np.array(labelSet, dtype=np.float32)
# confirm size
allSize = len(dataSet)
rowIndices = np.random.permutation(allSize)
trainSize = int(allSize * trainingSetProportion)
# for train
self.trainingSet = tempDataSetNumpy[rowIndices[0:trainSize], :]
self.trainingLabelSet = tempLabelSetNumpy[rowIndices[0:trainSize], :]
# for test
self.testingSet = tempDataSetNumpy[rowIndices[trainSize:allSize], :]
self.testingLabelSet = tempLabelSetNumpy[rowIndices[trainSize:allSize], :]
file.close()I use it numpy Storage matrix in np.array Format storage data matrix and label matrix , for The cycle is followed by trainingSetProportion Split into data sets and test sets , Split label data set and label test set .



Constructors : Establish a network
notes : You may need the following libraries for this article :
import numpy as np
import torch
from torch import nn
import rePytorch In order to build a network, it often needs reasonable inheritance nn.Module This class , When constructing this class, the framework of its network is often defined .
Here I designed three formal parameters : List of layers , Activation function string , Learning factors ( Gradient step size )
Specific changes can be made according to your own needs , For example, you can add the read data set path , I'll use this one alone setter It's done , If it is not collective management code , Then programming can be flexible .
class baseAnn(nn.Module):
def __init__(self, paraLayerNumNodes: list = None, paraActivators: str = "s" * 100, paraLearningRate: float = 0.05 ):
'''
Contruction, Create a neural network
:param paraLayerNumNodes: A list is used to describe each layer of network nodes
:param paraActivators: A string is used to describe each layer activators
:param paraLearningRate: Learning Rate
'''
super().__init__()
self.dataset: np.array
self.device = torch.device("cuda")
tempModel = []
for i in range(len(paraLayerNumNodes) - 1):
tempInput = paraLayerNumNodes[i]
tempOutput = paraLayerNumNodes[i + 1]
tempLinear = nn.Linear(tempInput, tempOutput)
tempModel.append(tempLinear)
tempModel.append(getActivator(paraActivators[i]))
self.model = nn.Sequential(*tempModel)
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=paraLearningRate)
self.lossFunction = nn.MSELoss().to(self.device)
def setDataSrc(self, dataSrc, trainingSetProportion):
'''
Read the data by path
:param dataSrc: Dataset path
:param trainingSetProportion: Percentage of training data in total data
:return: Dataset
'''
self.dataset = Dataset(dataSrc, trainingSetProportion)
...
...self.device = torch.device("cuda") ( Or write it as 'cuda:0') Declare the equipment used . torch.device For and on behalf of torch.Tensor The object assigned to the device , Yes cpu and cuda Two kinds of . And why is it written here "cuda" instead of "gpu" Well ? because gpu You can't participate in programming by yourself , Must pass cuda As an intermediary agent .
CUDA(Compute Unified Device Architecture), It's the video card manufacturer NVIDIA The new computing platform . CUDA It's a kind of NVIDIA General parallel computing architecture , The architecture enables GPU Able to solve complex computing problems . It contains CUDA Instruction set architecture (ISA) as well as GPU Internal parallel computing engine .
CUDA Is a software programming framework , Integrate a lot of low-level common code , With this framework, we can reduce the workload of programming , It is very convenient for us to call GPU, therefore CUDA It is a convenient call for us to write code GPU Framework .( From the blogger's summary )
Simply speaking , If your computer is N Card will be compatible cuda, utilize GPU Running program , When the number of network layers is large, it will be very fast . If it is A The card seems to be very troublesome to achieve compatibility .
Here attached CUDA Installation tutorial (CUDA Installation tutorial ( Hyperdetail )_Billie Blog of hard study -CSDN Blog _cuda install )
notes : Use torch.cuda.is_available() You can return whether it is currently available cuda.
At the same time, add to Then declare that the equipment used can realize the quasi replacement of operation
For example, the above No 21 That's ok self.lossFunction = nn.MSELoss().to(self.device) Is to move the declared loss function to GPU Up operation . Combined with my experience , A code needs to use GPU There are three main points at the operation end :
- Remove the matrix from numpy The matrix in is transformed into torch Medium tensor Matrix time . Common code is converted to : " torch.as_tensor().to(self.device)" Fill in brackets with numpy matrix .
- When declaring network objects, use GPU, For example, the network class I am building now is baseAnn, Then don't just write when declaring the object :" ann = baseAnn([4,64,64,64,3], "ssss", 0.01) " It needs to be written as " ann = baseAnn([4,64,64,64,3], "ssss", 0.01).cuda() " Use here .cuda() And .to(torch.device("cuda")) It is equivalent. .
- When declaring a loss function : self.lossFunction = nn.MSELoss().to(self.device)
remember ! For small networks , Use GPU And there is no more CPU The advantages of , But for super large networks, the time cost will increase very much , I will do a simple test at the end of this article .
It works nn.Sequential Method to construct a network , This method is more flexible and fast for simple serial network definition . You only need to know the list of network layers and the activation function string , Then traverse the list of layers . Each traversal selects two adjacent layers to set the linear layer (nn.Linear), Then add the linear layer to the list , Then add the activation function . This is it. 12~18 Description of line code . 19 Yes nn.Sequential(*tempModel) Extract the data in the list (Python Of * Can be (x,...,z) Decompose into x,..,z), Constitute the final self.model The Internet .
20 Yes torch.optim Is a package that implements a variety of optimization algorithms , You need to construct an optimizer object before using self.optimizer Used to save the current state , Different optimization functions have different formal parameter methods , But we all need a list of all parameters that can be iteratively optimized , This can be done through self.model.parameters() obtain . The setup of this optimizer is necessary , Because it is needed later Determine the initial gradient And Update the weights .
Adam Algorithm :
adam Algorithm source :Adam: A Method for Stochastic Optimization
Adam(Adaptive Moment Estimation) It's essentially a momentum term RMSprop, It uses the first-order moment estimation and the second-order moment estimation of the gradient to dynamically adjust the learning rate of each parameter . Its main advantage is that after offset correction , The learning rate of each iteration has a certain range , Make the parameters more stable .
Common algorithm libraries that can be used are Adadelta, Adagrad, Adam, AdamW, SparseAdam, Adamax, ASGD, LBFGS, RMSprop, Rprop, SGD
The activation function in the figure getActivator(paraActivators[i]) Abbreviated , This comes from the following function :
def getActivator(paraActivator: str = 's'):
'''
Parsing the specific char of activator
:param paraActivator: specific char of activator
:return: Activator layer
'''
if paraActivator == 's':
return nn.Sigmoid()
elif paraActivator == 't':
return nn.Tanh()
elif paraActivator == 'r':
return nn.ReLU()
elif paraActivator == 'l':
return nn.LeakyReLU()
elif paraActivator == 'e':
return nn.ELU()
elif paraActivator == 'u':
return nn.Softplus()
elif paraActivator == 'o':
return nn.Softsign()
elif paraActivator == 'i':
return nn.Identity()
else:
return nn.Sigmoid()About forward
Network training is nothing more than a forward and backPropagation( Fringe rights update ) constitute . Because of the original nn.Module Actually, I carry forward Methodical , So every time I write forward Essentially rewriting ( See below ), To achieve forward The method is very simple , Just need a simple code like the following, which is extra good
def forward(self, paraInput):
return self.model(paraInput)At first sight, there must be some doubts about this rewrite , Explain step by step .
This call forward There is a Python The grammatical features of , We didn't use self.forward(data) To use forward passing , Instead, we call our declared network model directly self.model And the use of () Method : self.model(data) To call .
This is from Python Medium __call__ grammar , Just define one def __call__(self, data): function , So directly for this __call__ The class object modified by the function is directly used () Method can be called .
class Module():
def __call__(self, paraData):
print('I call a parameter: ', paraData)
module = Module()
module(233)Output :
233therefore self.model(data) Essentially, it calls call Method .
and nn.Module Medium __call__ The details of neural network forward propagation are packaged in , Here we don't care too much , Because we can visualize how to use it . For our users , The only thing to pay attention to is to put a single __call__ The process iterates many times ( Because the network forward transmission is many forward Series connection of , Or iteration ), and __call__ An exit is reserved in the source code :
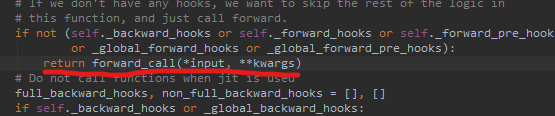
Through this exit, you can jump to rewritable self.forward() Function , So we can rewrite self.forward() Function and add Enter again __call__ Entrance (self.forward()), Implementation source __call__ Iterative code . As for the , How to exit when you finally reach the output part ? This problem is encapsulated in the source code , Never mind .
So there is the following code :
def forward(self, paraInput):
return self.model(paraInput)It's not all forward transfer , It is only built-in forward passing code for iterative connection " The joints "
Then when other member functions want to design training code, if they want to use complete forward transfer Deliver , Use self.forward(data) And self.model(data) In fact, it's the same . Habitually speaking , Everyone uses self.module(data), There is no need to call one more function , and self.forward(data) Just as an iterative part .
Be careful : call The formal parameter of method call must be a torch Medium tensor matrix !
Finish a workout
Explain again , Training is nothing more than a forward and backPropagation( Fringe rights update ) constitute .
def oneRoundTrain(self):
'''
Finish single training to trainingSet
:return: Loss value
'''
if self.dataset == None:
print("Please load the dataset first")
return
tempInputTensor = torch.as_tensor(self.dataset.trainingSet).to(self.device)
tempOutputsTensor = self.model(tempInputTensor)
tempTargetsTensor = torch.as_tensor(self.dataset.trainingLabelSet).to(self.device)
loss = self.lossFunction(tempOutputsTensor, tempTargetsTensor)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()- The first 6 That's ok , Put the data set's numpy The matrix is transformed into torch Of tensor matrix , This process needs to be carried to gpu Up operation
- The first 7 That's ok , That is to call forward Positive transfer , Finally, it returns the prediction obtained by a forward transfer tensor matrix .
- The first 9,10 That's ok , Then the label matrix is also converted to tensor object , Put it into the loss function self.lossFunction Calculate the loss function .
- The first 12 That's ok , after self.optimizer.zero_grad() adopt optimistizer Set the gradient to 0
- The first 14, 16 That's ok Through the loss function result itself backward() Function to reverse calculate penalty information , Finally, through the optimizer optimizer Update the weights , The code is self.optimizer.step().
loss Is the tensor object , and item() Take out the array inside , Returns the calculated value of the final loss function , This value can be used as a measure of the current network fitting , Yue novel Ming fits best . Through observation, it is found that this value is constantly decreasing through the use of functions .
Cycle training and testing
Training and testing can be improved according to their own data , k- Fold and cross , batch Testing, etc. , I use relatively simple test set and training set to separate and single cycle test .
The idea of circular training is to carry out the specified round of training first , Then continue to test , Determine the end point of training according to the accuracy improvement of the test . The latter can avoid over fitting caused by blindly increasing the similarity .
- Function to determine formal parameters paraLowerRound, Indicates a training round ; paraEnhancementThreshold, Indicates the accuracy improvement threshold , Precision threshold .
- perform paraLowerRounds Time training .
- Carry out permanent cycle , Test once per cycle .
- When the accuracy of the test is higher than that of the last time , The increase value is lower than paraEnhancementThreshold when , End of cycle .
def predictForTrainingSet(self):
'''
Predicting the trainingSet
:return: Predictive accuracy
'''
tempInputTensor = torch.as_tensor(self.dataset.trainingSet).to(self.device)
predictionTensor = self.model(tempInputTensor)
index = 0
correct = 0
for line in predictionTensor:
if(line.argmax() == self.dataset.trainingLabelSet[index].argmax()):
correct += 1
index += 1
return float(correct / index)
def predictForTestingSet(self):
'''
Predicting the testingSet
:return: Predictive accuracy
'''
tempInputTensor = torch.as_tensor(self.dataset.testingSet).to(self.device)
predictionTensor = self.model(tempInputTensor)
index = 0
correct = 0
for line in predictionTensor:
if(line.argmax() == self.dataset.testingLabelSet[index].argmax()):
correct += 1
index += 1
return float(correct / index)
def boundedTrain(self, paraLowerRounds: int = 200, paraCheckingRounds: int = 200, paraEnhancementThreshold: float = 0.001):
'''
Multiple training on the data
:param paraLowerRounds: Rounds of Bounded train
:param paraCheckingRounds: Periodic output of current training round
:param paraEnhancementThreshold: The Precision of train
:return: Final testingSet Accuracy
'''
print("***Bounded train***")
# Step 2. Train a number of rounds.
# Training with specified number of rounds
for i in range(paraLowerRounds):
if i % 100 == 0:
print("round: ", i)
# Complete with the three matrices currently passed in temp_input Training for , temp_extended_label_matrix As the target value
self.oneRoundTrain()
# Step 3. Train more rounds.
# Keep training , The training will stop when the lifting range is lower than a certain threshold
print("***Precision train***")
i = paraLowerRounds
lastTrainingAccuracy = 0
while True:
# Train and gain the loss value of the first training
tempLoss = self.oneRoundTrain()
# Hit the checkpoint Output training effect
if i % paraCheckingRounds == paraCheckingRounds - 1:
tempAccuracy = self.predictForTestingSet()
print("Regular round: ", (i + 1), ", training accuracy = ", tempAccuracy)
if lastTrainingAccuracy > tempAccuracy - paraEnhancementThreshold:
break # No more enhancement.
else:
lastTrainingAccuracy = tempAccuracy
print("The loss is: ", tempLoss)
i += 1
# Output the final test data of the current model
result = self.predictForTestingSet()
print("Finally, the accuracy is ", result)
return resultIntroduce here paraCheckingRounds For regular output , It is convenient to monitor the operation .
The first two functions are the prediction of the training set and the test set according to the network , The predicted value is obtained by forward propagation .
Running results
if __name__ == "__main__":
ann = baseAnn([4,64,64,64,3], "ssss", 0.01).cuda()
ann.setDataSrc("D:\Java DataSet\iris.arff", 0.7)
timerStart = time.time()
ann.boundedTrain(500,100)
timerEnd = time.time()
print('time cost: ', 1000 * (timerEnd - timerStart), "ms")There are three hidden layers , The depth is 64, For the time being sigmoid As an activation function .
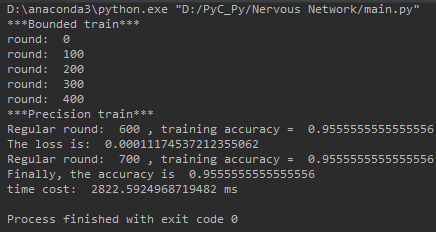
The running time is a little long ? Indeed, for such a small and simple data set, there is no need to set up such a deep network
Next, compare horizontally what I wrote in my Wheelless BP Blog of neural network Number of layers used in [4,8,8,3]
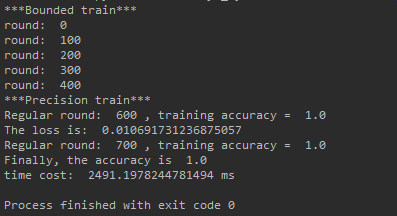
Because the network has randomness , Accuracy is not stable , But it's certain , Finally, the stability of recognition is relatively high .
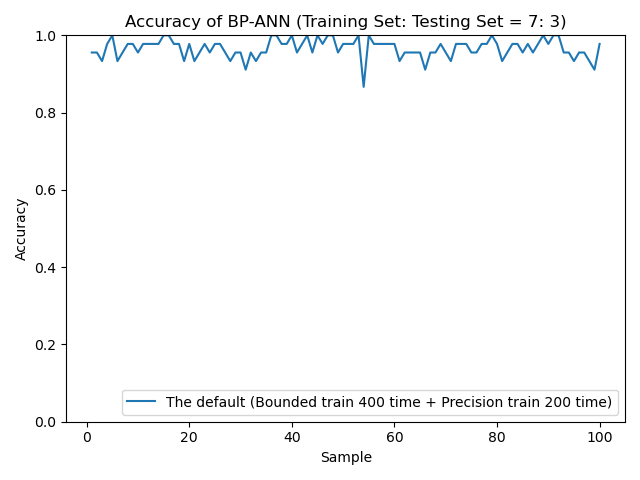
But this result is also better than my previous Wheelless pure BP The effect of the code Is much better , Less training results get better results
GPU And CPU contrast
The hidden layer depth of the network is changed from 64->8, Originally It's a big cut , But the time cut is not big , 2822->2491, It's a little longer than we expected , This should be GPU The problem of , GPU Running a small network doesn't actually CPU So nice , GPU The advantage of high-dimensional image data .
The following is the removal of cuda Use CPU Running efficiency .
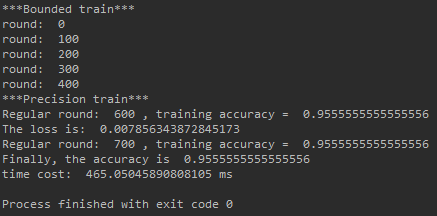
2491ms vs. 465ms, so to speak GPU In depth 8 In the network of CPU. In fact, expand the depth to 16,32,64... The effect is the same .
But when we expand the number of layers to a terrifying size , The result is totally different , When the number of layers becomes [4,1024,1024,1024,3] CPU And GPU The effect is as follows :
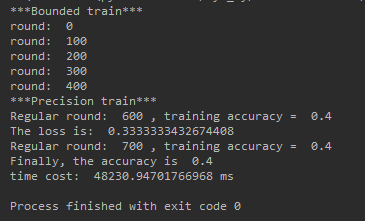
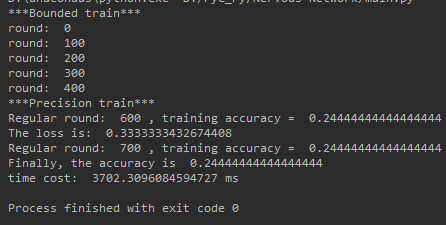
It is very obvious that , After the network grows GPU Yes CPU Showing the rolling trend , It's fast 13 times !
My historical legacy
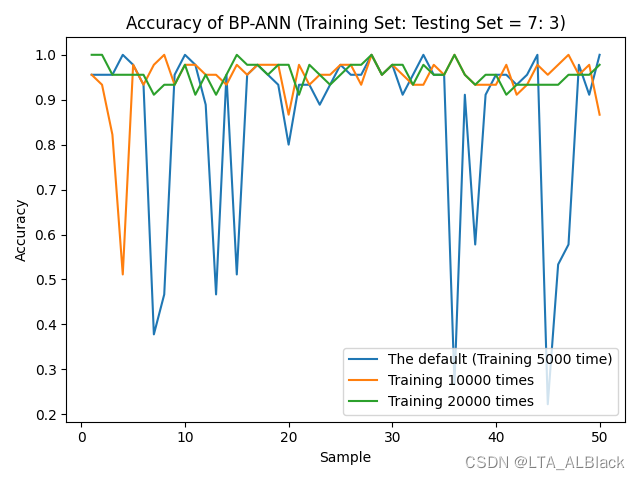
Before, I imitated the teacher's modularity BP When network code ( article : https://blog.csdn.net/qq_30016869/article/details/125015490), use ReLU The effect is very bad after class activates the function . This is the average effect running chart at that time :
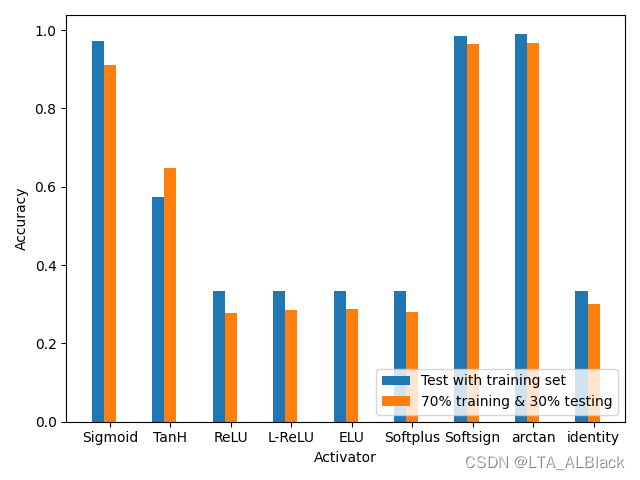
The reason I analyzed at that time was that the most rudimentary randomized initial network edge weight was used in the code , At the same time backPropagation The gradient descent scheme in the process is also a relatively simple derivation , There are no good optimization measures , For example, some possible regular penalties . Eventually, it will lead to gradient explosion or gradient disappearance , At that time, the network settings were not very compatible , To a large extent, it still faces sigmoid Network of .
however Pytorch Of nn.Module It provides a lot of initialization strategies , and Pytorch The default initialization method should be kaiming_normal. Why say probability ? Because the source code strategy in the early version has changed . Early versions used Xavier, The later version is kaiming_normal.
kaiming Initialization method , From the paper Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification
The formula is also derived from “ Variance consistency ” Out method ,kaiming Is aimed at Xavier Initialization method in ReLU The improvement of this kind of activation function due to its poor performance , For details, please refer to the paper . So in Pytorch It is very compatible in the activation function Relu.
See the following figure for the comparison between the final operation results and the past operation results :
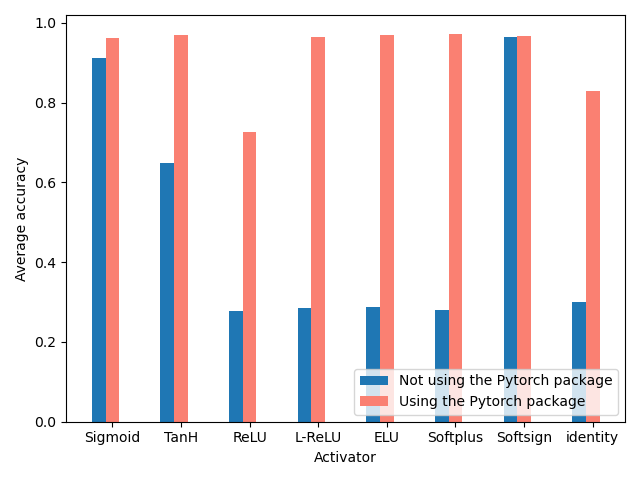
It is obvious that after using the package, more optimization strategies are compatible , The overall recognition has been greatly improved ( notes : Each value is the result of averaging multiple tests ), Everything here ReLU The optimized version of the activation function has been approximated 1.0 Of Accuracy, and ReLU Because of some defects of itself and the number of network layers is too small , So on average Accuracy It's not very high . Actually in the test , With ReLU The increase of the number of layers and depth , The recognition rate has been improved .
(Pytorch No, arctan The activation function of , Therefore, the comparison between this item and the previous code is deleted ~)
In short , Use Pytorch And wheels are really fragrant !!
边栏推荐
猜你喜欢
![[Li Kou] the second set of the 280 Li Kou weekly match](/img/8a/9718c38242f6f6f9637123dc4f3d8a.jpg)
[Li Kou] the second set of the 280 Li Kou weekly match
【SLAM】ORB-SLAM3解析——跟踪Track()(3)

JS音乐在线播放插件vsPlayAudio.js
【RISC-V】外部中断
Remote Sensing Image Super-resolution and Object Detection: Benchmark and State of the Art
IPv6 jobs

JS regular filtering and adding image prefixes in rich text

canvas切积木小游戏代码

StrError & PERROR use yyds dry inventory

Exness foreign exchange: the governor of the Bank of Canada said that the interest rate hike would be more moderate, and the United States and Canada fell slightly to maintain range volatility
随机推荐
3857 Mercator coordinate system converted to 4326 (WGS84) longitude and latitude coordinates
SD卡报错“error -110 whilst initialising SD card
继承day01
An article about liquid template engine
canvas切积木小游戏代码
【Rust 笔记】18-宏
Web security SQL injection vulnerability (1)
Custom attribute access__ getattribute__/ Settings__ setattr__/ Delete__ delattr__ method
[pointer training - eight questions]
Differences and application scenarios between resulttype and resultmap
How to write compile scripts compatible with arm and x86 (Makefile, cmakelists.txt, shell script)
Leetcode problem solving -- 173 Binary search tree iterator
Add one to non negative integers in the array
Deep parsing pointer and array written test questions
蓝色样式商城网站页脚代码
Restful style
Performance analysis of user login TPS low and CPU full
Codeforces 5 questions par jour (1700 chacune) - jour 6
施努卡:3d视觉检测应用行业 机器视觉3d检测
记录一下逆向任务管理器的过程