当前位置:网站首页>Tidb ecological tools (backup, migration, import / export) collation
Tidb ecological tools (backup, migration, import / export) collation
2022-07-06 03:11:00 【Charlotteck】
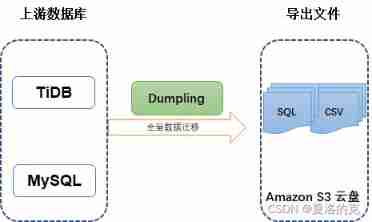
One 、 Dumpling
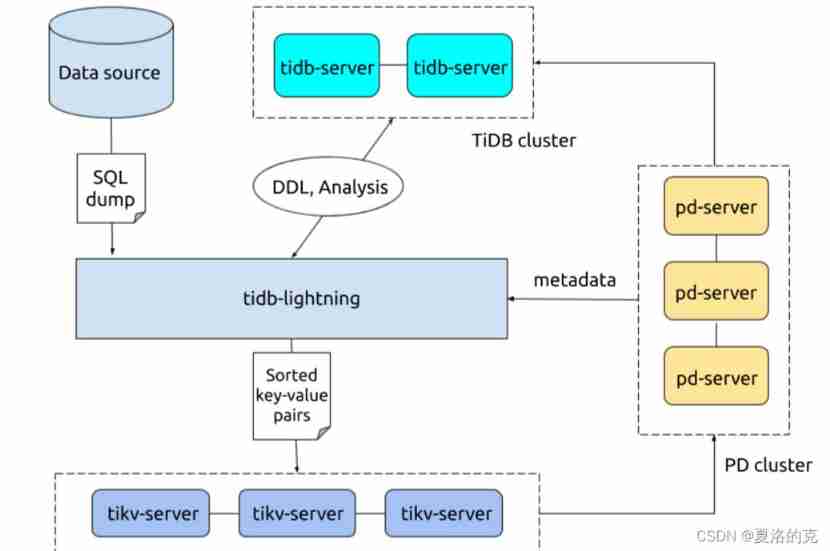
Two 、 Lightning
TiDB Lightning There are two main usage scenarios :
- rapid Import A lot of new data .
- Restore all backup data .
at present ,TiDB Lightning Support :
- Import Dumpling、CSV or Amazon Aurora Parquet Data source of output format .
- From local disk or Amazon S3 Cloud disk Reading data .
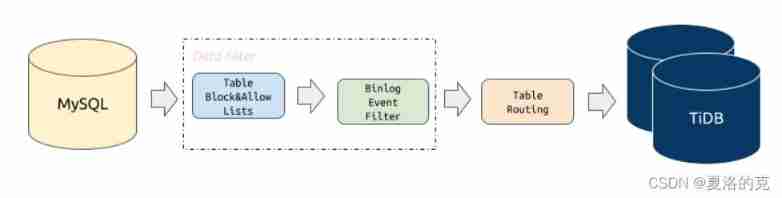
3、 ... and 、 Data Migration(DM)
Four 、 Backup & Restore (BR)
BR In addition to regular backup and recovery , It can also be used for large-scale data migration on the premise of ensuring compatibility .
This paper introduces BR How it works 、 Recommended deployment configuration 、 Use restrictions and several ways of use .
working principle :BR Issue the backup or recovery operation command to each TiKV node .TiKV After receiving the command, perform the corresponding backup or recovery operation .
In a backup or restore , each TiKV Each node will have a corresponding backup path ,TiKV The backup file generated during backup will be saved in this path , During recovery, the corresponding backup files will also be read from this path .

Backup file type
The following two types of files will be generated under the backup path :
- SST file : Storage TiKV Data information backed up
backupmetafile : Store the meta information of this backup , Including the number of backup files 、 Backup file Key Section 、 Backup file size and backup file Hash (sha256) valuebackup.lockfile : Used to prevent multiple backups to the same directory
SST File naming format
SST Document to storeID_regionID_regionEpoch_keyHash_cf Format naming . The format name is explained as follows :
- storeID:TiKV Node number
- regionID:Region Number
- regionEpoch:Region Version number
- keyHash:Range startKey Of Hash (sha256) value , Make sure it's unique
- cf:RocksDB Of ColumnFamily( The default is
defaultorwrite)
Usage restriction
Here's how to use BR Several restrictions for backup recovery :
- BR Back to TiCDC / Drainer Upstream cluster , Recovery data cannot be saved by TiCDC / Drainer Sync to downstream .
- BR Only in
new_collations_enabled_on_first_bootstrapSwitch value Operate between the same clusters . This is because BR Backup only KV data . If the backup cluster and the recovery cluster adopt different sorting rules , Data verification will fail . So when restoring the cluster , You need to make sureselect VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME='new_collation_enabled';The query result of the switch value of the statement is consistent with the query result at the time of backup , Before you can restore .
5、 ... and 、 Binlog
TiDB Binlog Is a tool for collecting TiDB Of binlog, And provide a commercial tool with quasi real-time backup and synchronization functions .
TiDB Binlog The following function scenarios are supported :
- Data synchronization : Sync TiDB Cluster data to other databases
- Real time backup and recovery : Backup TiDB Cluster data , It can also be used for TiDB Recovery in case of cluster failure
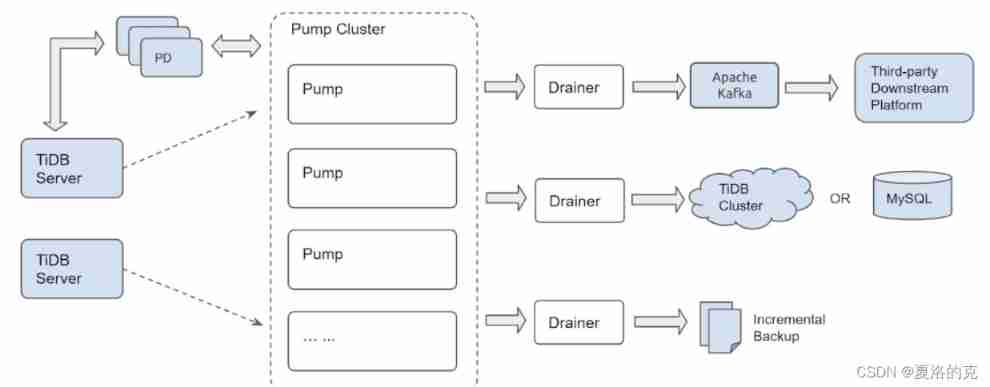
TiDB Binlog Clusters are mainly divided into Pump and Drainer Two components , as well as binlogctl Tools :
Pump
Pump For real-time recording TiDB Produced Binlog, And will Binlog Sort by transaction commit time , And then to Drainer Consumption .
Drainer
Drainer From each Pump To collect Binlog To carry on the merge , then Binlog Turn it into SQL Or data in a specified format , Final synchronization to downstream .
binlogctl Tools
binlogctl It's a TiDB Binlog Supporting operation and maintenance tools , It has the following functions :
- obtain TiDB The cluster's current TSO
- see Pump/Drainer state
- modify Pump/Drainer state
- Pause / Offline Pump/Drainer
The main features
- Multiple Pump Form a cluster , It can be expanded horizontally .
- TiDB Through the built-in Pump Client take Binlog Distribute to each Pump.
- Pump Responsible for the storage Binlog, And will Binlog Provide to in order Drainer.
- Drainer Be responsible for reading Pump Of Binlog, Send to downstream after merging and sorting .
- Drainer Support relay log function , adopt relay log Ensure the consistency of downstream clusters .
6、 ... and 、 TiCDC
TiCDC It's a pull through TiKV The change log implements TiDB Incremental data synchronization tool , It has the ability to restore the data to any upstream location TSO The ability to maintain a consistent state , At the same time provide Open data protocol (TiCDC Open Protocol), Support other systems to subscribe to data changes .
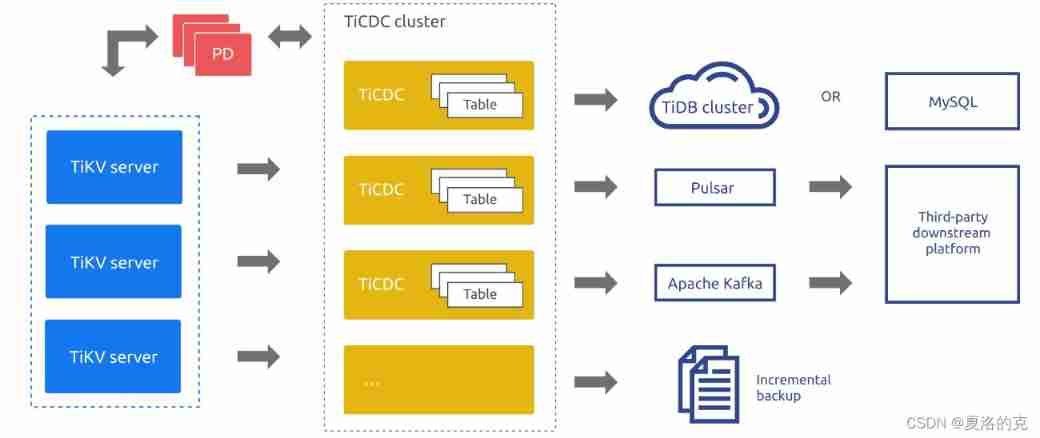
System roles
- TiKV CDC Components : Only the output key-value (KV) change log.
- Internal logic assembly KV change log.
- Provide output KV change log The interface of , Sending data includes real-time change log And incremental scanning change log.
capture:TiCDC Run the process , MultiplecaptureForm a TiCDC colony , be responsible for KV change log Synchronization of .- Every
captureBe responsible for pulling a part KV change log. - To pull one or more KV change log Sort .
- Restore transactions downstream or according to TiCDC Open Protocol For the output .
- Every
Introduction to synchronization function
This section introduces TiCDC Sync function .
sink Support
at present TiCDC sink The module supports synchronizing data to the following downstream :
- MySQL Protocol compatible database , Provide final consistency support .
- With TiCDC Open Protocol Output to Kafka, It can be realized that the current level is orderly 、 There are three consistency guarantees: final consistency or strict transaction consistency .
Synchronization sequence guarantee and consistency guarantee
Data synchronization sequence
- TiCDC For all DDL/DML Can be exported At least once .
- TiCDC stay TiKV/TiCDC During cluster failure, the same message may be sent repeatedly DDL/DML. For repeated DDL/DML:
- MySQL sink Can be repeated DDL, For downstream reentrant DDL ( for example truncate table) Direct execution succeeded ; For downstream non reentrant DDL( for example create table), Execution failure ,TiCDC Will ignore the error and continue to synchronize .
- Kafka sink Will send duplicate messages , But repeated messages will not destroy Resolved Ts Constraints , Users can go to Kafka Filter on the consumer side .
Data synchronization consistency
- MySQL sink
- TiCDC Do not split single table transactions , Guarantee Atomicity of single table transactions .
- TiCDC No guarantee The execution sequence of downstream transactions is exactly the same as that of upstream transactions .
- TiCDC Split cross table transactions by table , No guarantee Atomicity of cross table transactions .
- TiCDC Guarantee The update sequence of a single line is consistent with that of the upstream .
- Kafka sink
- TiCDC Provide different data distribution strategies , You can follow the table 、 Primary key or ts Wait for strategies to distribute data to different Kafka partition.
- Under different distribution strategies consumer The different ways of realizing , Different levels of consistency can be achieved , Including row level order 、 Final consistency or cross table transaction consistency .
- TiCDC Not provided Kafka On the consumer side , Provided only TiCDC Open data protocol , Users can realize Kafka Consumer side of data .
Synchronization limit
Use TiCDC When syncing , Please note the following relevant restrictions and scenarios that are not supported .
Requirements for effective indexing
TiCDC There can only be at least one synchronization Valid index Table of , Valid index Is defined as follows :
- Primary key (
PRIMARY KEY) Is a valid index . - A unique index that meets the following conditions (
UNIQUE INDEX) Is a valid index :- Each column in the index is clearly defined as non empty in the table structure (
NOT NULL). - The virtual build column does not exist in the index (
VIRTUAL GENERATED COLUMNS).
- Each column in the index is clearly defined as non empty in the table structure (
TiCDC from 4.0.8 Version start , You can synchronize by modifying the task configuration There is no valid index Table of , However, the guarantee of data consistency has been weakened . For specific usage and precautions, please refer to Synchronize tables without valid indexes .
Temporarily unsupported scenarios
at present TiCDC The currently unsupported scenarios are as follows :
- It is not supported to use alone RawKV Of TiKV colony .
- Temporarily not supported in TiDB in establish SEQUENCE Of DDL operation and SEQUENCE function . Upstream TiDB Use SEQUENCE when ,TiCDC The upstream execution will be ignored SEQUENCE DDL operation / function , But use SEQUENCE Functional DML The operation can be synchronized correctly .
- Provide partial support for scenarios with large transactions upstream , See
边栏推荐
- Leetcode problem solving -- 99 Restore binary search tree
- 适合程序员学习的国外网站推荐
- Communication between microservices
- MySQL advanced notes
- [ruoyi] enable Mini navigation bar
- Introduction to robotframework (II) app startup of appui automation
- . Net 6 and Net core learning notes: Important issues of net core
- My C language learning records (blue bridge) -- files and file input and output
- [pointer training - eight questions]
- Redis SDS principle
猜你喜欢
Modeling specifications: naming conventions

codeforces每日5題(均1700)-第六天
codeforces每日5题(均1700)-第六天

I sorted out a classic interview question for my job hopping friends
Maturity of master data management (MDM)
【 kubernets series】 a Literature Study on the Safe exposure Applications of kubernets Service
How to do function test well
Analyze menu analysis

有没有完全自主的国产化数据库技术
![[pointer training - eight questions]](/img/fd/1aa3937548a04078c4d7e08198c3a8.png)
[pointer training - eight questions]

随机推荐
Who is the winner of PTA
Performance test method of bank core business system
继承day01
[Yu Yue education] basic reference materials of digital electronic technology of Xi'an University of Technology
C language - Blue Bridge Cup - promised score
Solution: attributeerror: 'STR' object has no attribute 'decode‘
Introduction to robotframework (II) app startup of appui automation
Leetcode problem solving -- 99 Restore binary search tree
Overview of OCR character recognition methods
Fault analysis | analysis of an example of MySQL running out of host memory
【概念】Web 基础概念认知
Introduction to robotframework (III) Baidu search of webui automation
What are the principles of software design (OCP)
Linear regression and logistic regression
[kubernetes series] learn the exposed application of kubernetes service security
Rust language -- iterators and closures
How to do function test well
Audio-AudioRecord Binder通信机制
Custom attribute access__ getattribute__/ Settings__ setattr__/ Delete__ delattr__ method
SD card reports an error "error -110 whilst initializing SD card