当前位置:网站首页>教你用Pytorch搭建一个自己的简单的BP神经网络( 以iris数据集为例 )
教你用Pytorch搭建一个自己的简单的BP神经网络( 以iris数据集为例 )
2022-07-06 03:13:00 【LTA_ALBlack】
*目录*
前言:为什么想写这个博客
前阵子学习MASP的时候接触到了Python的torch库, 了解了Python搭建网络的便捷与方便, 很想模仿构建一个自己的简单网络, 方便自己查阅学习.
而且之前我模仿老师的BP神经网络代码(BP纯源码)写过一篇自学BP神经网络的博客:
基于 Java 机器学习自学笔记 (第71-73天:BP神经网络)_LTA_ALBlack的博客-CSDN博客注意:本篇为50天后的Java自学笔记扩充,内容不再是基础数据结构内容而是机器学习中的各种经典算法。这部分博客更侧重于笔记以方便自己的理解,自我知识的输出明显减少,若有错误欢迎指正!https://blog.csdn.net/qq_30016869/article/details/124902680同时也花时间整理过激活函数和模块化的BP神经网络, 但是无论怎么说, 无轮子的纯代码编写还是比较麻烦的, 但是使用了轮子很多内容就变得简单了. 而且torch本身是兼容GPU加速的, 很适用于大型网络, 因此我感觉有必要再用torch重写下当时的代码, 与此同时也梳理下我当时写模块化BP网络时遇到的ReLU激活函数的问题.
当然最重要的就是为我以后的神经网络编写提供参考, torch还是很方便的, 有了这篇博客, 我应该能很快就搭好一个基本正确的网络 !
数据集
@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
@DATA
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
...
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
...
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
6.3,2.9,5.6,1.8,Iris-virginica
6.5,3.0,5.8,2.2,Iris-virginicairis是一个相对简单的数据集, 表示花的种类, 一共3标签, 是一个简单三分类(请区别与多标签), 因此我们可以得到基本的标签矩阵:
[[1,0,0]
[1,0,0]
[1,0,0]
[1,0,0]
...
[0,1,0]
[0,1,0]
[0,1,0]
[0,1,0]
...
[0,0,1]
[0,0,1]
[0,0,1]
[0,0,1]]如果是多标签的话, 每个标签行" 1 "的个数就不是固定的一个了
然后我写了一个极其简易的读iris的代码, 具体其他数据集再根据情况写自己的reader吧, 其实许多规范的数据集是以标准的标签或者数据矩阵形式的.mat文件体现, 那时写的代码可能更有代表性吧.
import re
import numpy as np
class Dataset:
trainingSet: np.array
trainingLabelSet: np.array
testingSet: np.array
testingLabelSet: np.array
def __init__(self, fileName, trainingSetProportion):
'''
Construction
:param fileName: File path and name
:param trainingSetProportion: Percentage of training data in total data
'''
dataSet = []
labelSet = []
file = open(fileName, 'r', encoding='utf-8')
filecontent = file.read()
classList = []
for i in filecontent.split('\n'):
if len(i) == 0:
continue
if i[0] == '@' and i.find('class') != -1:
innerStr = re.findall(r'[{](.*?)[}]', i)
classList = innerStr[0].split(',')
continue
if i[0] in ['%','@']:
continue
rowStr = i.split(',')
dataSet.append(rowStr[0:4])
tempList = []
for className in classList:
tempList.append(int(className == rowStr[-1]))
labelSet.append(tempList)
# convert to numpy
tempDataSetNumpy = np.array(dataSet, dtype=np.float32)
tempLabelSetNumpy = np.array(labelSet, dtype=np.float32)
# confirm size
allSize = len(dataSet)
rowIndices = np.random.permutation(allSize)
trainSize = int(allSize * trainingSetProportion)
# for train
self.trainingSet = tempDataSetNumpy[rowIndices[0:trainSize], :]
self.trainingLabelSet = tempLabelSetNumpy[rowIndices[0:trainSize], :]
# for test
self.testingSet = tempDataSetNumpy[rowIndices[trainSize:allSize], :]
self.testingLabelSet = tempLabelSetNumpy[rowIndices[trainSize:allSize], :]
file.close()我用的是numpy中存储矩阵的np.array格式存储数据矩阵与标签矩阵, for循环之后就是按照trainingSetProportion分割为数据集与测试集, 分割标签数据集与标签测试集.



构造函数: 确立一个网络
注: 本篇文章您可能需要下面一些库:
import numpy as np
import torch
from torch import nn
import rePytorch中要搭建一个网络往往都需要合理继承nn.Module这个类, 而在构造这个类的时候往往就定义了其网络的框架.
这里我设计了三个形参: 层数列表, 激活函数字符串, 学习因子(梯度步长)
具体可以根据自己需求做变化, 比如可以加入读取数据集路径, 这个我单独用一个setter完成了, 若不是集体管理的代码, 那么编程可以灵活随意的.
class baseAnn(nn.Module):
def __init__(self, paraLayerNumNodes: list = None, paraActivators: str = "s" * 100, paraLearningRate: float = 0.05 ):
'''
Contruction, Create a neural network
:param paraLayerNumNodes: A list is used to describe each layer of network nodes
:param paraActivators: A string is used to describe each layer activators
:param paraLearningRate: Learning Rate
'''
super().__init__()
self.dataset: np.array
self.device = torch.device("cuda")
tempModel = []
for i in range(len(paraLayerNumNodes) - 1):
tempInput = paraLayerNumNodes[i]
tempOutput = paraLayerNumNodes[i + 1]
tempLinear = nn.Linear(tempInput, tempOutput)
tempModel.append(tempLinear)
tempModel.append(getActivator(paraActivators[i]))
self.model = nn.Sequential(*tempModel)
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=paraLearningRate)
self.lossFunction = nn.MSELoss().to(self.device)
def setDataSrc(self, dataSrc, trainingSetProportion):
'''
Read the data by path
:param dataSrc: Dataset path
:param trainingSetProportion: Percentage of training data in total data
:return: Dataset
'''
self.dataset = Dataset(dataSrc, trainingSetProportion)
...
...self.device = torch.device("cuda") (或者写为'cuda:0') 声明了使用的设备. torch.device代表将torch.Tensor分配到的设备的对象, 有cpu和cuda两种. 而这里写的为何是"cuda"而不是"gpu"呢? 因为gpu本身没法参与到编程中来, 必须要通过cuda作为中间代理.
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。
CUDA就是一个软件编程的框架,将很多底层通用的代码集成了,有了这个框架我们就可以减少编程的工作量,非常方便我们调用GPU,所以CUDA是一个方便我们编写代码调用GPU的框架。(来自这位博主总结)
简单来说, 如果你的电脑是N卡那么就能很好兼容cuda, 利用GPU跑程序, 在网络层数比较多时将会非常快. 如果是A卡似乎要实现兼容会非常麻烦.
这里附上CUDA安装教程(CUDA安装教程(超详细)_Billie使劲学的博客-CSDN博客_cuda安装)
注: 使用torch.cuda.is_available() 可以返回当前是否可用cuda.
同时在指定的命令后添加to然后声明使用的设备可以实现运行的准换
例如上面的第21行 self.lossFunction = nn.MSELoss().to(self.device) 就是将声明的损失函数挪到了GPU上运行. 结合我的使用体验来看, 一个代码中需要使用GPU指明运行端的主要有三个地方:
- 将矩阵从numpy中的矩阵转化为torch中的tensor矩阵时. 常见代码转化代码为: " torch.as_tensor().to(self.device)" 括号内填入一个numpy矩阵.
- 在声明网络对象时要使用GPU, 例如我现在构建的网络类是baseAnn, 那么在声明对象时不要单纯写作:" ann = baseAnn([4,64,64,64,3], "ssss", 0.01) "而需要写为" ann = baseAnn([4,64,64,64,3], "ssss", 0.01).cuda() " 这里使用.cuda() 与 .to(torch.device("cuda"))是等价的.
- 声明损失函数时: self.lossFunction = nn.MSELoss().to(self.device)
记住! 对于小体量的网络, 使用GPU并没有比CPU的优势, 但是对于超大型的网络的话时间开销提升就会非常大, 这个我在文章最后会进行简单测试.
这用了nn.Sequential方法来构造网络, 这种方法对于简单的串行网络定义更加灵活快捷. 只需要知道网络层数目列表与激活函数字符串, 然后对于层数列表进行遍历即可. 每次遍历都选择相邻两层设置线性层(nn.Linear), 然后将线性层加入列表, 之后再加入激活函数. 这就是12~18行代码的描述. 19行通过nn.Sequential(*tempModel)将列表内的数据提取出来(Python的*可将(x,...,z)分解为x,..,z), 构成了最终self.model网络.
20行的torch.optim是一个实现了多种优化算法的包, 在使用之前需要构造一个优化器对象self.optimizer用来保存当前的状态, 不同的优化函数有不同的形参方式, 但是统一地都需要一个可进行迭代优化的包含了所有参数的列表, 这个可以通过self.model.parameters() 获取. 这个优化器的设置是必须的, 因为后面需要它来确定初始梯度与更新权值.
Adam算法:
adam算法来源:Adam: A Method for Stochastic Optimization
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。它的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳.
常见的可以使用的算法库有Adadelta, Adagrad, Adam, AdamW, SparseAdam, Adamax, ASGD, LBFGS, RMSprop, Rprop, SGD
图中激活函数getActivator(paraActivators[i])进行了简写, 这个源于下面这样的函数:
def getActivator(paraActivator: str = 's'):
'''
Parsing the specific char of activator
:param paraActivator: specific char of activator
:return: Activator layer
'''
if paraActivator == 's':
return nn.Sigmoid()
elif paraActivator == 't':
return nn.Tanh()
elif paraActivator == 'r':
return nn.ReLU()
elif paraActivator == 'l':
return nn.LeakyReLU()
elif paraActivator == 'e':
return nn.ELU()
elif paraActivator == 'u':
return nn.Softplus()
elif paraActivator == 'o':
return nn.Softsign()
elif paraActivator == 'i':
return nn.Identity()
else:
return nn.Sigmoid()关于forward
网络的训练无非是由一次forward和backPropagation(附边权更新)构成.因为原生的nn.Module其实是携带了forward方法的, 所以每次编写forward本质上是重写(见下), 要实现forward方法非常简单, 只需要额外不错下面这样一个简单的代码就好了
def forward(self, paraInput):
return self.model(paraInput)初见这个重写定然会有一些疑惑, 一步步来解释.
这里调用forward时有一个Python的语法特征, 我们并没有直接使用self.forward(data)来使用正向传递, 而是直接调用我们声明的网络模型self.model且使用()方法: self.model(data)来调用.
这是来源于Python中的__call__语法, 只要定义一个def __call__(self, data): 函数, 那么直接对于这个__call__函数所修饰类对象直接使用()方法就可以进行调用.
class Module():
def __call__(self, paraData):
print('I call a parameter: ', paraData)
module = Module()
module(233)输出:
233因此self.model(data)本质上就是调用了call方法.
而nn.Module中的__call__中包装了神经网络正向传播的细节, 这里我们不要过度在意, 因为我们直观如何使用就好啦. 对于我们使用者, 唯一需要注意的就是把单次的__call__处理进行多次迭代(因为网络正向传递就是许多forward的串联, 或者说是迭代), 而__call__源码中预留了一个出口:
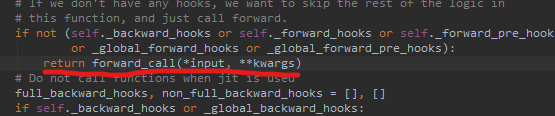
通过这个出口可以跳转到可重写的self.forward()函数中, 于是我们可重写self.forward()函数并在其中添加再进入__call__的入口(self.forward()), 实现源__call__代码的反复迭代. 至于说, 最终到达输出部分怎么退出? 这个问题在源码中封装好了, 不用担心.
于是就有了下面这个代码:
def forward(self, paraInput):
return self.model(paraInput)它不是正向传递的全部, 而仅仅是内置正向传递代码进行迭代连接的" 关节 "
然后在其他成员函数想要设计训练代码时若想使用完整的正向传递, 使用self.forward(data)与self.model(data)其实就是一样的了. 习惯来说, 大家都用的是self.module(data), 没必要多调用一个函数, 而self.forward(data)单纯作为一个迭代部件就好了.
注意: call方法调入的形参必须是一个torch中的tensor矩阵 !
完成一次训练
再次说明, 训练无非是由一次forward和backPropagation(附边权更新)构成.
def oneRoundTrain(self):
'''
Finish single training to trainingSet
:return: Loss value
'''
if self.dataset == None:
print("Please load the dataset first")
return
tempInputTensor = torch.as_tensor(self.dataset.trainingSet).to(self.device)
tempOutputsTensor = self.model(tempInputTensor)
tempTargetsTensor = torch.as_tensor(self.dataset.trainingLabelSet).to(self.device)
loss = self.lossFunction(tempOutputsTensor, tempTargetsTensor)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()- 第6行, 将数据集的numpy矩阵转变为torch的tensor矩阵, 这个过程需要搭载到gpu上运行
- 第7行, 即调用forward正向传递, 最后返回一次正向传递获得的预测tensor矩阵.
- 第9,10行, 之后标签矩阵也转换为tensor对象, 一并放入损失函数self.lossFunction计算损失函数.
- 第12行, 之后self.optimizer.zero_grad()通过optimistizer将梯度设置为0
- 第14, 16行 通过损失函数结果本身自带的backward()函数进行逆向计算惩罚信息, 最后再通过优化器optimizer更新权值, 代码为self.optimizer.step().
loss是张量对象, 而item()取出了里面的数组, 返回最终损失函数的计算值, 这个值可以作为当前网络拟合状况的度量, 越小说明拟合最好. 通过观察发现通过函数使用深入这个值是在不断减少的.
循环训练与测试
训练与测试可以根据自身数据的情况做出改进, k-折交叉, batch测试等等, 我这里用相对简单的测试集与训练集分离并且单一的循环测试.
循环训练思想是先进行指定回合的训练, 然后不断再进行测试, 根据测试的准确度提升量再确定训练的终点. 后者能避免一味增大相似度从而导致的过拟合.
- 函数确定形参paraLowerRound, 表示训练回合; paraEnhancementThreshold, 表示准确度提升量阈值, 即精度阈值.
- 执行paraLowerRounds次训练.
- 进行永循环, 每次循环时进行一次测试.
- 当测试的准确度相比上次准确度来说, 提升值低于paraEnhancementThreshold时, 结束循环.
def predictForTrainingSet(self):
'''
Predicting the trainingSet
:return: Predictive accuracy
'''
tempInputTensor = torch.as_tensor(self.dataset.trainingSet).to(self.device)
predictionTensor = self.model(tempInputTensor)
index = 0
correct = 0
for line in predictionTensor:
if(line.argmax() == self.dataset.trainingLabelSet[index].argmax()):
correct += 1
index += 1
return float(correct / index)
def predictForTestingSet(self):
'''
Predicting the testingSet
:return: Predictive accuracy
'''
tempInputTensor = torch.as_tensor(self.dataset.testingSet).to(self.device)
predictionTensor = self.model(tempInputTensor)
index = 0
correct = 0
for line in predictionTensor:
if(line.argmax() == self.dataset.testingLabelSet[index].argmax()):
correct += 1
index += 1
return float(correct / index)
def boundedTrain(self, paraLowerRounds: int = 200, paraCheckingRounds: int = 200, paraEnhancementThreshold: float = 0.001):
'''
Multiple training on the data
:param paraLowerRounds: Rounds of Bounded train
:param paraCheckingRounds: Periodic output of current training round
:param paraEnhancementThreshold: The Precision of train
:return: Final testingSet Accuracy
'''
print("***Bounded train***")
# Step 2. Train a number of rounds.
# 指定回合数的训练
for i in range(paraLowerRounds):
if i % 100 == 0:
print("round: ", i)
# 以当前传入的三个矩阵完成对于temp_input的训练, temp_extended_label_matrix作为目标值
self.oneRoundTrain()
# Step 3. Train more rounds.
# 继续训练, 当训练到提升幅度低于某个阈值时便停止
print("***Precision train***")
i = paraLowerRounds
lastTrainingAccuracy = 0
while True:
# 训练并获得第一次训练的损失值
tempLoss = self.oneRoundTrain()
# 碰到检查点 输出训练效果
if i % paraCheckingRounds == paraCheckingRounds - 1:
tempAccuracy = self.predictForTestingSet()
print("Regular round: ", (i + 1), ", training accuracy = ", tempAccuracy)
if lastTrainingAccuracy > tempAccuracy - paraEnhancementThreshold:
break # No more enhancement.
else:
lastTrainingAccuracy = tempAccuracy
print("The loss is: ", tempLoss)
i += 1
# 输出当前模型的最终测试数据
result = self.predictForTestingSet()
print("Finally, the accuracy is ", result)
return result这里引入paraCheckingRounds是为了定期进行输出, 方便对于运行情况进行监控.
前两个函数是分别是按照网络对于训练集和测试集的预测, 预测值由正向传播得到.
运行结果
if __name__ == "__main__":
ann = baseAnn([4,64,64,64,3], "ssss", 0.01).cuda()
ann.setDataSrc("D:\Java DataSet\iris.arff", 0.7)
timerStart = time.time()
ann.boundedTrain(500,100)
timerEnd = time.time()
print('time cost: ', 1000 * (timerEnd - timerStart), "ms")隐层有三个, 深度都为64, 暂时都采用sigmoid作为激活函数.
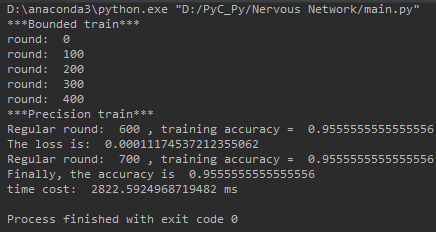
运行时间有些长? 确实对于这样小型简单的数据集没必要设置如此深度的网络
接下来横向比对我在我写的无轮子的BP神经网络的博客中使用的层数[4,8,8,3]
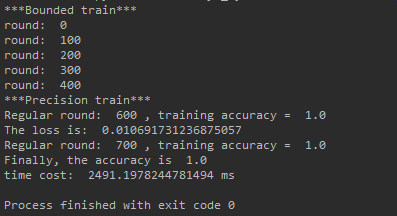
因为网络存在随机性, 准确度不是稳定的, 但是可以确定的是, 最终识别度稳定性是比较高的.
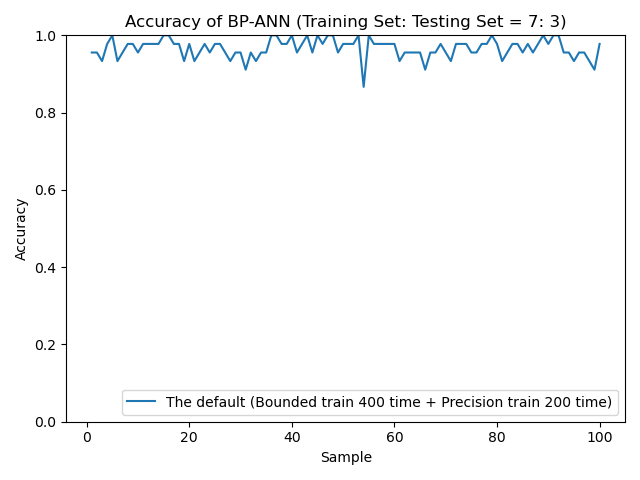
但是这样的结果也要比我之前的无轮子纯BP代码的效果要好很多, 更少的训练结果获得了更好的效果
GPU与CPU对比
上面将网络隐层深度从64->8, 本来是很大程度的削减, 但是时间削减并不大, 2822->2491, 稍微比我们希望的还是长了点, 这应该GPU的问题, GPU运行小体量网络其实没有CPU那么好, GPU的优势还是高维度的图像数据.
下面是去掉cuda使用CPU跑的效率.
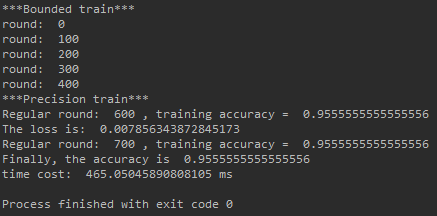
2491ms vs. 465ms, 可以说GPU在深度为8的网络中完败与CPU. 其实再把深度扩大到16,32,64...效果也是如此.
但是当我们把层数扩大到比较可怕的大小的时候, 结果就完全不一样了, 当层数变为[4,1024,1024,1024,3] CPU与GPU的效果如下:
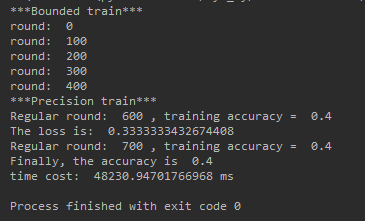
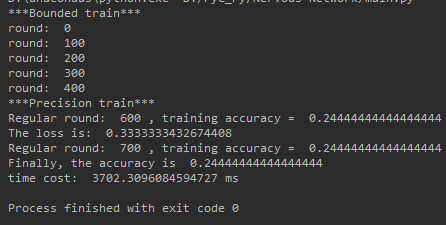
可以非常显然发现, 网络大了后GPU对CPU呈现碾压的态势, 速度快了13倍 !
我的历史遗留问题
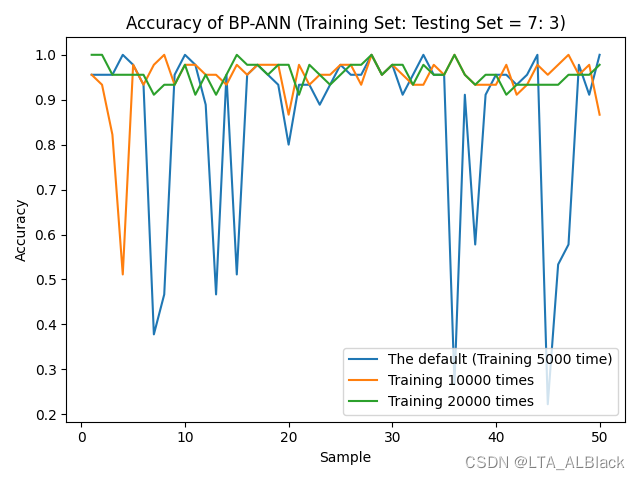
之前我模仿老师的模块化BP网络代码时(文章: https://blog.csdn.net/qq_30016869/article/details/125015490), 采用ReLU类激活函数之后效果非常糟糕. 这是当时的平均效果运行图:
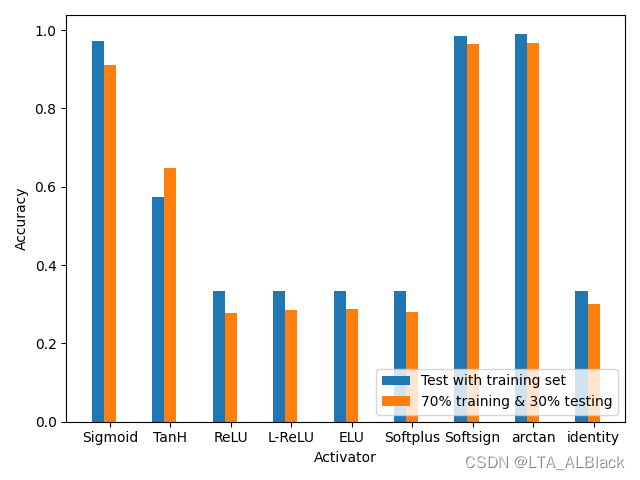
当时我分析的原因是代码中采用了最简陋的随机化初始网络边权, 同时在backPropagation过程中的梯度下降方案也是比较单一的求导, 没有很好的优化措施, 例如可能的一些正则惩罚之类的. 最终导致梯度爆炸或者梯度消失等现象, 当时的网络设置还没有很好的兼容性, 很大程度还是面向sigmoid的网络.
但是Pytorch的nn.Module本身提供了非常多的初始化策略, 而Pytorch默认初始化方式大概率应该是kaiming_normal. 为何说大概率呢? 因为早期版本中的源码其实策略发生过变化的. 早期的版本用的是Xavier, 后期的版本才是kaiming_normal.
kaiming初始化方法, 源于论文 Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification
公式推导同样从“方差一致性”出法,kaiming是针对Xavier初始化方法在ReLU这一类激活函数表现不佳而提出的改进, 详细可以参看论文. 因此在Pytorch在激活函数中很好兼容了Relu.
最终得到的运行结果与过去的运行结果对比见下图:
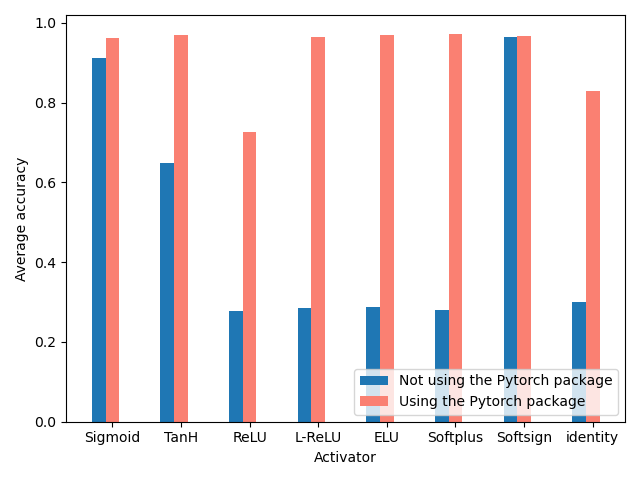
可以非常明显发现使用了包之后因为兼容了更多的优化策略, 整体识别度有较大提高(注: 每个值都是多次测试取平均得到的结果), 这里所有ReLU的优化版激活函数都得到了逼近1.0的Accuracy, 而ReLU因为本身的一些缺陷和网络层数太小, 所以平均Accuracy并不是很高. 实际在测试中, 随着ReLU的层数和深度的增加, 识别率存在一定的提升.
(Pytorch没有arctan的激活函数, 故删去了这一项与曾经代码的比对~)
总结来看, 使用Pytorch和轮子真香!!
边栏推荐
- Descriptor implements ORM model
- NR modulation 1
- OCR文字识别方法综述
- 华为、H3C、思科命令对比,思维导图形式从基础、交换、路由三大方向介绍【转自微信公众号网络技术联盟站】
- Safety science to | travel, you must read a guide
- Web security SQL injection vulnerability (1)
- Eight super classic pointer interview questions (3000 words in detail)
- 2022工作中遇到的问题四
- Performance analysis of user login TPS low and CPU full
- Getting started with applet cloud development - getting user search content
猜你喜欢
![[network security interview question] - how to penetrate the test file directory through](/img/48/be645442c8ff4cc5417c115963b217.jpg)
[network security interview question] - how to penetrate the test file directory through
NR modulation 1
SAP ALV单元格级别设置颜色

指针笔试题~走近大厂
My C language learning records (blue bridge) -- files and file input and output
Modeling specifications: naming conventions
IPv6 jobs
IPv6 comprehensive experiment
4. File modification

mysqldump数据备份
随机推荐
Leetcode problem solving -- 99 Restore binary search tree
1.16 - 校验码
有没有完全自主的国产化数据库技术
Overview of OCR character recognition methods
[Li Kou] the second set of the 280 Li Kou weekly match
MPLS experiment
SAP ALV单元格级别设置颜色
Inherit day01
深入探究指针及指针类型
【若依(ruoyi)】启用迷你导航栏
codeforces每日5题(均1700)-第六天
[padding] an error is reported in the prediction after loading the model weight attributeerror: 'model' object has no attribute '_ place‘
Sign SSL certificate as Ca
Selenium share
NR modulation 1
Leetcode problem solving -- 108 Convert an ordered array into a binary search tree
Web security SQL injection vulnerability (1)
NR modulation 1
Fault analysis | analysis of an example of MySQL running out of host memory
MySQL advanced notes