当前位置:网站首页>Era5 reanalysis data download strategy
Era5 reanalysis data download strategy
2022-07-06 02:53:00 【windawdaysss】
Preface
ERA5 It's the fifth generation ECMWF Atmospheric reanalysis of global climate data , The first part of the dataset is now publicly available (1959- Now? ),ERA5 Data provide hourly atmosphere 、 Estimates of terrestrial and oceanic climate variables .
Download process details
One 、 Download website description and registration
The download website is a foreign website :https://cds.climate.copernicus.eu/cdsapp#!/home, Follow the steps in the figure below ( The network is not good, there may be a bit of a card , Just drink some water and wait ):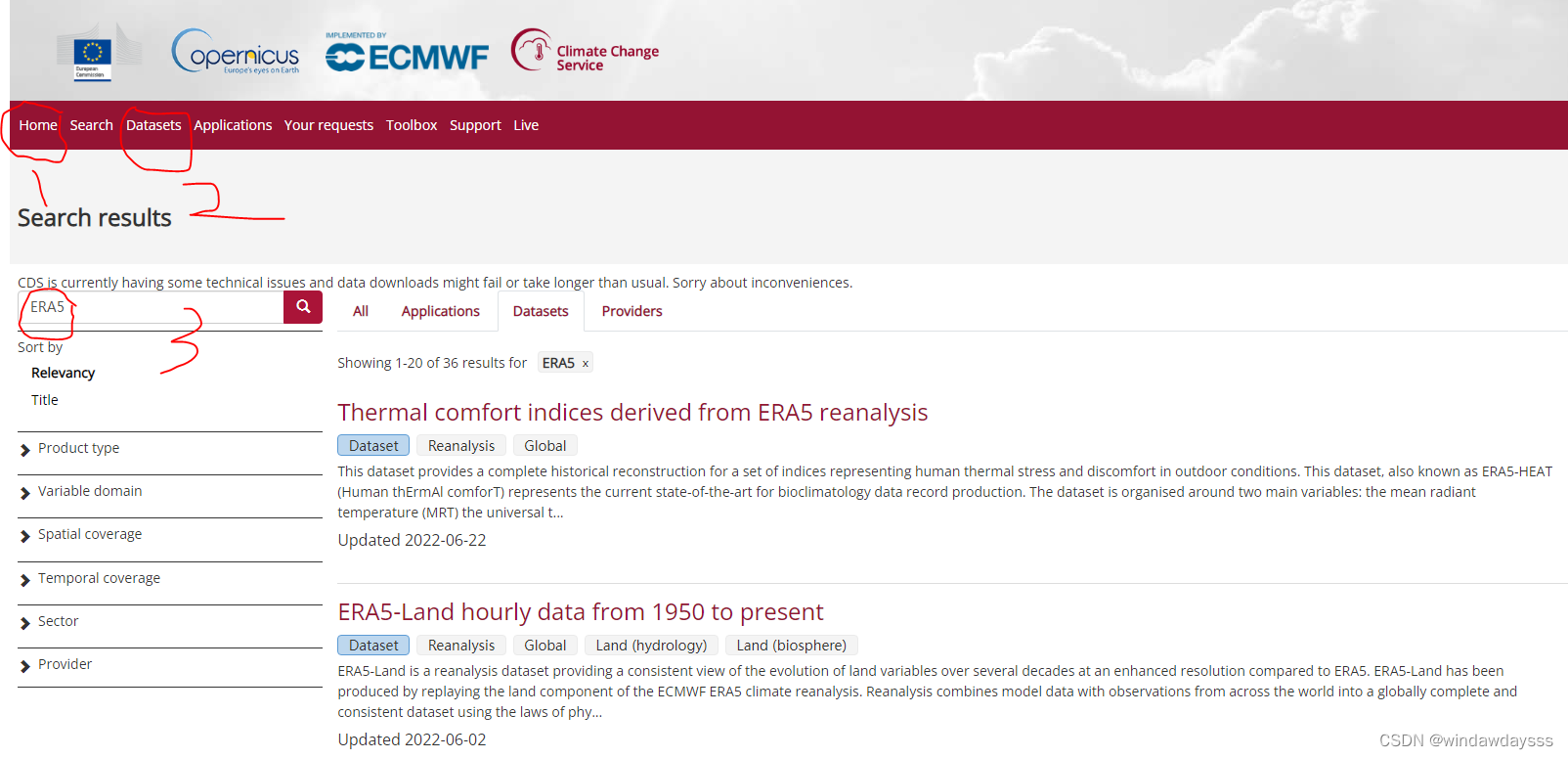
Check the list of various data found on the right , Choose the data you want to download , If it is not clear whether the selected data is correct , You can click in to have a look , such as , I choose the following data set :
After entering the point , default overwiew The composition variables of the data set and the introduction of the data will be introduced in the following figure . When you decide that it is the data you want , open overwiew After Download data that will do .
There are product types Product type,Variable,Pressure level,year…… Options such as , Choose what you need . Pull to the bottom to select an area , The default is global data , If you want to locate the area you want , For example, China , The following settings can be made , Generally, the data format is NetCDF that will do .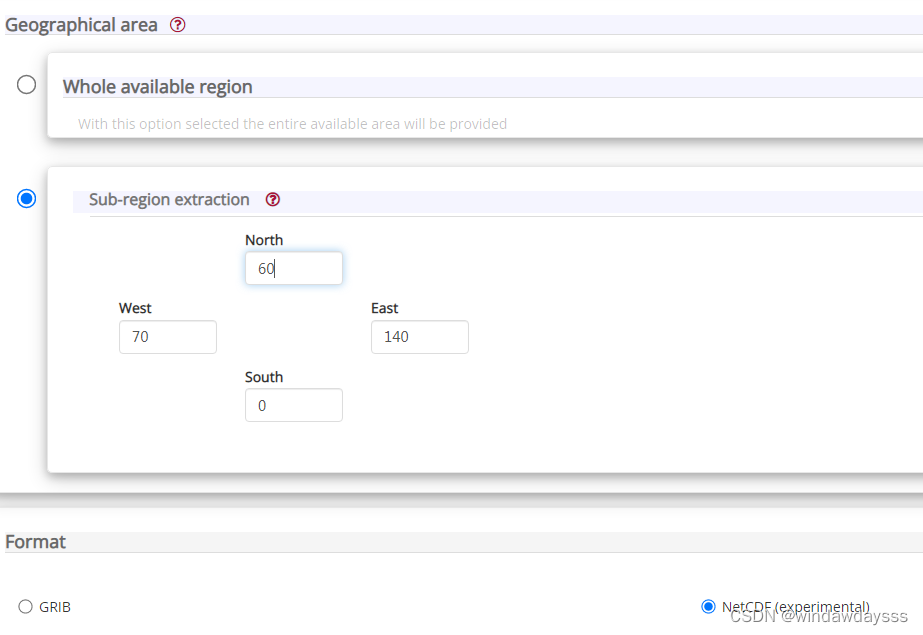
There is show API request, The point is python Script , There is... On the right login/register to submit request, You need to register or login :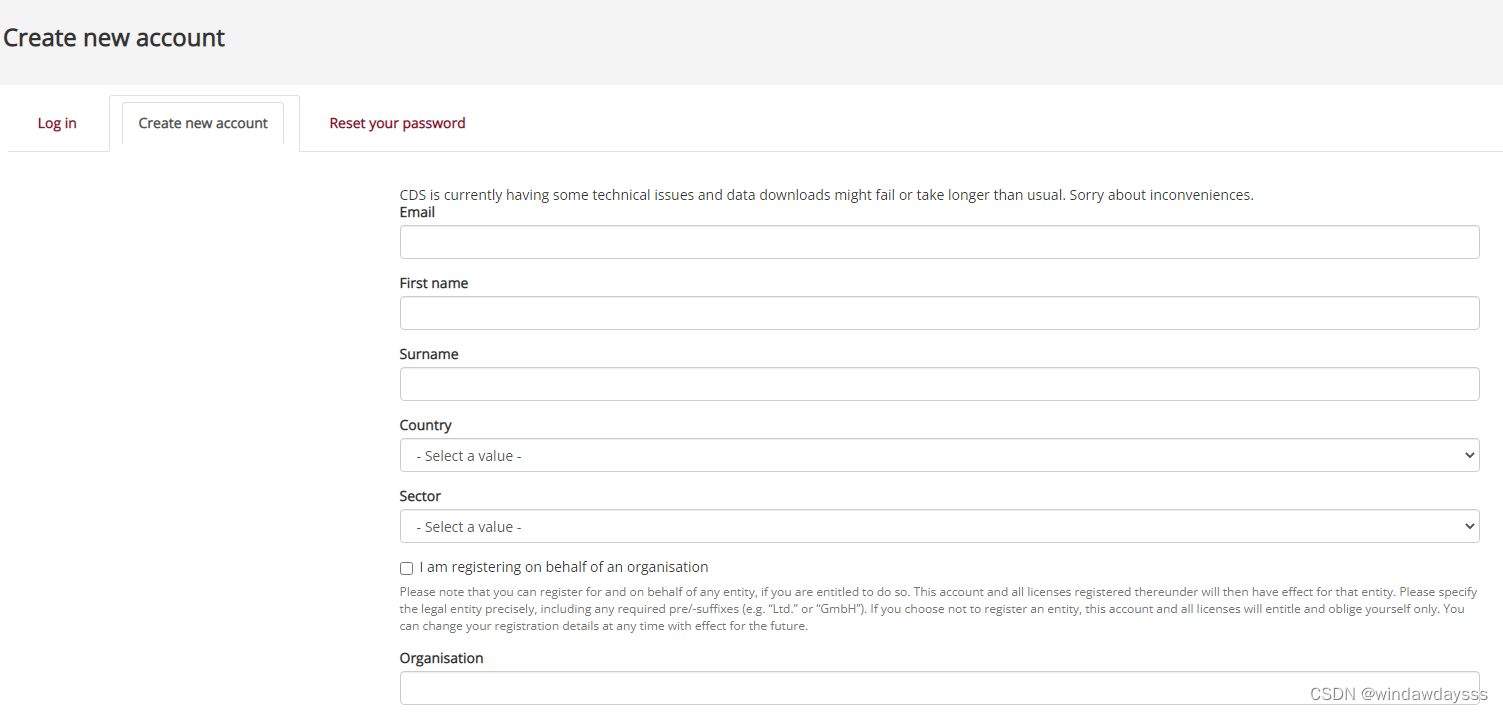
Register as required , Sign in .
Two 、 Download computer configuration
Click the login user name at the top right , There is API key
In the following format , Put it in the computer C:\Users\ Your users \ Next . Build one specifically txt Text , Copy the code in , Save as .cdsapirc file , Select all formats .
url: https://cds.climate.copernicus.eu/api/v2
key: UID:API key
3、 ... and 、 Batch download settings
- IDM yes “Internet Download Manager” For short , Is a very powerful download software .
- Install package Links :https://pan.baidu.com/s/1iojjYOg_Y2NdMcmJahz_pw, Extraction code :dimq, Version is v6.36 Build 7, Resources come from carrot week .
- After downloading the installation package, open the folder , double-click “idman636build7.exe” Start installation IDM, Keep clicking forward , Install to the default location .
- Copy the cracked patch to IDM Installation directory ( The default location is “C:\Program Files (x86)\Internet Download Manager” ), Double click to run the crack patch , Click on “ Crack IDM”, After cracking, click “ complete ” Close the patch .
Be careful : Don't update IDM, Otherwise, the software may not be available . - Yes IDM To configure , Open software , Find... In the main interface “ Options ”, open ;
- In the options window , find “ Connect ” page , modify “ Connection type / Speed ” by “ High speed connection : LAN /Wi-Fi/ The mobile network 4G/ other ”, modify “ Default maximum connections ” by 16, Click on “ determine ” Complete the configuration .
Four 、 Use python Script batch download
install cdsapi Third party Library .
pip install cdsapi
import cdsapi
import calendar
from subprocess import call
def idmDownloader(task_url, folder_path, file_name):
""" IDM Downloader :param task_url: Download task address :param folder_path: Storage folder :param file_name: file name :return: """
# IDM The installation directory
idm_engine = "C:\\Program Files (x86)\\Internet Download Manager\\IDMan.exe"
# Add task to queue
call([idm_engine, '/d', task_url, '/p', folder_path, '/f', file_name, '/a'])
# Start task queue
call([idm_engine, '/s'])
if __name__ == '__main__':
c = cdsapi.Client() # Create user
# Data information dictionary
dic = {
'product_type': 'reanalysis', # The product type
'format': 'netcdf', # data format
'variable': 'relative_humidity', # Variable name
'year': '', # year , Set to null
'month': '', # month , Set to null
'day': [], # Japan , Set to null
'pressure_level': [
'1', '2', '3',
'5', '7', '10',
'20', '30', '50',
'70', '100', '125',
'150', '175', '200',
'225', '250', '300',
'350', '400', '450',
'500', '550', '600',
'650', '700', '750',
'775', '800', '825',
'850', '875', '900',
'925', '950', '975',
'1000'],
'time': [ # Hours
'00:00', '01:00', '02:00', '03:00', '04:00', '05:00',
'06:00', '07:00', '08:00', '09:00', '10:00', '11:00',
'12:00', '13:00', '14:00', '15:00', '16:00', '17:00',
'18:00', '19:00', '20:00', '21:00', '22:00', '23:00'
],
'area': [60, 70, 0, 140],
}
# Download in batches through circulation 2016 Year to 2020 Data of all months of the year
for y in range(201, 2021):
for m in range(1, 13): # Traverse the month
day_num = calendar.monthrange(y, m)[1] # According to month and year , Get the number of days in the current month
# Will be 、 month 、 The day is updated in the dictionary
for d in range(1, day_num + 1):
dic['year'] = str(y)
dic['month'] = str(m).zfill(2)
dic['day'] = str(d).zfill(2)
r = c.retrieve('reanalysis-era5-pressure-levels', dic) # File downloader
url = r.location # Get the file download address
path = r'C:\downloadData\relative_humidity' # Storage folder
filename = 'era5.relative_humidity.' + str(y) + str(m).zfill(2) + str(d).zfill(2) + '.nc' # file name
idmDownloader(url, path, filename) # Added to the IDM Download
5、 ... and 、 explain
After running the script in four , There will be queued, It means waiting in line , here , Click... In the lower right corner of the page that selects the data format submit form, The following will appear , Wait in line , The state becomes in progress 了 , Processing download .
By practice , Usually in the morning during the day 10 From 00 to 34 p.m , The download speed is relatively fast , in addition , The weekend will also be better . After all, it's a foreigner's website , They will definitely be smoother when they are resting .
END
Reference material
边栏推荐
- RobotFramework入门(一)简要介绍及使用
- #PAT#day10
- Trends in DDoS Attacks
- Misc (eternal night), the preliminary competition of the innovation practice competition of the National College Students' information security competition
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 13
- Apt installation ZABBIX
- 2345 file shredding, powerful file deletion tool, unbound pure extract version
- 全国大学生信息安全赛创新实践赛初赛---misc(永恒的夜)
- [ruoyi] set theme style
- Rust language -- iterators and closures
猜你喜欢
Referenceerror: primordials is not defined error resolution
Shell script updates stored procedure to database
淘宝焦点图布局实战
微服务注册与发现
Blue Bridge Cup group B provincial preliminaries first question 2013 (Gauss Diary)
![[ruoyi] enable Mini navigation bar](/img/28/a8b38aecd90c8ddc98333f0e2d3eab.png)
[ruoyi] enable Mini navigation bar
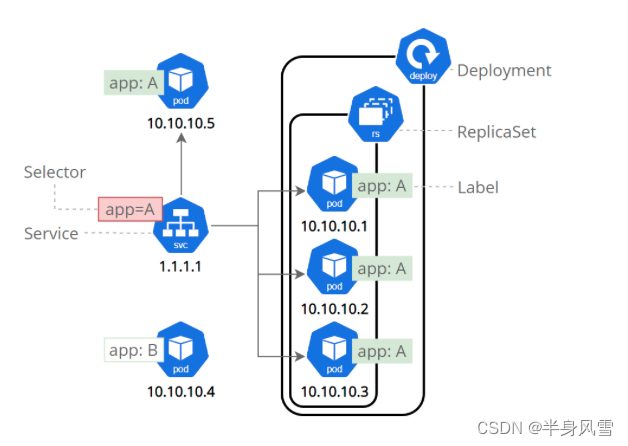
【Kubernetes 系列】一文學會Kubernetes Service安全的暴露應用
#PAT#day10

Déduisez la question d'aujourd'hui - 729. Mon emploi du temps I
Introduction to robotframework (I) brief introduction and use
随机推荐
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 16
Software design principles
#PAT#day10
Single instance mode of encapsulating PDO with PHP in spare time
Solution: attributeerror: 'STR' object has no attribute 'decode‘
Qt发布exe软件及修改exe应用程序图标
MySQL advanced notes
Microsoft speech synthesis assistant v1.3 text to speech tool, real speech AI generator
JS regular filtering and adding image prefixes in rich text
Briefly describe the implementation principle of redis cluster
PMP practice once a day | don't get lost in the exam -7.5
Redis cluster deployment based on redis5
RobotFramework入门(一)简要介绍及使用
Misc (eternal night), the preliminary competition of the innovation practice competition of the National College Students' information security competition
Summary of Bible story reading
Looking at the trend of sequence modeling of recommended systems in 2022 from the top paper
Microservice registration and discovery
故障分析 | MySQL 耗尽主机内存一例分析
How to accurately identify master data?
How to read excel, PDF and JSON files in R language?