当前位置:网站首页>Redis (replicate dictionary server) cache
Redis (replicate dictionary server) cache
2022-07-06 03:51:00 【Passerby Chen】
Redis(REmote DIctionary Server, Remote data services )
Redis(REmote DIctionary Server, Remote data services ) Yes, it is C Language Developed an open source high-performance Key value pair (key-value) database ,Redis Save all data in memory . Official test data ,50 Individual concurrent execution 100000 A request , The speed of reading is zero 110000 Time /s, The speed of writing is 81000 Time /s , And Redis Multiple key value data types are provided to meet the storage requirements in different scenarios , So far, Redis The supported key value data types are as follows :key always String type ,redis Supported data types Refers to value Types of data that can be stored .
Redis The default is 16 A database , The number is from 0~15. 【 The default is 0 Signal library 】
keys *: Query all key
exists key: Judge whether there is a specified key If there is a return 1, Otherwise return to 0
expire key Number of seconds : Set this key Lifetime in cache
- ttl key: Show assignments key The rest of the time
If the return value is Positive numbers : Appoint key The rest of the time
If the return value is -1: Never expireIf the return value is -2: Does not exist or has expired
del key: Delete the specified key
rename key new key: rename
type key: Judge a key The type of
ping : Test whether the connection is connected
select index: Switch Library
move key index: hold key Move to library number (index Is the library number )
flushdb: Clear the current database
flushall: Clear all databases under the current instance
Redis data type
String type | string | |
List the type | List | similar LinkedList |
Hash type / Hash type | hash | similar HashMap, Suitable for storing objects ( attribute , Property value ) |
Collection types ( disorder ) | set | similar HashSet, Disorder and uniqueness |
Ordered set type | zset/sorted_set | Orderly and unique |

Redis The persistence of
Redis Because it stores all the data in memory , In order to make Redis After the restart, the data can still be guaranteed not to be lost , Data need to be Sync from memory to hard disk ( file ) in , The process is persistence .
Redis Support two ways of persistence , One is RDB The way , One is AOF The way .
RDB Persistence : This mechanism can generate point in time snapshot of data set in specified time interval (point-in-time snapshot).
AOF Persistence : Record all write commands executed by the server , And when the server starts , Restore the dataset by reexecuting these commands .
RDB Persistence mechanism : Default It's on , No configuration required
| keyword | Time ( second ) | key Modify quantity | explain |
|---|---|---|---|
| save | 900 | 1 | Every time 900 second (15 minute ) There are at least 1 individual key change , be dump memory dump |
| save | 300 | 10 | Every time 300 second (5 minute ) There are at least 10 individual key change , be dump memory dump |
| save | 60 | 10000 | Every time 60 second (1 minute ) There are at least 10000 individual key change , be dump memory dump |
AOF Persistence mechanism : To use, you need to configure , Open manually AOF Persistence
| keyword | Time to persist | explain |
|---|---|---|
| appendfsync | always | Every time the update command is executed , Persistent once |
| appendfsync | everysec | Persist once per second |
| appendfsync | no | Non persistence |
RDB Persistence and AOF Persistence is different
| advantage | shortcoming | |
| RDB | 1.RDB Speed ratio when recovering large data sets AOF It's faster to recover ( Because its files are better than AOF Small ) 2.RDB It's better than AOF Better | 1.RDB The persistence of is not timely ( At regular intervals ), There may be data loss 2.RDB During persistence, if the file is too large, it may cause server blocking , Stop receiving client requests |
| AOF | 1.AOF The durability is more durable ( Every second. or Save once per operation ) 2.AOF The contents of the document are very easy to read , Analyze the document (parse) It's easy too ,AOF It's an incremental operation | 1.AOF The volume of the file is usually larger than RDB Volume of file 2.AOF May be slower than RDB |
RDB and AOF The difference between ?
RDB: Default on , Perform persistence operation within a certain time interval , Synchronize the data in memory into a binary file , The file size is small , Faster recovery , Good performance , But it is prone to data loss .
AOF: Manual opening required , Persistence can be achieved per second or after each operation , The default is to persist once per second , take redis The operation command of is saved to an incremental file , File size is large , Slow recovery , Low performance , But the database integrity is good .
Jedis Is the use of Java operation Redis The client of ( tool kit :Jedis=JDBC+ drive )
1.Jedis To get started
demand : Use java Code operation Redis Add ( Change ) Delete query
step :
1. Create project , Import jedis Of jar package
2. establish jedis object new Jedis(String host,int port);
3. Calling method
4. Close the object Release resources
public class Demo01 {
public static void main(String[] args) {
//1. establish jedis object
Jedis jedis = new Jedis("localhost",6379);
//2. Calling method
//2.1:string Type operation
// obtain value
String akey = jedis.get("akey");
System.out.println("akey = " + akey);
// Judge key Whether there is
Boolean flag = jedis.exists("akey");
System.out.println("akey Whether there is :"+flag);
//jedis.del("akey"); Delete key
// Storage key-value
jedis.set("dkey","ddd");
//2.2:hash type
jedis.hset("user1","name","zs");
String name = jedis.hget("user1", "name");
System.out.println("name = " + name);
//2.3:list type
jedis.rpush("list1","a","b","c");
System.out.println(jedis.lindex("list1", 2));
//2.4:set type
jedis.sadd("set1","a","b","c");
Set<String> set1 = jedis.smembers("set1");
for (String s : set1) {
System.out.println(s);
}
//3. Close the object
jedis.close();
}
}2.Jedis The use of connection pools -Jedis Advanced
demand : from Jedis From the connection pool jedis
step :
establish JedisPoolConfig object
establish JedisPool object
obtain jedis object
Calling method
The return jedis Object to Jedis Connection pool
public class Demo02 {
public static void main(String[] args) {
//1. establish JedisPoolConfig object
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(5);
config.setMaxWaitMillis(5000);
//2. establish JedisPool object
JedisPool jedisPool = new JedisPool(config, "localhost", 6379);
//3. obtain jedis object
Jedis jedis = jedisPool.getResource();
//4. Calling method demand : If akey There is obtain akey Value ; If akey non-existent Create a akey=aaa Deposit in redis in
if(jedis.exists("akey")){
System.out.println(jedis.get("akey"));
}else{
jedis.set("akey","aaa");
}
//5. The return jedis Object to Jedis Connection pool
jedis.close();
}
}3.JedisUtils Tool class extraction -Jedis Advanced
Purpose : 1. Make sure there is only one pool 2. get jedis object 3. The return
step :
establish JedisUtils Tool class
obtain jedis object
The return jedis object
Make sure there is only one pool Use static code blocks to create connection pool objects
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* Jedis Tool class
* 1. Provide access to jedis Object method getJedis();
* 2. Provide return jedis Object method close(Jedis jedis);
* Optimize : Give Way jedisPool Object has only one Use the singleton mode Declare a static variable JedisPool object Then initialize with static code blocks JedisPool object
*/
public class JedisUtils {
private static JedisPool jedisPool;
static{
//1. establish JedisPoolConfig object
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(5);
config.setMaxWaitMillis(3000);
//2. establish JedisPool object
jedisPool = new JedisPool(config,"localhost",6379);
}
/**
* obtain jedis object
* @return
*/
public static Jedis getJedis(){
//3. obtain jedis object
return jedisPool.getResource();
}
/**
* The return jedis object
* @param jedis
*/
public static void close(Jedis jedis){
if(jedis!=null){
jedis.close();
}
}
}Redis The pattern of
Standaloan Pattern ( standalone mode ) Stand alone mode refers to running in a single server Redis Program , Is the most primitive and basic mode . All services are connected to one Redis service , This mode is not applicable to production . In case of downtime , Memory explosion , It may cause all connections to change redis The cache failure of the service caused an avalanche
Master-slave Pattern ( A master-slave mode ) Can achieve read-write separation , The data backup . But it's not 「 High availability 」 Of
- Sentinel Pattern ( Sentinel mode ) It can be regarded as master-slave mode 「 High availability 」 edition , It introduces Sentinel To the whole Redis Service cluster for monitoring . But because there is only one master node , Therefore, there is still a write bottleneck .
Cluster Pattern ( Cluster pattern ) It not only provides a highly available means , At the same time, the data is saved in pieces in each node , It can support high concurrency write and read . Of course, the implementation is also the most complex .
1.Master-slave Pattern ( A master-slave mode )

Redis The master-slave mode of refers to master-slave replication :
- From the server to the master server
SYNCorPSYNCcommand- Primary server execution
BGSAVEcommand , Generate RDB file , And use the cache to record all write commands from now on- RDB After the file is generated , The master server will send it to the slave server
- Load... From the server RDB file , Update your database status synchronously to the master server
BGSAVEThe state of being ordered .- The master server sends all write commands of the buffer to the slave server , The slave service will execute these write commands , The database state is synchronized with the latest state of the main server .
SYNC And PSYNC The difference between
- SYNC
Re initiate from the server to the master serverSYNCcommand , The main server will All the data Regenerate again RDB The snapshot is sent to the server for synchronization- PSYNC
Re initiate from the server to the master serverPSYNCcommand . master server Judge whether it is necessary to complete resynchronization or only send the write command executed during the disconnection to the slave server according to the deviation of the data of both parties .PSYNC How to realize partial resynchronization ?
The realization of partial resynchronization mainly depends on three parts :
1. Record the copy offset
2. Copy backlog buffer
3. Recording server ID
2.Sentinel Pattern ( Sentinel mode )


3.Cluster Pattern ( Cluster pattern )
Redis Cluster pattern of In order to solve the horizontal expansion of the system and the storage of massive data , If you have a lot of data , So you can use it redis cluster.

边栏推荐
- 阿里测试师用UI自动化测试实现元素定位
- mysql关于自增长增长问题
- BUAA magpie nesting
- Prime protocol announces cross chain interconnection applications on moonbeam
- C language circular statement
- [Key shake elimination] development of key shake elimination module based on FPGA
- 3.1 rtthread 串口设备(V1)详解
- P7735-[noi2021] heavy and heavy edges [tree chain dissection, line segment tree]
- Prime Protocol宣布在Moonbeam上的跨链互连应用程序
- Microkernel structure understanding
猜你喜欢
![[practice] mathematics in lottery](/img/29/2ef2b545d92451cf083ee16e09ffb4.jpg)
[practice] mathematics in lottery
简易博客系统
Flask learning and project practice 9: WTF form verification
Network security - Security Service Engineer - detailed summary of skill manual (it is recommended to learn and collect)
Ks008 SSM based press release system
1、工程新建
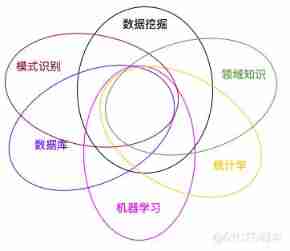
On Data Mining
KS008基于SSM的新闻发布系统
C#(二十七)之C#窗体应用
BUAA magpie nesting
随机推荐
Mathematical modeling regression analysis relationship between variables
Shell pass parameters
Flask learning and project practice 8: introduction and use of cookies and sessions
3分钟带你了解微信小程序开发
UDP reliable transport protocol (quic)
简易博客系统
3.1 rtthread 串口设备(V1)详解
Cubemx 移植正点原子LCD显示例程
Why do you want to start pointer compression?
MySQL about self growth
2. GPIO related operations
2.1 rtthread pin device details
Image super resolution using deep revolutionary networks (srcnn) interpretation and Implementation
STC8H开发(十二): I2C驱动AT24C08,AT24C32系列EEPROM存储
Pytoch foundation - (1) initialization of tensors
Recommended papers on remote sensing image super-resolution
Blue style mall website footer code
[optimization model] Monte Carlo method of optimization calculation
How do we make money in agriculture, rural areas and farmers? 100% for reference
Network security - Security Service Engineer - detailed summary of skill manual (it is recommended to learn and collect)