当前位置:网站首页>Target detection -- intensive reading of yolov3 paper
Target detection -- intensive reading of yolov3 paper
2022-07-04 08:51:00 【zyw2002】
Abstract( Abstract )

- YOLOv3 stay YOLO Some updates have been made on the basis of , Focus on Improvement Accuracy of detection .
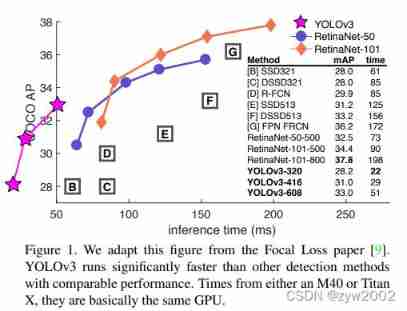
- When the resolution of the picture is 320 × 320,YOLOv3 Use only the 22 ms To test , mAP achieve 28.2. This test result is consistent with SSD Just as accurate , But more than SSD Three times faster . When we look at the old . When setting IOU The threshold of is 0.5 when ,yolov3 stay Titan X You can go to 51 ms Internal implementation 57.9 AP50, And in the retina anet On, you can 198 ms Internal implementation 57.5 AP50, Similar performance , But fast 3.8 times . All the code can be found in https://pjreddie.com/yolo/ Found on the .
1、Introduction

- ( Unique essay style beginning ) Sometimes , You have been perfunctory all year without knowing . For example, I haven't done much research this year , Spend time on twitter , Set up GANs In spite of . With a little momentum left over from last year , I succeeded in YOLO Did some upgrades . But to be honest , Nothing very interesting , It's just minor repairs . At the same time, I also made a little contribution to the research of others .
So there is today's paper . We have a final deadline , Random quotation is required YOLO Some updates , But there are no resources . So please pay attention to the technical report .
The best thing about technology reports is that they don't need to be introduced , You all know why we're here . therefore , The end of this introduction will point the way for the rest of this article . First we'll tell you YOLOv3 Principle . Then I'll tell you how we did it . We'll also tell you something we tried but didn't succeed . Last , We will think about what all this means
2、The Deal

- YOLOv3 The source of the : We mainly get good ideas from others . We also trained a new classifier network , It is better than other classifiers . We'll explain the whole system from the beginning , So you can understand it .(YOLOv3 The experimental results are shown below )
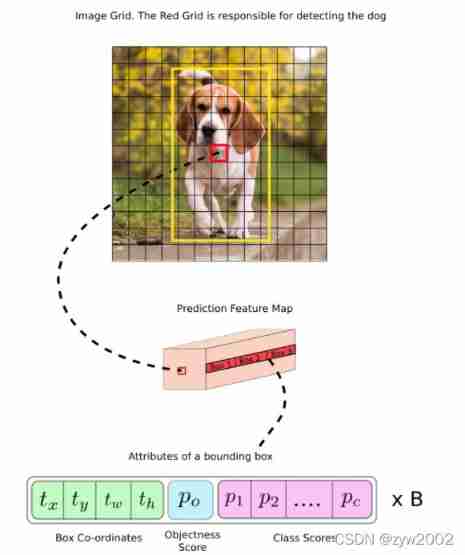
2.1 Bounding Box Prediction

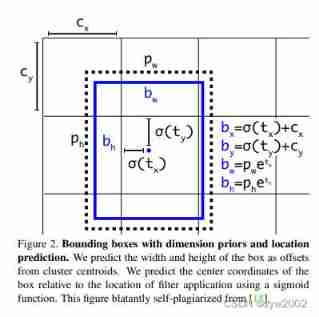
- stay YOLO9000 after , Our system uses clustering algorithm to generate anchor box to predict the boundary box . The network predicts the of each bounding box 4 A coordinate ,tx, ty, tw, th. If the cell is offset from the upper left corner of the image (cx, cy), And the width and height of the previous bounding box are pw, ph, Then the prediction corresponds to :
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h \begin{aligned} b_{x} &=\sigma\left(t_{x}\right)+c_{x} \\ b_{y} &=\sigma\left(t_{y}\right)+c_{y} \\ b_{w} &=p_{w} e^{t_{w}} \\ b_{h} &=p_{h} e^{t_{h}} \end{aligned} bxbybwbh=σ(tx)+cx=σ(ty)+cy=pwetw=pheth

In training , We use the sum of squares of the error loss . If the real value of coordinate prediction is ˆt*, Our gradient is the real value minus our predicted value :ˆt−t. This true value can be easily calculated by the reverse solution of the above equation .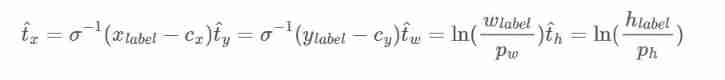


- stay YOLOv3 in , utilize logistic regression To predict object scores ( object score ), That is to say YOLOv1 The confidence index mentioned in the paper ( confidence ) :
Compared with the real bounding box IOU Is the maximum , And above the threshold 0.5 0.5 0.5 And anchor box Its object score = 1 =1 =1
Compared with the real bounding box I O U I O U IOU Not the maximum , But still above the threshold 0.5 0.5 0.5 And anchor box It ignores Its predicted value . - And Faster-RCNN Different ,YOLOv3 Assign only one to each real object anchor box, If not assigned to anchor box Real objects , There will be no coordinate error , Will only have object score error .
2.2 Class Prediction

- In the part of classification prediction ,YOLOv3 It uses logistic classifier , Not before softmax. Mainly because softmax There is a premise in use that there must be Mutually exclusive Of , That is to say, only one category can be predicted for each bounding box , But in some data sets , Such preconditions are not necessarily satisfied between categories ( May also meet 「 people 」 And 「 A woman 」 Categories ) . stay YOLOv3 In training , I used Binary Cross Entropy ( BCE, Binary cross entropy ) To make category prediction .
️ softmax The reason for being replaced
In the object detection task, an object may have multiple labels ;
logistic Activate the function to complete , In this way, we can predict that each category is / No 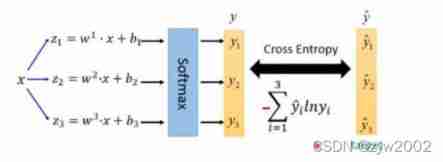
2.3 Predictions Across Scales

- YOLOv3 Three different scale bounding boxes will be predicted in . The whole system will use similar Feature Pyramid Network ( Characteristic pyramid ,FPN ) To extract features from these scales . In the whole feature extraction system ,YOLOv3 Added some convolution , Last output one 3D tensor , Contains bounding box predictions 、 Item score and category prediction .
️ In order to detect objects of different sizes , Designed 3 individual scale
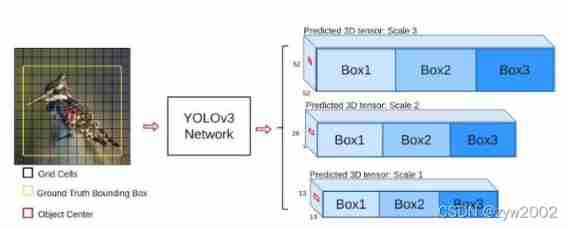
️ On the left : Image pyramid ; Right picture : Single input ;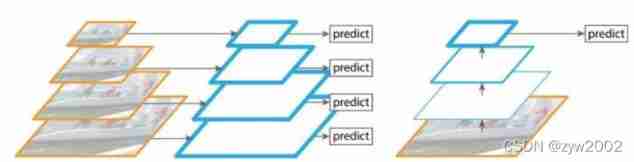
- With COCO In the experiment for training materials , The final output tensor is N × N ×[3∗(4 + 1 + 80)] be used for 4 A bounding box offset 、1 Object attribute prediction and 80 Class prediction .

- Next , We are from the previous 2 Extract feature map from layer , And sample it 2 times . We also get a feature map from the early network , And use Connect (concatenation) Compare it with what we sampled on A combination of features . This method allows us to obtain more meaningful Semantic information , And get more from the previous feature map Fine grained information . Then we add more convolution layers to deal with the characteristic graph of this combination , And finally predict a similar tensor , It's twice as big now .
️ On the left : Different feature maps are used separately ; Right picture : Prediction after fusion of different feature maps 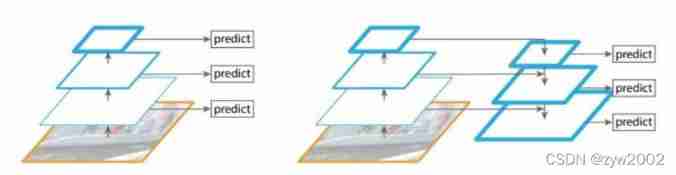

- We did the same design again , To predict the final proportion of the box . therefore , Our prediction of the third scale benefits from all previous calculations and the early fine-grained characteristics of the network .

- We still use k-means Clustering to determine our bounding box a priori . We just chose at random 9 Clusters and 3 Then divide these clusters evenly on the scale . stay COCO On dataset ,9 The two clusters are :(10 × 13)、(16 × 30)、(33 × 23)、(30 × 61)、(62 × 45)、(59 × 119)、(116 × 90)、(156 × 198)、(373 × 326).
A priori frame design 

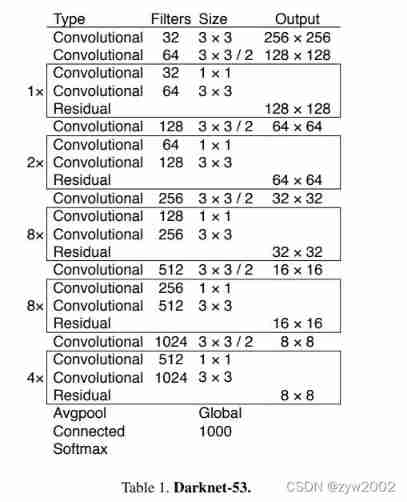
2.4、 Feature Extractor

- We use a new network for feature extraction . Our new network is YOLOv2 The network used in 、Darknet-19 And the newly invented hybrid method of residual network . Our network uses continuous 3 × 3 and 1 × 1 Convolution layer , Yes 53 Convolution layers , So we call it Darknet-53 .
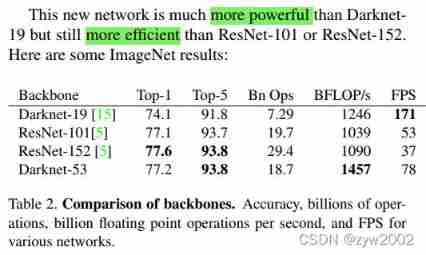
- This new network is better than Darknet19 Much stronger , Than ResNet-101 or ResNet-152 More effective . Here are some ImageNet Result :

- Each network is trained with the same settings , And in 256 × 256 Test under single precision . The running time is at 256 × 256 Of Titan X Measured on . therefore ,Darknet-53 Its performance is comparable to that of the most advanced classifiers , But there are fewer floating-point operations , Faster .Darknet-53 Than ResNet-101 good , Fast 1.5 times .Darknet-53 Have and ResNet-152 Similar performance , And ratio ResNet-152 fast 2 times .Darknet-53 It also realizes the highest floating-point operation per second . This means that the network structure makes better use of GPU, Make its evaluation more efficient , So faster .
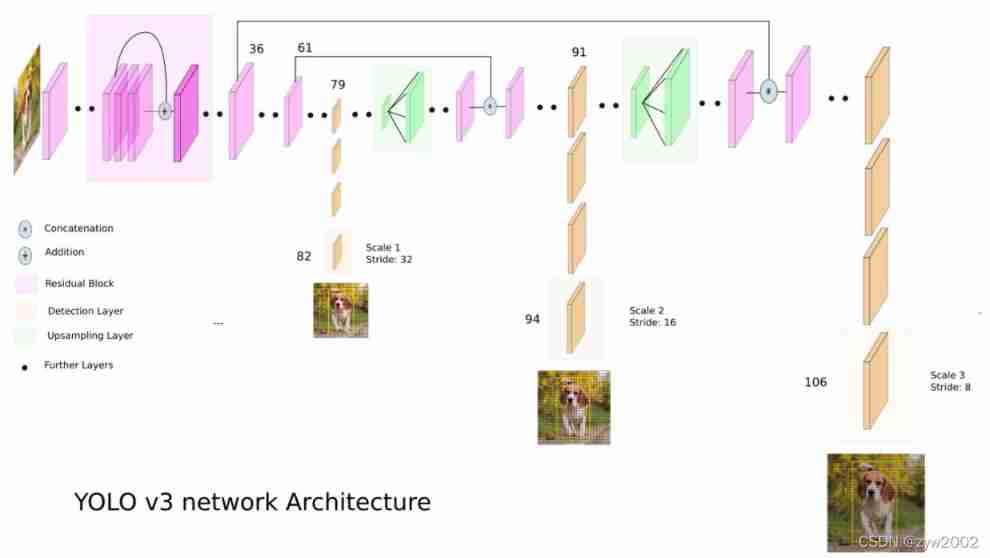
YOLOv3 Object detection architecture ( The figure below comes from here )
notes :
DBL yes Darknet53 The basic components of : Every DBL The unit is convoluted (Conv2D) layer 、 Batch normalization (BN) Layers and activation functions (Leaky ReLU) form .
Residual: Residual module
Concat: Tensor splicing , It expands the dimensions of two tensors .Concat and cfg In the document route Function as
Add: Add tensor , Tensors are added directly , It doesn't expand dimensions .add and cfg In the document shortcut Function as .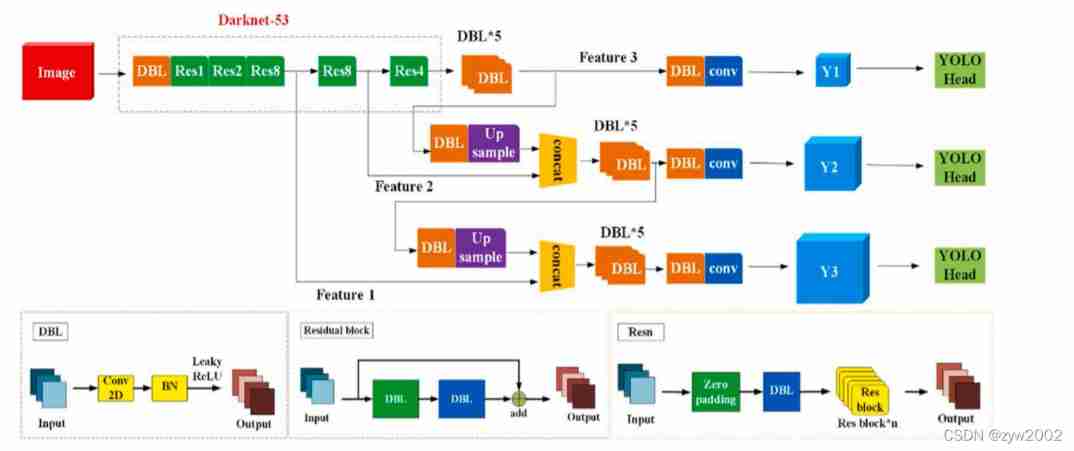
1、yolov3 Extracting multi feature layer for target detection , Three feature layers are extracted , Three feature layers are located in the backbone feature extraction network darknet53 In different places , They are located in the middle layer , Lower middle level , Bottom , Of three characteristic layers shape Respectively (52,52,256)、(26,26,512)、(13,13,1024), The back of these three feature layers is used for stacking and splicing with other feature layers after up sampling (Concat)
2、 The third feature layer (13,13,1024) Conduct 5 Sub convolution processing ( For feature extraction ), After processing, part is used for convolution + On the sampling UpSampling, The other part is used to output the corresponding prediction results (13,13,75),Conv2D 3×3 and Conv2D1×1 The two convolutions play the role of channel adjustment , Adjust to the size required for output .
3、 Convolution + After sampling, we get (26,26,256) The characteristic layer of , Then with Darknet53 Feature layer in network (26,26,512) Splicing , Got shape by (26,26,768), Proceed again 5 Sub convolution , After processing, one part is used for convolution up sampling , The other part is used to output the corresponding prediction results (26,26,75),Conv2D 3×3 and Conv2D1×1 Ditto for channel adjustment
4、 After then 3 Medium convolution + Up sampled feature layer and shape by (52,52,256) Feature layer splicing (Concat), Then convolute to get shape by (52,52,128) The characteristic layer of , Finally, Conv2D 3×3 and Conv2D1×1 Two convolutions , obtain (52,52,75) Characteristic layer
Residual module
Darknet53 The residual convolution in is the first convolution, and the size of the kernel is 3X3、 In steps of 2 Convolution of , The convolution will compress the width and height of the input feature layer , At this point, we can get a feature layer , We named this feature layer layer. After that, we will do another test on the feature layer 1X1 Of convolution and once 3X3 Convolution of , And add this result to layer, At this point, we form the residual structure . Through constant 1X1 Convolution sum 3X3 Convolution and superposition of residual edges , We will Greatly deepened the network . The characteristic of residual network is Easy to optimize , And can be achieved by increasing a considerable depth Improve accuracy . Its internal residual block uses jump connection , It alleviates the problem of increasing depth in the depth neural network The gradient vanishing problem .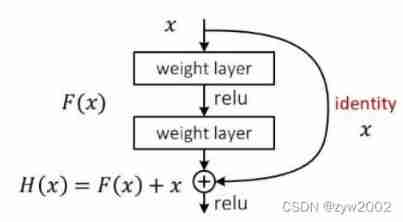
2.5 training

- We use multiscale training , A lot of data expansion , Batch standardization , Including all standard contents . We use Darknet The neural network framework is trained and tested .
loss Calculation process
λ coord ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j [ ( b x − b ^ x ) 2 + ( b y − b ^ y ) 2 + ( b w − b ^ w ) 2 + ( b h − b ^ h ) 2 ] \lambda_{\text {coord }} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} 1_{i, j}^{o b j}\left[\left(b_{x}-\hat{b}_{x}\right)^{2}+\left(b_{y}-\hat{b}_{y}\right)^{2}+\left(b_{w}-\hat{b}_{w}\right)^{2}+\left(b_{h}-\hat{b}_{h}\right)^{2}\right] λcoord ∑i=0S2∑j=0B1i,jobj[(bx−b^x)2+(by−b^y)2+(bw−b^w)2+(bh−b^h)2]
+ ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j [ − log ( p c ) + ∑ i = 1 n B C E ( c ^ i , c i ) ] +\sum_{i=0}^{S^{2}} \sum_{j=0}^{B} 1_{i, j}^{o b j}\left[-\log \left(p_{c}\right)+\sum_{i=1}^{n} B C E\left(\hat{c}_{i}, c_{i}\right)\right] +∑i=0S2∑j=0B1i,jobj[−log(pc)+∑i=1nBCE(c^i,ci)]
+ λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i , j noobj [ − log ( 1 − p c ) ] +\lambda_{\text {noobj }} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} 1_{i, j}^{\text {noobj }}\left[-\log \left(1-p_{c}\right)\right] +λnoobj ∑i=0S2∑j=0B1i,jnoobj [−log(1−pc)]
among :
S : S: S: The number of grids , namely S 2 S^{2} S2 by 13 ∗ 13 , 26 ∗ 26 13 * 13,26 * 26 13∗13,26∗26 and 52 ∗ 52 ; 52 * 52 ; 52∗52;
B : B: B: box;
1 i , j o b j 1_{i, j}^{o b j} 1i,jobj : If b o x b o x box There is a target , The value is 1, Otherwise 0 ; 0 ; 0;
B C E ( B C E( BCE( binary cross entropy ) : B C E ( c ^ i , c i ) = − c ^ i ∗ log ( c i ) − ( 1 − c ^ i ) ∗ log ( 1 − c i ) ): B C E\left(\hat{c}_{i}, c_{i}\right)=-\hat{c}_{i} * \log \left(c_{i}\right)-\left(1-\hat{c}_{i}\right) * \log \left(1-c_{i}\right) ):BCE(c^i,ci)=−c^i∗log(ci)−(1−c^i)∗log(1−ci)
1 i , j noobj 1_{i, j}^{\text {noobj }} 1i,jnoobj : If b o x b o x box No target , The value is 1, Otherwise 0 ; 0 ; 0;
The loss consists of three parts :a、 Positive sample , The encoded length and width are the same xy Difference between axis offset and predicted value .b、 Positive sample , The value of confidence in the prediction results is consistent with 1 contrast ; Negative sample , The value of confidence in the prediction results is consistent with 0 contrast .c、 The actual box , Comparison between the predicted results and the actual results .
3、How We Do
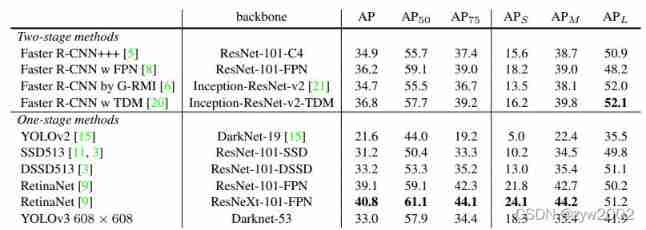
The table above shows , In general A P A P AP In terms of indicators ,YOLOv3 Performance and SSD A variation of the DSSD513 Drive side by side be equal in ability . If the A P 50 ( I O U A P_{50}(I O U AP50(IOU The threshold for 0.5 ) 0.5) 0.5) Look at , be YOLOv3 Even close to RetinaNet, But what the above table doesn't say is whether it is RetinaNet still DSSD,YOLOv3 The speed is fast 3 times above . However, with A P 75 A P_{75} AP75 Come on , YOLOv3 Instead, performance declines .
And on the detection of small objects , YOLOv3 Your performance has improved a lot . This shows that :
- YOLOv3 Good at detecting 「 appropriate 」, But we can't detect a very accurate bounding box .
- YOLOv3 Small object detection ability is improved , However, the detection of medium and large objects is relatively poor .
- If speed is taken into account ,YOLOv3 Overall, the performance was excellent .
4、 Things We Tried That Didn’t Work
In this part, the author records some futile practices .
Anchor box x, y offset predictions
The offset of will x,y Assuming that w or h Multiple , Such an attempt leads to the instability of the model , And the performance is not very ideal
Linear x, y predictions instead of logistic.
take activation function From the original logistic Change it to linear, It also leads to mAP Decline in .
Focal loss
YOLO In fact, the use of independent object score as well as class prediction It's solved Focal Loss The problem to be solved , However, using Focal Loss after YOLOv3 However, there is a decrease of two percentage points , Why is that? , The author is not sure .
Dual IOU thresholds and truth assignment
stay Faster-RCNN Two thresholds are used for training . When the predicted bounding box I O U I O U IOU Greater than 0.7 0.7 0.7 This is regarded as a positive sample , Be situated between 0.3 − 0.7 0.3-0.7 0.3−0.7 Between them , Less than 0.3 0.3 0.3 It is regarded as a negative sample . Such as the YOLOv3 Use similar methods to train , You can't get good results .
5、What This All Means
YOLOv3 It is a fast and accurate object detection system , Even if the performance is unsatisfactory between thresholds , But in the case of threshold , It's very good .
stay COCO The paper pursues the performance of high threshold , Yes YOLO The author doesn't think it is very meaningful . in fact , Human beings cannot accurately see the difference between values with the naked eye , In that case , As long as there is a certain degree of accuracy , Positioning accuracy does not need to pursue such a high standard .
The author hopes , People who apply computer vision technology , It can be used in good 、 The right thing , We have the responsibility to consider the harm that our work may cause to society .
Reference resources :
Why? YOLOv3 It was used Focal Loss after mAP Instead, it fell ?
[ The paper ] YOLOv3 : An Incremental Improvement
Yolo v3 loss function
What’s new in YOLO v3?
Intelligent target detection 26——Pytorch build yolo3 Target detection platform
How to implement a YOLO (v3) object detector from scratch in PyTorch: Part 1
边栏推荐
- 09 softmax regression + loss function
- Leetcode topic [array] -136- numbers that appear only once
- Flutter integrated amap_ flutter_ location
- What sparks can applet container technology collide with IOT
- ArcGIS应用(二十二)Arcmap加载激光雷达las格式数据
- The basic syntax of mermaid in typera
- go-zero微服务实战系列(九、极致优化秒杀性能)
- DM8 uses different databases to archive and recover after multiple failures
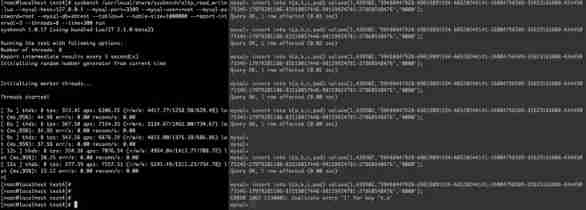
- C语言-入门-基础-语法-数据类型(四)
- awk从入门到入土(11)awk getline函数详解
猜你喜欢
Four essential material websites for we media people to help you easily create popular models
CLion-控制台输出中文乱码
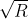
埃氏筛+欧拉筛+区间筛

What exactly is DAAS data as a service? Don't be misled by other DAAS concepts

随机事件的关系与运算

Codeforces Global Round 21(A-E)

小程序容器技术与物联网 IoT 可以碰撞出什么样的火花
09 softmax regression + loss function
Fault analysis | MySQL: unique key constraint failure
C language - Introduction - Foundation - syntax - data type (4)
随机推荐
Codeforces Round #793 (Div. 2)(A-D)
AcWing 244. Enigmatic cow (tree array + binary search)
09 softmax regression + loss function
The old-fashioned synchronized lock optimization will make it clear to you at once!
Guanghetong's high-performance 4g/5g wireless module solution comprehensively promotes an efficient and low-carbon smart grid
[CV] Wu Enda machine learning course notes | Chapter 9
C语言-入门-基础-语法-[主函数,头文件](二)
FOC control
Industry depression has the advantages of industry depression
Démarrage des microservices: passerelle
ArcGIS应用(二十二)Arcmap加载激光雷达las格式数据
Relationship and operation of random events
awk从入门到入土(6)正则匹配
ctfshow web255 web 256 web257
Codeforces Round #803 (Div. 2)(A-D)
Awk from digging into the ground to getting started (10) awk built-in functions
根据数字显示中文汉字
Display Chinese characters according to numbers
snipaste 方便的截图软件,可以复制在屏幕上
How to solve the problem that computers often flash