当前位置:网站首页>写一下跳表
写一下跳表
2022-07-07 18:24:00 【kyhoon】
class Skiplist {
// 1.定义跳表中的节点
class Node{
// 值
int val;
// 节点的右节点和下节点
Node right, down;
public Node(int val, Node right, Node down){
this.val = val;
this.right = right;
this.down = down;
}
public Node(int val){
this(val, null, null);
}
}
//2. 定义跳表相关属性
// 定义头节点默认值
final int DEFAULT_VALUE = -1;
// 定义默认头结点
final Node HEAD = new Node(DEFAULT_VALUE);
// 跳表对应的层级
int levels;
// 跳表中原链表的节点数
int length;
Node head;
// 3.初始化,默认层级为1,长度为1,, 默认头结点
public Skiplist() {
this.levels = 1;
this.length = 1;
this.head = HEAD;
}
// 4. 定义获取从某个节点开始搜索目标值对应的节点的前一个节点(因为节点之间并没有指向前节点的属性,且操作跳表中的节点
// 都是需要从目标节点的前一个节点开始, 所以我们取目标节点的前节点)
private Node get(int num, Node from){
// 1.从哪个节点开始搜索
Node node = from;
// 2.循环的逻辑就是先从左向右,然后从上到下进行查找
while(node!=null){
// 2.1 如果当前节点的右节点不为空而且右节点的值还小于目标值,那么继续向右搜索
while(node.right!=null && node.right.val<num){
node = node.right;
}
// 2.2 当右节点不为空时跳出循环,那么只有可能是右节点的值大于或等于目标值了
// 如果是等于,那么就是找到了,直接返回目标节点的前节点
Node right = node.right;
if(right!=null && right.val == num){
return node;
}
// 2.3如果不是相等情况,则继续向下查找
node = node.down;
}
return null;
}
// 5.查询是否存在
public boolean search(int target) {
// 直接调用上面的查询方法,从表头开始查找,如果返回不为空,代表找到
Node node = get(target, head);
return node != null;
}
// 6.插入节点,大体思路是先找到原链表中插入节点要插入的位置然后进行插入,
// 接着通过抛硬币来决定是否建索引节点
public void add(int num) {
// 6.1 定义临时数组用于存放插入的节点在每一层需要插入的位置的前节点
Node[] nodes = new Node[this.levels];
// 6.2 定义临时数组的下标变量
int i = 0;
// 6.3 定义搜索的开始节点
Node node = head;
// 6.4 和get方法的原理一样
while(node!=null){
// 6.4.1 先从左向右
while(node.right!=null &&node.right.val < num){
node = node.right;
}
// 6.4.2 跳出循环, 无论如何(不管右节点空了,或者是右节点的值已经大于或等于目标值了),
// 此时当前层的这个节点就是插入节点的前节点,所以我们进行记录
nodes[i++] = node;
//6.4.3 继续向下查找
node = node.down;
}
// 6.5 循环完毕,此时临时数组的最后一个节点就是原链表中目标节点的前节点
Node pre = nodes[--i];
// 6.6 定义目标值的节点
Node newNode =new Node(num, pre.right, null);
// 6.7 插入
pre.right = newNode;
// 6.8 长度加一
this.length++;
// 6.9 抛硬币决定是否要建索引节点
coinsFlip(nodes, newNode, i);
}
// 抛硬币决定是否建索引节点的大致逻辑是:通过 0,1随机数及层级数是否小于基准值决定是否建索引
// 如果要建,那么首先得看下需要建索引的当前层是否是在原有层级内,
// 如果是,则进行插入,并继续抛硬币决定上一层是否要建
// 如果不是则,新建头结点,接入新索引节点来新建新的一层
private void coinsFlip(Node[] nodes, Node newNode, int i) {
// 1.定义0,1的随机数生成
Random random = new Random();
int coins = random.nextInt(2);
// 2.定义索引节点的下节点
Node downNode = newNode;
// 3.抛硬币决定是否建索引
while(coins == 1 && this.levels<(this.length>>6)) {
// 3.1 当抛的硬币是1且当前层级数小于基准值时,进行索引节点的创建
if (i > 0) {
//3.2 如果是当前需要插入索引节点在当前层级范围内,则拿到
// 插入索引节点的前节点
Node pre = nodes[--i];
// 定义新索引节点
Node newIndex = new Node(newNode.val, pre.right, downNode);
// 将前节点的右节点设置为新的索引节点
pre.right = newIndex;
// 将新索引节点设置为接下来上一层的要建的新索引节点的下节点
downNode = newIndex;
// 继续抛硬币
coins = random.nextInt(2);
} else {
// 如果已经超出当前层,则新建索引节点
Node newIndex = new Node(newNode.val, null, downNode);
// 新建头结点并将右节点设置为新的索引节点
Node newHead = new Node(DEFAULT_VALUE, newIndex, head);
// 将跳表的头节点指向新的头结点
this.head = newHead;
// 层级数加一
this.levels++;
}
}
}
// 7.删除节点,大体思路就是找到每一层目标节点要删除节点的前节点,并进行删除
public boolean erase(int num) {
// 7.1 定义结果变量,默认是false没找到可以删除的节点
boolean result = false;
// 7.2 从头结点查找下目标节点的前节点
Node node = get(num, head);
// 7.3 如果有,则进行删除,并进行下一层节点的删除
while(node != null){
// 7.3.1 获取删除节点
Node right = node.right;
// 7.3.2 将删除节点的前节点的右节点指向要删除的节点的右节点
node.right = right.right;
// 7.3.3 将删除节点的右节点指向空,触发gc
right.right = null;
// 7.3.4 将结果值赋值为true
result = true;
// 7.3.5 继续查下一层需要删除的目标节点的前节点
node = get(num, node.down);
}
// 7.4 如果删除成功了,则长度减一
if(result){
this.length--;
}
return result;
}
}边栏推荐
- Kubernetes -- detailed usage of kubectl command line tool
- Force buckle 459 Duplicate substring
- MSE API learning
- I Basic concepts
- 深度学习模型压缩与加速技术(七):混合方式
- Nebula Importer 数据导入实践
- Lingyun going to sea | saihe & Huawei cloud: jointly help the sustainable development of cross-border e-commerce industry
- 九度 1201 -二叉排序数遍历- 二叉排序树「建议收藏」
- Mrs offline data analysis: process OBS data through Flink job
- Implement secondary index with Gaussian redis
猜你喜欢
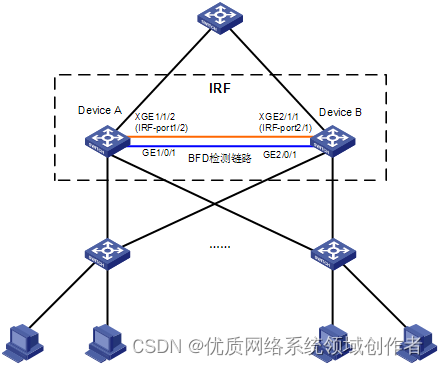
H3C S7000/S7500E/10500系列堆叠后BFD检测配置方法

ERROR: 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your
How to test CIS chip?

Implement secondary index with Gaussian redis
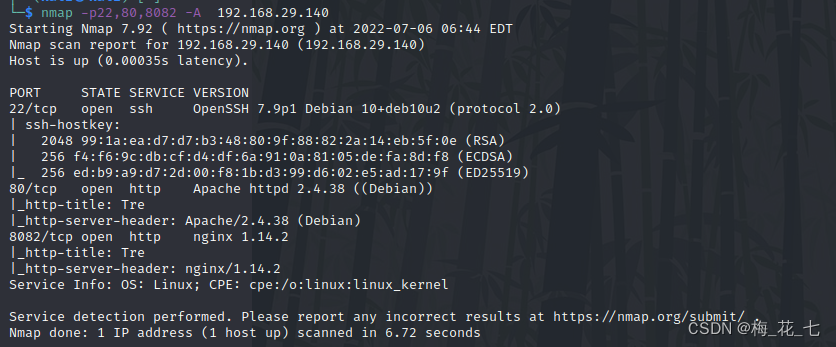
Vulnhub tre1
使用高斯Redis实现二级索引
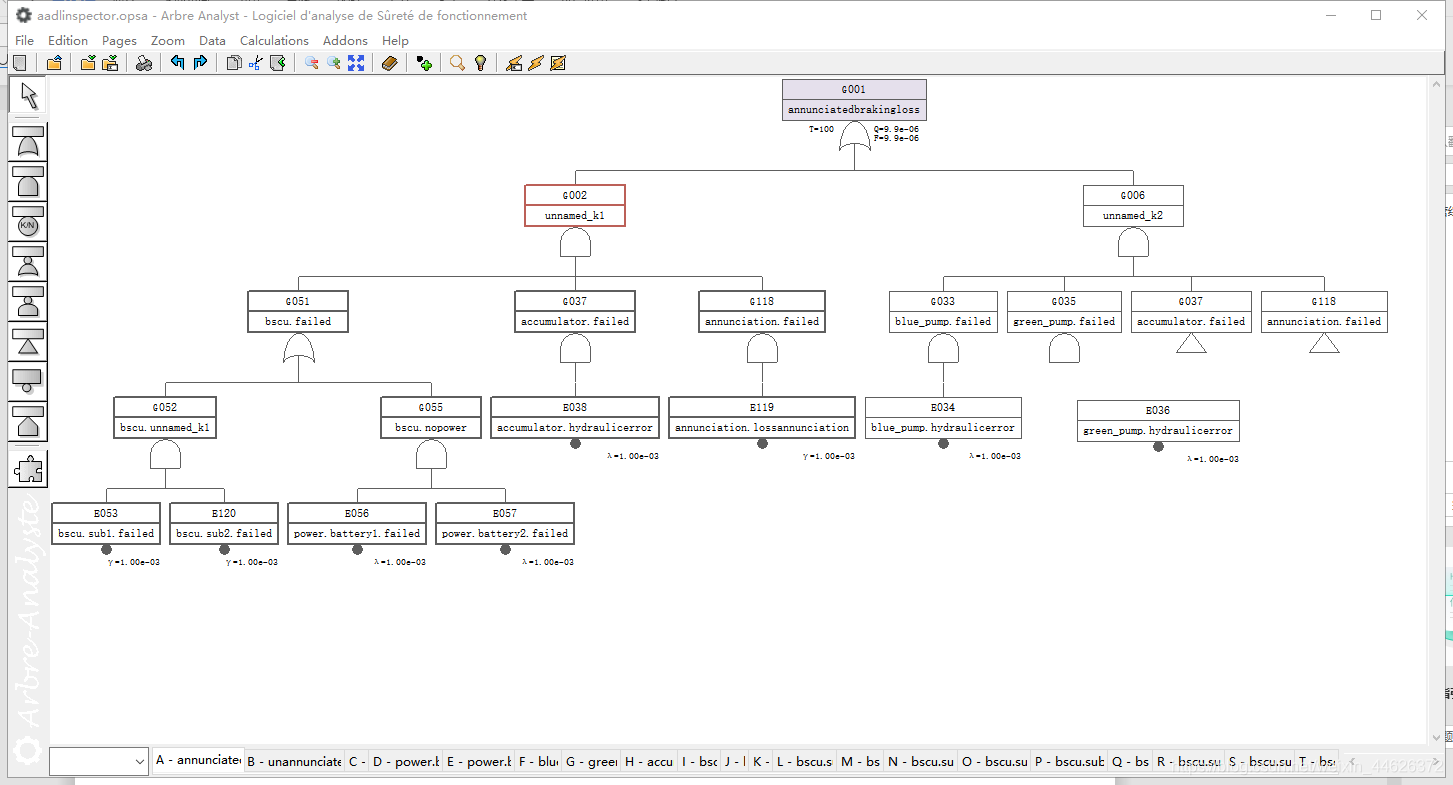
AADL Inspector 故障树安全分析模块
网络原理(1)——基础原理概述

Airiot helps the urban pipe gallery project, and smart IOT guards the lifeline of the city
使用高斯Redis实现二级索引
随机推荐
Implement secondary index with Gaussian redis
Helix QAC 2020.2新版静态测试工具,最大限度扩展了标准合规性的覆盖范围
Data island is the first danger encountered by enterprises in their digital transformation
机械臂速成小指南(十二):逆运动学分析
【Auto.js】自动化脚本
Force buckle 599 Minimum index sum of two lists
4G设备接入EasyGBS平台出现流量消耗异常,是什么原因?
Cantata9.0 | 全 新 功 能
【奖励公示】第22期 2022年6月奖励名单公示:社区明星评选 | 新人奖 | 博客同步 | 推荐奖
2022如何评估与选择低代码开发平台?
[auto.js] automatic script
Force buckle 989 Integer addition in array form
Traversée des procédures stockées Oracle
Nebula importer data import practice
华为CE交换机下载文件FTP步骤
测量楼的高度
OneSpin | 解决IC设计中的硬件木马和安全信任问题
如何满足医疗设备对安全性和保密性的双重需求?
Useful win11 tips
解决/bin/sh进去的容器运行可执行文件报not found的问题