当前位置:网站首页>Update iteration summary of target detection based on deep learning (continuous update ing)
Update iteration summary of target detection based on deep learning (continuous update ing)
2022-07-07 20:18:00 【Breeze_】
RCNN The process of
- Selective Search Do candidate box extraction ,1000~2000 individual
- Candidate box Resize To a fixed size , Input CNN The extracted features
- Feature directly SVM classification , Get the results of classification
- Further adjust the position
SPPNet Innovation of
Combined with the spatial pyramid method CNNs Multi scale input of .
SPP Net My first contribution is After the last convolution layer , Access to the pyramidal pool , Ensure that the input to the next full connection layer is fixed . let me put it another way , In ordinary CNN In Institutions , The size of the input image is often fixed ( such as 224*224 Pixels ), The output is a vector of fixed dimensions .SPP Net In ordinary CNN The structure adds ROI Pooling layer (ROI Pooling), The input image of the network can be any size , The output is the same , It's also a vector of fixed dimensions . in short ,CNN Originally only fixed input 、 Fixed output ,CNN add SSP after , Can then Any input 、 Fixed output .
ROI The pooling layer is generally behind the convolution layer , In this case, the input of the network can be of any scale , stay SPP layer Every one of them pooling Of filter Will adjust the size according to the input , and SPP The output is a vector of fixed dimensions , And then give the full connection FC layer .Only extract convolution features from the original image once .
stay R-CNN in , Each candidate box begins with resize To uniform size , And then as CNN The input of , This is very inefficient .
and SPP Net According to this shortcoming, we have optimized : Only one convolution calculation of the original image , Then we get the convolution feature of the whole graph feature map, Then find each candidate box in feature map Mapping on patch, Put this patch As the convolution feature of each candidate box, input to SPP layer And later layers , Complete feature extraction .such ,R-CNN To compute convolution for each region , and SPPNet You only need to compute convolution once , So it saves a lot of computing time , Than R-CNN It's about a hundred times faster .
Specifically Next :fast rcnn Medium spplayer(ROI Pooling), Finally, the output dimension is consistent because it is a one-dimensional linear direct splicing ( We'll use that later FC);yolov3 And later series spplayer, The dimension consistency after output is due to the pooling process of different core sizes , The step size is used s=1,padding=k//2, Finally get WH_out = k+1 Characteristics of scale . The two have different purposes , The former is to solve Any input fixed output The problem of , The latter is for promotion Small target detection ability Other questions .
Fast RCNN The process of
Selective Search Do candidate box extraction ,1000~2000 individual
Calculate the characteristics of the whole image shared feature map, And put the candidate box (ROI, Region of interest ) Map to the corresponding shared feature map(New)
notes : The mapping rules are simple , It's just dividing the coordinates by “ Enter the picture and feature map The ratio of the size of ”, Got it feature map Upper box coordinate
utilize ROI Pooling Features adjusted to a fixed size (New)
Feed features into CNN Extract new features
The two losses of classification and regression are supervised and trained at the same time ( Full connection )(New)
ROI Pooling operation
According to input image, take ROI Mapping to feature map Corresponding position
Divide the mapped area into the same size sections(sections Quantity is the same dimension as output )
For each sections Conduct max pooling operation , obtain batch×channel×W×H The characteristics of dimensions
Faster RCNN The process of
- Calculate the characteristics of the whole image feature map
- Feed features into RPN The Internet , Return the information of a series of candidate boxes ( The goal is + coordinate ,k Anchor frames ), Here we need to do regression training (New)
- utilize ROI Pooling Features adjusted to a fixed size
- Feed features into CNN(FC) Extract new features
- The two losses of classification and regression are supervised and trained at the same time ( Full connection )
SSD Innovation of
Use VGG16 Network as feature extractor ( and Faster R-CNN Used in CNN equally ), Replace the following full connection layer with convolution layer , And then add a custom volume layer , At last, convolution is directly used for detection .
differ Faster R-CNN Only in the last feature layer anchor, SSD Take... On multiple feature layers default box, You can get different scales default box
Take different aspect ratios on each cell of the feature map default box, Generally, the aspect ratio is {1,2,3,1/2,1/3} Select the , Sometimes an additional aspect ratio is added 1 But with a special scale box
In order to make the positive and negative samples as balanced as possible ( Generally, the proportion of positive and negative samples is about 1:3),SSD use hard negative mining, That is, the negative samples are arranged in descending order according to the confidence of their predicted background class , Choose the one with less confidence top-k As a negative sample of training .
Q1, How to set up default boxes Q2, How to match prior boxes Q3, How to get the predicted results
YOLOv1( Treat the detection task as a regression task )
- Network structure :24 A convolution +2 A full connection ( Image location + Category probability )
- Input :1x3x448x448 Scale image
- Output :7 × 7 × 30 Scale of ,30=20+(4+1)*2,20 Is the number of categories ,4 For position ,1 by score Degree of confidence
- Loss function : It is divided into Coordinate prediction 、 Containing the bounding box of the object confidence forecast ( High weight )、 Without the bounding box of the object confidence forecast ( Less weight )、 Classified forecast Four parts , It uses L2 Loss
YOLOv2 Of Innovation points
- DarkNet As a backbone
- introduce Anchor Mechanism , Avoided YOLOv1 The problem of information loss caused by direct regression results of medium and full connections , Use K-means clustering
- introduce BathNormalization, Play a certain role in improving the convergence speed of the model , Prevent model over fitting
- Use high-resolution network input
- Use anchor The position of the prediction target is directly regressed by the coordinate center and the offset
- reference SSD Use multi-scale feature map to do detection
- Multiscale training , The prediction effect of large scale is good
- Remove the last convolution 、global avgpooling Layers and softmax layer , And added three 3 × 3 × 2014 3\times 3 \times 2014 3×3×2014 Convolution layer , I've added one passthrough layer , Finally using 1 × 1 1\times 1 1×1 The convolution layer outputs the prediction results
YOLOv3 Of Innovation points
- Use the new backbone Darknet-53( Introduce residual block ,53 Convolution layers )
- Use FPN Do multi-scale prediction
- Use logical return instead of Softmax Be a classifier
YOLOv4 Of Innovation points
- Input end : New data enhancements such as CutMix and Mosaic
- Backbone network :CSPDarkNet-53,Mish Activation function ,DroupBlock
- Neck network : Space Pyramid pooling SPP, Path aggregation PAN, Characteristic pyramid network FPN
- Head network :CIoU Loss ,DIoU_NMS
RetinaNet Of innovation spot :
The author of One-stage A series of algorithms are studied and the class imbalance problem is found , It is suggested that Focal Loss, It is an improvement of the loss function ,one-stage combination Focal Loss The combined network is RetinaNet
What is category imbalance (class imbalance)?
answer : The number of negative samples is greater than the number of positive samples , For example, the area containing objects ( Positive sample ) Very few , Areas that do not contain objects ( Negative sample ) quite a lot . For example, the detection algorithm will generate a large wave in the early stage bbox. And in a regular picture , Just a few at most object. It means , Most of bbox Belong to background. Simply speaking , because bbox Quantity explosion . Precisely because bbox Of background Of bbox That's too much , So if the classifier mindlessly puts all bbox Uniformly classified as background,accuracy You can also brush it very high . So , The training of classifier fails . Classifier training failed , The detection accuracy is naturally low .
Focal Loss The definition of , Introduced modulating factor namely ( 1 − p t ) γ (1-p_t)^\gamma (1−pt)γ, p t p_t pt It reflects the difficulty of classification
F L ( p t ) = − ( 1 − p t ) γ log ( p t ) FL(p_t) = -(1-p_t)^\gamma \log(p_t) FL(pt)=−(1−pt)γlog(pt)
- RetinaNet = ResNet + FPN + Two sub-networks + Focal Loss
边栏推荐
- Force buckle 599 Minimum index sum of two lists
- 力扣 1232.缀点成线
- Read PG in data warehouse in one article_ stat
- Micro service remote debug, nocalhost + rainbow micro service development second bullet
- Cloud 组件发展升级
- 【mysql篇-基础篇】事务
- Some important knowledge of MySQL
- 【解决】package ‘xxxx‘ is not in GOROOT
- Opencv learning notes high dynamic range (HDR) imaging
- 深度学习模型压缩与加速技术(七):混合方式
猜你喜欢
力扣 2319. 判断矩阵是否是一个 X 矩阵
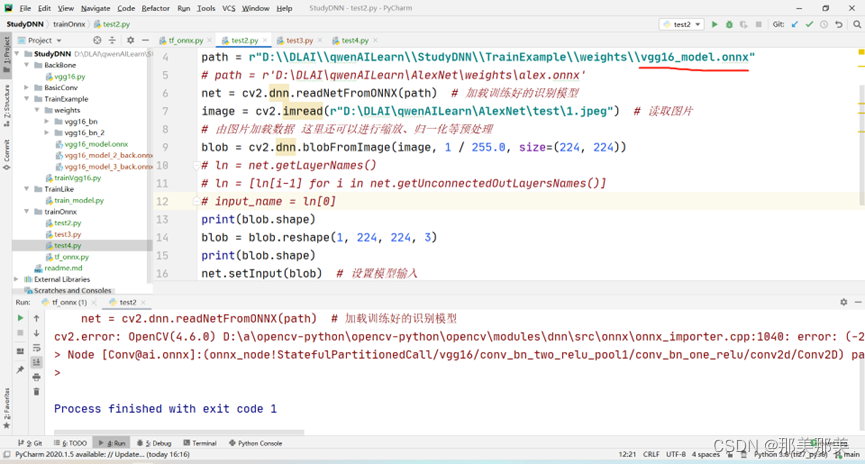
关于cv2.dnn.readNetFromONNX(path)就报ERROR during processing node with 3 inputs and 1 outputs的解决过程【独家发布】

Some important knowledge of MySQL

Mongodb由浅入深学习
Force buckle 599 Minimum index sum of two lists

AIRIOT助力城市管廊工程,智慧物联守护城市生命线
一键部署Redis任意版本
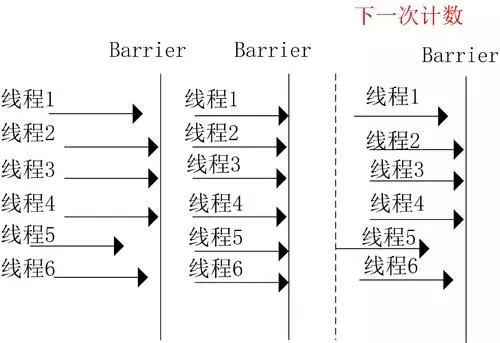
How to cooperate among multiple threads
数据孤岛是企业数字化转型遇到的第一道险关

九章云极DataCanvas公司摘获「第五届数字金融创新大赛」最高荣誉!
随机推荐
【解决】package ‘xxxx‘ is not in GOROOT
【论文阅读】MAPS: Multi-agent Reinforcement Learning-based Portfolio Management System
Micro service remote debug, nocalhost + rainbow micro service development second bullet
Force buckle 2315 Statistical asterisk
Version selection of boot and cloud
About cv2 dnn. Readnetfromonnx (path) reports error during processing node with 3 inputs and 1 outputs [exclusive release]
Graduation season | regretful and lucky graduation season
2022如何评估与选择低代码开发平台?
Precautions for cjson memory leakage
How to implement safety practice in software development stage
Chapter 9 Yunji datacanvas company won the highest honor of the "fifth digital finance innovation competition"!
力扣 989. 数组形式的整数加法
php 获取图片信息的方法
Mongodb由浅入深学习
PHP method of obtaining image information
pom.xml 配置文件标签:dependencies 和 dependencyManagement 区别
School 1 of vulnhub
Machine learning notes - explore object detection datasets using streamlit
第二十章 使用工作队列管理器(三)
How to cooperate among multiple threads