Abstract : gaussian Redis Build secondary index of business , Low cost , High performance , Achieve win-win performance and cost .
This article is shared from Huawei cloud community 《 Hua Wei Yun GaussDB(for Redis) Uncover secrets 21 period : Use Gauss Redis Implement secondary index 》, author : gaussian Redis The official blog .
One 、 background
Bring up the index , The first impression is the noun of database , however , gaussian Redis You can also implement secondary indexing !!! gaussian Redis The secondary index in generally uses zset To achieve . gaussian Redis Compared to open source Redis It has higher stability 、 And cost advantage , Use Gauss Redis zset Realize the secondary index of business , You can get a win-win situation of performance and cost .
The essence of index is to use ordered structure to speed up query , So by Zset Structural Gauss Redis It can easily realize the index of numeric type and character type .
• Numeric type index (zset Sort by score ):
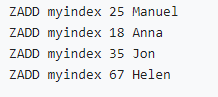
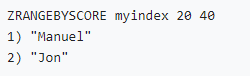
• Character type index ( When the scores are the same zset Sort by dictionary order ):

Let's cut into two classic business scenarios , See how to use Gauss Redis To build a stable and reliable secondary index system .
Two 、 Scene one : Complete the dictionary
When typing a query in the browser , Browsers usually recommend searches with the same prefix according to the possibility , This kind of scene can use Gauss Redis The secondary index function is realized .
2.1 Basic plan
The easiest way is to add each query of the user to the index . When user input completion recommendation is required , Use ZRANGEBYLEX Just execute the range query . If you don't want to return too many entries , gaussian Redis Also supports the use of LIMIT Options to reduce the number of results .
• Search the user banana Add to index :
ZADD myindex 0 banana:1
• Suppose the user enters “bit”, And we want to offer the possibility to “bit” Search keywords at the beginning .
ZRANGEBYLEX myindex "[bit" "[bit\xff"
That is to use ZRANGEBYLEX Make a range query , The query range is the string that the user is now entering , And the same string plus a trailing byte 255(\xff). In this way , We can get all strings prefixed with the string typed by the user .
2.2 Frequency related dictionary completion
In practical applications, we usually want to automatically sort and complete the entries according to the frequency of occurrence , At the same time, it can eliminate the entries that are no longer popular , And automatically adapt to future input . We can still use Gauss Redis Of ZSet Structure to achieve this goal , Just in the index structure , Not only do you need to store search terms , You also need to store the frequency associated with it .
• Search the user banana Add to index
• Judge banana Whether there is
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1
• hypothesis banana non-existent , add to banana:1, among 1 It's the frequency
ZADD myindex 0 banana:1
• hypothesis banana There is , You need to increase the frequency
if ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1 The frequency returned in is 1
1) Delete old entries :
ZREM myindex 0 banana:1
2) Add one frequency to rejoin :
ZADD myindex 0 banana:2
Please note that , Because there may be concurrent updates , Therefore, it should pass Lua The script sends the above three commands , use Lua script Automatically get the old count and add the entry again after increasing the score .
• Suppose the user enters “banana”, And we want to provide similar search keywords . adopt ZRANGEBYLEX The results are sorted by frequency .
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 10 1) "banana:123" 2) "banaooo:1" 3) "banned user:49" 4) "banning:89"
• Use streaming algorithm to clear infrequent input . Select an entry randomly from the returned entries , Subtract its score 1, Then add it again with the new score . however , If the new score is 0, We need to delete this entry from the list .
• If the frequency of randomly selected items is 1, Such as banaooo:1
ZREM myindex 0 banaooo:1
• If the frequency of randomly selected items is greater than 1, Such as banana:123
ZREM myindex 0 banana:123 ZADD myindex 0 banana:122
In the long run , The index will contain popular searches , If popular searches change over time , It will also automatically adapt .
3、 ... and 、 Scene two : Multidimensional index
Except for queries on a single dimension , gaussian Redis It also supports retrieval in multidimensional data . for example , Retrieve all ages at 50 to 55 Between the ages of , At the same time, the salary is 70000 to 85000 Between people . The key to realize multi-dimensional secondary index is to convert two-dimensional data into one-dimensional data through coding , Then based on Gauss Redis zset Storage .
Represent two-dimensional indexes from a visual perspective . There are some points in the space below , They represent our data samples , among x and y It's two variables , The maximum values are 400. The blue box in the picture represents our query . We hope to inquire x Be situated between 50 and 100 Between ,y Be situated between 100 and 300 All points between .
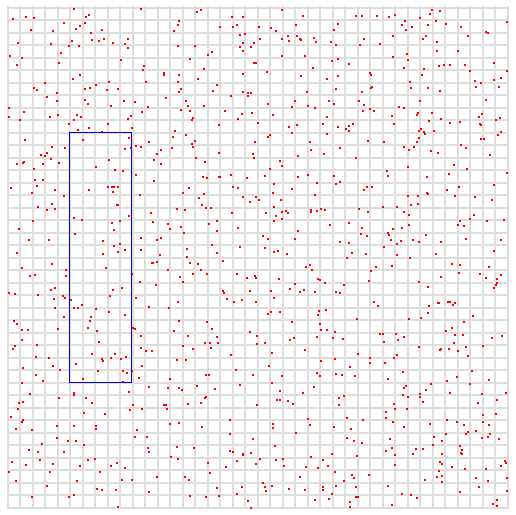
3.1 Data encoding
If the inserted data point is x = 75 and y = 200
1) fill 0( Data maximum is 400, So fill 3 position )
x = 075
y = 200
2) Interleave numbers , With x Represents the leftmost number , With y Represents the leftmost number , And so on , To create a code
027050
If you use 00 and 99 Replace the last two , namely 027000 to 027099,map return x and y, namely :
x = 70-79
y = 200-209
therefore , in the light of x=70-79 and y = 200-209 Two dimensional query , It can be encoded map become 027000 to 027099 One dimensional query , This can be achieved by Gauss Redis Of Zset The structure is easy to realize .
Empathy , We can aim at the last four / 6、 ... and /etc Perform the same operation with digits , So as to obtain a larger range .
3) Use binary
To obtain finer granularity , Data can be represented in binary , So when replacing numbers , Each time, you will get twice the original search scope . Suppose we only need 9 position ( To indicate at most 400 A number of values ), Our number in binary form will be :
x = 75 -> 001001011
y = 200 -> 011001000
After interweaving ,000111000011001010
Let's look at the use of 0s ad 1s Replace the last 2、4、6、8,... What is our range of bits :

3.2 Add a new element
If the inserted data point is x = 75 and y = 200
x = 75 and y = 200 Binary interleaved code is 000111000011001010,
ZADD myindex 0 000111000011001010
3.3 Inquire about
Inquire about :x Be situated between 50 and 100 Between ,y Be situated between 100 and 300 All points between
Replace from index N Bit will give us a side length of 2^(N/2) Search box . therefore , What we need to do is to check the smaller size of the search box , And check the closest 2 The power of , And constantly divide the remaining space , Then use ZRANGEBYLEX To search .
Here is the sample code :
def spacequery(x0,y0,x1,y1,exp) bits=exp*2 x_start = x0/(2**exp) x_end = x1/(2**exp) y_start = y0/(2**exp) y_end = y1/(2**exp) (x_start..x_end).each{|x| (y_start..y_end).each{|y| x_range_start = x*(2**exp) x_range_end = x_range_start | ((2**exp)-1) y_range_start = y*(2**exp) y_range_end = y_range_start | ((2**exp)-1) puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}" # Turn it into interleaved form for ZRANGEBYLEX query. # We assume we need 9 bits for each integer, so the final # interleaved representation will be 18 bits. xbin = x_range_start.to_s(2).rjust(9,'0') ybin = y_range_start.to_s(2).rjust(9,'0') s = xbin.split("").zip(ybin.split("")).flatten.compact.join("") # Now that we have the start of the range, calculate the end # by replacing the specified number of bits from 0 to 1. e = s[0..-(bits+1)]+("1"*bits) puts "ZRANGEBYLEX myindex [#{s} [#{e}" } } end spacequery(50,100,100,300,6)
Four 、 summary
This paper introduces how to pass Gauss Redis Build a secondary index , The secondary index is in e-commerce 、 chart (hexastore)、 Games and other fields have a wide range of application scenarios , gaussian redis There are many similar applications in Xianwang . gaussian Redis Based on the architecture of separation of storage and calculation , Rely on distributed storage pool to ensure strong data consistency , It can easily support the secondary index function , Provide stable and reliable services for enterprise customers 、 Super high concurrency , Core data storage services that can be rapidly and elastically expanded .
appendix
- The author of this article : Huawei cloud database GaussDB(for Redis) The team
- Hangzhou / Xi'an / Shenzhen resume delivery :[email protected]
- More product information , Welcome to the official blog :bbs.huaweicloud.com/blogs/248875
Click to follow , The first time to learn about Huawei's new cloud technology ~