当前位置:网站首页>pytorch applied to MNIST handwritten font recognition
pytorch applied to MNIST handwritten font recognition
2022-08-04 02:10:00 【windawdaysss】
前言
手写字体MNIST数据集是一组常见的图像,It is often used to evaluate and compare the performance of machine learning algorithms,本文使用pytorchframework to realize the recognition of this dataset,and optimize the results step by step.
一、数据集
MNIST数据集是由28x28大小的0-255A grayscale image of a range of pixel values(如下图所示),其中610,000 sheets are used to train the model,110,000 sheets are used to test the model.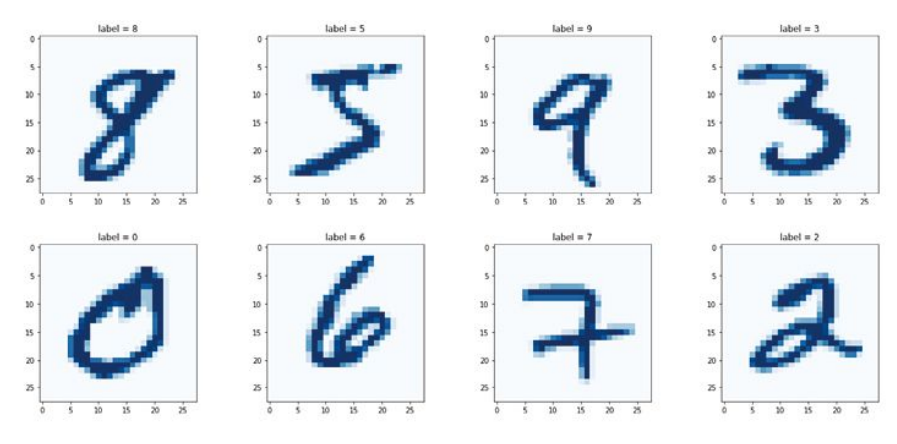
The dataset is available from the link below:
训练数据集:
https://pjreddie.com/media/files/mnist_train.csv
测试数据集:
https://pjreddie.com/media/files/mnist_test.csv
The dataset has one row785个值,The first value is the numeric label in the image,其余784value is the pixel value of the image.
The example code for reading data is as follows:
import pandas
import matplotlib.pyplot as plt
df = pandas.read_csv(r'./data/mnist_train.csv', header=None)
# print(df.head()) # 显示前5行
# print(df.info()) # 显示DataFrame概况
row = 0
data = df.iloc[row]
label = data[0],
img = data[1:].values.reshape(28, 28)
plt.title('label = ' + str(label))
plt.imshow(img, interpolation='none', cmap='Blues')
plt.show()
二、建立模型
# 构建模型
import torch
import torch.nn as nn
from torch.utils.data import Dataset
class Classifier(nn.Module):
def __init__(self):
# 初始化pytorch父类
super().__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.Sigmoid(),
nn.Linear(200, 10),
nn.Sigmoid()
)
self.loss_function = nn.MSELoss()
self.optimizer = torch.optim.SGD(self.parameters(), lr=0.01)
self.counter = 0
self.progress = []
def forward(self, inputs):
return self.model(inputs)
def train_model(self, inputs, targets):
outputs = self.forward(inputs)
loss = self.loss_function(outputs, targets)
self.optimizer.zero_grad() # 梯度归零 ,Because the gradients computed by backpropagation accumulate
loss.backward() # 反向传播
self.optimizer.step() # 更新权重
# 可视化训练过程
self.counter += 1
if self.counter % 10 == 0:
self.progress.append(loss.item()) # Get the numbers in a single tensor
pass
if self.counter % 10000 == 0:
print('counter = ', self.counter)
pass
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16, 8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
plt.show()
pass
class MnistDataset(Dataset):
def __init__(self, csv_file):
self.data_df = pandas.read_csv(csv_file, header=None)
pass
def __len__(self):
return len(self.data_df)
def __getitem__(self, index):
label = self.data_df.iloc[index, 0]
target = torch.zeros((10))
target[label] = 1
image_value = torch.FloatTensor(self.data_df.iloc[index, 1:].values) / 255.0
return label, image_value, target
def plot_image(self, index):
arr = self.data_df.iloc[index, 1:].values.reshape(28, 28)
plt.title('label = ' + str(self.data_df.iloc[index, 0]))
plt.imshow(arr, interpolation='none', cmap='Blues')
plt.show()
pass
pass
The model framework is established above,并对训练过程进行可视化,Create a read data class.
三、训练分类模型
mnist_train_dataset = MnistDataset(r'./data/mnist_train.csv')
# mnist_dataset.plot_image(9)
# 训练分类模型
start_time = time.time()
C = Classifier()
epochs = 3 # 训练3轮
for i in range(epochs):
print('training epoch ', i+1, 'of', epochs)
for lable, image_tensor, target_tensor in mnist_train_dataset:
C.train_model(image_tensor, target_tensor)
pass
pass
C.plot_process()
print('run time = ', (time.time()-start_time) / 60)
训练3The round takes about less than approx3min,效率还不错
四、测试模型
# 测试模型
mnist_test_dataset = MnistDataset(r'./data/mnist_test.csv')
record = 19
mnist_test_dataset.plot_image(record) # numbers in the image
image_data = mnist_test_dataset[record][1]
output = C.forward(image_data)
pandas.DataFrame(output.detach().numpy()).plot(kind='bar', legend=False, ylim=(0, 1)) # 预测的数字
plt.show()
score = 0
items = 0
for label, img_tensor, label_tensor in mnist_test_dataset:
ans = C.forward(img_tensor)
if ans.argmax() == label:
score += 1
pass
items += 1
pass
print(score, items, score / items)
The test score of the model is 87%,考虑到这是一个简单的网络,This score is not too bad.
五、模型优化
The optimization of the model mainly starts from four aspects:
- 1、损失函数
The design loss function in the above model is MSEloss,Here it is changed to binary cross-entropy loss((binary cross entropy loss)
self.loss_function = nn.BCELoss()
训练3轮,Find the score by87%提升到91%了
- 2、激活函数
SigmoidOne disadvantage of activation functions is that,when the input value becomes larger,梯度会变得非常小甚至消失.Now commonly used is the improved linear rectification functionLeaky ReLU,Also called a leaky linear rectifier function.
self.model = nn.Sequential(
nn.Linear(784, 200),
# nn.Sigmoid(),
nn.LeakyReLU(0.02),
nn.Linear(200, 10),
# nn.Sigmoid()
nn.LeakyReLU(0.02)
)
The loss function is the originalMSEloss,训练3轮,分数由87%上升到97%,这是一个很大的提升.
- 3 、优化器
The above model uses the gradient descent method,A disadvantage of this method is that it gets stuck in local minima of the loss function,Another disadvantage is using the same learning rate for all learnable parameters.Common alternatives are Adam,It uses momentum to reduce the possibility of getting stuck in a local minimum,Additionally it uses a separate learning rate for each learnable parameter,这些学习率随着每个参数在训练期间的变化而变化.
self.optimizer = torch.optim.Adam(self.parameters())
Changing only the optimizer discovery model achieves the same effect as changing the activation function,分数由87%提升到97%.
- 4、标准化
Normalization refers to reducing the range of parameters and signals in the network,将均值转换为0,A common practice is to normalize the signal before feeding it into the neural network.
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.Sigmoid(),
# nn.LeakyReLU(0.02),
nn.LayerNorm(200), # 标准化
nn.Linear(200, 10),
nn.Sigmoid()
# nn.LeakyReLU(0.02)
)
Add normalization to the network,模型的分数87%提升到91%
Combine all of the above methods,Since the binary cross-entropy function can only handle 0~1的值,而LeakyReLUOut-of-range values may be output,Leave the activation function of the latter layer as the originalSigmoid函数:
self.model = nn.Sequential(
nn.Linear(784, 200),
# nn.Sigmoid(),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200, 10),
nn.Sigmoid()
# nn.LeakyReLU(0.02)
)
3After cycle training,模型的分数为97%,The integrated optimization scheme cannot make the model score greater than 97%.
END
参考资料
-[英]塔里克•拉希德(Tariq Rashid)著,Translated by Han Jianglei. PyTorch生成对抗网络编程. 人民邮电出版社
边栏推荐
猜你喜欢

Continuing to invest in product research and development, Dingdong Maicai wins in supply chain investment
halcon自定义函数基本操作
activiti流程执行过程中,数据库表的使用关系

出海季,互联网出海锦囊之本地化
实例039:有序列表插入元素
SAP SD模块前台操作
持续投入商品研发,叮咚买菜赢在了供应链投入上
Continuing to invest in product research and development, Dingdong Maicai wins in supply chain investment
Web APIs BOM- 操作浏览器:swiper 插件
C程序编译和预定义详解
随机推荐
TensoFlow学习记录(二):基础操作
持续投入商品研发,叮咚买菜赢在了供应链投入上
Example: 036 is a prime number
共n级台阶,每次可以上1级或2级台阶,有多少种上法?
Priority_queue element as a pointer, the overloaded operators
halcon自定义函数基本操作
关联接口测试
Flutter3.0线程——四步教你如何全方位了解(事件队列)
2022.8.3-----leetcode.899
工程制图平面投影练习
企业虚拟偶像产生了实质性的价值效益
Web APIs BOM - operating browser: swiper plug-in
ant-design的Select组件采用自定义后缀图标(suffixIcon属性)时,点击该自定义图标没有反应,不会展示下拉菜单的问题
Example 039: Inserting elements into an ordered list
计算首屏时间
initramfs详解----添加硬盘驱动并访问磁盘
flask框架初学-06-对数据库的增删改查
Use of lombok annotation @RequiredArgsConstructor
董明珠直播时冷脸离场,员工频犯低级错误,自家产品没人能弄明白
持续投入商品研发,叮咚买菜赢在了供应链投入上