当前位置:网站首页>What is fake sharing after filling the previous hole?
What is fake sharing after filling the previous hole?
2022-07-07 22:53:00 【Yes' level training strategy】
Hello everyone , I am a yes.
I was writing before FastThreadLocal When , Dug a hole .

Cough , It's been a long time , But the impact is not great. I'll make up for it today .
Let's talk about what is pseudo sharing , And why Netty To remove this optimization here ?
Don't talk much , Start !
What is pseudo sharing ?
This noun sounds a bit advanced , Actually, it's easy to understand .
We all know CPU The execution speed of is much faster than the speed of getting data from memory , In order to reduce this gap, researchers continue to study , Output cache , But this cache is due to process integration , Media that cannot be used as main memory , So common CPU The cache structure is shown in the following figure :
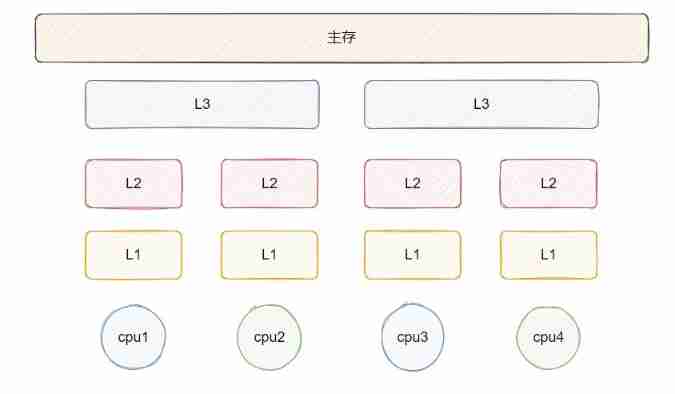
L1、L2、L3 Then for CPU And main memory , distance CPU The closer the cache access is, the faster , And the smaller the capacity .
For example, my notebook CPU On :
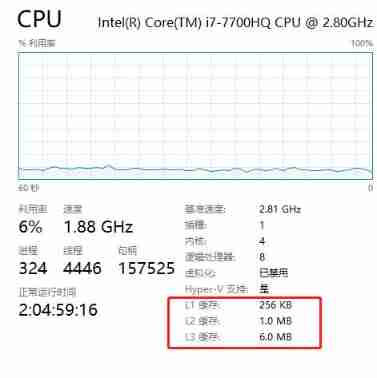
Access speed :L1>L2>L3> Main memory .
L1 and L2 It's a single core CPU Exclusive , When CPU When accessing data, you will go first L1 Look up , I can't find it L2, And then there was L3, Finally, main memory . So when calculating a data repeatedly , Try to ensure that the data is L1 in , This is efficient .
From the structure above , Experienced students will certainly find that the above structure has the problem of shared memory multithreading . Here we introduce the consistency protocol MESI. The specific contents of the agreement are not expanded here , Here is a simple example to understand :
When cpu1 and cpu3 When jointly accessing a data in main memory , Will be obtained and placed in their own cache , When cpu1 After modifying this data ,cpu3 The data in the cache of is invalid , It will make cpu1 Refresh this change to main memory , Then load the data in the main memory , Only in this way can the data be correct .
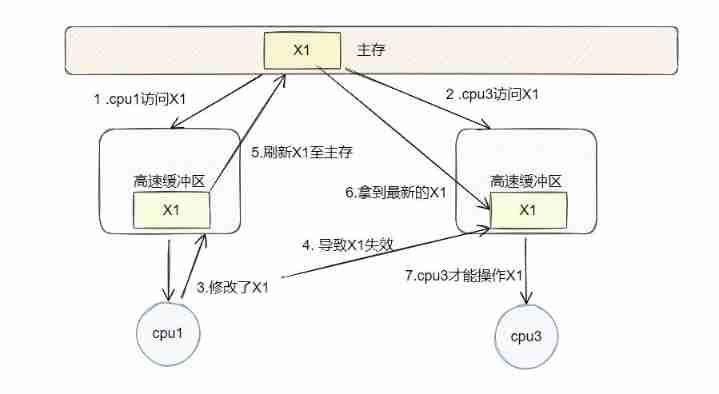
Read the figure in sequence , It shouldn't be hard to understand .
Then came the point ,CPU The unit of cache is cache row , in other words CPU Getting data from main memory is not one by one , Take it line by line , The size of this line is generally 64 byte , That's the question .
such as , Now there's a long Array , The size is 8 , Then this array just meets the size of one row . Now? cpu1 Update frequently long[0] Value , and cpu3 Update frequently long[5] Value , This is a little numb .
Due to the mechanism of caching rows , Every time cpu1 The entire array will be loaded into the cache , Only modify each time long[0] It will also make this industry dirty , here cpu3 Access to the long[5] Is failure , therefore cpu3 Need make cpu1 Refresh the changes to main memory , Then it retrieves it from main memory long[5] Do it again , Suppose this time cpu1 Change again long[0], Then the above operation has to be done again !
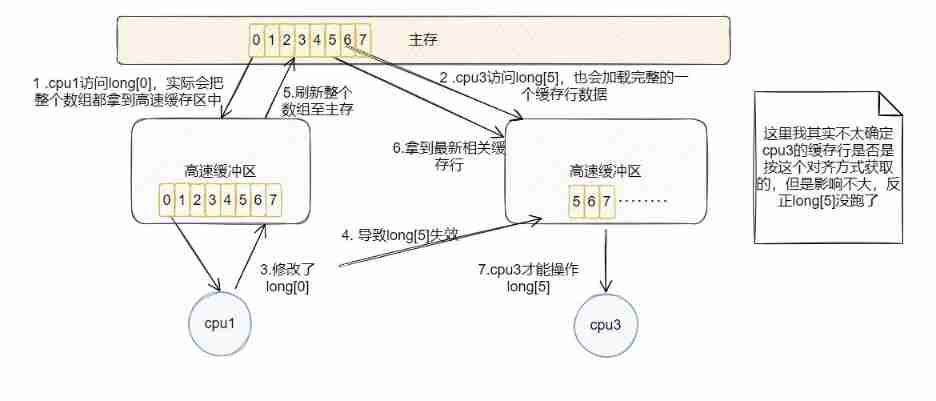
It is different variables that are obviously modified , But they affect each other , This situation , It's called , False sharing !
How to avoid pseudo sharing ?
The solution is very simple and crude , fill .
Separate the data that may conflict in memory , What kind of partition ? Separate with useless data .
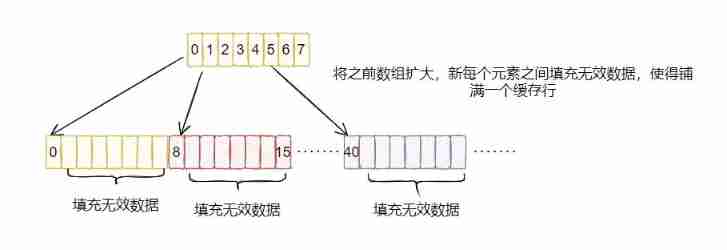
Before and after the key data ( The above figure is only filled in after ) Fill in useless data , Let a cache line , Only one valid data will exist , Others are invalid data , This avoids multiple valid data in one cache line . In this way, it's different CPU If the core modifies different data, it will not cause other data caches to fail , Avoid the problem of pseudo sharing .
therefore Netty in InternalThreadLocalMap This is what the strange code in .

But with all due respect , Maybe I'm too low , I don't see which variable this thing is filled for .
Sure enough , In the latest version, a boss labeled it obsolete

I started from github I looked up , The reason why the boss abandoned it is as follows :
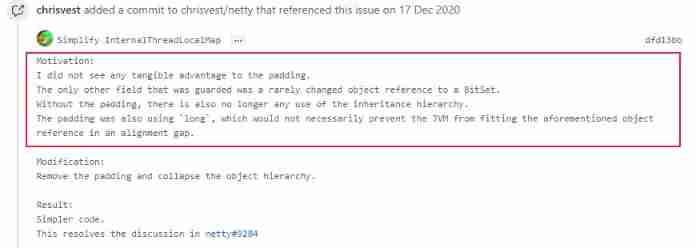
Simple and straightforward translation :
- I don't see any real benefits of filling .
- The only protected object may be BitSet, But it is not frequently modified
- Filling used long, This does not necessarily stop JVM Match the above object reference in the alignment gap .
In short, I didn't find any good use of this filling , So it was scrapped , Future versions will crack it .
So get Netty To show examples of pseudo sharing is no good ( I just wrote before FastThreadLocal The pit is filled ).
Now I'm finished , Let's take another good example .
Run and see with code
I wrote an example , Let's look at the real gap between filling and not filling .
I use two threads to cycle 50 million times to modify two variables in an object a and b, The probability of these two variables will be in the same cache line , This creates a pseudo shared scene .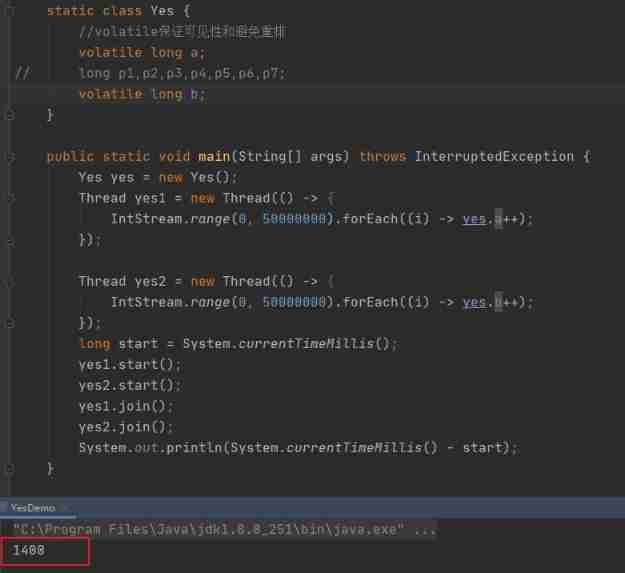
In the case of unfilled , The number of milliseconds taken is 1400.
Then we use variables p1-p7 Fill it in , separate a and b.
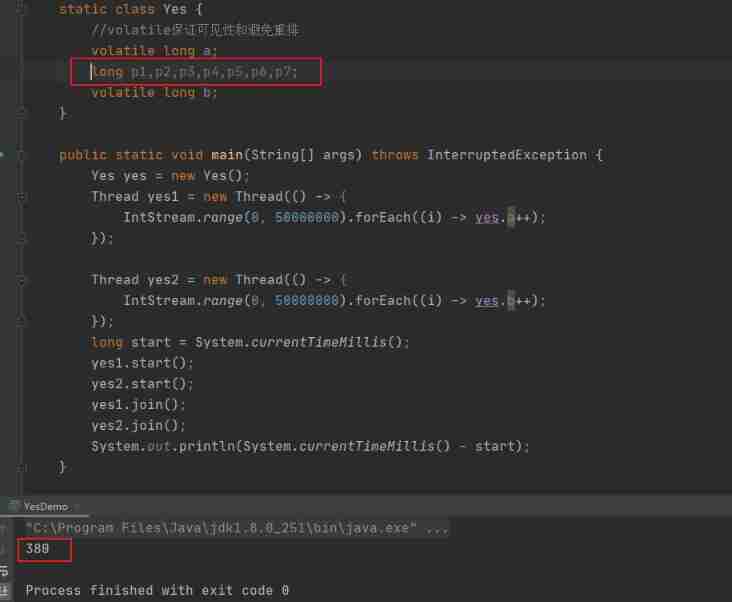
You can see , It turned out to be 380 millisecond , Look at this , It does work ! It indicates that filling is indeed effective !
Actually Java Provides an annotation @Contended, It can be marked on the specified field , Reduce the occurrence of pseudo sharing , You can think that this annotation will make JVM Automatically help us fill in , Variables that do not need to be filled in by hand . But pay attention to , This annotation needs to be added at startup -XX:-RestrictContended Parameters , Will take effect .

Let's run and see the result :
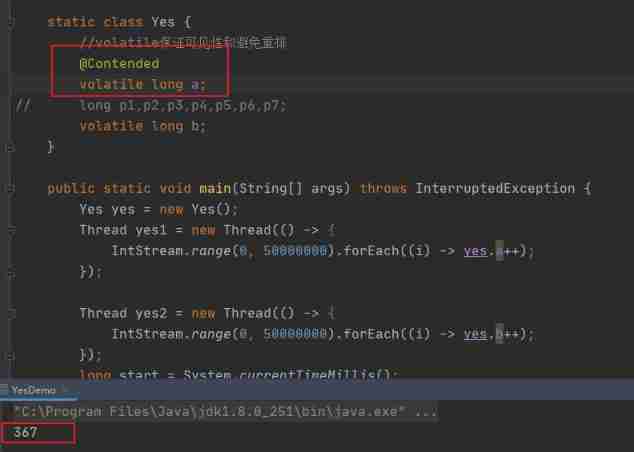
Sure enough , It also improves efficiency !
This annotation can also be used in other places , such as ConcurrentHashMap Inside CounterCell

also Striped64 Inside Cell
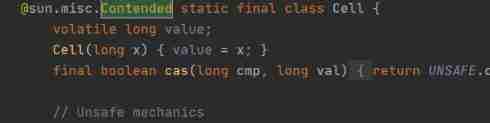
But be careful , No, -XX:-RestrictContended It won't work !
Last
thus , You must have understood what pseudo sharing is , And filling can be used to avoid the problem of pseudo sharing .
But filling represents a waste of space , It is not necessary to fill in any case .
Only when the adjacent fields are updated frequently , It is possible to consider pseudo sharing , Don't worry about other situations .
Okay , That's it today .
I am a yes, From a little bit to a billion , See you next time !
边栏推荐
- Basic knowledge of linked list
- Class implementation of linear stack and linear queue (another binary tree pointer version)
- Sword finger offer 55 - I. depth of binary tree
- 行测-图形推理-6-相似图形类
- Form组件常用校验规则-2(持续更新中~)
- What does it mean to prefix a string with F?
- Pyqt GUI interface and logic separation
- Amesim2016 and matlab2017b joint simulation environment construction
- vite Unrestricted file system access to
- Micro service remote debug, nocalhost + rainbow micro service development second bullet
猜你喜欢
Ueeditor custom display insert code
苹果在iOS 16中通过'虚拟卡'安全功能进一步进军金融领域
UWA Q & a collection
vite Unrestricted file system access to
Ligne - raisonnement graphique - 4 - classe de lettres
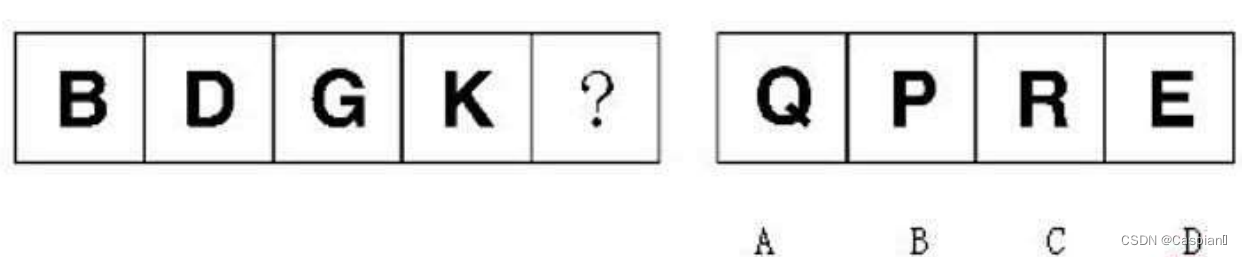
行测-图形推理-4-字母类

Line test - graphic reasoning -5- one stroke class
![LeetCode206. Reverse linked list [double pointer and recursion]](/img/3c/84351e771ac9763c1e5f7b4921c099.jpg)
LeetCode206. Reverse linked list [double pointer and recursion]
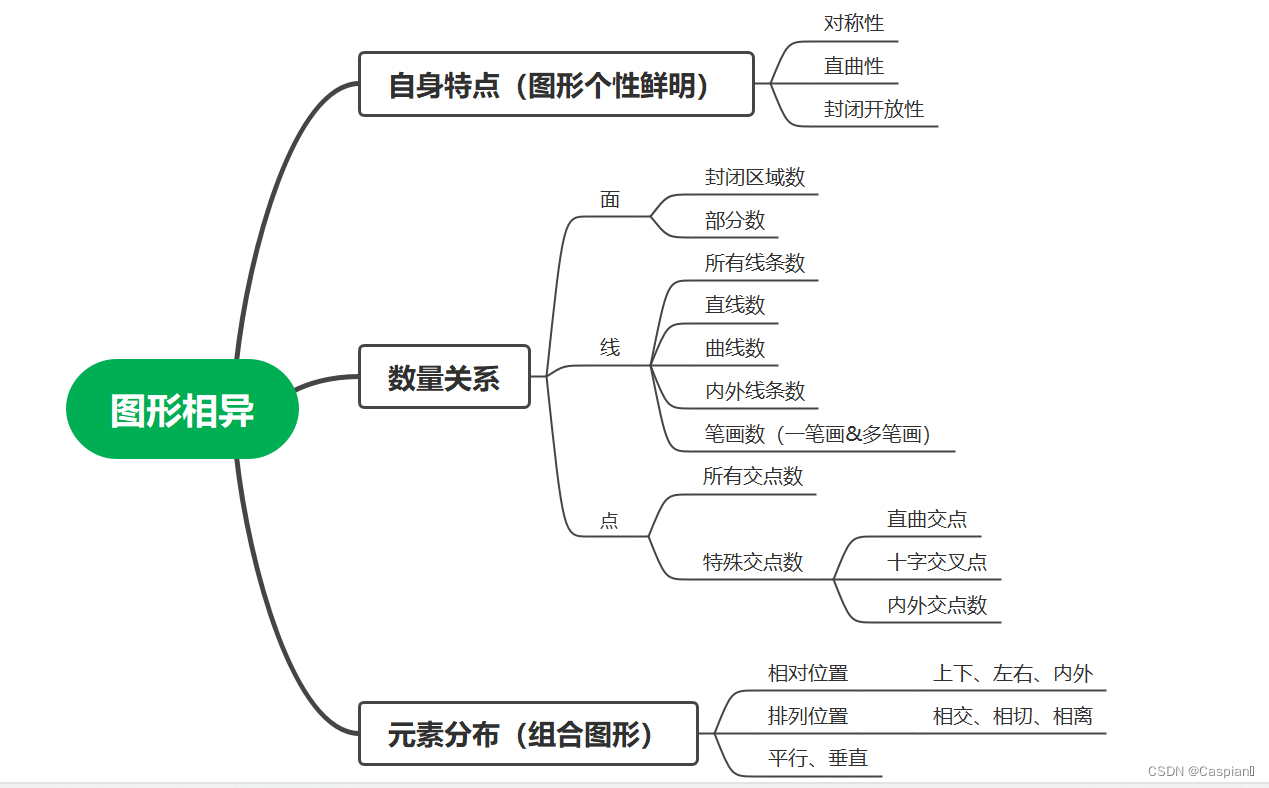
行测-图形推理-7-相异图形类
Loki, the "open source star picking program", realizes the efficient management of harbor logs
随机推荐
How to choose the appropriate automated testing tools?
Line test - graphic reasoning -7- different graphic classes
Debezium系列之:源码阅读之BinlogReader
Basic knowledge of binary tree
ASP. Net core introduction V
Add get disabled for RC form
Debezium series: support the use of variables in the Kill Command
Line test - graphic reasoning - 2 - black and white lattice class
XMIND mind mapping software sharing
Yarn开启ACL用户认证之后无法查看Yarn历史任务日志解决办法
Unity development --- the mouse controls the camera to move, rotate and zoom
Line test - graphic reasoning - 3 - symmetric graphic class
Remember that a development is encountered in the pit of origin string sorting
IP network active evaluation system -- x-vision
0-5vac to 4-20mA AC current isolated transmitter / conversion module
CTF练习
Revit secondary development - intercept project error / warning pop-up
行测-图形推理-4-字母类
面试百问:如何测试App性能?
Debezium系列之:支持 mysql8 的 set role 語句