当前位置:网站首页>10 distributed databases that take you to the galaxy
10 distributed databases that take you to the galaxy
2022-07-07 05:11:00 【Heapdump performance community】
Hello everyone , I'm Wukong .
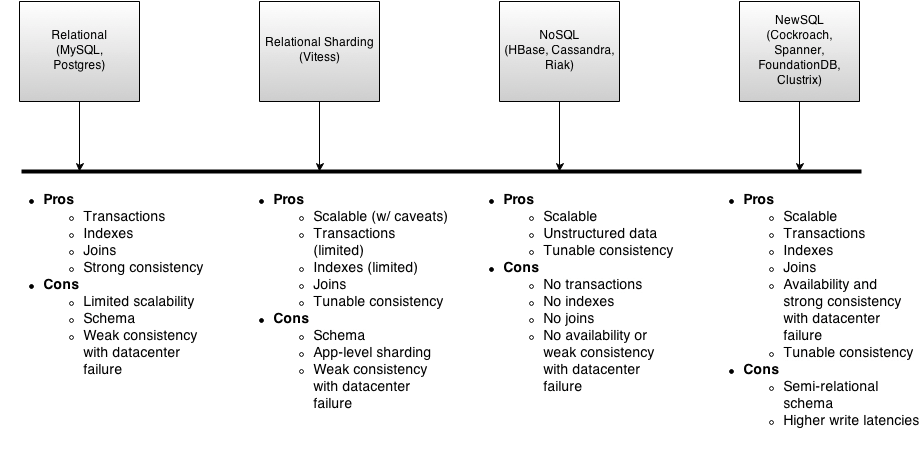
This time, let's talk about databases in distributed scenarios . First of all, let's take a look at the differences and characteristics between relational and non relational databases .
One 、 Relational type vs Non relational
1.1 Relational type
1.1.1 What is relational ?
Relational databases refer to the use of relational models ( Two dimensional table model ) To organize a database of data , A data organization consisting of two-dimensional tables and their connections .
1.1.2 Common relational databases
Common relational database management system (ORDBMS):Oracle、MySql、Microsoft SQL Server、SQLite、PostgreSQ、IBM DB2.
1.1.3 The advantage of relational
Using two-dimensional table structure is very close to the normal development logic .
Universal support SQL( Structured query language ) sentence .
Rich integrity greatly reduces the problem of data redundancy and data inconsistency .
It can be used SQL It's a very complicated query between multiple tables ;
Relational databases provide support for transactions .
1.1.4 The disadvantages of relational type
(1) It stores row records .
Can't store array 、 Data in nested fields and other formats .
(2) It is inconvenient to extend the table structure .
An error will be reported if the operation does not exist , Adding columns requires execution SQL Statement . And you need to pay special attention to it , Because the table will be locked for a long time when it is updated , This can have a serious impact on the online environment .
(3) It takes up a lot of memory .
When a relational database performs statistics and other operations on a large number of data tables , It takes up a lot of memory , Because even if it only operates on one column , It also reads the entire line of data from the storage device into memory .
(4) The performance of full-text search is poor
Be similar to MySQL Relational database , Only use like Matching for whole table scanning , Efficiency is very low . Today, , There are many scenarios that need to support fuzzy matching , And it has to support efficient lookup . For example, query the log information containing keywords , Or query the product list according to a product keyword .
1.2 Non relational
1.2.1 What is non relational ?

NoSQL(NoSQL = Not Only SQL ), meaning " not only SQL".
A non relational database is not strictly a database , It should be a collection of data structured storage methods , It can be document or key value equivalence .
1.2.2 Common non relational databases
Key value database :Redis、Memcached、Riak.
Columnar database :Bigtable、HBase、Cassandra.
Document database :MongoDB、CouchDB、MarkLogic.
Graphic database :Neo4j、InfoGrid.
1.2.3 The advantage of non relational
Flexible format : The format for storing data can be key,value form 、 Document form 、 Picture form and so on , Document form 、 Picture form and so on , Flexible use , Wide application scenarios , Relational databases only support basic types .
Fast :NoSQL You can use hard disk or memory to store , The relational database can only use hard disk ;
High scalability ;
The cost is low :nosql Database deployment is simple , It's basically open source software .
1.2.4 The disadvantages of non relational
Does not provide sql Support , The cost of learning and using is high ;
No transactions .MongoDB 4.0 Supported transaction .
The data structure is relatively complex , It's a little bit less in terms of complex queries .
Two 、 Distributed database
2.1 The definition of distributed database
There is no official definition of distributed database , It's just a conventional saying put forward by our technicians .
In the realm of databases , When the product is constantly evolving and gradually recognized by everyone , It will become a standard , For example, Microsoft's SQL Server database , Other databases like to contrast it , that SQL Server The database will become a standard .
But distributed database is also proposed in recent years , It's still relatively new , There is no reference . However, we can understand the distributed database through the experience of these big companies .
Distributed database is a database implemented with distributed architecture .
2.2 The advantages of distributed databases
Distributed has always been a topic of my research , Now many popular technologies use distributed architecture , For example, micro services 、 Message queue .
So why do we use distributed architecture ? Simply speaking , It's using multiple computers ( machine ) To horizontally expand the performance of a single machine , Another important reason is distributed reliability , For example, multi machine backup 、 Disaster tolerance, etc .
Does the database also need to improve performance and ensure reliability ? The answer is yes .
Which big factories are using distributed database ?
Every year 11, Ali likes it show A wave of trading record , Its distributed database OceanBase " . Big companies like Tencent 、 Bytes to beat 、 Meituan also began to use distributed databases , In addition, major banks have launched distributed databases .
So distributed database is a trend , If the business scenario requires high performance and high reliability , We can consider using the database under the distributed architecture .
2.3 Features of distributed database
First of all, let's take a look at two scenarios where databases are classified according to transaction types :
online transaction (OLTP)
OLTP It's a transaction oriented process , The amount of data for a single transaction is small , But we have to give the results in a very short time , Typical scenes include shopping 、 Pay 、 Transfer, etc ;
Online analytics (OLAP)
OLAP Scenarios are usually operations based on large data sets , Typical scenarios include the generation of personal annual bills and corporate financial statements .
OLTP It is characterized by more writing and less reading 、 Low delay 、 High concurrency , So the database + Distributed in OLTP What are the characteristics of the scene ?
characteristic :
It's powerful in the context of more writing and less reading .
Low latency response .
Support high concurrency .
Support mass storage .
high reliability .
3、 ... and 、10 A distributed database
3.1 PingCAP Of TiDB
Open source + Good community operation , Have a high popularity .
Definition : It supports both online transaction processing and online analysis processing (Hybrid Transactional and Analytical Processing, HTAP) Integrated distributed database products , With horizontal expansion or reduction 、 Financial high availability 、 real time HTAP、 Cloud native distributed database 、 compatible MySQL 5.7 The protocol and MySQL Ecological and other important characteristics . The goal is to provide users with one-stop OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP Solution .TiDB For high availability 、 Strong consensus requires higher requirements 、 Large data scale and other application scenarios .
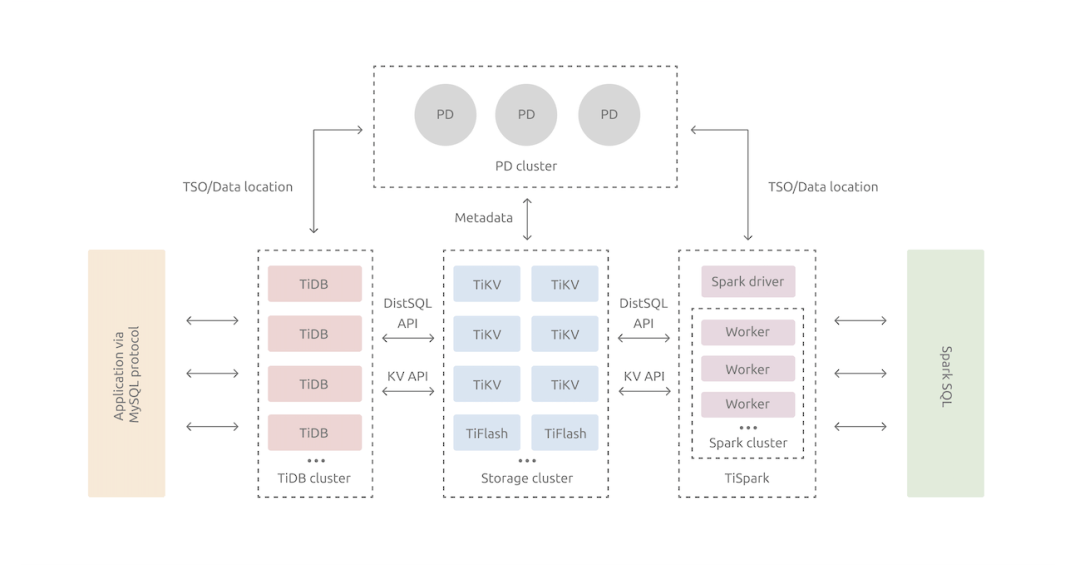
TiDB Architecture diagram
TIDB Using a layered architecture , There are three kinds of characters :
TIDB: As SQL engine .
TiKV: As the underlying distributed key value storage .
PD: Responsible for metadata management and global clock .
TiDB The derivatives of :
Ti-Binlog、Ti-CDC Support data export .
Ti-Operator More convenient to implement container cloud deployment .
Chaos Mesh Support chaos Engineering .
shortcoming : Global deployment is not supported , This is a cross regional large-scale cluster application TiDB Set up obstacles .
3.2 Google Of Spanner
Spanner It's developed by Google 、 Extensible 、 Many versions 、 Globally distributed 、 Synchronous replication database . It supports externally consistent distributed transactions .
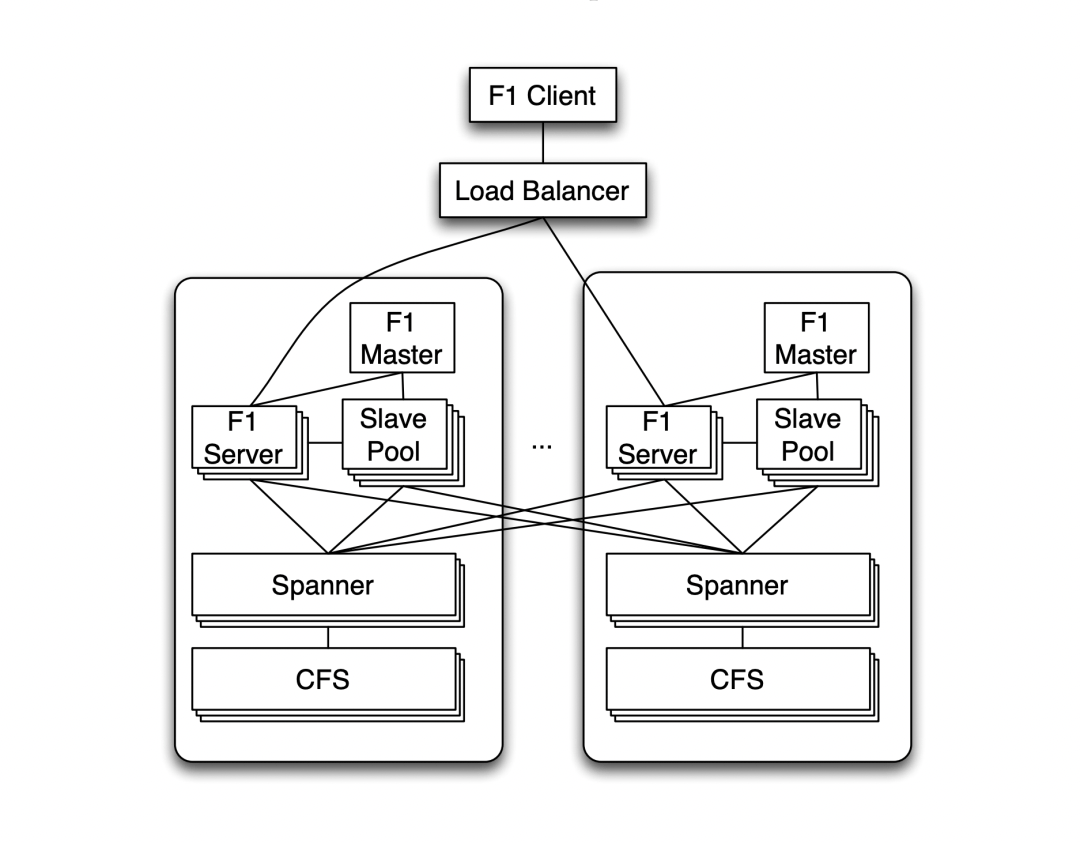
F1 Mainly as SQL engine
Spanner Mainly responsible for transaction consistency 、 Replication mechanism 、 Scalable storage, etc .
Spanner The core processing module in the architecture is Spanserver,
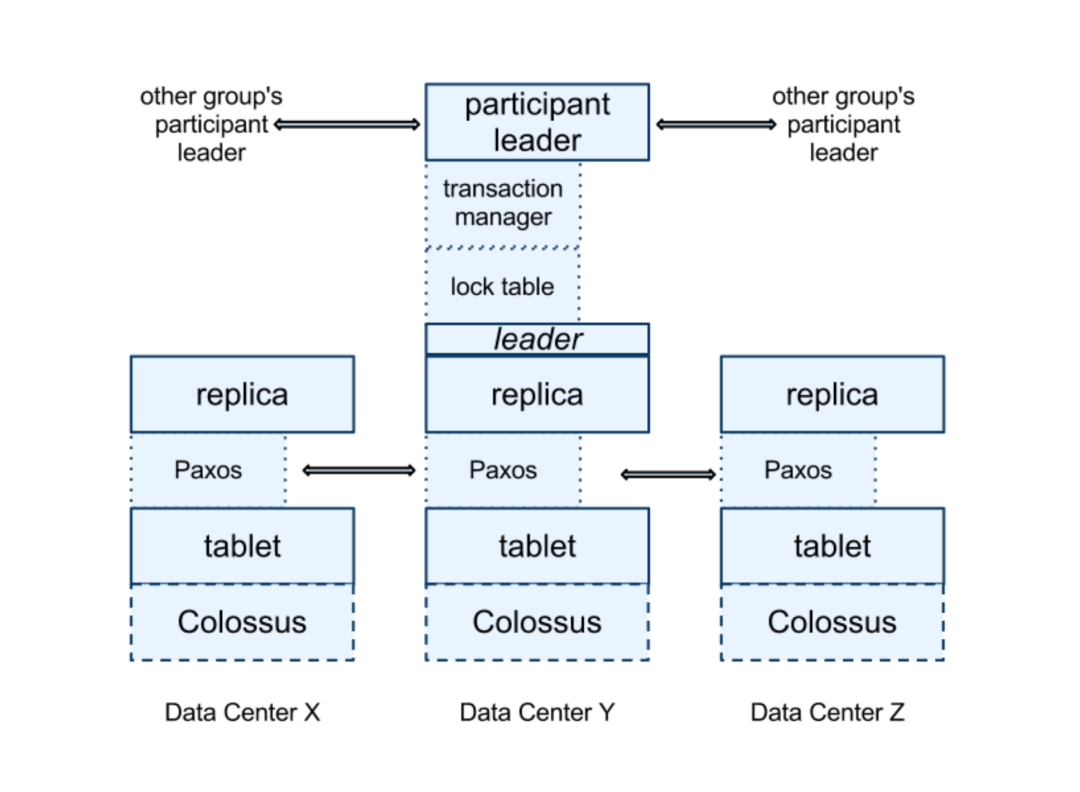
Spanner The architecture of , come from Google The paper
Spanserver There are three parts to the core of our work :
be based on Paxos Protocol data replication .Paxos The agreement can be seen in an article I wrote before :《 Talk about distributed algorithms in Three Kingdoms , Comfortable, right ?》
be based on Tablet Slice management of .
be based on 2PC Transaction consistency management for .2PC The agreement can be seen in an article I wrote before :《 Use Taijiquan to teach distributed theory , It is really comfortable !》
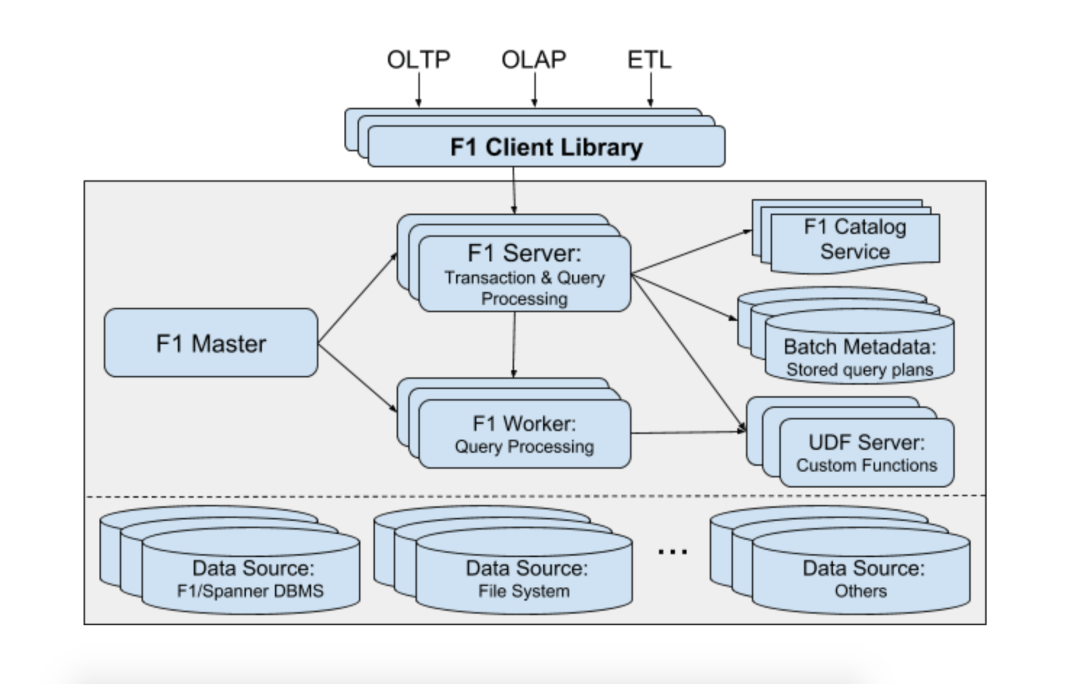
2017 year ,F1 and Spanner It's split up , No longer a binding relationship . The principle is as follows :
3.3 CockroachDB Cockroach database
CockroachDB ( Cockroach database ) It's a scalable 、 Support geographic processing 、 Data storage system supporting transaction processing .
Why is it called a cockroach ?
Because this database as long as the number of damaged nodes does not exceed half of the total number , So the cluster still works , Strong vitality .
Through distributed consistency algorithm instance to adjust to ensure consistency , It's chosen to use Raft Consistency algorithm . All consistent states exist in RocksDB in .
Cockroach It's a distributed one SQL database . The primary design goal is Extensibility , Strong consistency , Viability , Just like its name .Cockroach Our goal is to... Without human intervention , Tolerate disks with minimal interruption time , host , The rack even Data Center disaster .Cockroach The nodes of are peer-to-peer , One of the design goals is to have minimal configuration and no dependency , Deploy decentralized peer nodes . Chinese community address :cockroachdb-cn.
CockroachDB Provides two different transaction features , Including snapshot isolation (snapshot isolation, abbreviation SI) Isolated from sequential snapshots (SSI) semantics , The latter is the default isolation level .
CockroachDB It's a distributed one K/V Data warehouse , Support ACID Business , Multi version value storage is its primary feature . The main design goals are global consistency and reliability , You can see this from the name of cockroaches . The cockroach database can handle disks 、 Physical machines 、 Minimum delay service interruption in case of rack or even data center failure ; The whole failure process does not need human intervention . Cockroach nodes are balanced , Its design goal is homogeneous deployment ( There's only one binary package ) And the minimum configuration .
CockroachDB and TiDB、YugabyteDB They all claim to be inspired Spanner, So it is often considered to be isomorphic products .CockroachDB and TiDB, It's often compared .
difference :
CockroachDB Using standard P2P framework , As long as the number of damaged nodes is less than half of the total , So the cluster still works .
CockroachDB Support global deployment , Because it uses a hybrid logic clock (HLC), So data consistency can be achieved on a global physical scale .
There are different management mechanisms of fragmentation .
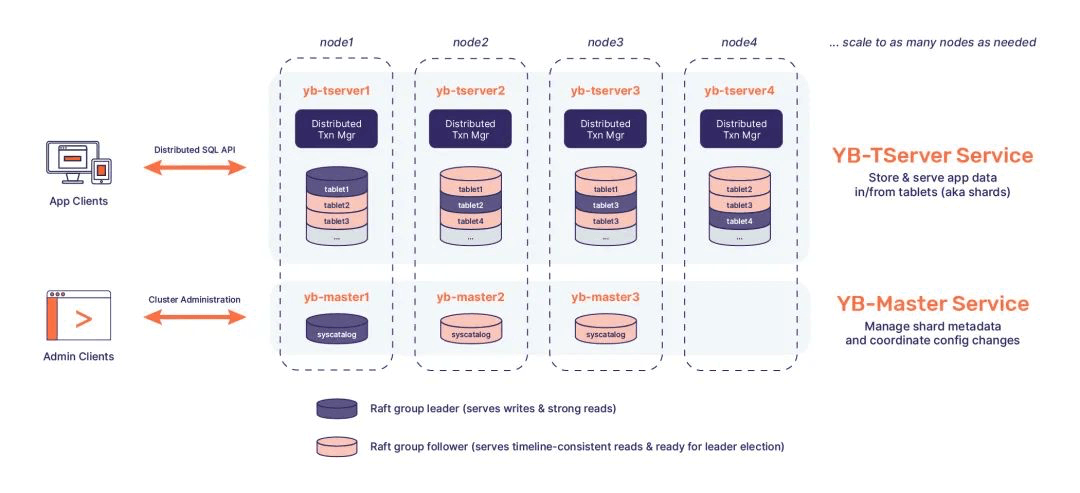
3.4 YugabyteDB
Architecturally and CockroachDB There are many similarities , For example, supporting global deployment , Using mixed logic clock (HLC), be based on Percolator Transaction model of , compatible PostgreSQL agreement .
Because of the high degree of similarity ,YugabyteDB And CockroachDB The competition is very fierce .
Yugabyte It adopts a two-tier architecture : Query layer and storage layer . But the architecture is only logical , In the deployment structure , These two floors are located in TServer In progress . This and TiDB Different .
Yugabyte At the same time SQL and CQL Two kinds of API, among CQL Is compatible Cassandra It's a dialect grammar , The storage model corresponding to the document database ; and SQL API It's directly based on PostgresQL Demonic , It's compatible with PG grammar ,
Yugabyte It's the storage layer that matters . among TServer Responsible for the storage tablet, Every tablet Corresponding to one Raft Group, Distributed on three different nodes , To ensure high availability .Master Responsible for Metadata Management , except tablet Location information for , It also includes table structure and other information .Master It also depends on Raft High availability .
3.5 Ali OceanBase
OceanBase It is a financial level distributed relational database developed by ant group , From 2010 year .OceanBase With strong data consistency 、 High availability 、 High performance 、 Online expansion 、 Highly compatible SQL Standards and mainstream relational databases 、 Low cost and so on .
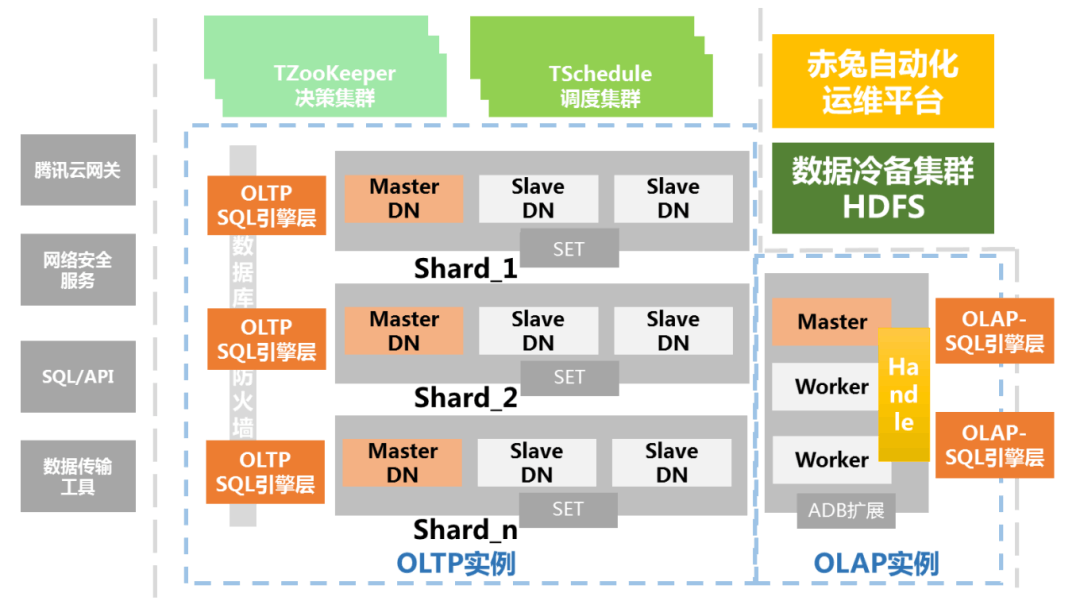
3.6 Tencent's TDSQL
TDSQL All of the nodes are used MySQL. It is a distributed cluster architecture ( Here's the picture ), This kind of cluster architecture has high flexibility , Simplify the various Communication mechanism between nodes , It also simplifies the need for hardware . It doesn't just mean TDSQL A relational example of 、 branch Cloth example 、 Analytic instances can be deployed in the same cluster , It also means that even simple x86 The server , also You can build something similar to a minicomputer 、 Shared storage and other stable and reliable database .
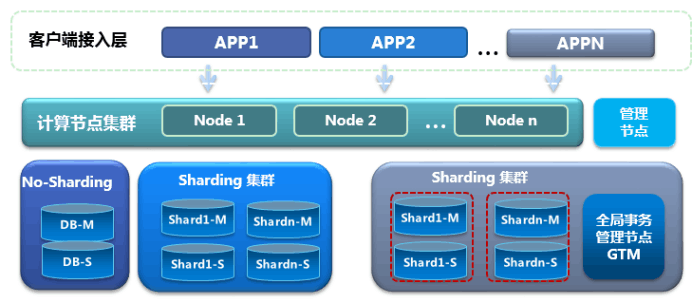
3.7 Zte's GoldenDB
GoldenDB It is almost the largest distributed database in the domestic banking industry , and TDSQL Also select... On the data node MySQL, But the increase in global clock nodes makes it a standard PGXC framework .
3.8 Tencent's TBase
TBase It's Tencent's data platform team in open source PostgreSQL Enterprise level distribution based on R & D HTAP Database management system :
- With high-performance and scalable distributed transaction capabilities , Support RC and RR Two isolation levels ;
- Through security 、 management 、 The system of separation of audit powers , Provide a comprehensive data security guarantee mechanism ;
- Support high performance partition table , The efficiency of data retrieval can be doubled ;
- SQL Aspect compatibility 2003 standard 、PostgreSQL Grammar and common use Oracle function & data type 、 Window functions, etc ;
- Provide data separation between large and small businesses 、 Efficient data management capabilities such as hot and cold data separation
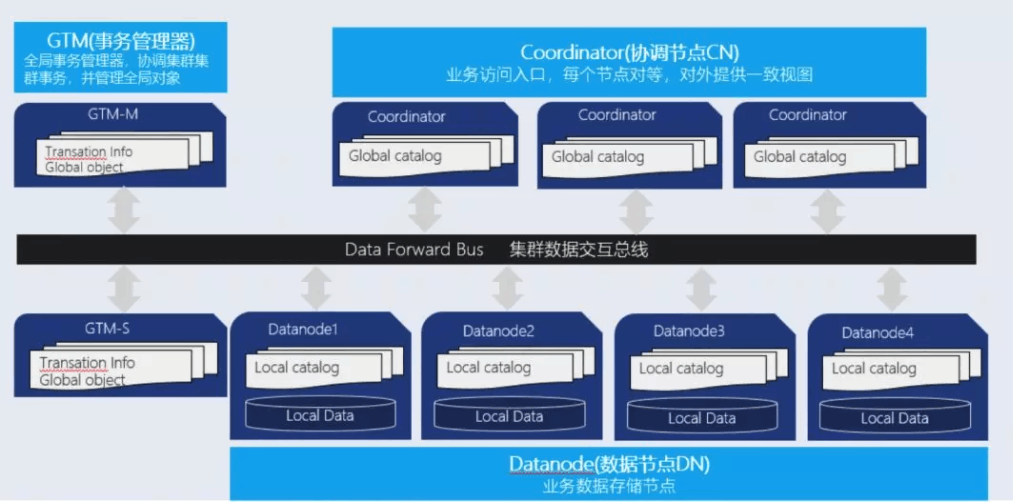
There are three types of nodes in a cluster , They have different functions , Connect to a system through the Internet . The three node types are :
- **Coordinator:** Coordinate nodes , Provide external interface , Responsible for data distribution and query planning , Multiple nodes are equally located , Each node provides the same database view ,CN Global metadata of the storage system .
- **Datanode:** Process and store metadata related to this node , Each node also stores a slice of data . Functionally ,DN The node is responsible for completing the execution request distributed by the execution coordination node .
- GTM: Global transaction manager (Global transaction manager.), Responsible for the management of cluster transaction information , At the same time, manage the global objects of the cluster , Example sequence , besides GTM There are no other functions available on .
3.9 VoltDB
VoltDB The profile provided on the official website :VoltDB It's the fastest in memory database in the world , It inherits the strong consistency requirement of traditional relational database , It also provides the ability to deploy and distribute on the Internet cloud Horizontal expansion capability of database .VoltDB By saving all the databases in memory , Eliminates massive data and log disk access operations , In a single threaded way , Eliminates disk lock and record lock ; Through database fragmentation Technology , Let the database support high concurrent requests ; Support horizontal expansion of database through distributed cluster . Its query speed is as fast as that of traditional database 100 More than times .
2019 It was officially closed in , Into pure commercial products . At the same time ,VoltDB There is no complete service support system in China , This affects its promotion to a large extent .
3.10 Giant fir SequoiaDB
SequoiaDB Jushan database is an open source financial level distributed relational database , It mainly provides high performance for high concurrent online transaction scenarios 、 Reliable, stable and unlimited horizontal expansion of database services .
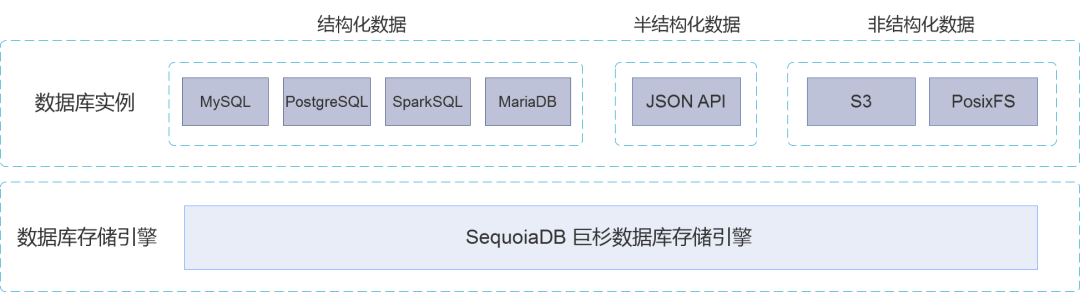
Users can go to SequoiaDB Create multiple types of database instances in Jushan database , In order to meet the needs of different upper applications .
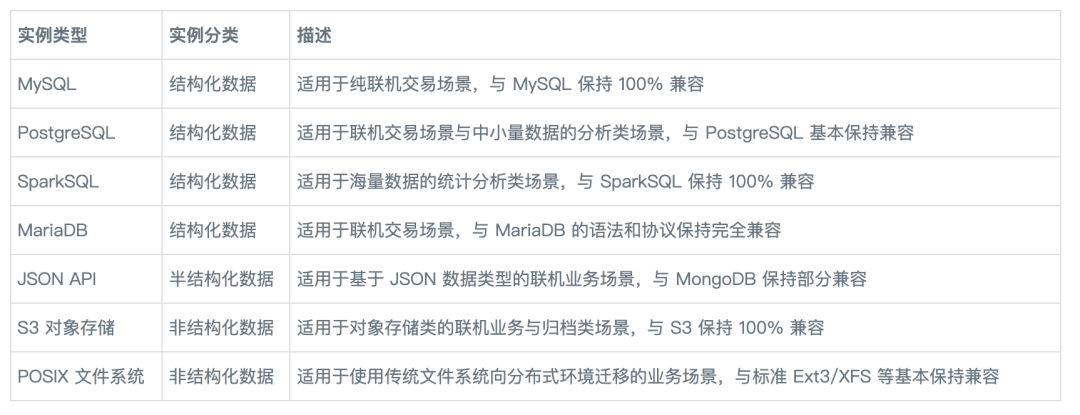
SequoiaDB Jushan database supports MySQL、PostgreSQL、SparkSQL and MariaDB Four relational database instances 、 class MongoDB Of JSON Document class database instance 、 as well as S3 Object storage and POSIX Unstructured data instance of file system .
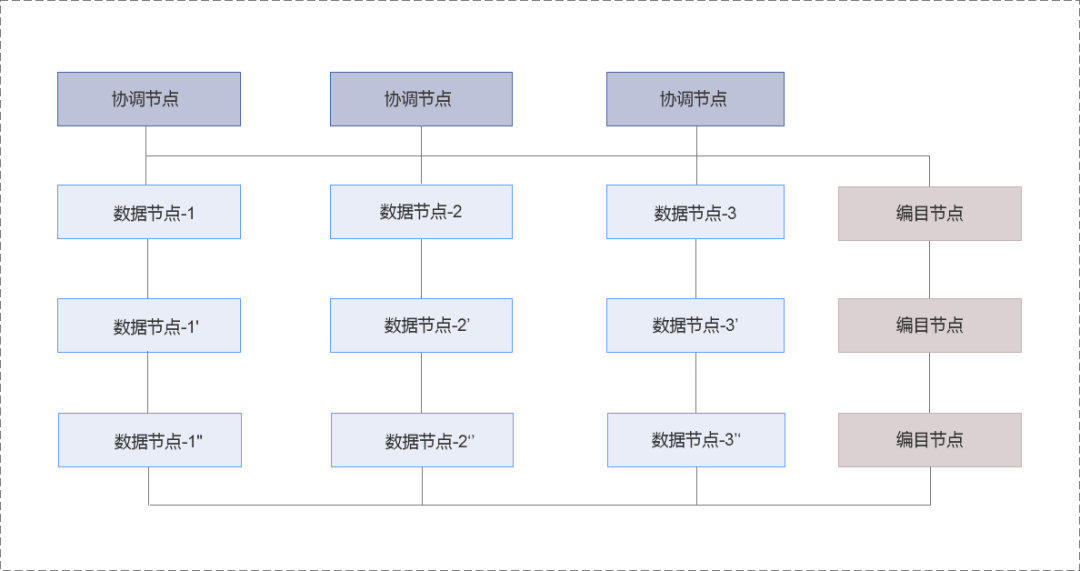
SequoiaDB Jushan database storage engine adopts distributed architecture . Each node in the cluster is an independent process , Between nodes TCP/IP Protocol to communicate .
The same operating system can deploy multiple nodes , Different ports are used to distinguish nodes .
Okay , For distributed databases , If you also have experience with distributed databases , Welcome to leave a message ~
Reference material :
https://docs.pingcap.com/zh/tidb/stable
http://vldb.org/pvldb/vol11/p1835-samwel.pdf
http://ericfu.me/yugabyte-db-introduction/
https://blog.csdn.net/duan_zhihua/article/details/88549173
https://www.voltdb.com/
https://www.zhihu.com/question/24225007/answer/1707736658
https://www.zhihu.com/question/24225007/answer/1326259742
https://time.geekbang.org/column/article/296558
边栏推荐
- Pointer and array are input in function to realize reverse order output
- ThinkPHP关联预载入with
- U++ 游戏类 学习笔记
- IMS data channel concept of 5g vonr+
- Test interview | how much can you answer the real test interview question of an Internet company?
- JS variable case output user name
- PLC Analog output analog output FB analog2nda (Mitsubishi FX3U)
- Using thread class and runnable interface to realize the difference between multithreading
- Knapsack problem unrelated to profit (depth first search)
- 基于Bevy游戏引擎和FPGA的双人游戏
猜你喜欢
一文搞懂常见的网络I/O模型
Batch normalization (Standardization) processing
 [email protected] Mapping relatio"/>
[email protected] Mapping relatio"/>Why JSON is used for calls between interfaces, how fastjson is assigned, fastjson 1.2 [email protected] Mapping relatio
c语言神经网络基本代码大全及其含义

【愚公系列】2022年7月 Go教学课程 005-变量
【问道】编译原理
PMP证书有没有必要续期?
Sublime tips
【二叉树】二叉树寻路
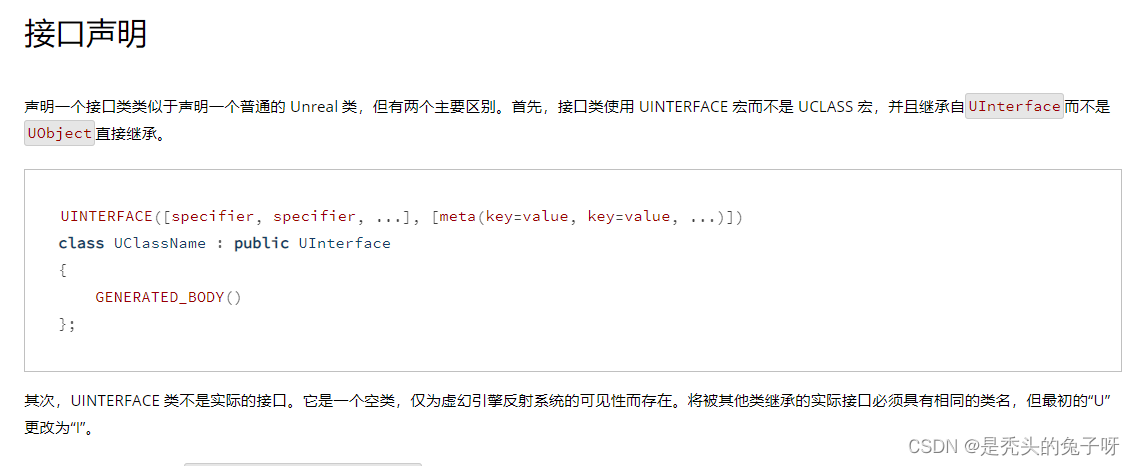
U++4 接口 学习笔记
随机推荐
【ArcGIS教程】专题图制作-人口密度分布图——人口密度分析
Appium practice | make the test faster, more stable and more reliable (I): slice test
Ansible概述和模块解释(你刚走过了今天,而扑面而来的却是昨天)
sublime使用技巧
Longest palindrome substring (dynamic programming)
Pointer and array are input in function to realize reverse order output
Servicemesh mainly solves three pain points
Using thread class and runnable interface to realize the difference between multithreading
Leetcode longest public prefix
Common Oracle SQL statements
Error: No named parameter with the name ‘foregroundColor‘
2. Overview of securities investment funds
sublime使用技巧
When knative meets webassembly
Function pointer and pointer function in C language
磁盘监控相关命令
PMP证书有没有必要续期?
Operand of null-aware operation ‘!‘ has type ‘SchedulerBinding‘ which excludes null.
R descriptive statistics and hypothesis testing
No experts! Growth secrets for junior and intermediate programmers and "quasi programmers" who are still practicing in Universities