当前位置:网站首页>全自动化处理每月缺卡数据,输出缺卡人员信息
全自动化处理每月缺卡数据,输出缺卡人员信息
2022-07-07 21:54:00 【阿黎逸阳】
不管是上学还是上班都会统计考勤,有些学校或公司会对每月缺卡次数过多(比如三次以上)的人员进行处罚。有些公司还规定对于基层员工要在工作日提交日志、管理人员要提交周报或月报,对于少提交的人员要进行处罚。如果公司HR逐个对人员的日志或缺卡数据进行处理,将是一项耗时且无聊的工作。
本文提供了自动处理考勤和日志缺失的方法。不用安装Python,不用学Python语法,只要你会在电脑上新建文件夹,点击文件就可以实现考勤和日志缺失名单的统计输出。接下来一起来看下实现步骤吧。
一、效果展示
1 实现效果
首先来看下实现效果。
大体实现步骤如下:
步骤1:在D盘中新建“每月缺卡数据处理“文件夹(已在代码中固定死了,必须建该文件夹)。
步骤2:把处理考勤缺失的exe文件和原始数据文件放到step1新建的文件夹中。
步骤3:点击exe文件,会自动出来csv结果文件,具体格式如下:

2 原始数据模板
原始数据文件需为”判断是否提交日志2.xlsx“,本文使用的原始数据如下(表头需按如下命名):
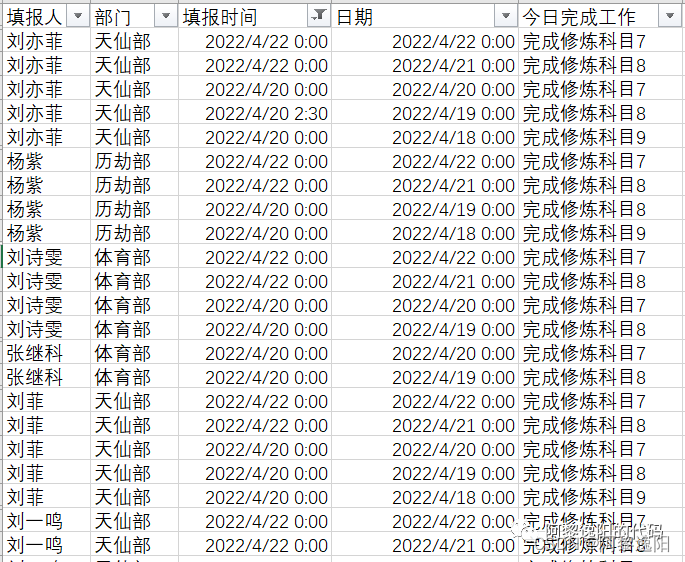
注:如需本文原始数据、和直接运行得到结果的exe文件,可到本公众号中回复“缺卡”,即可免费获取。
其中填报人指学生或员工姓名,部门若为学生可以填某某班。填报时间指日志填报时间,日期指日志实际日期。若为考勤打卡,两个日期都填实际打卡的日期即可。若为考勤打卡,今日完成工作列可置为空。
如果原始文件中想存放员工打卡的全年数据,但想统计其中某个月的缺卡数据。只需把想统计的月份放在日期的第一行即可,代码中已按日期第一行进行了同年月数据子框的筛选。如需设置定时任务,把运行结果定时邮件发送给相关人员,可以到公众号中私信我。
二、代码详解
对于部分了解Python的朋友来说,如果有个性化的需求,可以自己微调代码实现需求。接下来详细阐述实现上述功能的代码。
1 导入库
首先导入本文需要加载的库,如果你有些库还没有安装,导致运行代码时报错,可以在Anaconda Prompt中用pip方法安装。
# -*- coding: UTF-8 -*-
''' 代码用途 :处理缺卡数据 作者 :阿黎逸阳 公众号 : 阿黎逸阳的代码 '''
import os
import calendar
import numpy as np
import pandas as pd
from datetime import datetime
from xlrd import xldate_as_tuple
from chinese_calendar import is_workday
from chinese_calendar import is_holiday
from chinese_calendar import get_holiday_detail
本文应用到了os、calendar、numpy、pandas、datetime、xlrd、chinese_calendar库。
os库可以设置文件读取的位置。
calendar和chinese_calendar库是日期处理库。
numpy和pandas库处理数据框。
xlrd和datetime库处理时间。
2 定义时间处理函数
接着应用xlrd和datetime库中的函数定义时间处理函数,把时间戳或带时分秒的时间转换成只含年月日的时间。
def num_to_date(x):
''' 日期处理函数 把时间戳或带时分秒的时间转换成只含年月日的时间 '''
try:
x1 = datetime(*xldate_as_tuple(x, 0)).strftime('%Y-%m-%d')
except:
x1 = datetime.date(x).strftime('%Y-%m-%d')
return x1
定义成年月日统一时间的目的是为了方便后续代码的运行。
3 读取数据调整日期格式
接着读取数据,应用第二小节定义的时间处理函数把填报时间和日期进行处理。
#读取数据
os.chdir(r'D:\每月缺卡数据处理')
date = pd.read_excel('判断是否提交日志2.xlsx', sheet_name='Sheet1')
#调整日期格式
date['填报时间'] = date['填报时间'].apply(num_to_date)
date['日期'] = date['日期'].apply(num_to_date)
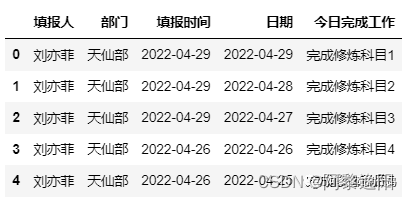
原始部分数据如下:
调用时间处理函数得到的部分数据如下:
4 计算工作日天数
接着取出数据框日期列的第一个值,获取要统计的年月信息。根据年月信息获取该月工作日的天数。
#取出想看缺卡信息的年月
y_m1 = date['日期'][0][0:7]
def sele_ym(x, y_m=y_m1):
''' 判断数据框中的日期是否为某月 '''
if x.find(y_m)>=0:
return True
#找出这一个月中的工作日,求出工作日的天数
days = calendar.Calendar().itermonthdates(int(y_m1.split('-')[0]), int(y_m1.split('-')[1]))
mth_nwkdays = [] #非工作日
mth_wkdays = [] #工作日
mth_days = [] #全部日期
for day in days:
if str(day).find(y_m1)>=0:
#print(str(day))
mth_days.append(str(day))
if is_workday(day)>0:
mth_wkdays.append(str(day))
else:
mth_nwkdays.append(str(day))
work_days = len(mth_wkdays) #工作日天数
把工作天数和员工本月的实际打卡或写日志的天数进行对比,如果实际值小于理论值,说明员工缺卡或请假了。由于大部分的员工都是正常打卡或写日志的,这时人工再对缺卡员工进行排查已经极大地缩小了排查面。如有特殊代码需求,需要求助的,可以到公众号中私信我。
5 获取缺卡名单
最后调用函数获取缺卡名单,主要是对每个填报日期和实际工作日期进行比对。
#定义获取缺卡信息的函数
def stat_dail_short(date, y_m1, work_days):
''' date:存储日志的数据大表 y_m1:月份 work_days:该月的工作天数 '''
qk_file = []
date_m = date[date['日期'].apply(sele_ym)==True]
for i in set(date_m['填报人']):
sub_date = date_m[date_m['填报人'] == i]
if len(sub_date['日期'])<work_days:
qk = str(set(sub_date['填报人'])) + str(set(sub_date['部门'])) + '缺了'+ str((work_days-len(sub_date['日期']))) + '次卡' + ';缺卡日期为:'+ str(set(mth_wkdays)^set(sub_date['日期']))
qk_file.append(qk)
print(set(sub_date['填报人']), set(sub_date['部门']), '缺了%d次卡'%(work_days-len(sub_date['日期'])), ';缺卡日期为:', set(mth_wkdays)^set(sub_date['日期']),sep='')
qk_file_1 = pd.DataFrame(qk_file)
qk_file_1.columns = ['缺卡信息']
qk_file_1.to_csv(y_m1+' 缺卡名单'+'.csv', encoding='gbk')
#调用函数获取缺卡名单
stat_dail_short(date, y_m1, work_days)
得到结果:
{
'张继科'}{
'体育部'}缺了5次卡;缺卡日期为:{
'2022-04-11', '2022-04-29', '2022-04-22', '2022-04-18', '2022-04-21'}
{
'杨紫'}{
'历劫部'}缺了1次卡;缺卡日期为:{
'2022-04-20'}
{
'刘诗雯'}{
'体育部'}缺了2次卡;缺卡日期为:{
'2022-04-18', '2022-04-28'}
结果中的数据是用填报人、填报部门、缺卡次数、具体的缺卡日期进行拼接展示的。会以csv的形式存放到指定文件夹中。如果需要把姓名、部门、缺卡次数等信息分开,可以在excel中按特定条件分列,或调整一下代码进行实现。
本文开头的exe文件生成方法,可以参考Pinstaller(Python打包为exe文件)一文。我在生成exe的过程中一直有报错,后面在网上看到方法说先在cmd中运行pip uninstall matplotlib,再运行生成exe的语句就不会报错。按网上方法真成功了,虽然没有明白原理,但还是非常感谢!如果你在打包的时候没有报错,还是不建议删除matplotlib库。
至此,全自动化处理每月缺卡数据,输出缺卡人员信息已讲解完毕,动动手分享给你身边有需要的ta吧。
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
用Python绘制520永恒心动
Python人脸识别—我的眼里只有你
Python画好看的星空图(唯美的背景)
【Python】情人节表白烟花(带声音和文字)
用Python中的py2neo库操作neo4j,搭建关联图谱
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)

边栏推荐
- Anti climbing means cracking the second
- Wechat applet development beginner 1
- C语言学习
- Kubectl 好用的命令行工具:oh-my-zsh 技巧和窍门
- C language learning
- limit 与offset的用法(转载)
- Idea automatically generates serialVersionUID
- 95. (cesium chapter) cesium dynamic monomer-3d building (building)
- 解析token的网址
- postgres timestamp转人眼时间字符串或者毫秒值
猜你喜欢
One click free translation of more than 300 pages of PDF documents
About the difference between ch32 library function and STM32 library function
PostGIS learning
Chisel tutorial - 02 Chisel environment configuration and implementation and testing of the first chisel module

Rectification characteristics of fast recovery diode
Ora-02437 failed to verify the primary key violation

The file format and extension of XLS do not match
Installing gradle
快速回复二极管整流特性
Learn about scratch

随机推荐
Chisel tutorial - 00 Ex.scala metals plug-in (vs Code), SBT and coursier exchange endogenous
Binary sort tree [BST] - create, find, delete, output
Traduction gratuite en un clic de plus de 300 pages de documents PDF
Data analysis series 3 σ Rule / eliminate outliers according to laida criterion
DataGuard active / standby cleanup archive settings
蓝桥ROS中使用fishros一键安装
BSS 7230 flame retardant performance test of aviation interior materials
Anti climbing means cracking the second
[path planning] use the vertical distance limit method and Bessel to optimize the path of a star
ASP. Net query implementation
【推荐系统基础】正负样本采样和构造
C - Fibonacci sequence again
Balanced binary tree [AVL tree] - insert, delete
Kubectl 好用的命令行工具:oh-my-zsh 技巧和窍门
Les mots ont été écrits, la fonction est vraiment puissante!
Connect diodes in series to improve voltage withstand
P2141 [noip2014 popularization group] abacus mental arithmetic test
35岁那年,我做了一个面临失业的决定
Jisuan Ke - t3104
Download AWS toolkit pycharm