当前位置:网站首页>The underlying structure of five data types in redis
The underlying structure of five data types in redis
2022-07-06 04:45:00 【Chirp cat】
Redis The underlying structure of five data types
Redis It's called a core object redisObject , Used to represent all key value pairs , use redisObject Structure to represent string、hash、list、set、zset These five basic data types .
string character string
redis There are two ways to store strings :SDS( Simple dynamic string )、 Direct storage ( Use when the storage object is an integer )
SDS characteristic : Dynamic capacity expansion 、 Binary security 、 Fast traversal of strings 、 Compatible with traditional C character string .
string The coding :int、raw、embstr
Direct storage , Use int code
- int: Use when the storage object is an integer
SDS Storage , Use raw or embstr code
raw: The storage object is longer than 32 Bit string ( establish / There are two memory allocations when releasing objects :1、 establish / Release redisObject object ,2、 establish / Release sdshdr structure . here redisObject and sdshdr Not in a continuous space )
embstr: The storage object is less than or equal to 32 Bit string ( establish / There is only one memory allocation when releasing an object ,redisObject and sdshdr Are allocated in the same continuous memory space )
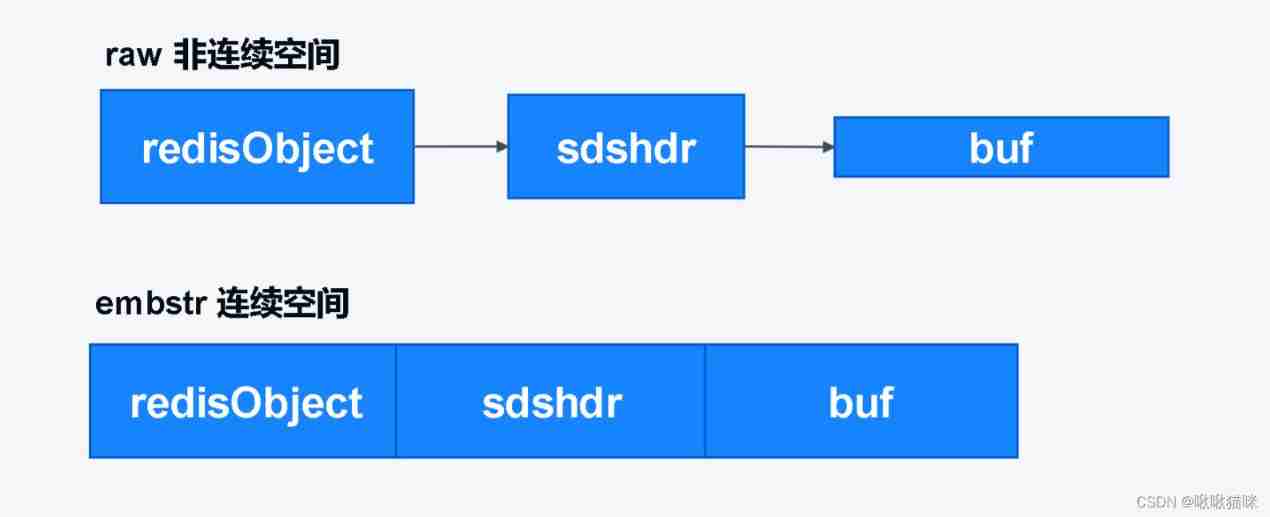
SDS Be similar to Java Of ArrayList, Reduce the frequent allocation of memory by pre allocating redundant space , Dynamic capacity expansion .
Conventional C String with ‘\0’ Character as end , Will ignore ‘\0’ All characters after the end , That is, cannot store with ‘\0’ String data for ( Such as the picture 、 Video and other binary files ).Redis Of SDS In traditional C A string header is added to the string (sdshdr), In the string header len Member records the length of the string , And according to len Member to determine the end position of the string , This means that it can store any binary data and text data , Include ‘\0’ , therefore SDS It's binary safe . Because there is len The existence of members , The time complexity of getting the string length is O(1).
list list ( queue )
stay redis 3.2 Before ,list The underlying the ziplist( Compressed list ) And linkedlist( Double linked list ) Storage
linkedlist: It's essentially a two-way linked list , Each node is a storage object . Because the storage space of the linked list is not continuous , Linked list nodes are too scattered in memory , Therefore, too much space debris will be generated .linkedlist It is generally used to store large list objects with more data .
ziplist: Similar to byte array ,ziplist Nodes of are stored continuously in memory , But unlike arrays , To save memory ,ziplist The memory size of each node of can be different . Each node can be a byte array or an integer . Only when the following two conditions are met ,redis Only use ziplist Store list objects :
(1) The length of all string elements saved by the list object is less than 64 byte .
(2) The list object holds fewer elements than 512 individual .
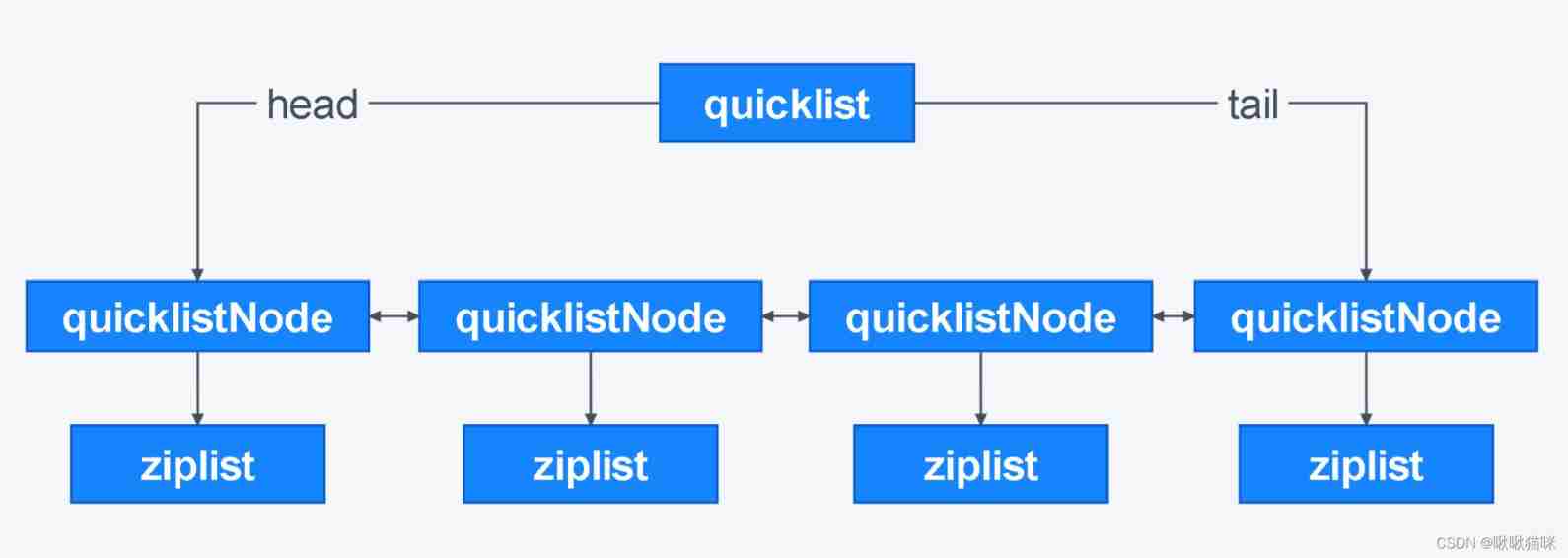
stay redis 3.2, Added a new data structure quicklist( Quick list ), Unified use quicklist To store list objects .
- quicklist: The quick list is also a two-way linked list ,quicklist By ziplist and linkedlist Combined , Each of its nodes is a ziplist.quicklist Both make up for ziplist The disadvantage of occupying too much continuous space , And avoid things like linkedlist That space occupation is too fragmented . but quicklist Not all nodes are ziplist,quicklist When storing objects, a group of nodes in the middle of the list will be compressed , The compressed node data structure in the middle of the list is quicklistZF( Compressed ziplist), The data structure of the nodes at both ends of the list is ziplist. Because the nodes at both ends will be operated frequently , therefore quicklist Nodes at both ends will not be compressed , Both optimize the space and ensure the performance .
set aggregate
unordered set , Collection members are unique , Duplicate data cannot appear in the set .
set The coding :intset( Set of integers )、hashtable( Hashtable ).
intset: A set of integers , All elements are saved here . It can store three types of data , Namely int16_t、int32_t、int64_t.intset Be similar to SDS And an array , Memory is continuous .
Collection objects use intset Coding needs to meet the following two conditions :
(1) All elements are integers .
(2) The number of elements is less than or equal to 512 individual .hashtable: The bottom layer is implemented by a dictionary , Using dictionaries key Key to save the collection object , Dictionary value The value is null.
sorted set Ordered set (zset)
sorted set The coding :ziplist、skiplist( Skip list ).
ziplist:sorted set Use ziplist Storage objects need to meet the following two conditions :
(1) All elements are less than 64 byte .
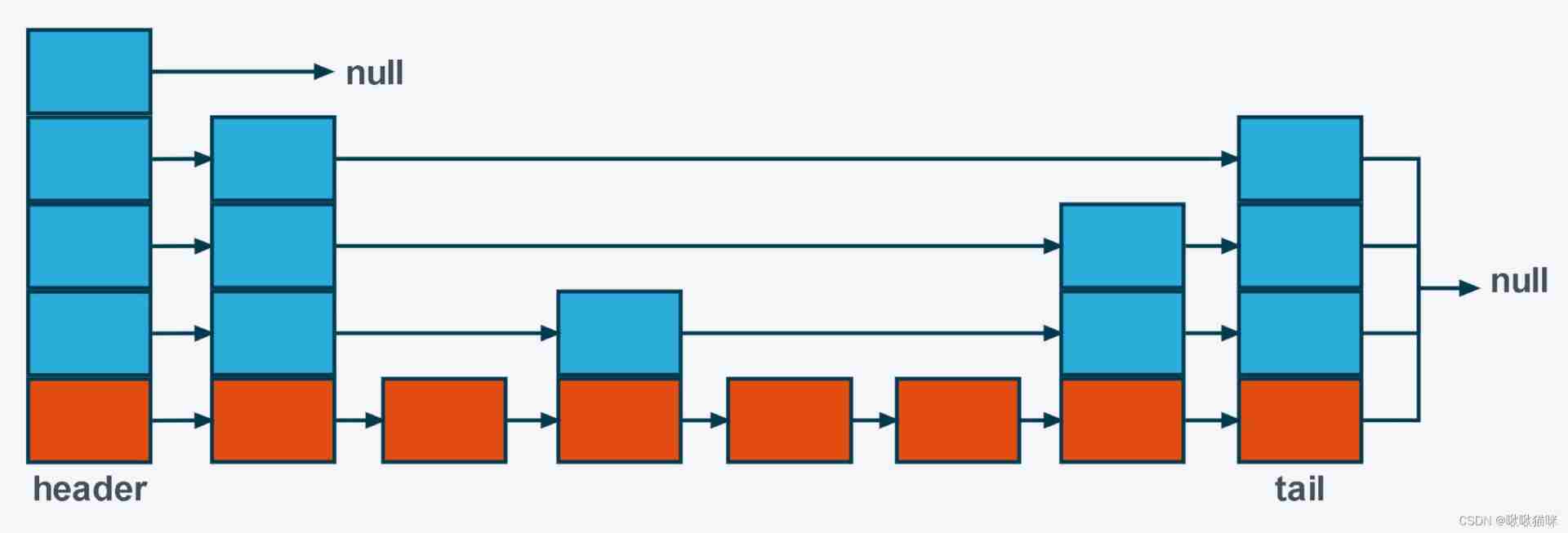
(2) The number of elements is less than 128 individual .skiplist:skiplist In essence, it is also a linked list , But each node of it will randomly generate different layers , It is a probabilistic data structure . Compared with the balanced tree , The implementation of jump table is simpler , Doing range search and insertion / Delete operation , Balance trees are more complex than jump tables ( When searching the range, the balance tree needs to traverse the middle order , Difficult to achieve , The jump table only needs to find the small value , Traversal of the first level linked list can be achieved . Insert / When deleting, the subtree of the balance tree may need to be adjusted , The jump table only needs to modify the pointer of adjacent nodes .).
Jump table node level generation code :
int randomizeLevel(double p, int lmax) {
// The initial number of layers is 1
int level = 1;
// Random number function
Random random = new Random();
// If the generated random number meets the conditions , Then the number of layers +1, Go to the next level of circulation
while (random.nextDouble() < p && level < lmax) {
// The higher the number of layers , The lower the probability
level++;
}
// If the generated random number does not meet the conditions , Out of the loop , Returns the current number of layers
return level;
}
If the probability of generating a layer is 1/2, Then the probability of generating two layers is 1/4, The third floor is 1/8, The higher the number of layers , The lower the probability of generation .
hash Hash
hash The coding :ziplist、hashtable( Hashtable ).
ziplist: stay ziplist in , Key value pairs are placed in a closely connected way , Put in first key, And then put in value, Key value pairs are always added to the end of the table .hash Objects need to meet the following two conditions before they can be used ziplist Storage :
(1) The string length of keys and values of all key value pairs is less than 64 byte .
(2) The number of key value pairs is less than 512 individual .hashtable: At the bottom is a dictionary ,hash Each key value pair of the object is directly stored in the dictionary .
边栏推荐
- Certbot failed to update certificate solution
- 拉格朗日插值法
- [face recognition series] | realize automatic makeup
- [Zhao Yuqiang] deploy kubernetes cluster with binary package
- Platformio create libopencm3 + FreeRTOS project
- 程序员在互联网行业的地位 | 每日趣闻
- newton interpolation
- Canal synchronizes MySQL data changes to Kafka (CentOS deployment)
- [try to hack] John hash cracking tool
- After learning classes and objects, I wrote a date class
猜你喜欢
Certbot failed to update certificate solution

JVM garbage collector concept
IPv6 comprehensive experiment
Flink kakfa data read and write to Hudi

Uva1592 Database
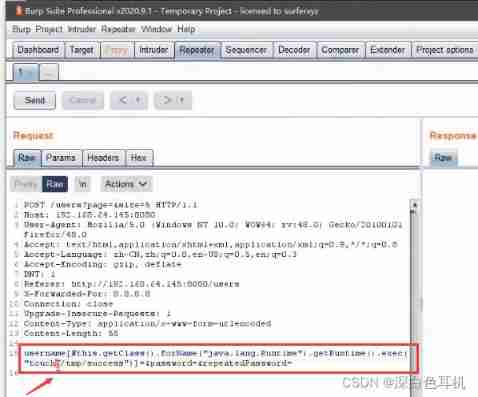
Vulnerability discovery - vulnerability probe type utilization and repair of web applications
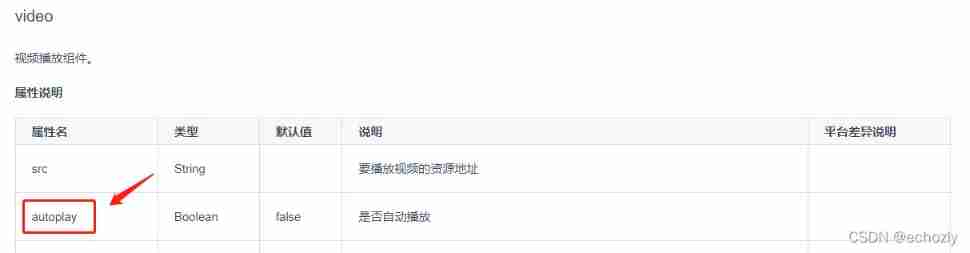
How to realize automatic playback of H5 video
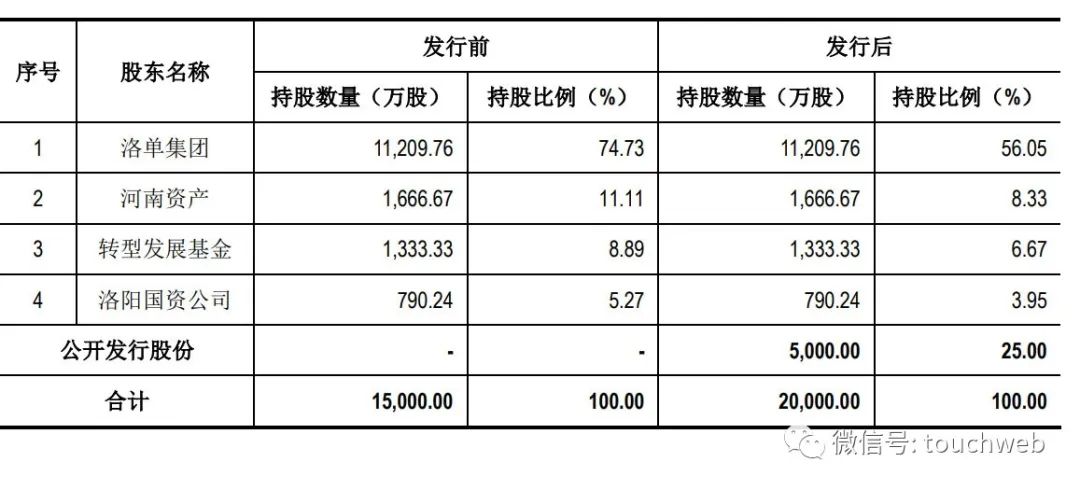
麦斯克电子IPO被终止:曾拟募资8亿 河南资产是股东
Solutions: word coverage restoration, longest serial number, Xiaoyu buys stationery, Xiaoyu's electricity bill
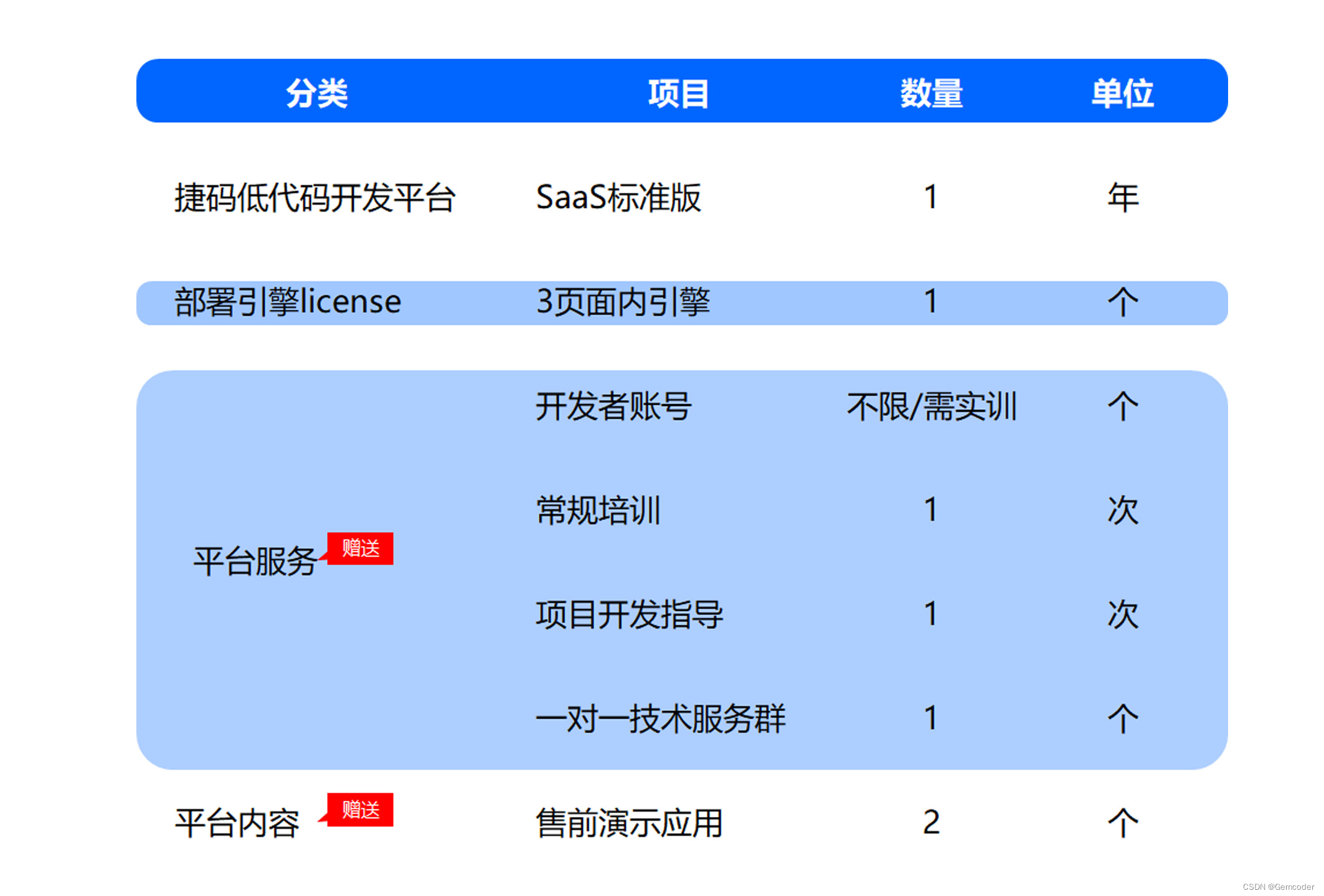
满足多元需求:捷码打造3大一站式开发套餐,助力高效开发
随机推荐
IPv6 comprehensive experiment
程序员在互联网行业的地位 | 每日趣闻
Yyds dry goods inventory OSI & tcp/ip
Etcd database source code analysis -- etcdserver bootstrap initialization storage
Easyrecovery靠谱不收费的数据恢复电脑软件
Distributed transaction solution
Platformio create libopencm3 + FreeRTOS project
Word cover underline
Uva1592 Database
Flink kakfa data read and write to Hudi
Postman断言
CADD course learning (8) -- virtual screening of Compound Library
牛顿插值法
[Chongqing Guangdong education] engineering fluid mechanics reference materials of southwestjiaotonguniversity
Fuzzy -- basic application method of AFL
The most detailed and comprehensive update content and all functions of guitar pro 8.0
canal同步mysql数据变化到kafka(centos部署)
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
P2102 floor tile laying (DFS & greed)
npm命令--安装依赖包--用法/详解