当前位置:网站首页>Etcd database source code analysis -- etcdserver bootstrap initialization storage
Etcd database source code analysis -- etcdserver bootstrap initialization storage
2022-07-06 04:24:00 【Tertium FATUM】
etcdserver.NewServer The first step of the function is to call bootstrap function ( It's defined in server/etcdserver/bootstrap.go In file ), Its input parameter is config.ServerConfig, The output parameter is bootstrappedServer, Its main function is to store Storage、 Cluster information Cluster And consistency module information Raft Initialize and recover .etcd 3.6.0 Different from the previous version, the modules that need to be restored are concentrated in bootstrappedServer In the structure , To simplify code logic .
bootstrapSnapshot
func bootstrap(cfg config.ServerConfig) (b *bootstrappedServer, err error) {
// Every etcd Nodes will save their data to " The name of the node .etcd/member" Under the table of contents . Here we will check whether the directory exists , If it doesn't exist, create the directory
if terr := fileutil.TouchDirAll(cfg.Logger, cfg.DataDir); terr != nil {
return nil, fmt.Errorf("cannot access data directory: %v", terr) }
if terr := fileutil.TouchDirAll(cfg.Logger, cfg.MemberDir()); terr != nil {
return nil, fmt.Errorf("cannot access member directory: %v", terr) }
// Delete tmp snapshot , establish snapshotter
ss := bootstrapSnapshot(cfg)
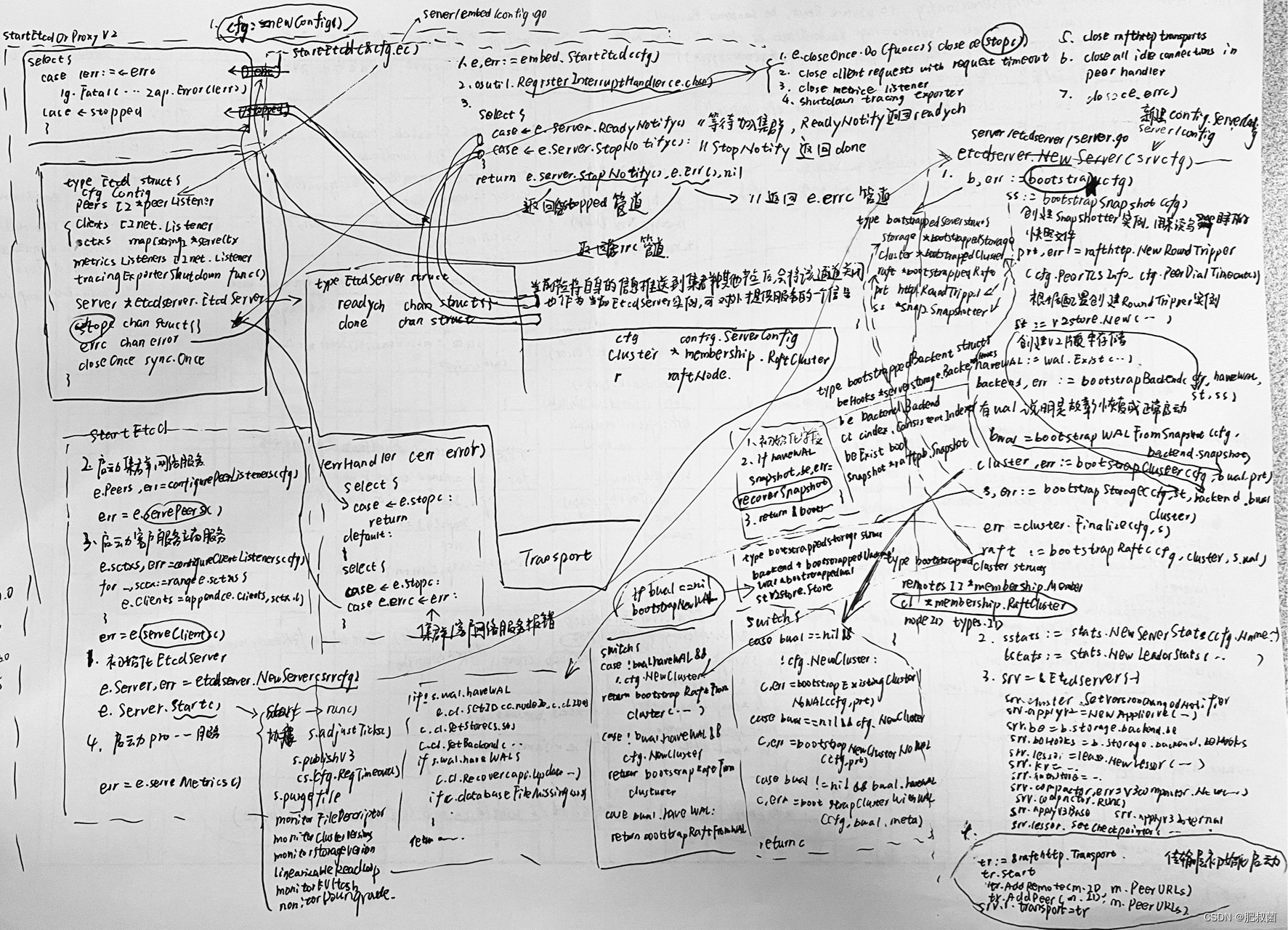
bootstrapSnapshot function The main function is to create snapshotter. Here's an explanation of what is snapshotter? As the node runs , It will handle a large number of requests from clients and other nodes in the cluster , Corresponding WAL Logs will continue to increase , A lot of WAL Log files . When the node goes down , If you want to restore its state , You need to read all from the beginning WAL Log files , This is obviously impossible .etcd To do this, snapshots are created periodically and saved to local disk ( and redis The persistence of RDB The principle of memory snapshot is consistent ), When restoring the node state, the snapshot file will be loaded first , Use the snapshot data to restore the node to the corresponding state , Then read from the corresponding position after the snapshot data WAL Log files , Finally, restore the node to the correct state .etcd Separate the snapshot function to snap Module ,snapshotter Namely snapshot The core structure of the module , Here, first initialize the structure , From the perspective of recovery logic, it is normal .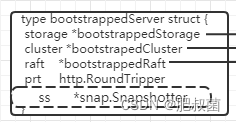
bootstrapSnapshot Function first determines that there is snap Catalog , Then delete the with tmp Prefixed snapshot file , The final call snap In bag New Function initialization snapshotter example .
func bootstrapSnapshot(cfg config.ServerConfig) *snap.Snapshotter {
if err := fileutil.TouchDirAll(cfg.Logger, cfg.SnapDir()); err != nil {
cfg.Logger.Fatal("failed to create snapshot directory",zap.String("path", cfg.SnapDir()),zap.Error(err), ) }
if err := fileutil.RemoveMatchFile(cfg.Logger, cfg.SnapDir(), func(fileName string) bool {
return strings.HasPrefix(fileName, "tmp") }); err != nil {
cfg.Logger.Error("failed to remove temp file(s) in snapshot directory",zap.String("path", cfg.SnapDir()),zap.Error(err),)
}
return snap.New(cfg.Logger, cfg.SnapDir()) // establish snaoshotter example , For reading and writing snap The snapshot file in the directory
}
Create from configuration RoundTripper example ,RoundTripper Mainly responsible for the realization of network requests and other functions .
prt, err := rafthttp.NewRoundTripper(cfg.PeerTLSInfo, cfg.PeerDialTimeout())
if err != nil {
return nil, err }
bootstrapBackend
establish v2 Version storage and detection wal Does the directory contain WAL Log files 、snaoshotter Examples should be used as bootstrapBackend The formal parameter of the function .
haveWAL := wal.Exist(cfg.WALDir()) // testing wal Does the directory contain WAL Log files
st := v2store.New(StoreClusterPrefix, StoreKeysPrefix) // establish v2 Version storage , It's specified here StoreClusterPrefix and StoreKeysPrefix Two read-only directories , These two constant values are "/0" and "/1"
backend, err := bootstrapBackend(cfg, haveWAL, st, ss)
if err != nil {
return nil, err }
First of all, we need to know what needs to be initialized Backend In fact, that is Backend An instance of an interface , according to v3 Design of version storage , The underlying storage can be switched . So here we just need initialization Backend, Restore storage . therefore bootstrapBackend The first is to judge whether it exists v3 Stored database files . Then there is the most important link first Load the snapshot file , Use the snapshot data to restore the node storage to the snapshot state , This is it. recoverSnapshot What the function does ; without wal There is no need to recover , That is, the node is newly established .
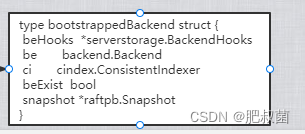
func bootstrapBackend(cfg config.ServerConfig, haveWAL bool, st v2store.Store, ss *snap.Snapshotter) (backend *bootstrappedBackend, err error) {
beExist := fileutil.Exist(cfg.BackendPath()) // testing BoltDB Whether the database file exists
ci := cindex.NewConsistentIndex(nil)
beHooks := serverstorage.NewBackendHooks(cfg.Logger, ci)
be := serverstorage.OpenBackend(cfg, beHooks) // In this function, a background process will be started to complete Backend Instance initialization
defer func() {
if err != nil && be != nil {
be.Close() } }()
ci.SetBackend(be)
schema.CreateMetaBucket(be.BatchTx())
if cfg.ExperimentalBootstrapDefragThresholdMegabytes != 0 {
err = maybeDefragBackend(cfg, be)
if err != nil {
return nil, err }
}
cfg.Logger.Debug("restore consistentIndex", zap.Uint64("index", ci.ConsistentIndex()))
// TODO(serathius): Implement schema setup in fresh storage
var ( snapshot *raftpb.Snapshot )
if haveWAL {
snapshot, be, err = recoverSnapshot(cfg, st, be, beExist, beHooks, ci, ss)
if err != nil {
return nil, err
}
}
if beExist {
err = schema.Validate(cfg.Logger, be.ReadTx())
if err != nil {
cfg.Logger.Error("Failed to validate schema", zap.Error(err))
return nil, err
}
}
return &bootstrappedBackend{
beHooks: beHooks, be: be, ci: ci, beExist: beExist, snapshot: snapshot, }, nil
}
We can see recoverSnapshot The function needs to v2 Storage st and v3 Storage be Passing in functions , as well as snapshotter ss Used to obtain snapshot files on disk . We know that every time we take a snapshot of storage , Accordingly, we will report to WAL Add... To the log snapType Logging of , Therefore, the first step is to find these types of log records , This is it. ValidSnapshotEntries What the function does . The code logic here describes a situation where there is a corresponding snapshot file , But there is no corresponding snapshot type of logging , This is certainly the case , So here we need to get the latest snapType Type of logs get the corresponding snapshot data on the disk . In addition to directly deleting snapshot data , Otherwise, there will be no snapType Type of log without obtaining the corresponding snapshot . Note here that snapshot data recovery v2 The stored code is st.Recovery(snapshot.Data), Using snapshot recovery v3 The stored code is serverstorage.RecoverSnapshotBackend(cfg, be, *snapshot, beExist, beHooks).v2 The stored recovery is actually loading the snapshot file JSON data .v3 Storage recovery will detect the previously created Backend Instance availability ( That is, it contains all the snapshot data Entry Record ), If available, continue to use this Backend example , If it is not available, find the available according to the metadata of the snapshot BoltDB Data files , And create a new Backend example .
func recoverSnapshot(cfg config.ServerConfig, st v2store.Store, be backend.Backend, beExist bool, beHooks *serverstorage.BackendHooks, ci cindex.ConsistentIndexer, ss *snap.Snapshotter) (*raftpb.Snapshot, backend.Backend, error) {
// Find a snapshot to start/restart a raft node ValidSnapshotEntries Return to the given directory wal All valid snapshot entries in the log . If the snapshot entry raft log index Less than or equal to the recently submitted hard state raft log index, Then the snapshot entry is valid .
walSnaps, err := wal.ValidSnapshotEntries(cfg.Logger, cfg.WALDir())
if err != nil {
return nil, be, err }
// snapshot files can be orphaned if etcd crashes after writing them but before writing the corresponding bwal log entries If etcd After writing the snapshot file, but after writing the corresponding bwal Log entries crash before , Then the snapshot file can be isolated orphaned
snapshot, err := ss.LoadNewestAvailable(walSnaps)
if err != nil && err != snap.ErrNoSnapshot {
return nil, be, err }
if snapshot != nil {
if err = st.Recovery(snapshot.Data); err != nil {
cfg.Logger.Panic("failed to recover from snapshot", zap.Error(err)) } // Use snapshot data recovery v2 Storage
if err = serverstorage.AssertNoV2StoreContent(cfg.Logger, st, cfg.V2Deprecation); err != nil {
cfg.Logger.Error("illegal v2store content", zap.Error(err))
return nil, be, err
}
cfg.Logger.Info("recovered v2 store from snapshot",zap.Uint64("snapshot-index", snapshot.Metadata.Index),zap.String("snapshot-size", humanize.Bytes(uint64(snapshot.Size()))),)
if be, err = serverstorage.RecoverSnapshotBackend(cfg, be, *snapshot, beExist, beHooks); err != nil {
cfg.Logger.Panic("failed to recover v3 backend from snapshot", zap.Error(err)) } // Using snapshot recovery v3 Storage
// A snapshot db may have already been recovered, and the old db should have already been closed in this case, so we should set the backend again.
ci.SetBackend(be)
s1, s2 := be.Size(), be.SizeInUse()
cfg.Logger.Info("recovered v3 backend from snapshot",zap.Int64("backend-size-bytes", s1),zap.String("backend-size", humanize.Bytes(uint64(s1))),zap.Int64("backend-size-in-use-bytes", s2),zap.String("backend-size-in-use", humanize.Bytes(uint64(s2))),)
if beExist {
// TODO: remove kvindex != 0 checking when we do not expect users to upgrade etcd from pre-3.0 release.
kvindex := ci.ConsistentIndex()
if kvindex < snapshot.Metadata.Index {
if kvindex != 0 {
return nil, be, fmt.Errorf("database file (%v index %d) does not match with snapshot (index %d)", cfg.BackendPath(), kvindex, snapshot.Metadata.Index)}
cfg.Logger.Warn("consistent index was never saved",zap.Uint64("snapshot-index", snapshot.Metadata.Index),
)
}
}
} else {
cfg.Logger.Info("No snapshot found. Recovering WAL from scratch!") // No snapshot
}
return snapshot, be, nil
}
bootstrapWALFromSnapshot
The main function of this step is initialization bootstrappedWAL, without wal There is no need to initialize .
var ( bwal *bootstrappedWAL )
if haveWAL {
if err = fileutil.IsDirWriteable(cfg.WALDir()); err != nil {
return nil, fmt.Errorf("cannot write to WAL directory: %v", err)}
bwal = bootstrapWALFromSnapshot(cfg, backend.snapshot)
}

openWALFromSnapshot Read at a given snapshot WAL, And back to WAL、 Its latest hard state and clustering ID, And in WAL All entries that appear after a given snapshot location in . The snapshot must have been saved to WAL, Otherwise, this call will cause panic .
func bootstrapWALFromSnapshot(cfg config.ServerConfig, snapshot *raftpb.Snapshot) *bootstrappedWAL {
wal, st, ents, snap, meta := openWALFromSnapshot(cfg, snapshot)
bwal := &bootstrappedWAL{
lg: cfg.Logger, w: wal, st: st,
ents: ents, snapshot: snap, meta: meta, haveWAL: true,
}
if cfg.ForceNewCluster {
// discard the previously uncommitted entries
bwal.ents = bwal.CommitedEntries()
entries := bwal.NewConfigChangeEntries()
// force commit config change entries
bwal.AppendAndCommitEntries(entries)
cfg.Logger.Info("forcing restart member",zap.String("cluster-id", meta.clusterID.String()),zap.String("local-member-id", meta.nodeID.String()),zap.Uint64("commit-index", bwal.st.Commit),
)
} else {
cfg.Logger.Info("restarting local member",zap.String("cluster-id", meta.clusterID.String()),zap.String("local-member-id", meta.nodeID.String()),zap.Uint64("commit-index", bwal.st.Commit),
)
}
return bwal
}
func openWALFromSnapshot(cfg config.ServerConfig, snapshot *raftpb.Snapshot) (*wal.WAL, *raftpb.HardState, []raftpb.Entry, *raftpb.Snapshot, *snapshotMetadata) {
var walsnap walpb.Snapshot
if snapshot != nil {
// From snapshot data raftpb.Snapshot Extract from Index(raft log index) And term of office
walsnap.Index, walsnap.Term = snapshot.Metadata.Index, snapshot.Metadata.Term
}
repaired := false
for {
w, err := wal.Open(cfg.Logger, cfg.WALDir(), walsnap) // initialization WAL example , And from walsnap
if err != nil {
cfg.Logger.Fatal("failed to open WAL", zap.Error(err)) }
if cfg.UnsafeNoFsync {
w.SetUnsafeNoFsync() }
wmetadata, st, ents, err := w.ReadAll()
if err != nil {
w.Close()
// we can only repair ErrUnexpectedEOF and we never repair twice.
if repaired || err != io.ErrUnexpectedEOF {
cfg.Logger.Fatal("failed to read WAL, cannot be repaired", zap.Error(err))
}
if !wal.Repair(cfg.Logger, cfg.WALDir()) {
cfg.Logger.Fatal("failed to repair WAL", zap.Error(err))
} else {
cfg.Logger.Info("repaired WAL", zap.Error(err))
repaired = true
}
continue
}
var metadata etcdserverpb.Metadata
pbutil.MustUnmarshal(&metadata, wmetadata)
id := types.ID(metadata.NodeID)
cid := types.ID(metadata.ClusterID)
meta := &snapshotMetadata{
clusterID: cid, nodeID: id}
return w, &st, ents, snapshot, meta
}
}
cluster, err := bootstrapCluster(cfg, bwal, prt)
if err != nil {
backend.Close()
return nil, err
}
s, err := bootstrapStorage(cfg, st, backend, bwal, cluster)
if err != nil {
backend.Close()
return nil, err
}
err = cluster.Finalize(cfg, s)
if err != nil {
backend.Close()
return nil, err
}
raft := bootstrapRaft(cfg, cluster, s.wal)
return &bootstrappedServer{
prt: prt,
ss: ss,
storage: s,
cluster: cluster,
raft: raft,
}, nil
}
bootstrappedServer.close
func NewServer(cfg config.ServerConfig) (srv *EtcdServer, err error) {
b, err := bootstrap(cfg)
if err != nil {
return nil, err }
defer func() {
if err != nil {
b.Close() } }()
sstats := stats.NewServerStats(cfg.Name, b.cluster.cl.String())
lstats := stats.NewLeaderStats(cfg.Logger, b.cluster.nodeID.String())
heartbeat := time.Duration(cfg.TickMs) * time.Millisecond
srv = &EtcdServer{
readych: make(chan struct{
}),Cfg: cfg,lgMu: new(sync.RWMutex),
lg: cfg.Logger,errorc: make(chan error, 1),v2store: b.storage.st,
snapshotter: b.ss,r: *b.raft.newRaftNode(b.ss, b.storage.wal.w, b.cluster.cl),
memberId: b.cluster.nodeID,attributes: membership.Attributes{
Name: cfg.Name, ClientURLs: cfg.ClientURLs.StringSlice()},
cluster: b.cluster.cl,stats: sstats,lstats: lstats,
SyncTicker: time.NewTicker(500 * time.Millisecond),peerRt: b.prt,
reqIDGen: idutil.NewGenerator(uint16(b.cluster.nodeID), time.Now()),
AccessController: &AccessController{
CORS: cfg.CORS, HostWhitelist: cfg.HostWhitelist},
consistIndex: b.storage.backend.ci,
firstCommitInTerm: notify.NewNotifier(),clusterVersionChanged: notify.NewNotifier(),
}
serverID.With(prometheus.Labels{
"server_id": b.cluster.nodeID.String()}).Set(1)
srv.cluster.SetVersionChangedNotifier(srv.clusterVersionChanged)
srv.applyV2 = NewApplierV2(cfg.Logger, srv.v2store, srv.cluster)
srv.be = b.storage.backend.be
srv.beHooks = b.storage.backend.beHooks
minTTL := time.Duration((3*cfg.ElectionTicks)/2) * heartbeat
// always recover lessor before kv. When we recover the mvcc.KV it will reattach keys to its leases. If we recover mvcc.KV first, it will attach the keys to the wrong lessor before it recovers.
srv.lessor = lease.NewLessor(srv.Logger(), srv.be, srv.cluster, lease.LessorConfig{
MinLeaseTTL: int64(math.Ceil(minTTL.Seconds())),
CheckpointInterval: cfg.LeaseCheckpointInterval,
CheckpointPersist: cfg.LeaseCheckpointPersist,
ExpiredLeasesRetryInterval: srv.Cfg.ReqTimeout(),
})
tp, err := auth.NewTokenProvider(cfg.Logger, cfg.AuthToken, func(index uint64) <-chan struct{
} {
return srv.applyWait.Wait(index)}, time.Duration(cfg.TokenTTL)*time.Second, )
if err != nil {
cfg.Logger.Warn("failed to create token provider", zap.Error(err))
return nil, err
}
mvccStoreConfig := mvcc.StoreConfig{
CompactionBatchLimit: cfg.CompactionBatchLimit,CompactionSleepInterval: cfg.CompactionSleepInterval,}
srv.kv = mvcc.New(srv.Logger(), srv.be, srv.lessor, mvccStoreConfig)
srv.authStore = auth.NewAuthStore(srv.Logger(), schema.NewAuthBackend(srv.Logger(), srv.be), tp, int(cfg.BcryptCost))
newSrv := srv // since srv == nil in defer if srv is returned as nil
defer func() {
// closing backend without first closing kv can cause
// resumed compactions to fail with closed tx errors
if err != nil {
newSrv.kv.Close() }
}()
if num := cfg.AutoCompactionRetention; num != 0 {
srv.compactor, err = v3compactor.New(cfg.Logger, cfg.AutoCompactionMode, num, srv.kv, srv)
if err != nil {
return nil, err }
srv.compactor.Run()
}
if err = srv.restoreAlarms(); err != nil {
return nil, err }
srv.uberApply = srv.NewUberApplier()
if srv.Cfg.EnableLeaseCheckpoint {
// setting checkpointer enables lease checkpoint feature.
srv.lessor.SetCheckpointer(func(ctx context.Context, cp *pb.LeaseCheckpointRequest) {
srv.raftRequestOnce(ctx, pb.InternalRaftRequest{
LeaseCheckpoint: cp}) })
}
// Set the hook after EtcdServer finishes the initialization to avoid
// the hook being called during the initialization process.
srv.be.SetTxPostLockInsideApplyHook(srv.getTxPostLockInsideApplyHook())
// TODO: move transport initialization near the definition of remote
tr := &rafthttp.Transport{
Logger: cfg.Logger,TLSInfo: cfg.PeerTLSInfo,DialTimeout: cfg.PeerDialTimeout(),
ID: b.cluster.nodeID,URLs: cfg.PeerURLs,ClusterID: b.cluster.cl.ID(),Raft: srv,
Snapshotter: b.ss,ServerStats: sstats,LeaderStats: lstats,ErrorC: srv.errorc,}
if err = tr.Start(); err != nil {
return nil, err }
// add all remotes into transport
for _, m := range b.cluster.remotes {
if m.ID != b.cluster.nodeID {
tr.AddRemote(m.ID, m.PeerURLs) } }
for _, m := range b.cluster.cl.Members() {
if m.ID != b.cluster.nodeID {
tr.AddPeer(m.ID, m.PeerURLs) } }
srv.r.transport = tr
return srv, nil
}
边栏推荐
- Fundamentals of SQL database operation
- Lambda expression learning
- 颠覆你的认知?get和post请求的本质
- Implementation of knowledge consolidation source code 2: TCP server receives and processes half packets and sticky packets
- Global and Chinese markets for patent hole oval devices 2022-2028: Research Report on technology, participants, trends, market size and share
- 脚本生命周期
- 1291_Xshell日志中增加时间戳的功能
- 1291_ Add timestamp function in xshell log
- Explain in simple terms node template parsing error escape is not a function
- Query the number and size of records in each table in MySQL database
猜你喜欢
Yyds dry goods inventory hcie security Day11: preliminary study of firewall dual machine hot standby and vgmp concepts
捷码赋能案例:专业培训、技术支撑,多措并举推动毕业生搭建智慧校园毕设系统

The most detailed and comprehensive update content and all functions of guitar pro 8.0

综合能力测评系统
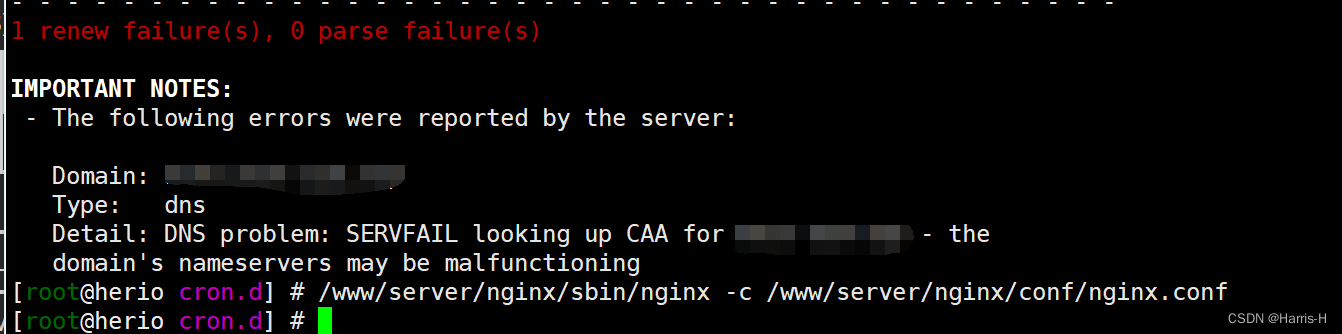
CertBot 更新证书失败解决
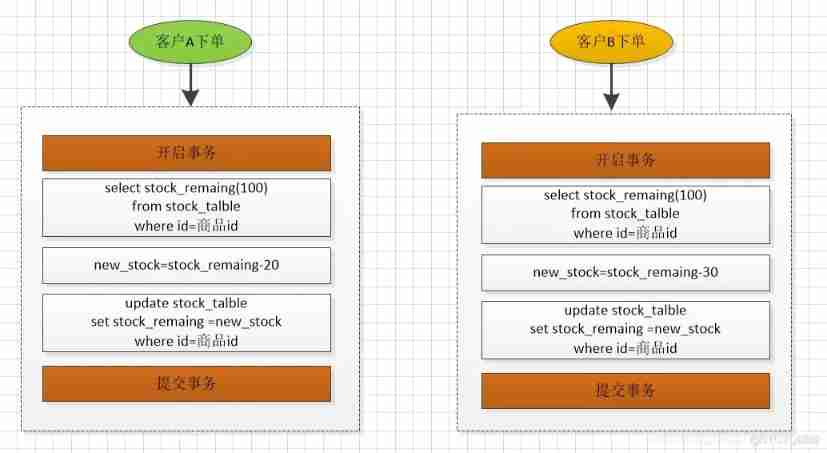
Jd.com 2: how to prevent oversold in the deduction process of commodity inventory?
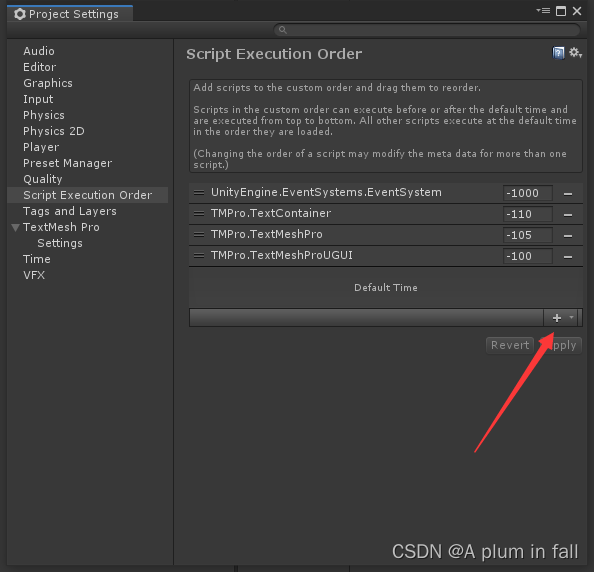
Execution order of scripts bound to game objects
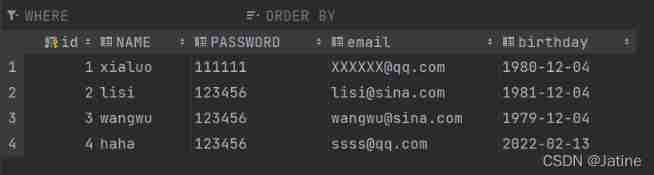
MySQL learning record 13 database connection pool, pooling technology, DBCP, c3p0
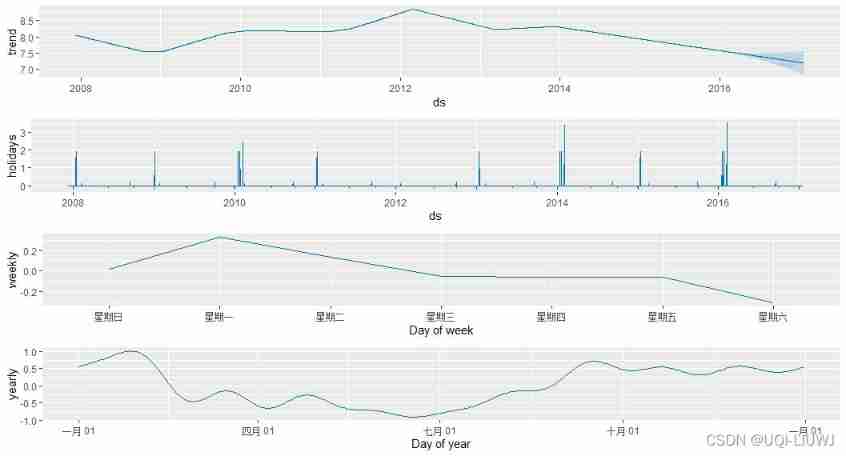
R note prophet
题解:《单词覆盖还原》、《最长连号》、《小玉买文具》、《小玉家的电费》
随机推荐
Global and Chinese markets for patent hole oval devices 2022-2028: Research Report on technology, participants, trends, market size and share
View 工作流程
Comprehensive ability evaluation system
User datagram protocol UDP
Tengine kernel parameters
Global and Chinese market of plasma separator 2022-2028: Research Report on technology, participants, trends, market size and share
SharedPreferences 源码分析
Stable Huawei micro certification, stable Huawei cloud database service practice
绑定在游戏对象上的脚本的执行顺序
Easyrecovery靠谱不收费的数据恢复电脑软件
CADD课程学习(8)-- 化合物库虚拟筛选(Virtual Screening)
C. The Third Problem(找规律)
PTA tiantisai l1-078 teacher Ji's return (15 points) detailed explanation
Overturn your cognition? The nature of get and post requests
Fundamentals of SQL database operation
How does computer nail adjust sound
MySQL transaction isolation level
颠覆你的认知?get和post请求的本质
我想问一下 按照现在mysql-cdc的设计,全量阶段,如果某一个chunk的binlog回填阶段,
Global and Chinese market of rubber wheel wedges 2022-2028: Research Report on technology, participants, trends, market size and share