当前位置:网站首页>Flink kakfa data read and write to Hudi
Flink kakfa data read and write to Hudi
2022-07-06 04:40:00 【wudl5566】
1. Running environment
1.1 edition
| Components | edition |
|---|---|
| hudi | 10.0 |
| flink | 13.5 |
1.2.flink lib Needed jar package
hudi-flink-bundle_2.12-0.10.0.jarflink-sql-connector-kafka_2.12-1.13.5.jarflink-shaded-hadoop-2-uber-2.8.3-10.0.jar
Here are all of them jar package
-rw-r--r-- 1 root root 7802399 1 month 1 08:27 doris-flink-1.0-SNAPSHOT.jar
-rw-r--r-- 1 root root 249571 12 month 27 23:32 flink-connector-jdbc_2.12-1.13.5.jar
-rw-r--r-- 1 root root 359138 1 month 1 10:17 flink-connector-kafka_2.12-1.13.5.jar
-rw-r--r-- 1 hive 1007 92315 12 month 15 08:23 flink-csv-1.13.5.jar
-rw-r--r-- 1 hive 1007 106535830 12 month 15 08:29 flink-dist_2.12-1.13.5.jar
-rw-r--r-- 1 hive 1007 148127 12 month 15 08:23 flink-json-1.13.5.jar
-rw-r--r-- 1 root root 43317025 2 month 6 20:51 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
-rw-r--r-- 1 hive 1007 7709740 12 month 15 06:57 flink-shaded-zookeeper-3.4.14.jar
-rw-r--r-- 1 root root 3674116 2 month 13 14:08 flink-sql-connector-kafka_2.12-1.13.5.jar
-rw-r--r-- 1 hive 1007 35051557 12 month 15 08:28 flink-table_2.12-1.13.5.jar
-rw-r--r-- 1 hive 1007 38613344 12 month 15 08:28 flink-table-blink_2.12-1.13.5.jar
-rw-r--r-- 1 root root 62447468 2 month 6 20:44 hudi-flink-bundle_2.12-0.10.0.jar
-rw-r--r-- 1 root root 17276348 2 month 6 20:51 hudi-hadoop-mr-bundle-0.10.0.jar
-rw-r--r-- 1 root root 1893564 1 month 1 10:17 kafka-clients-2.0.0.jar
-rw-r--r-- 1 hive 1007 207909 12 month 15 06:56 log4j-1.2-api-2.16.0.jar
-rw-r--r-- 1 hive 1007 301892 12 month 15 06:56 log4j-api-2.16.0.jar
-rw-r--r-- 1 hive 1007 1789565 12 month 15 06:56 log4j-core-2.16.0.jar
-rw-r--r-- 1 hive 1007 24258 12 month 15 06:56 log4j-slf4j-impl-2.16.0.jar
-rw-r--r-- 1 root root 724213 12 month 27 23:23 mysql-connector-java-5.1.9.jar
1.3 flink-conf.yaml Of checkpoints To configure
Parameter description
| Parameters | value | explain |
|---|---|---|
| state.backend | rocksdb | State backend Configuration of |
| state.backend.incremental | true | Whether the data saved in the checkpoint is incremental |
| state.checkpoints.dir | hdfs://node01.com:8020/flink/flink-checkpoints | Is used to specify the checkpoint Of data files and meta data Stored directory |
| state.savepoints.dir | hdfs://node01.com:8020/flink-savepoints | SavePoint Storage location |
| classloader.check-leaked-classloader | false | If the user class loader of a job is used after the job terminates , Then the attempt to load the class will fail . This is usually caused by stranded threads or improperly behaved library leaked classloaders , This may also cause other jobs to use classloaders . Only when the leak prevents further jobs from running , Should disable this check . |
| classloader.resolve-order | parent-first | Define the class resolution strategy when loading classes from user code , That is, first check the user code jar(“child-first”) Or the application classpath 【application classpath】(“parent-first”). The default setting indicates first from user code jar Load class , This means user code jar Can contain and load different from Flink Dependencies used ( Pass on ) |
| execution.checkpointing.interval | 3000 | Checkpoint Time interval between , The unit is millisecond . |
# Parameters
state.backend: rocksdb
state.backend.incremental: true
state.checkpoints.dir: hdfs://node01.com:8020/flink/flink-checkpoints
state.savepoints.dir: hdfs://node01.com:8020/flink-savepoints
classloader.check-leaked-classloader: false
classloader.resolve-order: parent-first
execution.checkpointing.interval: 3000
2. scene
kafka ----> flink sql ----> hudi —> flink sql read hudi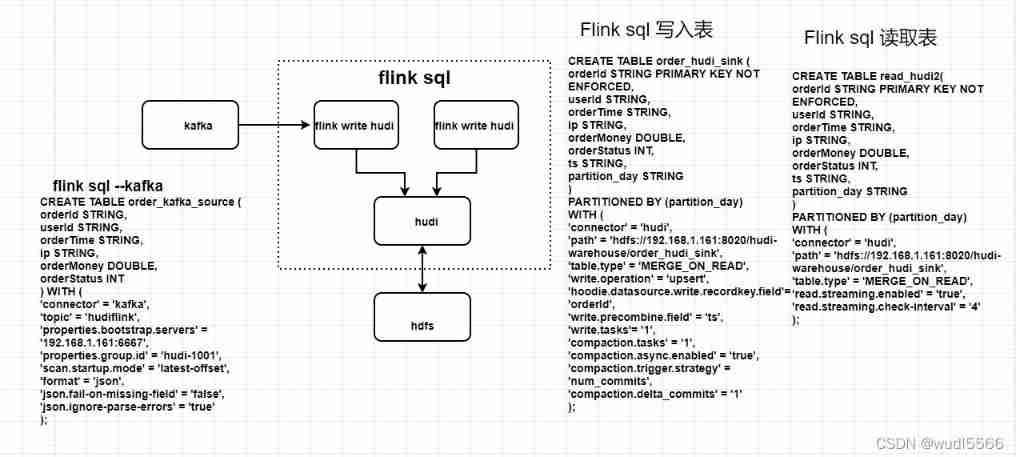
3. flink sql client Client mode
3.1 Enter the client
[[email protected] bin]# ./sql-client.sh embedded -j /opt/module/flink/flink-1.13.5/lib/hudi-flink-bundle_2.12-0.10.0.jar
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set.
3.2 establish kafka surface
Flink SQL> CREATE TABLE order_kafka_source (
> orderId STRING,
> userId STRING,
> orderTime STRING,
> ip STRING,
> orderMoney DOUBLE,
> orderStatus INT
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'hudiflink',
> 'properties.bootstrap.servers' = '192.168.1.161:6667',
> 'properties.group.id' = 'hudi-1001',
> 'scan.startup.mode' = 'latest-offset',
> 'format' = 'json',
> 'json.fail-on-missing-field' = 'false',
> 'json.ignore-parse-errors' = 'true'
> );
[INFO] Execute statement succeed.
3.3 establish hudi Write table
Flink SQL> CREATE TABLE order_hudi_sink (
> orderId STRING PRIMARY KEY NOT ENFORCED,
> userId STRING,
> orderTime STRING,
> ip STRING,
> orderMoney DOUBLE,
> orderStatus INT,
> ts STRING,
> partition_day STRING
> )
> PARTITIONED BY (partition_day)
> WITH (
> 'connector' = 'hudi',
> 'path' = 'hdfs://192.168.1.161:8020/hudi-warehouse/order_hudi_sink',
> 'table.type' = 'MERGE_ON_READ',
> 'write.operation' = 'upsert',
> 'hoodie.datasource.write.recordkey.field'= 'orderId',
> 'write.precombine.field' = 'ts',
> 'write.tasks'= '1',
> 'compaction.tasks' = '1',
> 'compaction.async.enabled' = 'true',
> 'compaction.trigger.strategy' = 'num_commits',
> 'compaction.delta_commits' = '1'
> );
[INFO] Execute statement succeed.
3.4 flink Real time reading table
Flink SQL> CREATE TABLE read_hudi2(
> orderId STRING PRIMARY KEY NOT ENFORCED,
> userId STRING,
> orderTime STRING,
> ip STRING,
> orderMoney DOUBLE,
> orderStatus INT,
> ts STRING,
> partition_day STRING
> )
> PARTITIONED BY (partition_day)
> WITH (
> 'connector' = 'hudi',
> 'path' = 'hdfs://192.168.1.161:8020/hudi-warehouse/order_hudi_sink',
> 'table.type' = 'MERGE_ON_READ',
> 'read.streaming.enabled' = 'true',
> 'read.streaming.check-interval' = '4'
> );
[INFO] Execute statement succeed.
3.5 Real time streaming Insert
Flink SQL> INSERT INTO order_hudi_sink
> SELECT
> orderId, userId, orderTime, ip, orderMoney, orderStatus,
> substring(orderId, 0, 17) AS ts, substring(orderTime, 0, 10) AS partition_day
> FROM order_kafka_source ;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: ea29591aeb04310b88999888226c04b2
Such as :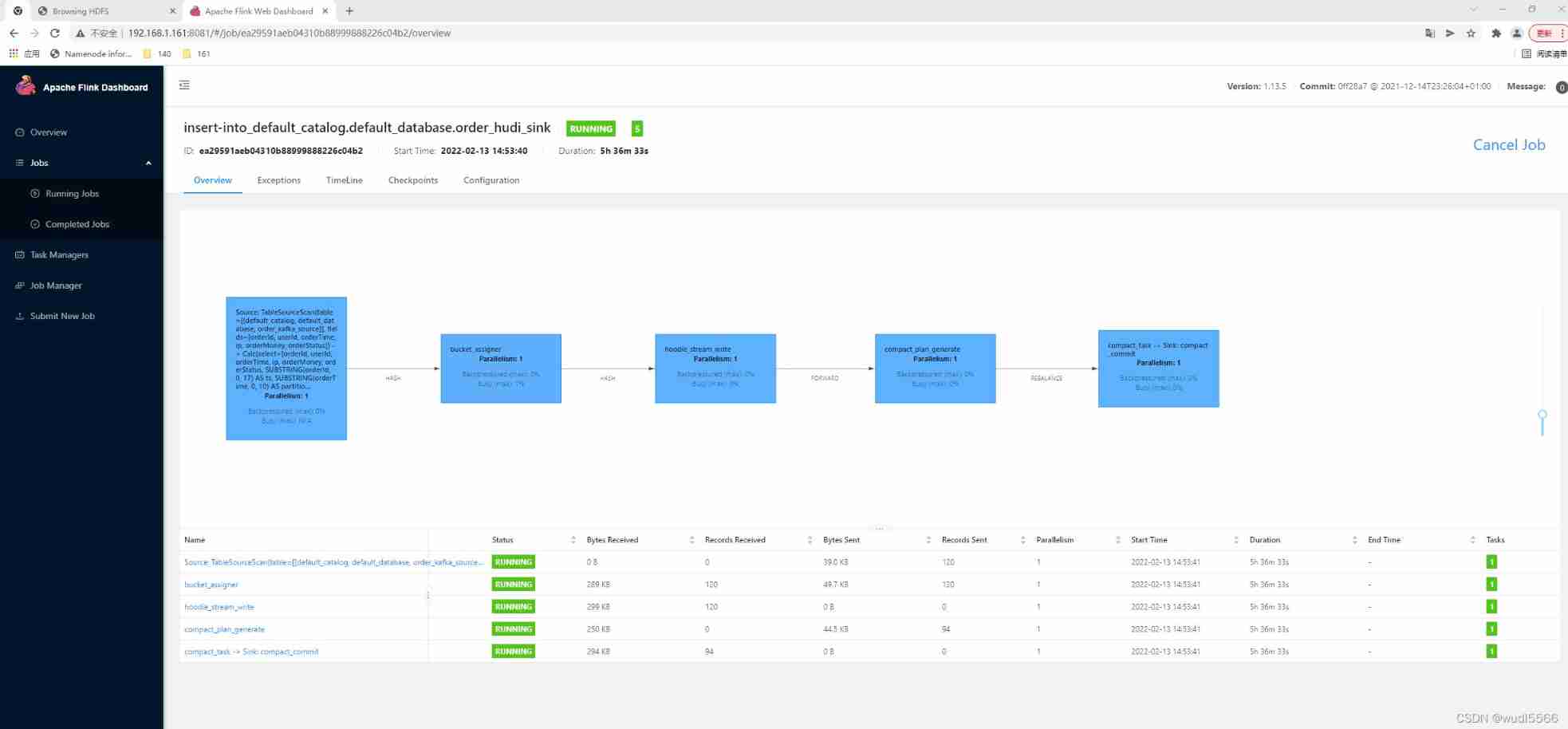
4. result
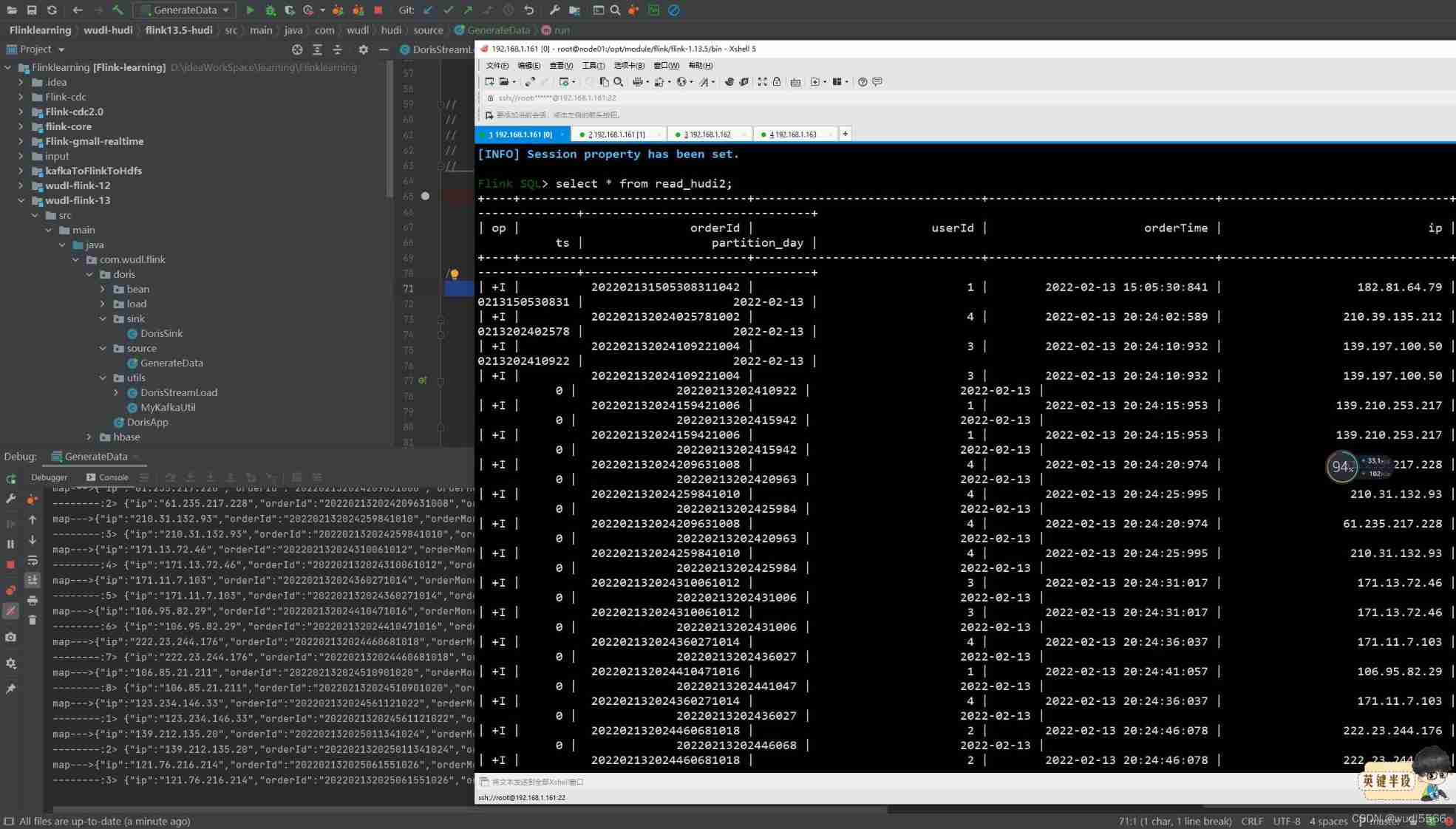
5. Code implementation
package com.wudl.hudi.sink;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
/**
* @author :wudl
* @date :Created in 2022-02-07 22:56
* @description:
* @modified By:
* @version: 1.0
*/
public class FlinkKafkaWriteHudi {
public static void main(String[] args) throws Exception {
// 1- Get the table execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO: Write data to... Due to increment Hudi surface , So you need to start Flink Checkpoint checkpoint
env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // Set streaming mode
.build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
// 1.1 Turn on CK
env.enableCheckpointing(5000L);
env.getCheckpointConfig().setCheckpointTimeout(10000L);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// normal Cancel When the task , For the last time CK
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// Restart strategy
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L));
// State backend
env.setStateBackend(new FsStateBackend("hdfs://192.168.1.161:8020/flink-hudi/ck"));
// Set access HDFS Username
System.setProperty("HADOOP_USER_NAME", "root");
// 2- Create input table ,TODO: from Kafka Consumption data
tableEnv.executeSql(
"CREATE TABLE order_kafka_source (\n" +
" orderId STRING,\n" +
" userId STRING,\n" +
" orderTime STRING,\n" +
" ip STRING,\n" +
" orderMoney DOUBLE,\n" +
" orderStatus INT\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'hudiflink',\n" +
" 'properties.bootstrap.servers' = '192.168.1.161:6667',\n" +
" 'properties.group.id' = 'gid-1002',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")"
);
// 3- Conversion data : have access to SQL, It can also be Table API
Table etlTable = tableEnv
.from("order_kafka_source")
// Add fields :Hudi Table data merge fields , Time stamp , "orderId": "20211122103434136000001" -> 20211122103434136
.addColumns(
$("orderId").substring(0, 17).as("ts")
)
// Add fields :Hudi Table partition fields , "orderTime": "2021-11-22 10:34:34.136" -> 021-11-22
.addColumns(
$("orderTime").substring(0, 10).as("partition_day")
);
tableEnv.createTemporaryView("view_order", etlTable);
// 4- Create output table ,TODO: Related to Hudi surface , Appoint Hudi The name of the table , Storage path , Field name and other information
tableEnv.executeSql(
"CREATE TABLE order_hudi_sink (\n" +
" orderId STRING PRIMARY KEY NOT ENFORCED,\n" +
" userId STRING,\n" +
" orderTime STRING,\n" +
" ip STRING,\n" +
" orderMoney DOUBLE,\n" +
" orderStatus INT,\n" +
" ts STRING,\n" +
" partition_day STRING\n" +
")\n" +
"PARTITIONED BY (partition_day)\n" +
"WITH (\n" +
" 'connector' = 'hudi',\n" +
// " 'path' = 'file:///D:/flink_hudi_order',\n" +
" 'path' = 'hdfs://192.168.1.161:8020/hudi-warehouse/order_hudi_sink' ,\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'write.operation' = 'upsert',\n" +
" 'hoodie.datasource.write.recordkey.field'= 'orderId',\n" +
" 'write.precombine.field' = 'ts',\n" +
" 'write.tasks'= '1'\n" +
")"
);
tableEnv.executeSql("select *from order_hudi_sink").print();
// 5- Through sub query , Write data to the output table
tableEnv.executeSql(
"INSERT INTO order_hudi_sink " +
"SELECT orderId, userId, orderTime, ip, orderMoney, orderStatus, ts, partition_day FROM view_order"
);
}
}
边栏推荐
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- Word cover underline
- [network] channel attention network and spatial attention network
- SQL注入漏洞(MSSQL注入)
- [face recognition series] | realize automatic makeup
- English Vocabulary - life scene memory method
- Knowledge consolidation source code implementation 3: buffer ringbuffer
- Microservice resource address
- Use sentinel to interface locally
- Bubble sort
猜你喜欢

Lombok原理和同时使⽤@Data和@Builder 的坑
VNCTF2022 WriteUp

Database - MySQL storage engine (deadlock)
电脑钉钉怎么调整声音
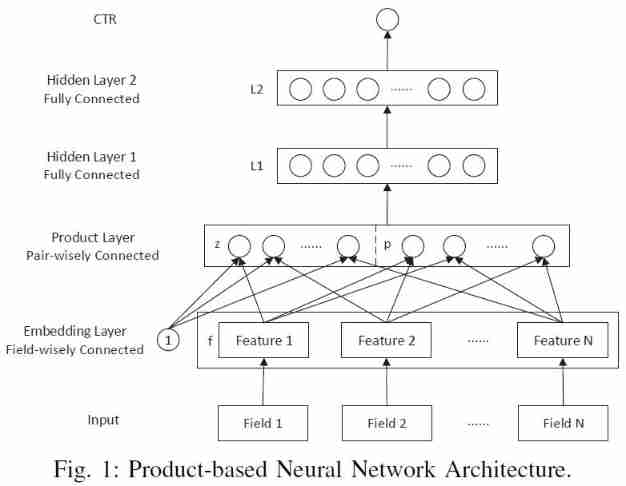
Recommendation system (IX) PNN model (product based neural networks)
CertBot 更新证书失败解决
When debugging after pycharm remote server is connected, trying to add breakpoint to file that does not exist: /data appears_ sda/d:/segmentation
English Vocabulary - life scene memory method
满足多元需求:捷码打造3大一站式开发套餐,助力高效开发
解决“C2001:常量中有换行符“编译问题
随机推荐
比尔·盖茨晒18岁个人简历,48年前期望年薪1.2万美元
Patent | subject classification method based on graph convolution neural network fusion of multiple human brain maps
word封面下划线
Platformio create libopencm3 + FreeRTOS project
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
win10电脑系统里的视频不显示缩略图
[try to hack] John hash cracking tool
How does computer nail adjust sound
[Zhao Yuqiang] deploy kubernetes cluster with binary package
How to realize automatic playback of H5 video
One question per day (Mathematics)
cdc 能全量拉去oracle 表嘛
也算是學習中的小總結
优秀PM必须经历这3层蜕变!
Jd.com 2: how to prevent oversold in the deduction process of commodity inventory?
In depth MySQL transactions, stored procedures and triggers
Quatre méthodes de redis pour dépanner les grandes clés sont nécessaires pour optimiser
捷码赋能案例:专业培训、技术支撑,多措并举推动毕业生搭建智慧校园毕设系统
Can CDC pull the Oracle table in full
Coreldraw2022 new version new function introduction cdr2022