当前位置:网站首页>【重新理解通信模型】Reactor 模式在 Redis 和 Kafka 中的应用
【重新理解通信模型】Reactor 模式在 Redis 和 Kafka 中的应用
2022-07-07 15:40:00 【林立可】
重新理解通信模型
每个框架都有自己的通信模型,用于处理网络事件。只是不同的框架依据自身的侧重点,对网络通信的要求和实现方式不一样。
我们的网络通信模式发展历程:
- 单线程:一次只能处理一个请求,其他请求阻塞,处理效率低;
- 多线程:一个请求一个连接,大量的创建线程,带来线程切换和维护问题,系统复杂度高;
- 线程池:线程复用,线程管理,但是线程池资源有限,也有线程等待问题。
- Reactor:现代高性能网络 IO 模式,利用事件驱动机制。
0,Reactor
Reactor 模式,反应堆模式,是一种以事件驱动的网络请求处理模式,在许多高性能网络通信框架中都有实现。
在 Reactor 模式中,将网络处理请求分为一个个事件,具体包括读事件、写事件、连接事件。
该模式下,有三个关键组件:reactor、acceptor、handler,分别对应着监听并分发请求,连接请求和处理请求。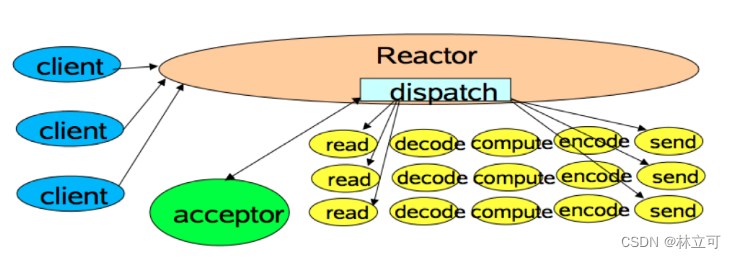
基本流程:客户端请求首先都被 reactor 接收,reactor 根据请求类型将请求分发,对于连接请求会分发到 acceptor 组件,他时刻监听者网络状态,对于读请求和写请求则交给 handler 处理。
同时,按照处理方式的不同,reactor 模式又可以分为多种:
单 reactror 单线程:一个 reactor,一个 handler;
缺点:单线程,处理能力慢(相较于这三者来说),redis6.0 以前采用这种方式,比如 keys * 就容易阻塞
单 reactror 多线程:一个 reactor,handler 将请求丢到 worker 线程池,读写事件由线程池处理
充分利用多核能力,redis6.0 引入的多线程机制就是这种模式,但是 redis 具体命令执行的逻辑仍然是单线程。
多 reactor 多线程:mainReactor 负责 acceptor 处理,subReactors 负责 handler 处理
可以看到性能非常强悍了,kafka,netty 都有使用到这种模式。
1,Redis 中的 Reactor
redis 中 reactor 模式的体现是在 IO 多路复用基础上实现的,具体来说 redis 针对不同 os 的 IO 多路复用机制实现了不同的 reactor 模型,比如 mac os 的 kqueue;我们主要说下 Redis 基于 Linux 的 epoll 函数实现的 reactor 模式。注意:只有 epoll 采用了事件驱动的思想。
那 redis 是如何复用 epoll 的呢?
首先通过一个 while 循环不断监听网络事件,根据事件的不同执行不同的处理策略。主要有三类事件,空事件,继续轮询;时间事件,调用时间处理函数;读写事件,这时就需要调用 os 的 io 多路复用机制执行事件捕获了。这里简单提一下多路复用函数 epoll 的工作流程:
epoll 首先通过 epoll_ctl 函数注册一个文件描述符,并监听其他文件描述符状态,如果某个 fd 就绪,便会采用回调机制 callback,激活这个 fd 并把它放到就绪列表中,然后由具体的线程处理。
2,Kafka 中的 Reactor
kafaka 中也依据 Reactor 模式设计了自己的网络通信框架,底层使用 NIO 中的 selector 函数。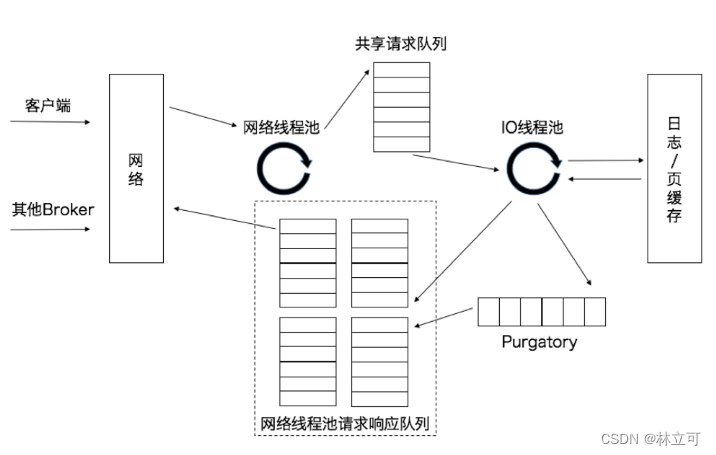
首先,broker 中有个 stockerserver 会监听并分派请求,acceptor 处理连接请求,并轮旋选择一个 processor 处理这个连接。这个网络线程处理由参数 num.network.threads=3 控制。然后在 IO 线程中由 work 线程具体执行,num.io.threads=8。执行完之后,会将 reponse 放到响应队列中,然后返回到客户端。其中,每个网络线程都有自己的响应队列。
除此之外,kafka 增加了一个缓存层,RequestChannel,用来缓存那些延时请求,用来处理设置了 ack=all 的 produce 请求
源码中的一些细节:
#SocketServer,管理了两套 acceptor,processor,RequestChannel;包括数据请求 data-plane,控制请求 control-plane;
#KafkaRequestHandlerPool,IO 线程池,实际处理请求的线程,KafkaRequestHandler 匹配并处理不同的请求。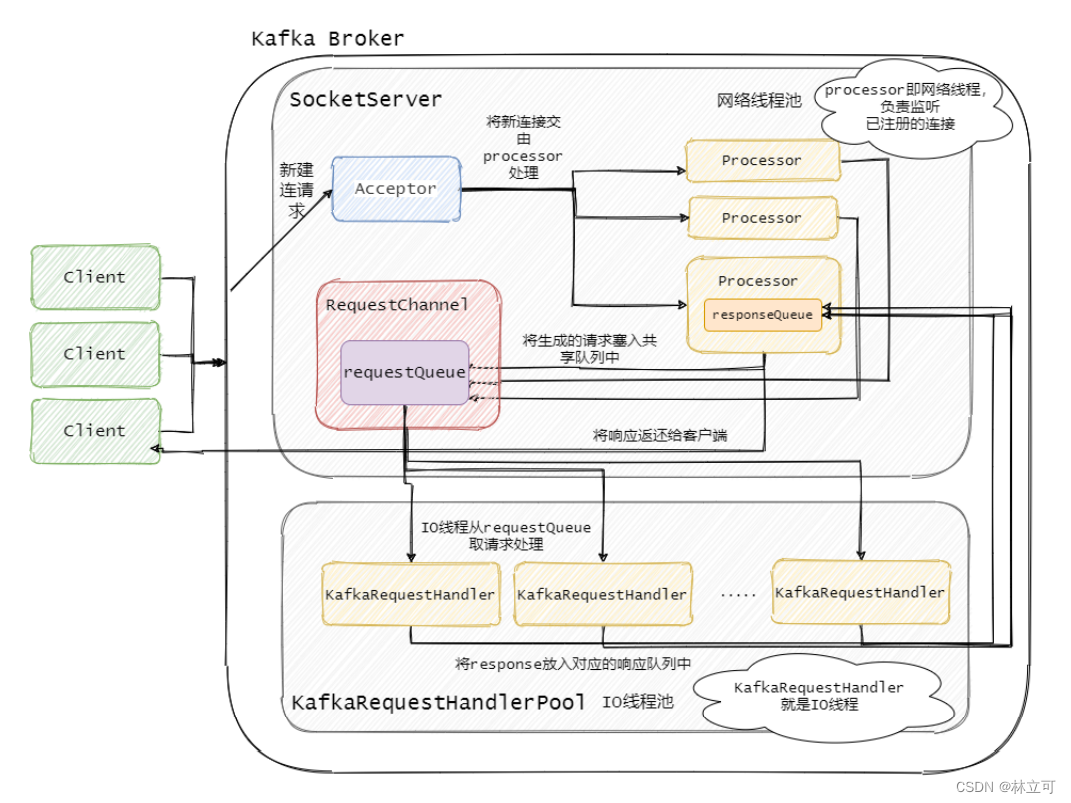
kafka 的请求过程就是网络通信的过程,这里再提一下,为了处理不同的请求,kafka 将请求设置了优先级。分为
数据请求:如 produce 请求,将消息写入到磁盘;fetch 请求,从磁盘或缓存页拉取消息
控制请求:如更新副本及 ISR 的 leaderAndlsr 请求,以及勒令副本下线的 stopReplica 请求等
请求优先级的好处是,可以优先处理部分请求,防止无效的请求处理。比如,在删除主题时,我们会使用 stopreplica 请求,这样即便是 ack=all 的情况下,也无需等待 ack 全部完成,即可执行删除请求,加快了处理速度,避免了无效操作。实现机制是,启动上面提到的两套请求处理模型,并配置不同的 listeners 监听该请求,然后显示指定。
参考链接:
边栏推荐
- 【饭谈】那些看似为公司着想,实际却很自私的故事 (一:造轮子)
- DNS series (I): why does the updated DNS record not take effect?
- LeetCode 648(C#)
- PLC:自动纠正数据集噪声,来洗洗数据集吧 | ICLR 2021 Spotlight
- L1-027 出租(Lua)
- 麒麟信安加入宁夏商用密码协会
- 责任链模式 - Unity
- Flask搭建api服务
- Flask build API service SQL configuration file
- A tour of grpc:03 - proto serialization / deserialization
猜你喜欢
![[video / audio data processing] Shanghai daoning brings you elecard download, trial and tutorial](/img/14/4e7ebfb1ed5b99f8377af9d17d2177.jpg)
[video / audio data processing] Shanghai daoning brings you elecard download, trial and tutorial
赋能智慧电力建设 | 麒麟信安高可用集群管理系统,保障用户关键业务连续性
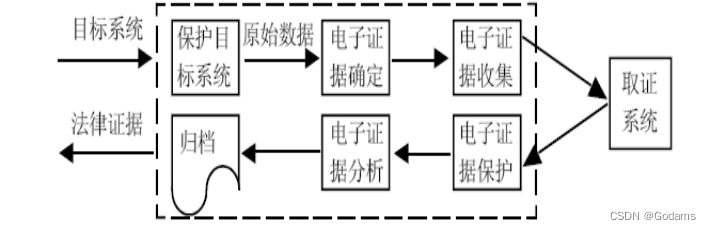
【信息安全法律法规】复习篇
![[Seaborn] combination chart: facetgrid, jointgrid, pairgrid](/img/89/a7cf40fb3a7622cb78ea1b92ffd2fb.png)
[Seaborn] combination chart: facetgrid, jointgrid, pairgrid
Mrs offline data analysis: process OBS data through Flink job
自定义View必备知识,Android研发岗必问30+道高级面试题

《世界粮食安全和营养状况》报告发布:2021年全球饥饿人口增至8.28亿

With the latest Alibaba P7 technology system, mom doesn't have to worry about me looking for a job anymore

Sator a lancé le jeu web 3 "satorspace" et a lancé huobi

第3章业务功能开发(安全退出)
随机推荐
AI来搞财富分配比人更公平?来自DeepMind的多人博弈游戏研究
99% of users often make mistakes in power Bi cloud reports
Mrs offline data analysis: process OBS data through Flink job
电脑无法加域,ping域名显示为公网IP,这是什么问题?怎么解决?
【黄啊码】为什么我建议您选择go,而不选择php?
Problems encountered in Jenkins' release of H5 developed by uniapp
数值 - number(Lua)
Nerf: the ultimate replacement for deepfake?
Flash build API service
Flash build API Service - generate API documents
【可信计算】第十三次课:TPM扩展授权与密钥管理
Sator a lancé le jeu web 3 "satorspace" et a lancé huobi
专精特新软件开发类企业实力指数发布,麒麟信安荣誉登榜
【网络攻防原理与技术】第6章:特洛伊木马
Several best practices for managing VDI
【视频/音频数据处理】上海道宁为您带来Elecard下载、试用、教程
策略模式 - Unity
L1-027 出租(Lua)
SIGGRAPH 2022最佳技术论文奖重磅出炉!北大陈宝权团队获荣誉提名
管理VDI的几个最佳实践