当前位置:网站首页>Statistical knowledge required by data analysts
Statistical knowledge required by data analysts
2022-06-11 04:14:00 【Xinyi 2002】
This paper describes five basic statistical concepts that data analysts should understand : Statistical characteristics 、 A probability distribution 、 Dimension reduction 、 Oversampling / Undersampling 、 Bayesian statistical methods .
From a high point of view , Statistics is a technology that uses mathematical theory to analyze data . A basic visual form like a histogram , Will give you more comprehensive information . however , Through statistics, we can operate the data in a more information driven and targeted way . The mathematical theories involved help us form specific conclusions of the data , Not just guessing .
Using statistics , We can go deeper 、 Take a closer look at how the data is accurately organized , And based on this organizational structure , How to apply other related technologies in the best form to obtain more information . today , Let's take a look at what data analysts need to know 5 A basic statistical concept , And how to apply it effectively .
Characteristic statistics

Characteristic statistics is probably the most commonly used statistical concept in data science . It's a statistical technique you often use when studying data sets , Include deviation 、 variance 、 Average 、 Median 、 percentage wait . It's easy to understand feature statistics and implement them in code . Please look at the chart below. :

Above picture , The middle line represents the median of the data . The median is used in the mean , Because it is more robust to outliers . The first quartile is essentially the twenty fifth quartile , In the data 25% Below this value . The third quartile is the 75th quartile , In the data 75% Below this value . The maximum and minimum values represent the upper and lower ends of the data range .
The box diagram well illustrates the role of basic statistical features :
When the box chart is short , This means that many data points are similar , Because many values are distributed in a very small range ;
When the box diagram is high , This means that most data points are very different , Because these values are widely distributed ;
If the median is close to the bottom , Then most of the data has lower values . If the median is closer to the top , Then most data have higher values . Basically , If the median line is not in the middle of the box , So it's skewed data ;
If the lines at the top and bottom of the box are very long, it means that the data has high standard deviation and variance , It means that these values are scattered , And it changes a lot . If there is a long line on one side of the frame , The other side is not long , Then the data may change greatly in only one direction
A probability distribution

We can define probability as the probability that some events will happen , Expressed as a percentage . In the field of Data Science , This is usually quantified to 0 To 1 Within the range of , among 0 Indicates that the event is certain not to occur , and 1 Indicates that the event is certain to occur . that , Probability distribution is a function of the probability of all possible values . Please look at the chart below. :



Common probability distributions , Uniform distribution ( On )、 Normal distribution ( middle )、 Poisson distribution ( Next ):
Uniform distribution is the most basic way of probability distribution . It has a value that only appears in a certain range , And beyond that range are 0. We can also consider it as a variable with two classifications :0 Or another value . Categorical variables may have division 0 Multiple values other than , But we can still visualize it as multiple uniformly distributed piecewise functions .
Normal distribution , Also known as Gaussian distribution , It is defined by its mean and standard deviation . The average value is distributed back and forth in space , The standard deviation controls its distribution and diffusion range . The main difference from other distribution methods is , The standard deviation is the same in all directions . therefore , Through Gaussian distribution , We know the average value of the data set and the diffusion distribution of the data , That is, it expands on a wide range , It is mainly concentrated around a few values .
Poisson distribution is similar to normal distribution , But there is a skew rate . Like a normal distribution , When the skewness value is low , Poisson distribution has relatively uniform diffusion in all directions . however , When the skewness value is very large , The diffusion of our data in different directions will be different . In one direction , The diffusion of data is very high , And in the other direction , The degree of diffusion is very low .
If you encounter a Gaussian distribution , So we know there are many algorithms , By default, Garth distribution will perform well , So you should first find those algorithms . If it's a Poisson distribution , We must be very careful , Choose an algorithm that is robust to changes in space expansion .
Dimension reduction

The term dimensionality reduction can be understood intuitively , It means reducing the dimension of a data set . In Data Science , This is the number of characteristic variables . Please look at the chart below. :

The cube in the figure above represents our dataset , It has 3 Dimensions , in total 1000 A little bit . With current computing power , Calculation 1000 One point is easy , But on a larger scale , You'll be in trouble . However , Just look at our data from a two-dimensional perspective , For example, from the angle of one side of the cube , You can see that it's easy to divide all the colors . By reducing dimensions , We will 3D The data is presented to 2D In the plane , This effectively reduces the number of points we need to calculate to 100 individual , It greatly saves the amount of calculation .
Another way is that we can reduce the dimension by feature pruning . Use this method , It is not important for the analysis that we delete any features we see . for example , After studying the data set , We may find that , stay 10 Of the features , Yes 7 Features have a high correlation with the output , Others 3 One has a very low correlation . that , this 3 A low correlation feature may not be worth calculating , We may just be able to Remove them from the analysis without affecting the output .
The most common statistical technique for dimensionality reduction is PCA, It essentially creates a vector representation of features , It shows their importance to the output , Correlation .PCA It can be used for the above two dimensionality reduction methods .
Oversampling and undersampling

Oversampling and undersampling are techniques for classification problems . for example , We have 1 Taxonomic 2000 Samples , But the first 2 There are only 200 Samples . This will set aside many machine learning techniques we try and use to model and predict data . that , Oversampling and undersampling can cope with this situation . Please look at the chart below. :
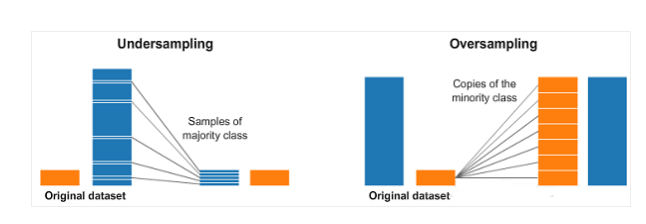
On the left and right in the figure above , The blue category has more samples than the orange category . under these circumstances , We have 2 A preprocessing option , It can help machine learning model training .
Under sampling means that we will only select some data from the classification with many samples , And try to use as many classified samples as possible . This choice should be to maintain the probability distribution of classification . We just make the data set more balanced by less sampling .
Oversampling means that we are going to create a few copies of the classification , So as to have the same number of samples as most classifications . Copies will be made to maintain the distribution of a few categories . We just make the data set more balanced without getting more data .
Bayesian Statistics

Fully understand why when we use Bayesian Statistics , It is required to first understand the failure of frequency statistics . Most people are hearing “ probability ” When it's a word , Frequency statistics is the first type of statistics that comes to mind . It involves the application of some mathematical theories to the analysis of the probability of an event , To be clear , The only data we calculate is a priori data (prior data).

Suppose I give you a dice , Ask you to throw it 6 What's the probability of a dot , Most people would say one in six .
however , If someone gives you a specific die, you can always roll it 6 A little bit ? Because frequency analysis only considers previous data , And the factors that give you cheating dice are not taken into account .
Bayesian statistics does take this into account , We can illustrate it by Bayes rule :

The probability in the equation P(H) It's basically our frequency analysis , Given the previous data on the probability of an event . In the equation P(E|H) Called possibility , According to the information from frequency analysis , In essence, it is the probability that the phenomenon is correct . for example , If you're going to roll the dice 10000 Time , And before 1000 Every time I throw 6 A little bit , Then you will be very confident that the dice cheated .
If the frequency analysis is done very well , Then we will be very confident that , guess 6 This point is correct . meanwhile , If dice cheating is true , Or not based on its own a priori probability and frequency analysis , We will also consider cheating . As you can see from the equation , Bayesian statistics takes everything into account . When you think the previous data is not a good representation of future data and results , We should use Bayesian statistics .
author :George Seif
Long press attention - About data analysis and visualization - Set to star , Dry goods express
NO.1
Previous recommendation
Historical articles
One line of code makes a data analysis crosstab , It's so convenient
The most complete arrangement !37 individual Python Web Development framework summary
Linux Operational prerequisites 150 An order , Speed collection ~
Decision tree 、 Random forests 、bagging、boosting、Adaboost、GBDT、XGBoost summary
Share 、 Collection 、 give the thumbs-up 、 I'm looking at the arrangement ?




边栏推荐
- 合理使用线程池以及线程变量
- 使用工具类按一定规则读取Excel文件
- It's 2022. When will the "module freedom" be realized?
- 域名解析耗时是什么?域名解析耗时影响因素有哪些?
- Linq. pdf
- SQL injection correlation analysis
- June 10, 2022: Captain Shu crosses a sweet potato field from north to South (m long from north to South and N wide from east to West). The sweet potato field is divided into 1x1 squares. He can start
- Unity prefab scene conflict merge tool unityyamlmerge
- 如何检查域名解析是否生效?
- Market prospect analysis and Research Report of engraving laser in 2022
猜你喜欢

Zhongang Mining: fluorochemical industry is the main consumption field of fluorite

A - Eddy‘s AC难题(C语言)

Vulkan-官方示例解读-RayTracing

2022-06-10:薯队长从北向南穿过一片红薯地(南北长M,东西宽N),红薯地被划分为1x1的方格, 他可以从北边的任何一个格子出发,到达南边的任何一个格子, 但每一步只能走到东南、正南、西南方向的
Eth relay interface

Watson K's Secret Diary

Matlab reports an error when trying to use * * * as a function problem, and tries to execute script PCA as a function:
华生·K的秘密日记

Composition and configuration of GPS Beidou clock synchronization (satellite time synchronization system) in power plant

Some differences between people
随机推荐
数据分析师必知必会的统计学知识
七个好用的装饰器
Fundamentals of embedded audio processing
Market prospect analysis and Research Report of digital line scan camera in 2022
Pictures that make people feel calm and warm
B - 刷墙 (C语言)
How to invest in programming knowledge and reduce the impact of knowledge failure
三层带防护内网红队靶场
Market prospect analysis and Research Report of Ethernet scanner in 2022
Grandpa simayan told you what is called inside roll!
Safe and borderless, Guanghe tongdai 5g module +ai intelligent security solution shines at CPSE Expo
Code replicates CSRF attack and resolves it
[激光器原理与应用-2]:国内激光器重点品牌
Market prospect analysis and Research Report of programmable digital temperature regulator in 2022
游戏数学: 计算屏幕点中的平面上的点(上帝视角)
A.前缀极差(C语言)
This artifact is highly recommended. One line command will convert the web page to PDF!
Market prospect analysis and Research Report of seed laser in 2022
ESP series module burning firmware
June 10, 2022: Captain Shu crosses a sweet potato field from north to South (m long from north to South and N wide from east to West). The sweet potato field is divided into 1x1 squares. He can start