当前位置:网站首页>自然语言处理系列(二)——使用RNN搭建字符级语言模型
自然语言处理系列(二)——使用RNN搭建字符级语言模型
2022-07-02 09:42:00 【raelum】
一、任务背景
本文的任务主要来源于PyTorch的官方教程,即给定各国人名的数据集,你需要训练出一个RNN,它能够根据输入的人名来判断这个人来自哪个国家(分类任务)。
数据集是一个 names 文件夹,里面包含了 18 18 18 个文本文档,均以 [Language].txt 命名。每个文本文档中,每一行都是该语种下的一个(常见)人名。
需要注意的是,官方给的数据集疑似存在错误(爬虫没爬干净) ,在 Russian.txt 文件中,第 7941 ∼ 7964 7941\sim7964 7941∼7964 行出现了 To The First Page 字样,很显然这不是一个人名。此外,第 4395 , 5236 , 5255 4395,5236,5255 4395,5236,5255 行的人名均以 , 结尾(我想俄罗斯人的名字应该不会以逗号结尾吧?)。
博主已经帮大家修正了这个数据集,下载地址(所需积分0)。
不同于官方教程,在本篇文章中,博主会根据自己的理解重构代码,使其变得通俗易懂。
二、数据预处理
首先,我们需要构造一个字典,它的格式为:{language: [names ...]}。
因为人名均由Unicode字符组成,我们需要先将其转化为ASCII字符:
import unicodedata
import string
# 转化后的人名由大小写字母和空格字符,单引号字符组成
all_letters = string.ascii_letters + " '"
def unicodeToAscii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn' and c in all_letters)
print(unicodeToAscii('Ślusàrski'))
# Slusarski
构造字典:
import os
filenames = os.listdir('names')
data = dict()
for filename in filenames:
# 注意需要以utf-8格式打开
with open(f'names/{
filename}', encoding='utf-8') as f:
# 需要去掉filename中的.txt后缀
data[filename[:-4]] = [unicodeToAscii(name) for name in f.readlines()]
all_categories = list(data.keys())
print(all_categories)
# ['Arabic', 'Chinese', 'Czech', 'Dutch', 'English', 'French', 'German', 'Greek', 'Irish', 'Italian', 'Japanese', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Scottish', 'Spanish', 'Vietnamese']
print(data['Arabic'][:6])
# ['Khoury', 'Nahas', 'Daher', 'Gerges', 'Nazari', 'Maalouf']
从下面的输出结果可以看出,数据集一共有 18 类,并且每一类中的数据个数也都不同:
print(len(all_categories))
# 18
print([len(data[category]) for category in all_categories])
# [2000, 268, 519, 297, 3668, 277, 724, 203, 232, 709, 991, 94, 139, 74, 9384, 100, 298, 73]
神经网络无法直接处理字母,因此我们需要先将字母转化成对应的 One-Hot 向量:
import torch
import torch.nn.functional as F
def letterToTensor(letter):
# 获取letter在all_letters中的索引
letter_idx = torch.tensor(all_letters.index(letter))
return F.one_hot(letter_idx, num_classes=len(all_letters))
r = letterToTensor("c")
print(r)
# tensor([0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0])
向量长度为 54,这是因为有26个小写字母+26个大写字母+空格字符+单引号字符。
接下来我们需要将完整的单词(人名)编码成张量。单词中的每一个字母代表一个时间步,因此一个完整的单词可以看作是一个序列。由于单词的长度各不相同,因此我们把一个单词看作一个 batch,从而单词应是形状为 (sequence_length, batch_size, features) = (sequence_length, 1, 54) 的张量。
def nameToTensor(name):
result = torch.zeros(len(name), len(all_letters))
for i in range(len(name)):
result[i] = letterToTensor(name[i])
return result.unsqueeze(1)
print(nameToTensor('ab'))
# tensor([[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0.]],
#
# [[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0.]]])
print(nameToTensor('abcd').size())
# torch.Size([4, 1, 54])
因为我们已经将一个单词视为了一个batch,所以不再使用DataLoader去构造迭代器,而是采用随机采样的方法去抽取数据进行训练。
三、模型搭建与训练
我们使用PyTorch中的 nn.RNN 模块来搭建单隐层单向RNN:
import torch.nn as nn
class RNN(nn.Module):
def __init__(self):
super().__init__()
self.rnn = nn.RNN(
input_size=54,
# 128是随便选的,也可以选择其他数值
hidden_size=128,
)
# 18分类任务,所以最后一层有18个神经元
self.out = nn.Linear(128, 18)
def forward(self, x):
# None代表全零初始化隐状态
output, h_n = self.rnn(x, None)
# output[-1]是最后时刻输出的隐状态,等同于h_n[0]
return self.out(output[-1])
考虑到不同类别的样本个数不同(相差较大),并且我们已经将一个单词视为了一个batch,因此使用DataLoader会显得较为困难。这里保持和官方教程一样的做法,即每次随机从数据集 data 中抽取一个 category,再从 category 中随机抽取一个 name 投喂到RNN中。
import random
def random_sample():
category = random.choice(all_categories)
name = random.choice(data[category])
return category, name
print(random_sample())
# ('Irish', "O'Kane")
我们选择在GPU上进行训练,选择交叉熵损失和SGD优化器:
LR = 1e-3 # 学习率
N_ITERS = 10**5 # 训练多少个iteration
device = 'cuda' if torch.cuda.is_available() else 'cpu'
rnn = RNN()
rnn.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(rnn.parameters(), lr=LR, momentum=0.9)
train_loss = []
def train(model, criterion, optimizer):
model.train()
avg_loss = 0
for iteration in range(N_ITERS):
category, name = random_sample()
# 将name转化成数字
X = nameToTensor(name).to(device)
# 因为output的形状是(1,18),所以target的形状必须为(1,)而非标量
target = torch.tensor([all_categories.index(category)]).to(device)
# 正向传播
output = model(X)
loss = criterion(output, target)
avg_loss += loss
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每隔1000个iteration输出一次平均loss并保存
if (iteration + 1) % 1000 == 0:
avg_loss /= 1000
train_loss.append(avg_loss.item())
print(f"Iteration: [{
iteration + 1}/{
N_ITERS}] | Train Loss: {
avg_loss:.4f}")
avg_loss = 0
训练完成后,绘制损失函数的曲线:
import numpy as np
import matplotlib.pyplot as plt
plt.plot(np.arange(1, N_ITERS + 1, 1000), train_loss)
plt.ylabel('Train Loss')
plt.xlabel('Iteration')
plt.show()
为了保证结果的可复现性,我们需要设置全局种子:
def setup_seed(seed):
random.seed(seed) # 为random库设置种子
np.random.seed(seed) # 为numpy库设置种子
torch.manual_seed(seed) # 为Pytorch-CPU设置种子
torch.cuda.manual_seed(seed) # 为当前GPU设置种子
torch.cuda.manual_seed_all(seed) # 为所有GPU设置种子
设置种子为 42,损失曲线变化图如下:

从上图可以看出,模型损失在第 70000 70000 70000 个 iteration 左右时达到了最小。不过这里为了方便起见,我们采用最后得到的模型用来测试。
四、模型测试
在训练过程中,我们一共训练了 100000 100000 100000 个 Iteration,每个 Iteration 中只有一个样本。在测试阶段,我们随机抽取 10000 10000 10000 个样本来绘制混淆矩阵:
from sklearn.metrics import ConfusionMatrixDisplay
def test(model):
model.eval()
y_true, y_pred = [], []
for _ in range(10000):
category, name = random_sample()
# 获取该样本的真实标签对应的下标
true_idx = all_categories.index(category)
y_true.append(true_idx)
# 获取预测标签对应的下标
X = nameToTensor(name).to(device)
output = model(X)
y_pred.append(output.argmax().item())
# 绘制混淆矩阵
ConfusionMatrixDisplay.from_predictions(y_true,
y_pred,
labels=np.arange(18),
display_labels=all_categories,
xticks_rotation='vertical',
normalize='true',
include_values=False)
plt.show()
最终结果:
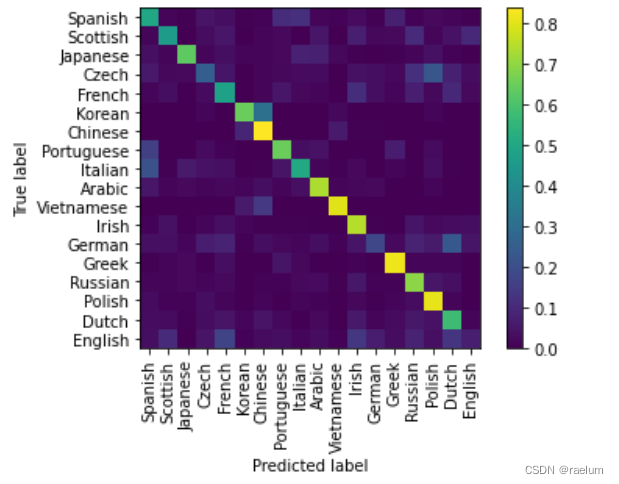
从混淆矩阵的结果可以看出:
- Korean 容易被误判成 Chinese,Czech 容易被误判成 Polish,German 容易被误判成 Dutch;
- English、German、Czech 不容易被识别.
附录:完整代码
运行环境:
- 系统:Ubuntu 20.04
- GPU:RTX 3090
- PyTorch版本:1.10
- Python版本:3.8
- Cuda:11.3
需要注意的是,在 Linux 系统中,os.listdir() 的返回结果与 Windows 系统不同,因此即使随机种子相同,也有可能产生不同的实验结果。
import os
import string
import random
import unicodedata
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
class RNN(nn.Module):
def __init__(self):
super().__init__()
self.rnn = nn.RNN(input_size=54, hidden_size=128)
self.out = nn.Linear(128, 18)
def forward(self, x):
output, h_n = self.rnn(x, None)
return self.out(output[-1])
def unicodeToAscii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn' and c in all_letters)
def letterToTensor(letter):
letter_idx = torch.tensor(all_letters.index(letter))
return F.one_hot(letter_idx, num_classes=len(all_letters))
def nameToTensor(name):
result = torch.zeros(len(name), len(all_letters))
for i in range(len(name)):
result[i] = letterToTensor(name[i])
return result.unsqueeze(1)
def random_sample():
category = random.choice(all_categories)
name = random.choice(data[category])
return category, name
def train(model, critertion, optimizer):
model.train()
avg_loss = 0
for iteration in range(N_ITERS):
category, name = random_sample()
X = nameToTensor(name).to(device)
target = torch.tensor([all_categories.index(category)]).to(device)
output = model(X)
loss = criterion(output, target)
avg_loss += loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (iteration + 1) % 1000 == 0:
avg_loss /= 1000
train_loss.append(avg_loss.item())
print(f"Iteration: [{
iteration + 1}/{
N_ITERS}] | Train Loss: {
avg_loss:.4f}")
avg_loss = 0
def test(model):
model.eval()
y_true, y_pred = [], []
for _ in range(10000):
category, name = random_sample()
true_idx = all_categories.index(category)
y_true.append(true_idx)
X = nameToTensor(name).to(device)
output = model(X)
y_pred.append(output.argmax().item())
ConfusionMatrixDisplay.from_predictions(y_true,
y_pred,
labels=np.arange(18),
display_labels=all_categories,
xticks_rotation='vertical',
normalize='true',
include_values=False)
plt.show()
def setup_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
""" Data preprocessing """
all_letters = string.ascii_letters + " '"
filenames = os.listdir('names')
data = dict()
for filename in filenames:
with open(f'names/{
filename}', encoding='utf-8') as f:
data[filename[:-4]] = [unicodeToAscii(name) for name in f.readlines()]
all_categories = list(data.keys())
""" Model building and training """
setup_seed(42)
LR = 1e-3
N_ITERS = 10**5
device = 'cuda' if torch.cuda.is_available() else 'cpu'
rnn = RNN()
rnn.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(rnn.parameters(), lr=LR, momentum=0.9)
train_loss = []
train(rnn, criterion, optimizer)
plt.plot(np.arange(1, N_ITERS + 1, 1000), train_loss)
plt.ylabel('Train Loss')
plt.xlabel('Iteration')
plt.show()
""" Testing """
test(rnn)
如果这篇文章有帮助到你还请麻烦你点一个免费的赞,这将是我创作的最大动力!
边栏推荐
- GGHIGHLIGHT: EASY WAY TO HIGHLIGHT A GGPLOT IN R
- BEAUTIFUL GGPLOT VENN DIAGRAM WITH R
- 【多线程】主线程等待子线程执行完毕在执行并获取执行结果的方式记录(有注解代码无坑)
- Some problems encountered in introducing lvgl into esp32 Arduino
- pgsql 字符串转数组关联其他表,匹配 拼接后原顺序展示
- Wechat applet uses Baidu API to achieve plant recognition
- ESP32存储配网信息+LED显示配网状态+按键清除配网信息(附源码)
- Esp32 stores the distribution network information +led displays the distribution network status + press the key to clear the distribution network information (source code attached)
- 念念不忘,必有回响 | 悬镜诚邀您参与OpenSCA用户有奖调研
- Homer forecast motif
猜你喜欢

GGPlot Examples Best Reference

Digital transformation takes the lead to resume production and work, and online and offline full integration rebuilds business logic
Pyqt5+opencv project practice: microcirculator pictures, video recording and manual comparison software (with source code)

HOW TO CREATE A BEAUTIFUL INTERACTIVE HEATMAP IN R

GGPLOT: HOW TO DISPLAY THE LAST VALUE OF EACH LINE AS LABEL
Mmrotate rotation target detection framework usage record

Beautiful and intelligent, Haval H6 supreme+ makes Yuanxiao travel safer

【2022 ACTF-wp】

文件操作(详解!)
How to Add P-Values onto Horizontal GGPLOTS
随机推荐
Digital transformation takes the lead to resume production and work, and online and offline full integration rebuilds business logic
R HISTOGRAM EXAMPLE QUICK REFERENCE
GGPLOT: HOW TO DISPLAY THE LAST VALUE OF EACH LINE AS LABEL
Data analysis - Matplotlib sample code
RPA advanced (II) uipath application practice
qt 仪表自定义控件
ESP32 Arduino 引入LVGL 碰到的一些问题
Always report errors when connecting to MySQL database
PX4 Position_Control RC_Remoter引入
BEAUTIFUL GGPLOT VENN DIAGRAM WITH R
HOW TO ADD P-VALUES ONTO A GROUPED GGPLOT USING THE GGPUBR R PACKAGE
Take you ten days to easily finish the finale of go micro services (distributed transactions)
vant tabs组件选中第一个下划线位置异常
Writing contract test cases based on hardhat
可升级合约的原理-DelegateCall
MySQL basic statement
How to Create a Nice Box and Whisker Plot in R
Fabric.js 3个api设置画布宽高
ESP32存储配网信息+LED显示配网状态+按键清除配网信息(附源码)
Amazon cloud technology community builder application window opens