论文提出引入少数超大卷积核层来有效地扩大有效感受域,拉近了CNN网络与ViT网络之间的差距,特别是下游任务中的性能。整篇论文阐述十分详细,而且也优化了实际运行的表现,值得读一读、试一试
来源:晓飞的算法工程笔记 公众号
论文: Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs

Introduction
在图像分类、特征学习等前置任务(pretext task)以及目标检测、语义分割等下游任务(downstream task)上,卷积网络的性能不断被ViTs(vision transformer)网络超越。人们普遍认为ViTs的性能主要得益于MHSA(multi-head self-attention)机制,并为此进行了很多研究,从不同的角度对比MHSA与卷积之间的优劣。
解释VisTs与CNNs的性能差异不是这篇论文的目的,相对于研究MHSA和卷积的差异,论文则关注于ViTs与CNNs在构建长距离位置关系(long-range spatial connections)的范式上的差异。在ViTs中,MHSA通常使用较大的感受域(\(\ge 7\times 7\)),每个输出都能包含较大范围的信息。而在CNNs中,目前的做法都是通过堆叠较小(\(3\times 3\))的卷积来增大感受域,每个输出所包含信息的范围较小。

基于上面发现的感受域差异,论文尝试通过引入少量大核卷积层来弥补ViTs和CNNs之间的性能差异。借此提出了RepLKNet网络,通过重参数化的大卷积来建立空间关系。RepLKNet网络基于Swin Transformer主干进行改造,将MHSA替换为大的深度卷积,性能比ViTs网络更好。另外,论文通过图1的可视化发现,引入大卷积核相对于堆叠小卷积能显著提升有效感受域(ERFs),甚至可以跟ViTs一样能够关注形状特征。
Guidelines of Applying Large Convolutions
直接使用大卷积会导致性能和速度大幅下降,论文通过实验总结了5条高效使用大卷积核的准则,每条准则还附带了一个备注。
Guideline 1: large depth-wise convolutions can be efficient in practice.
大卷积的计算成本很高,参数量和计算量与卷积核大小成二次方关系,而深度卷积恰好可以弥补这一缺点。将各stage的卷积核从\([3,3,3,3]\)标准卷积改为\([31,29,27,13]\)深度卷积,仅带来了18.6%的计算量增加和10.4%的参数量增加。
但由于计算量和内存访问数的比值较低,\(3\times 3\)深度卷积在并行设备上的计算效率较低。不过当卷积核变大时,单个特征值被使用的次数增加,深度卷积的计算密度则会相应提高。根据Roofline模型,计算密度随着卷积核的增大而增大,计算延迟应该不会像计算量那样增加那么多。
Remark 1
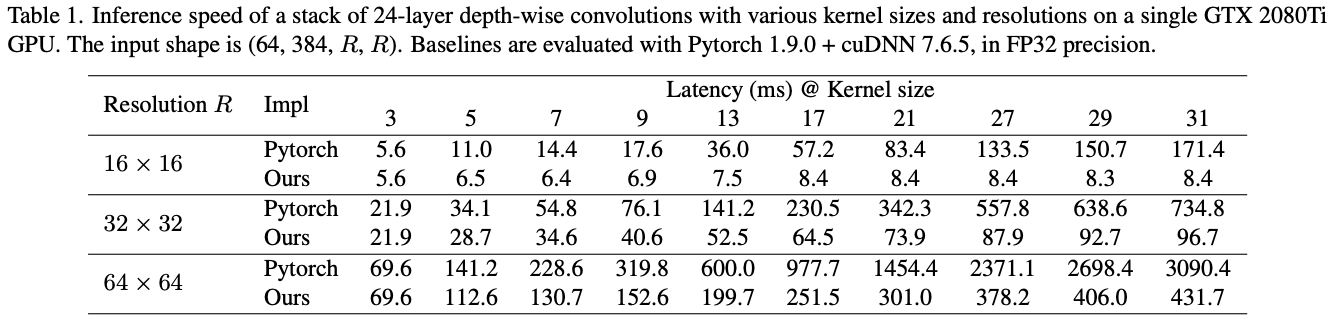
如表1所示,目前的深度学习框架对深度卷积的实现较为低效。为此,论文尝试了不同的方法来优化CUDA内核,最后选择了block-wise(inverse) implicit gemm算法并集成到了MegEngine框架中。相对于Pytorch,深度卷积带来的计算延迟从49.5%降低到了12.3%,几乎与计算量成正比。
具体的相关分析和实现,可以去看看这篇文章《凭什么 31x31 大小卷积核的耗时可以和 9x9 卷积差不多?》(https://zhuanlan.zhihu.com/p/479182218)。
Guideline 2: identity shortcut is vital especially for networks with very large kernels.
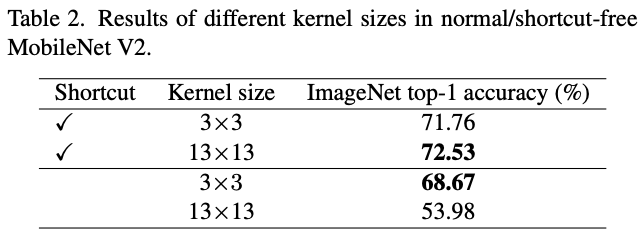
为了验证短路连接对大卷积核的重要性,论文以MobileNetV2作为基准,替换其中的深度卷积核大小来进行有无短路连接的对比。如表2所示,在有短路连接的情况下,大卷积核能带来0.77%的性能提升。而没短路连接的情况下,大卷积核的准确率降低至53.98%。
Remark 2
这个准则同样也适用于ViTs中。近期有研究发现,如果移除短路连接,ViTs中的注意力会随着深度的增加而双倍地减少,最后出现注意力过度平滑的问题。尽管大卷积核性能下降的原因可能跟ViT不一样,但同样也有难以捕捉局部特征的现象。为此,论文认为如参考文献《Residual networks behave like ensembles of relatively shallow
networks》所说的,短路连接能够使得模型显式地变为多个不同感受域大小的模型的组合(小感受域与大感受域不断直接累加),从而能够在更大的感受域中得到提升并且不会丢失捕捉小尺度特征的能力。
Guideline 3: re-parameterizing with small kernels helps to make up the optimization issue.
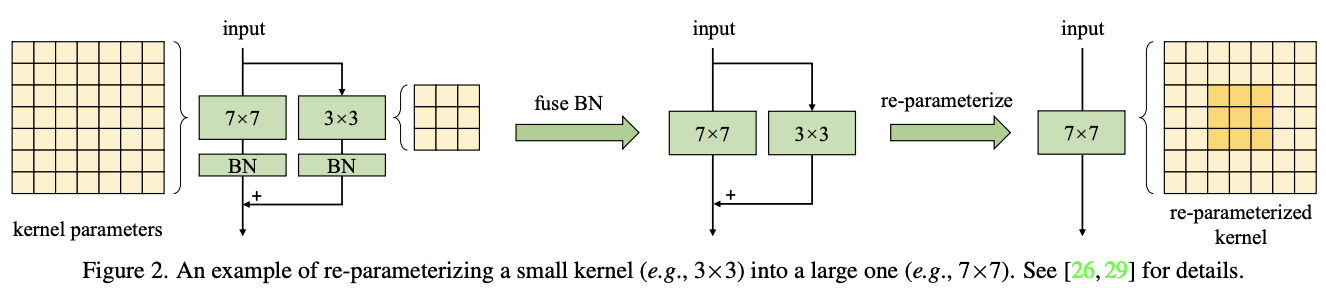
论文将MobileNetV2中的\(3\times 3\)卷积核分别替换为\(9\times 9\)和\(13\times 13\),再采用结构重参数帮助更好地训练。具体的做法如图2所示,先将\(3\times 3\)卷积核替换为更大的卷积核,再并行一个\(3\times 3\)深度卷积层,经过BN处理后将其结果相加作为输出。训练完成后,合并并行的大小卷积层及其BN层,得到没有小卷积层的模型。整体思路跟RepVGG类似,有兴趣的可以去看看公众号之前的文章《RepVGG:VGG,永远的神! | 2021新文》

结构重参数的对比如表3所示,卷积核从9增大到13导致了准确率的下降,使用结构重参数则可用解决这个问题。在语义分割任务中,结构重参数也同样可以解决增大卷积核导致性能下降的问题。
Remark 3
ViTs在小数据集上会有优化问题,通常需要添加前置卷积层来解决。比如在每个self-attention前面添加一个\(3\times 3\)深度卷积层,这跟论文提出的并行\(3\times 3\)卷积的做法类似。添加的卷积层能为ViT网络预先引入平移不变性和局部特征,使其在小数据集上更容易优化。论文在RepLKNet上也发现了类似的现象,当预训练数据集增大到7300万时,不再需要结构重参数化来辅助优化。
Guideline 4: large convolutions boost downstream tasks much more than ImageNet classification.
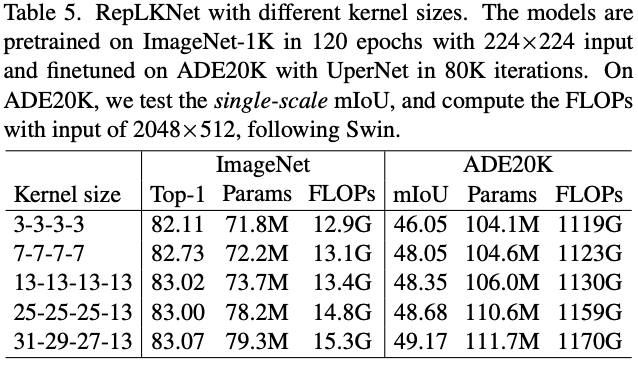
如前面表3所示,相对于分类任务,卷积核增大为分割任务带来的收益更多。而表5的结果也有类似的现象,大卷积核在ADE20K数据集上的提升更为明显。这表明,即使预训练模型有相似的ImageNet性能,但其在下游任务中的性能可能差距较大。
Remark 4
论文认为导致这一现象的原因主要有两点:
- 大卷积核能显著增加有效感受域(ERF),可包含更多的上下文信息,这对下游任务十分关键。
- 大卷积能引导网络倾向于学习更多形状特征。图像分类仅需要上下文或形状信息,而目标识别则非常需要形状信息。所以,倾向于更多形状特征的模型显然更适合下游任务。ViTs之所以在下游任务中表现强劲,也是得益于其强大的形状特征提取能力。相反,ImageNet预训练的传统卷积网络则倾向于上下文信息。
Guideline 5: large kernel (e.g., 13×13) is useful even on small feature maps (e.g., 7×7).

为了验证大卷积在小特征图上的有效性,将MobileNetV2最后的stage(特征图大小为7x7)的深度卷积分别扩大至7x7和13x13进行对比,实验结构附带了准则3建议的结构重参数。结果如表4所示,尽管特征图已经很小了,增大卷积核依然可以带来性能提升。
Remark 5
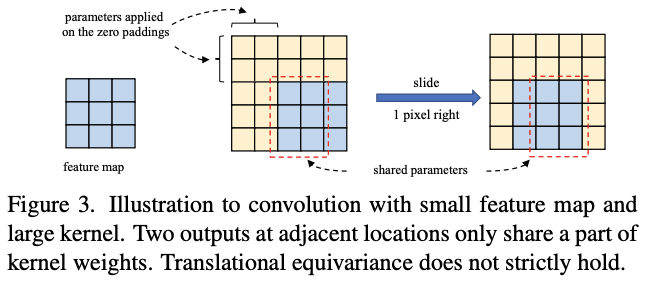
当小特征图上的卷积核变大时,卷积的平移不变性不再严格成立。如图3所示,两个相邻的输出关联了不同的卷积核权值。这刚好符合ViTs的理念,通过放宽对称的先验要求(如输出要用相同的卷积权值得到)来获得更大的识别能力。有趣的是,transformer中使用的2D相对位置编码(其它特征相对于当前特征的位置)也可认为是一个卷积核大小为\((2H-1)\times(2W-1)\)的深度卷积,其中\(H\)和\(W\)分别为特征图的高和宽。所以,大卷积核不仅能够帮助学习特征间的相对位置信息,由于要添加较多padding,还编码了绝对位置信息(参考论文《On translation invariance in cnns: Convolutional layers can exploit
absolute spatial location》)。
RepLKNet: a Large-Kernel Architecture
基于上面的准则,论文提出了RepLKNet,一个大卷积核的纯CNN架构。目前,SOTA小网络仍然以CNN为主,所以论文主要在大模型方面与ViT进行比较。
Architecture Specification
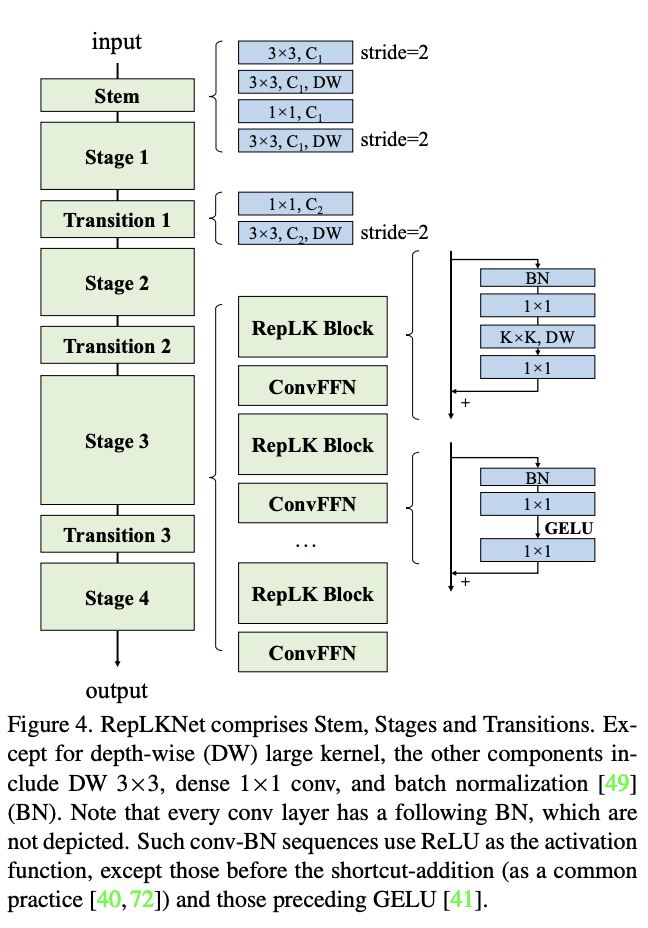
RepLKNet的结构如图4所示,各模块细节如下:
- Stem:由于RepLKNet的主要应用是下游任务,所以需要在网络前期捕捉更多的细节。在开始的stride=2 3x3卷积下采样之后接一个3x3深度卷积来提取低维特征,之后接一个1x1卷积和3x3深度卷积用于下采样。
- Stages 1-4:每个stage包含多个RepLK Block,block里面包含了准则1建议的深度卷积和准则2建议的短路连接。根据准则3,每个深度卷积并行一个5x5深度卷积用于结构重参数。除了感受域和空间特征提取能力,模型的特征表达能力还和特征的维度有关。为了增加非线性和通道间的信息交流,在深度卷积前用1x1卷积增加特征维度。参考transformers和MLPs网络使用的Feed-Forward Network(FFN),论文提出CNN风格的ConvFFN,包含短路连接、两个1x1卷积核GELU。在应用时,ConvFFN的中间特征一般为输入的4倍。参照ViT和Swin,将ConvFFN放置在每个RepLK Block后面。
- Transition Blocks:放在stage之间,先用1x1卷积扩大特征维度,再通过两个3x3深度卷积来进行2倍下采样。
总的来说,每个stage有3个超参数:ReLK Block数\(B\)、维度数\(C\)以及卷积核大小\(K\),所以一个RepLKNet的结构可表达为\([B_1, B_2, B_3, B_4]\), \([C_1, C_2, C_3, C_4]\), \([K_1, K_2, K_3, K_4]\)。
Making Large Kernels Even Larger
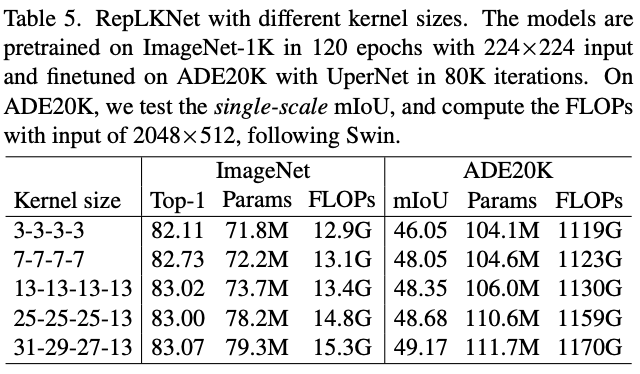
论文固定\(B=[2,2,18,2]\)以及\(C=[128,256,512,1024]\),简单调整\(K\)提出了5个不同大小的网络,称为RepLKNet-3/7/13/25/31。在没有特殊调整训练配置情况下,各模型的参数和性能如表5所示。
另外,论文还对训练配置进行细调以便于与SOTA模型对比,该模型称为RepLKNet-31B。在此基础上,调整超参数\(C=[192,384,768,1536]\)得到RepLKNet-31L。进一步调整超参数\(C=[256,512,1024,2048]\)得到RepLKNet-31XL,该网络的RepLK Blocks的中间特征为输入的1.5倍。
Discussion
Large-Kernel CNNs have Larger ERF than Deep Small-Kernel Models
一般来说,堆叠的小卷积最终也能达到跟单个大卷积一样的感受域大小,但为什么传统网络的性能要低于大卷积核网络呢?论文认为,尽管能达到同样大小的感受域,单层大卷积核要比多层小卷积更有效,主要有两点:
- 根据有效感受域特性,其大小与\(\mathcal{O}(K\sqrt{L})\)成比例关系。可以看到,有效感受域与卷积核大小成线性关系,而与深度成次线性关系。
- 深度的增加会带来训练问题。尽管ResNet似乎已经解决了这个问题,但近期有研究表明,ResNet的有效感受域并没有随着深度增加而显著增加。
所以大卷积核的设计仅需要更少的层就可以达到预定的有效感受域,同时避免了深度增加带来的优化问题。
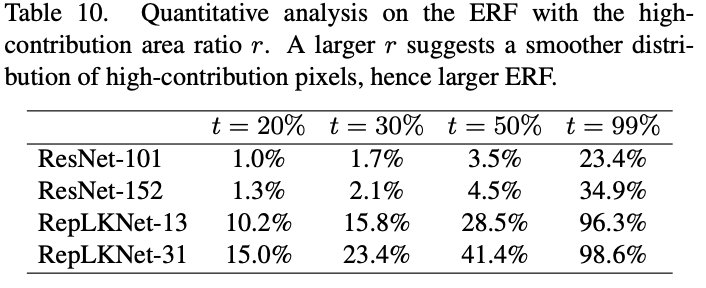
论文也对ResNet和RepLKNet的有效感受域进行可视化和统计,发现RepLkNet整体有效感受域要大于ResNet。
Large-kernel Models are More Similar to Human in Shape Bias
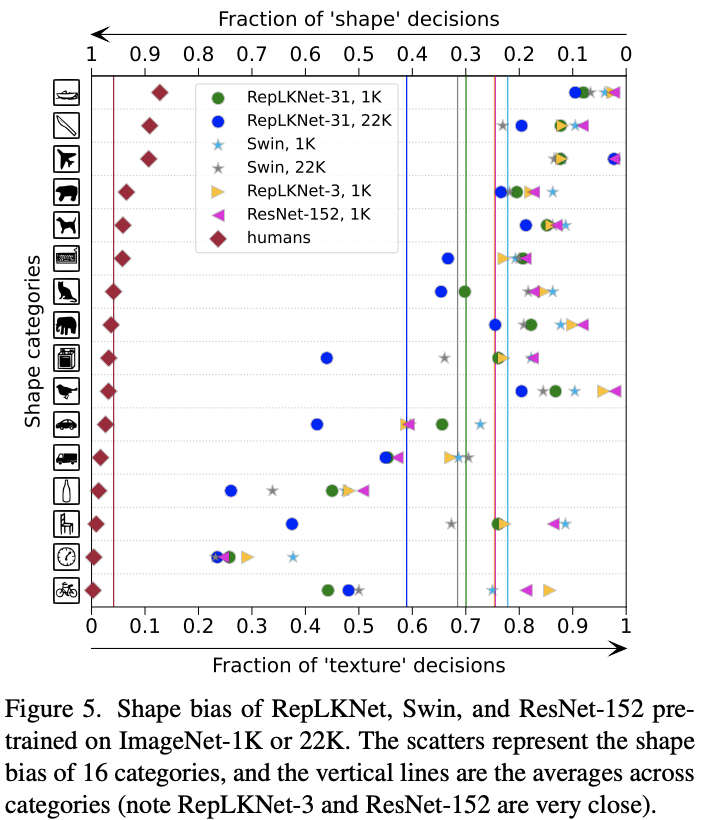
有研究发现ViT更接近人体视觉,基于目标的形状进行预测,而CNN则更多地依赖局部上下文。论文借用https://github.com/bethgelab/model-vs-human的工具来计算模型的形状特征的偏向性,得到图5的结果,结果越低越好。从结果来看,大卷积核的RepLKNet更注重形状特征,当卷积核减少时,RepLKNet-3则变为更注重上下文特征。
Dense Convolutions vs. Dilated Convolutions
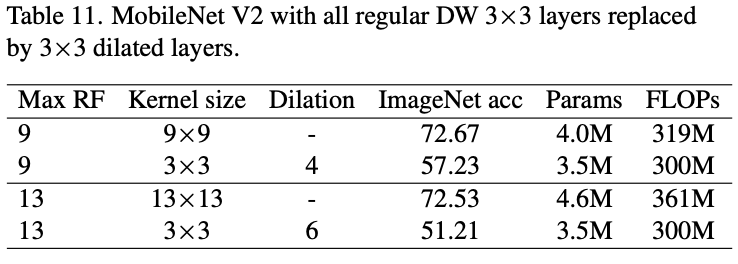
空洞卷积是一个常用的扩大卷积范围的方法,所以论文对空洞深度卷积和普通深度卷积进行了对比。如表11所示,尽管最大感受域可能一样,但空洞深度卷积的表达能力要弱很多,准确率下降非常明显。这也是符合预期的,虽然空洞卷积的感受域较大,但其计算用的特征非常少。
Experiment
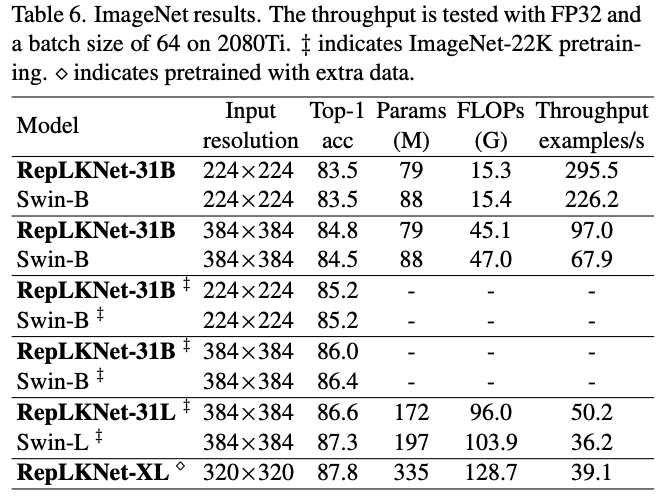
ImageNet图像分类性能对比。
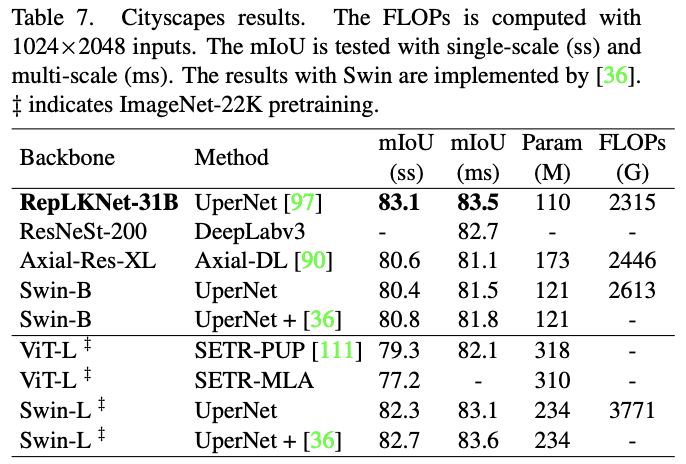
Cityscapes语义分割性能对比。

ADE20K语义分割性能对比。
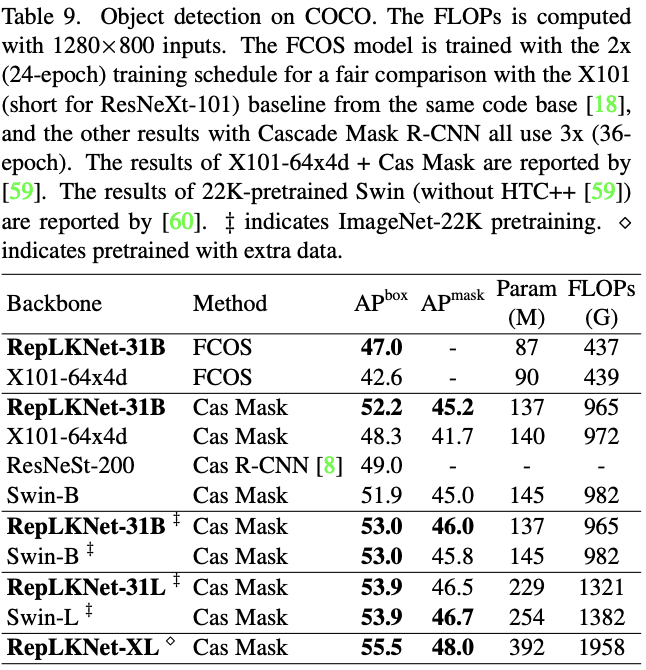
MSCOCO目标检测性能对比。
Conclusion
论文提出引入少数超大卷积核层来有效地扩大有效感受域,拉近了CNN网络与ViT网络之间的差距,特别是下游任务中的性能。整篇论文阐述十分详细,而且也优化了实际运行的表现,值得读一读、试一试。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】



![1330: [example 8.3] minimum steps](/img/69/9cb13ac4f47979b498fa2254894ed1.gif)
![P6183 [USACO10MAR] The Rock Game S](/img/f4/d8c8763c27385d759d117b515fbf0f.png)
![P1451 calculate the number of cells / 1329: [example 8.2] cells](/img/c4/c62f3464608dbd6cf776c2cd7f07f3.png)