当前位置:网站首页>【Ranking】Pre-trained Language Model based Ranking in Baidu Search
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
2022-07-02 07:22:00 【lwgkzl】
executive summary
This article focuses on solving the following problems :
- The existing pre training language model cannot be applied to online ranking system, Because the network text is usually long .
- The existing pre training paradigm , Like random mask vocabulary , The next round of sentence prediction , There are Rank The task doesn't matter , Therefore, the relevance in the text will be ignored , So as to weaken its presence ad-hoc Effects in retrieval .
- In a real information retrieval system ,Ranking Modules usually need to be used in combination with other modules , How to make ranking It is also a problem worth exploring that the module can be better compatible with other modules of the retrieval system .
For the above problems , This paper gives a specific solution .
For the first question , That is, long text processing .
This paper first proposes a method to extract long text abstracts quickly , Then use the abstract to replace the content of the original text , This reduces the length of the text . secondly , This paper puts forward a kind of Pyramid-ERNIE Structure , It can reduce query The time complexity of the interaction with the summary .
For the second question , That is, ordinary pre training tasks cannot model the correlation between texts , about web For retrieval , In especial query And document The relevance of . This article uses Baidu search query Train with the user's click data as a weak supervision signal . It also introduces how to use some de-noising methods to establish high-quality user click dataset pairs ENRIE pretraining .
For the third question , namely ranking Compatibility between the module and other modules of the system . This paper uses human labeled data again fine-tuning, Strive for consistency between the relevance score of the system and human , Make the system have better interpretability and compatibility with other modules ( Other modules also need to be consistent with human annotations )
The specific methods are introduced as follows :
Specific method introduction
- A fast Abstract extraction algorithm

The reason for this algorithm is : because web document Too long , Previous work may only use document Of title As document Information about , however title Yes document The summary of information is too abstract , Will lose a lot of text information . So we need to find a way to document Key information extracted .
To sum up, this algorithm is : Set the weight for each word , And then according to query And the selected sentence and the candidate sentence ( Sentences in the document ) The common vocabulary weight and , Determine the score of the candidate sentence . Select the candidate sentence with the highest score each time and add it to the summary . And after choosing the sentence , It will dynamically update the weight of words , Make the selected sentences cover more words . According to the number of sentences selected, the length of the final summary can be dynamically weighed .
See the pseudo code of the algorithm for specific details .
2. Pyramid-ERNIE Structure 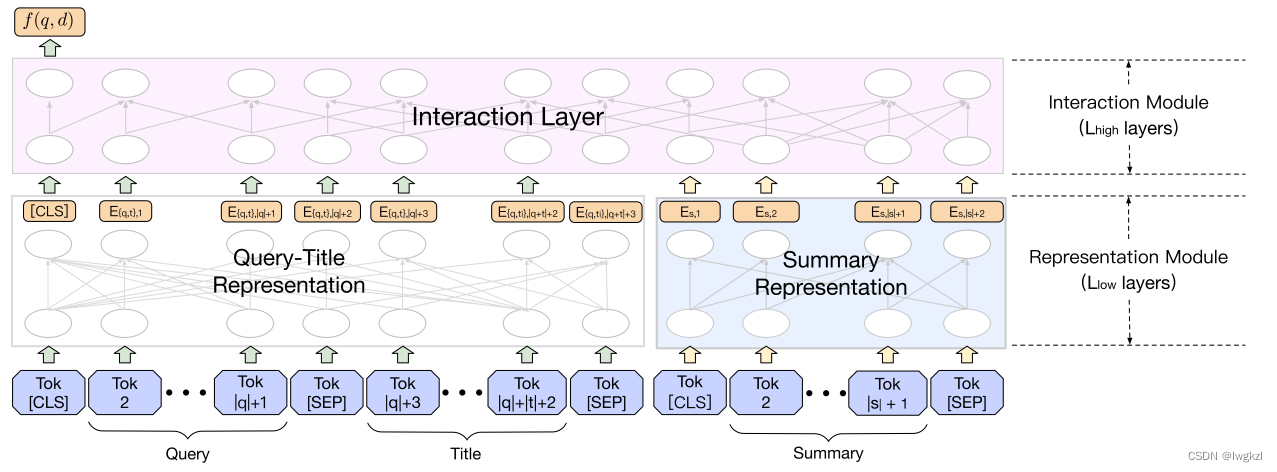
Pyramid-ERNIE The structure of is relatively intuitive , It is a classic two tower structure , The left input is query+ Combination of titles , The right input is the extracted document summary . Like most twin tower models , After extracting the features of the left and right branches respectively , Enter the interaction layer to interact .
And direct splicing query, The title and summary are then entered into ERNIE Comparatively speaking , The establishment of twin tower model has better time complexity ( It reduces the length of a single input sentence ).
analysis :( Personal opinion )
If the input on the left is query, The input on the right is the title + In summary , The online efficiency of the whole model will be improved a lot , Because in application , The feature extraction part of all abstracts can be preprocessed , When online , Just deal with it query part , Then do feature interaction accordingly .
However, subsequent experiments have proved that the title should be similar to query It will be better to put it on the left side together . and , This article applies to Ranking Stage , so document The number of is relatively small , Therefore, such treatment should also be acceptable in terms of time .
3. Pre training with user click data
Pre training tasks for modeling text relevance , An intuitive solution is to use the user click data in the real scene to do weak supervision signal for pre training . However, this direct approach will have some problems :
a. There will be false positives in the collected user click data ( Users are late )
b. Exposure deviation , The existing system ranks in the previous pages document You will get more clicks , And those who rank lower will not get clicks , Therefore, the label of the later document cannot be obtained . And when it's actually online , It is possible that users need documents that are currently at the bottom of the list ( No fake tags , Therefore, it has not been trained by the model ), This will cause performance differences online and offline .
c. Click signals do not fully represent Correlation , Maybe the user has a new interest in a retrieved web page . Therefore, the relevance between simple user clicks and text cannot be equated .
If there is a problem, there will be a solution :
Aiming at problems a, This paper uses some empirical indicators , Such as the length of web browsing , Whether the evaluation of rolling speed is delayed .
Aiming at problems b, This paper uses #click/#skip To solve ( I don't quite understand this )
Aiming at problems c, This paper manually annotates a correlation data set , And based on this data set , And the artificial features extracted before , A tree model is trained to filter a large number of unlabeled user click data . The specific tree model is shown in the following figure :
Final , The pre training task is (g(x) Tags predicted for the tree model ):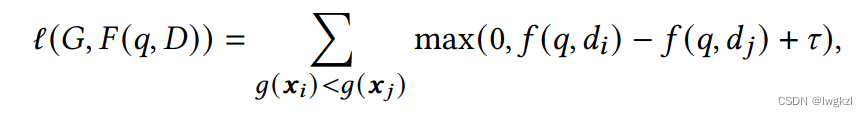
.
4. Using human annotation data Fine-Tuning
reason :
a. ranking model Need and retrieve other modules of the system ( authoritative , Freshness, etc ) consistency , You can't pre train correlation only with click data .
b. Use only pairwise Of loss To train the model will have great query Variance of distribution ( High frequency inquiry can train to get a lot of relevant documents , Low frequency inquiry is less trained , Therefore, the relevant documents cannot be found well )
c. pairwise Training focuses on the relative relevance of training , While ignoring the query And documents , therefore rank model The scoring of is lack of practical significance .
In order to solve the above three problems , This paper chooses to manually label a large-scale correlation data set , And in Pyramid-ERNIE Fine-tuning When , With the label of prediction reality point-loss.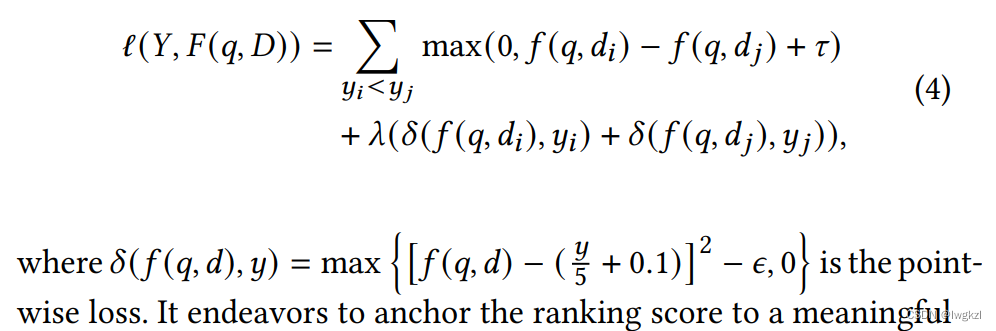
边栏推荐
- MySQL has no collation factor of order by
- 腾讯机试题
- Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK
- JSP智能小区物业管理系统
- Oracle apex Ajax process + dy verification
- ssm人事管理系统
- 【信息检索导论】第七章搜索系统中的评分计算
- Oracle EBS DataGuard setup
- ssm超市订单管理系统
- [introduction to information retrieval] Chapter II vocabulary dictionary and inverted record table
猜你喜欢

MapReduce与YARN原理解析
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization

SSM学生成绩信息管理系统
spark sql任务性能优化(基础)

DNS attack details

oracle apex ajax process + dy 校验

Error in running test pyspark in idea2020
【BERT,GPT+KG调研】Pretrain model融合knowledge的论文集锦
【信息检索导论】第一章 布尔检索
图解Kubernetes中的etcd的访问
随机推荐
[medical] participants to medical ontologies: Content Selection for Clinical Abstract Summarization
【论文介绍】R-Drop: Regularized Dropout for Neural Networks
MapReduce concepts and cases (Shang Silicon Valley Learning Notes)
中年人的认知科普
【Torch】最简洁logging使用指南
The first quickapp demo
Ceaspectuss shipping company shipping artificial intelligence products, anytime, anywhere container inspection and reporting to achieve cloud yard, shipping company intelligent digital container contr
PHP uses the method of collecting to insert a value into the specified position in the array
Sparksql data skew
华为机试题
ORACLE EBS接口开发-json格式数据快捷生成
MySQL composite index with or without ID
Implementation of purchase, sales and inventory system with ssm+mysql
[introduction to information retrieval] Chapter 1 Boolean retrieval
Data warehouse model fact table model design
Agile development of software development pattern (scrum)
sparksql数据倾斜那些事儿
解决万恶的open failed: ENOENT (No such file or directory)/(Operation not permitted)
Network security -- intrusion detection of emergency response
Conda 创建,复制,分享虚拟环境