当前位置:网站首页>【信息检索导论】第一章 布尔检索
【信息检索导论】第一章 布尔检索
2022-07-02 06:25:00 【lwgkzl】
总览
第一章主要介绍了信息检索,布尔检索的概念以及一些检索的基本定义,如倒排索引等。
1.1 信息检索的一个例子
信息检索(information retrieval):从大规模非结构化语料中(通常是文本)找出满足用户信息需求资料的过程。
Ad hoc retrieval: 这是信息检索的一个应用场景,一般来说整个信息检索分为两种,一种是Ad hoc retrieval, 即语料库是基本固定的,利用这个语料库去满足用户任意的询问,这种场景是IR里面最常见的,比如搜索引擎,图书馆检索系统等,都可以看做是Ad hoc retrieval。 还有一种是filtering retrieval,这种是用户的需求不会怎么变化,但是语料库会随时处于迭代,这种需求较少,一个不那么恰当的例子是体育新闻网站的搜索, 用户的query大概就是固定的(球星,联赛),而新闻是动态更新的。
索引(index):通常的查找是线性查找,如线性的扫描文本,寻找想要的字段等。 如果有一个标记可以标志该字段所在的文档,则可以把该标记成为索引,如图书馆的编号等。
词项(term): 在文本检索中,词项将作为索引的单位。将一句话进行分词,得到的子单元就是词项. 如“我是中国人” 分词后为[“我”,“是”,“中国人”],列表中就是三个词项。
文档(document): 检索系统中,被检索的对象,可以是书籍,新闻,篇章等。当然我们需要给每一个文档赋予一个编号(01,02,03…)。
词项-文档关联矩阵(term-document incidence matrix): 简单布尔检索的基础结构, 是词项与文档组成的两维矩阵C,取值由0,1组成, C i j = 1 C_{ij}=1 Cij=1表示词项i在文档j中出现过,反之则表示没有出现。示例图如下: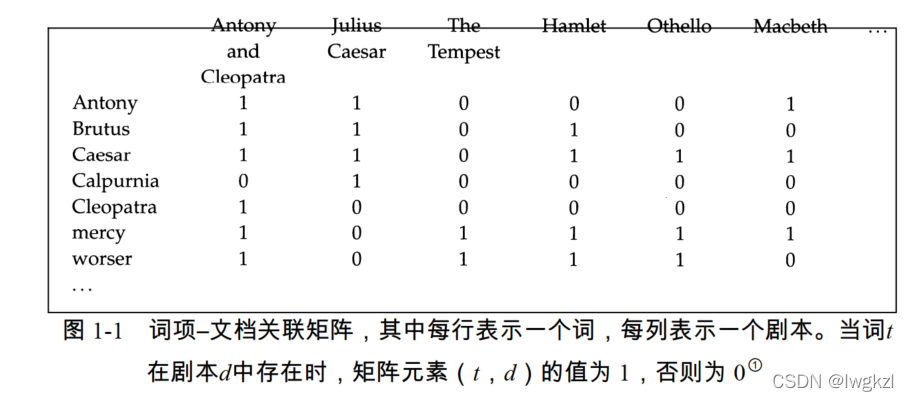
布尔检索模型(bool retrieval model):布尔检索是根据关键词检索包含该词的所有文档。并且支持多个关键词之间的“AND”,“OR”,"NOT"操作。
根据上面的词项-文档关联矩阵,我们可以很容易的做到这一点。
如检索同时包含 “Antony” 和 “Brutus”的文档,则将“Antony”所对应的文档向量“110001”与“Brutus”的文档向量"110100"做与操作即可
110001 & 110100 => 110000
与操作得到的答案前两位是1,说明一个文档和第二个文档是检索的答案(同时包含以上两个词汇)。同理可以实现“OR”和“NOT”操作
倒排索引(inverted index):
为什么需要倒排索引: 以词项-文档关联矩阵构建词项与文档之间的关系太占空间, 因为现实生活中,词项是上万的,文档是千亿级别的,两者相乘是什么机器都存不下的体积。 由于词项-文档矩阵中,大量的位置是0,其实可以用图论中的** 邻接表**来存储,即对于每个词项,只存包含该词项的文档编号。
什么是倒排索引: 即以词项为键的邻接表,每一行存储包含该词项的文档编号的一种思想。
倒排记录表(posting list):用倒排索引思想存储词项-文档之间关联关系的邻接表,如下图所示:左侧是词项列,右侧是一个链表,存储包含该词项的文档编号
为了更加高效的检索,左侧的词项根据字典序有序排列,右侧的文档编号由小到大排列
1.2 初步构建倒排索引表
主要分为四个步骤
- 收集数据

- 对文本数据进行分词,构建词项
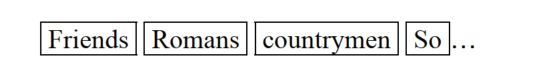
- 对词项进行归一化处理。(英文中,去除词汇时态,等)
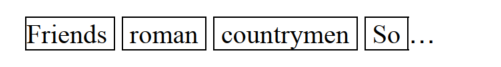
- 合并词项对应的文档,并对按顺序存放,还可以统计词汇的频率。

1.3 处理布尔检索的查询
倒排表合并(posting merge):由于每一个词项对应一个邻接表(图1-3),那么之前布尔检索的需求,“AND”,“OR”,"NOT"的实现就不是简单的对向量进行与或非的操作了。而是需要合并对应对应的多个链表,找出其公共元素。而找链表公共元素可以在 O ( n ) O(n) O(n)的时间内完成(建立在同一词项的文档编号是有序的前提下):
更复杂的操作有对应的优化,在此不做详细介绍
1.4 拓展布尔检索
布尔检索可以找到符合条件的所有文档,但是并不能对文档进行打分和排序,即所有的文档都是相同权重的,因此在这里引出:
词项临近指标(term proxlmity): 其主要思想为:用于指定查询的两个词项应该在文档中互相靠近,靠近程度取决于两个词是否在同一个机构单元(同一段,同一句话等)
这为布尔检索提供了额外的功能(不仅仅是“AND”“OR”,“NOT”):
“/s”,"/p","/k"分别表示两个词在同一句,同一段,以及K个词内。
局限性: 使用“AND”操作时,会造成高precision,低recall的情形,而使用“OR”操作的时候,会造成高recall,低precision的情况,很难通过构造查询规则来权衡这两者的关系。
总结
本章主要介绍了:
- 倒排索引的概念及构造
- 布尔检索模型的概念
- 一些信息检索的基本概念
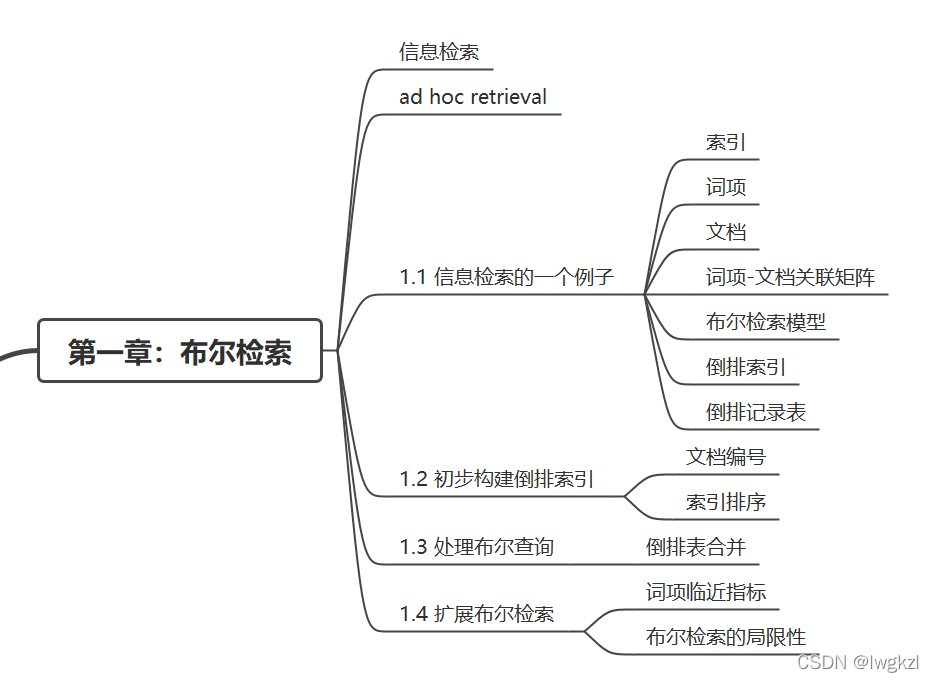
本章知识图谱
边栏推荐
猜你喜欢

MySQL中的正则表达式

Oracle EBs and apex integrated login and principle analysis

Sqli-labs customs clearance (less6-less14)
2021-07-05c /cad secondary development create arc (4)

@Transational踩坑

MapReduce concepts and cases (Shang Silicon Valley Learning Notes)

Check log4j problems using stain analysis

Sqli-labs customs clearance (less18-less20)

ssm超市订单管理系统

ORACLE EBS ADI 开发步骤
随机推荐
Principle analysis of spark
第一个快应用(quickapp)demo
Oracle rman自动恢复脚本(生产数据向测试迁移)
Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK
php中计算两个日期之前相差多少天、月、年
TCP attack
CRP implementation methodology
Changes in foreign currency bookkeeping and revaluation general ledger balance table (Part 2)
JSP智能小区物业管理系统
UEditor . Net version arbitrary file upload vulnerability recurrence
腾讯机试题
Review of reflection topics
Error in running test pyspark in idea2020
php中的数字金额转换大写数字
Basic knowledge of software testing
Flex Jiugongge layout
Explanation of suffix of Oracle EBS standard table
php中获取汉字拼音大写首字母
2021-07-19c CAD secondary development creates multiple line segments
SSM学生成绩信息管理系统