当前位置:网站首页>One click extraction of tables in PDF
One click extraction of tables in PDF
2022-07-06 11:07:00 【zkkkkkkkkkkkkk】
Preface :
Due to work needs , Now we need to pdf The table in is not sealed properly csv Or database tables , Then it opened the road of forced research . Through investigation and research , At present, support from Editable pdf Read out the table Python Library has :pdfminer3k、tabula、pdfplumber etc. . All three libraries have flaws . But I'm still more inclined to pdfplumber . Self perception pdfplumber Simple and easy to implement functions . The following article is about pdfplumber Introduction to . For the other two Python If you are interested, you can check the relevant information by yourself . about pdf Editable in Central Africa ( Table recognition in the picture ) problem , Maybe this library can't help you .
Catalog
1.2、 Open source code git Address
One 、pdfplumber Introduce
1.1、 Introduce
Let's first look at an official introduction :pdfplumber Support vertical view PDF, View each text character 、 Rectangle and row details . Additional features : Table extraction and visual debugging . Most suitable for machine generated , Not scanned pdf file . On the whole pdfplumber It is a multi-function pdf Processing tools .
1.2、 Open source code git Address
1.3、 Official documents
1.4、 Installation mode
pip install pdfplumberTwo 、 Easy to use
2.1、 Data set introduction
Data is transaction flow ,pdf The table is editable . The purpose is to extract the data in the table .
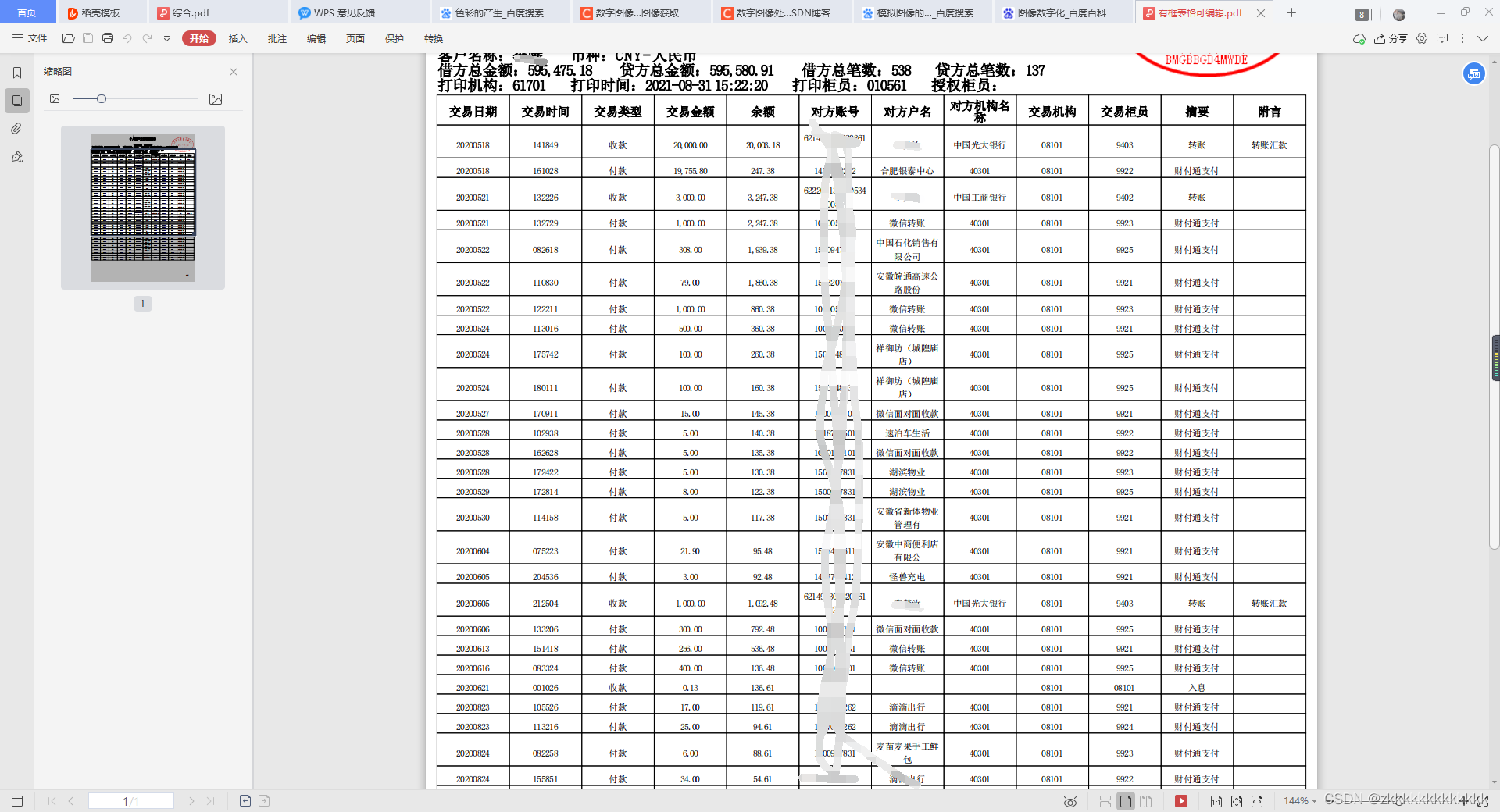
2.2、 Code implementation
import pdfplumber
# path = 'D:\\202104147187110045_1.pdf'
path = '../recognize_img/demo_img/ A framed table can be edited .pdf'
pdf = pdfplumber.open(path)
# obtain pdf Page number object
print(pdf.pages) # [<Page:1>]
count = 0
for page in pdf.pages:
count += 1
# page.extract_text() You can grab all the information of the current page , Because there is a lot of content, please comment first .
# print(page.extract_text())
for table in page.extract_tables():
for row in table:
print(row)
print(f'============ The first {count} End of page parsing ============')
# To dataframe Output
# pass
pdf.close()3.3、 Results output
The result is output as a list per row . If necessary csv Or database requirements , You can first convert the following data into dataframe, Then output to the target source .

边栏推荐
- API learning of OpenGL (2005) gl_ MAX_ TEXTURE_ UNITS GL_ MAX_ TEXTURE_ IMAGE_ UNITS_ ARB
- CSDN question and answer tag skill tree (I) -- Construction of basic framework
- Copy constructor template and copy assignment operator template
- [untitled]
- API learning of OpenGL (2001) gltexgen
- QT creator create button
- Postman uses scripts to modify the values of environment variables
- SSM integrated notes easy to understand version
- Ansible实战系列三 _ task常用命令
- CSDN question and answer tag skill tree (II) -- effect optimization
猜你喜欢
Navicat 導出錶生成PDM文件
QT creator specify editor settings
Deoldify项目问题——OMP:Error#15:Initializing libiomp5md.dll,but found libiomp5md.dll already initialized.
Idea import / export settings file

【博主推荐】SSM框架的后台管理系统(附源码)
Swagger, Yapi interface management service_ SE
CSDN-NLP:基于技能树和弱监督学习的博文难度等级分类 (一)

Data dictionary in C #
![[reading notes] rewards efficient and privacy preserving federated deep learning](/img/c3/5e88277b5024885d5ceeaa0de14b27.jpg)
[reading notes] rewards efficient and privacy preserving federated deep learning
安装numpy问题总结
随机推荐
Invalid global search in idea/pychar, etc. (win10)
FRP intranet penetration
[ahoi2009]chess Chinese chess - combination number optimization shape pressure DP
A brief introduction to the microservice technology stack, the introduction and use of Eureka and ribbon
MySQL主從複制、讀寫分離
QT creator shape
Deoldify项目问题——OMP:Error#15:Initializing libiomp5md.dll,but found libiomp5md.dll already initialized.
[Li Kou 387] the first unique character in the string
[number theory] divisor
MySQL完全卸载(Windows、Mac、Linux)
【博主推荐】C# Winform定时发送邮箱(附源码)
MySQL19-Linux下MySQL的安装与使用
frp内网穿透那些事
Some notes of MySQL
Are you monitored by the company for sending resumes and logging in to job search websites? Deeply convinced that the product of "behavior awareness system ba" has not been retrieved on the official w
Navicat 导出表生成PDM文件
CSDN Q & a tag skill tree (V) -- cloud native skill tree
Generate PDM file from Navicat export table
@Controller, @service, @repository, @component differences
February 13, 2022-2-climbing stairs