当前位置:网站首页>CSDN question and answer module Title Recommendation task (II) -- effect optimization
CSDN question and answer module Title Recommendation task (II) -- effect optimization
2022-07-06 10:42:00 【Alexxinlu】
Catalog
- Series articles
- 1. The problem background
- 2. Effect optimization methodology
- 3. Summary and next step plan
- P.S.
Series articles
- CSDN Q & a module Title recommended tasks ( One ) —— Construction of basic framework
- CSDN Q & a module Title recommended tasks ( Two ) —— Effect optimization
Team blog : CSDN AI team
1. The problem background
This article continues from the previous article 《CSDN Q & a module Title recommended tasks ( One ) —— Construction of basic framework 》. In short , It's right CSDN The question and answer module optimizes the effect of the title asked by users , Recommend more reasonable and informative titles to users . For specific tasks, Beijing can refer to Last article , This article mainly introduces the effect optimization strategy of this task .
2. Effect optimization methodology
The basis of effect optimization is mainly based on Last article 2.3 Section analyzes the problem of wrong data , In addition, it also combines the opinions and suggestions of others , Made more reasonable improvements . The specific optimization methodology is as follows .
2.1 Detection of invalid titles
stay Last article in , All user questions are recommended , But in many cases, it is a valid Title ( About 91%), And a small number of recommended titles may be worse than the original valid titles . Therefore, in order to improve the efficiency of Title Recommendation , And avoid the worse effect after the original title recommendation , You need to detect all invalid titles first , Further Title Recommendation .
Invalid Title Detection mainly includes the following two strategies :
2.1.1 Keyword matching strategy
Most invalid titles contain some keywords , For example, the following title , Contains bosses 、 Rescue 、 emergency !、 thank , The title composed of these words cannot express the meaning of the problem itself .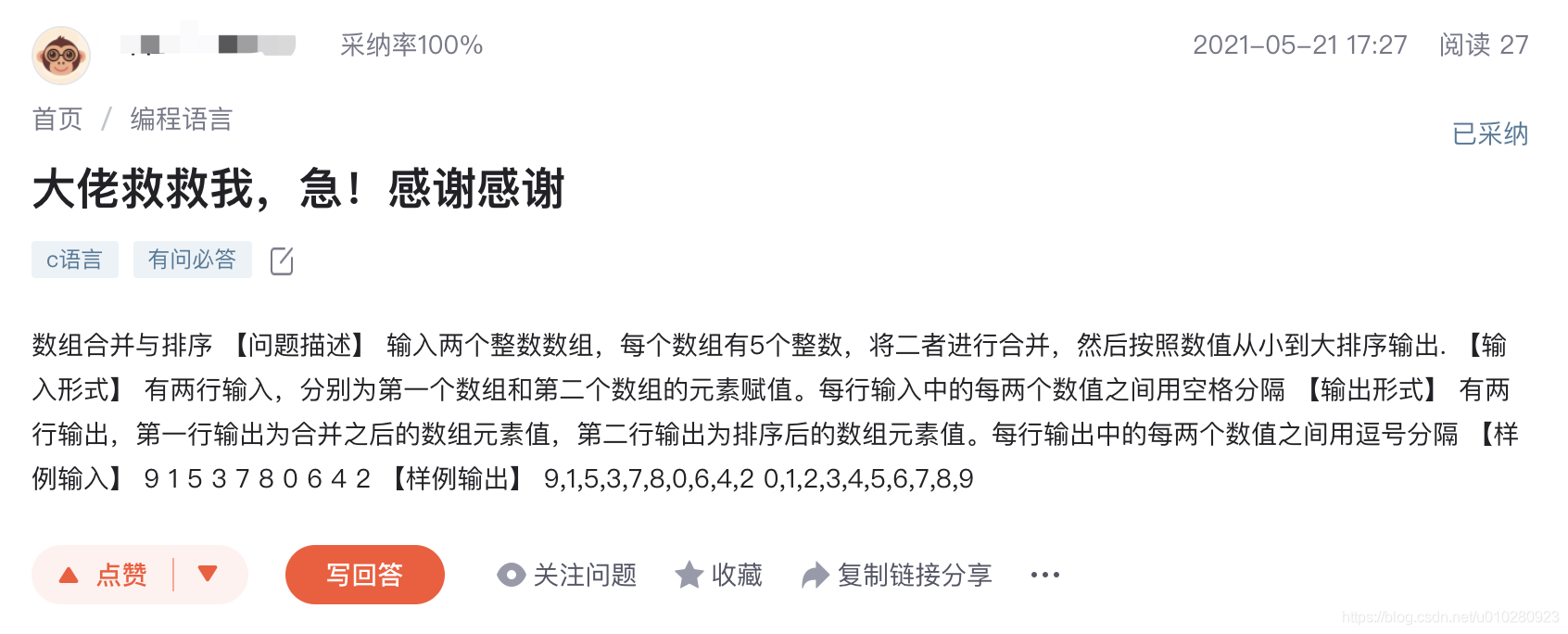
This paper adopts the method of manual collection , Sort out 64 Key words , And determine whether the title is invalid by string matching . All the keywords sorted out are listed below :
emergency !
Urgent demand
Rescue
uncle
emergency
Help
Please
Ball
For help
Ask for advice
Beg
A great god
bosses
Instruction
Give directions
answer
The small white
Adorable new
children
Help
Help
brother
sister
Younger sister
Youngest sister
The younger brother
eldest brother
Novice
New people
Vegetable dog
rookie
Vegetable chicken
brother
master
Beginners
self-taught
thank you
thank
Brother
Homework
Crazy
teacher
Be really something
This question
subject
Source code
Problem.
Ah ah
Online, etc.
It's too hard
Family
brothers
one's junior of equal standing
This question
This question
Examination questions
A question
Source code
Programming questions
How to write the question
How to solve the problem
Source code
haha
curriculum design
Random sampling 2000 The current coverage of invalid Title Recognition in the data test is 98.32%.
2.1.1 Stop phrase strategy
Some invalid titles have no obvious keywords , But the whole title has no amount of information , For such titles , This article is based on deactivating this table , Remove the stop words from the title , Finally, judge whether the title is empty , If it is empty, the title is invalid .
For example, the following title , It's all question marks :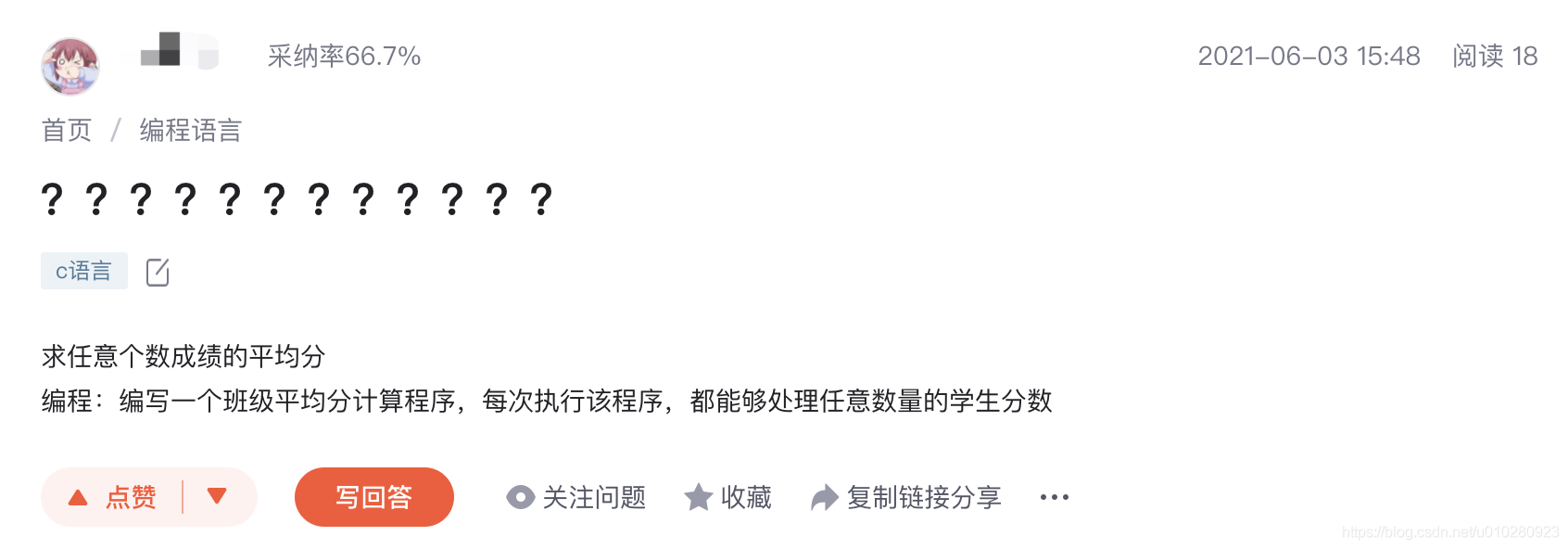
Another example is the following title , The titles are words without any useful information :
2.2 OCR modular : Ensure the integrity of information
In some user questions , Key information can be included in the uploaded pictures , Or there are only a few pictures in the user's body description , Without any written description , for example :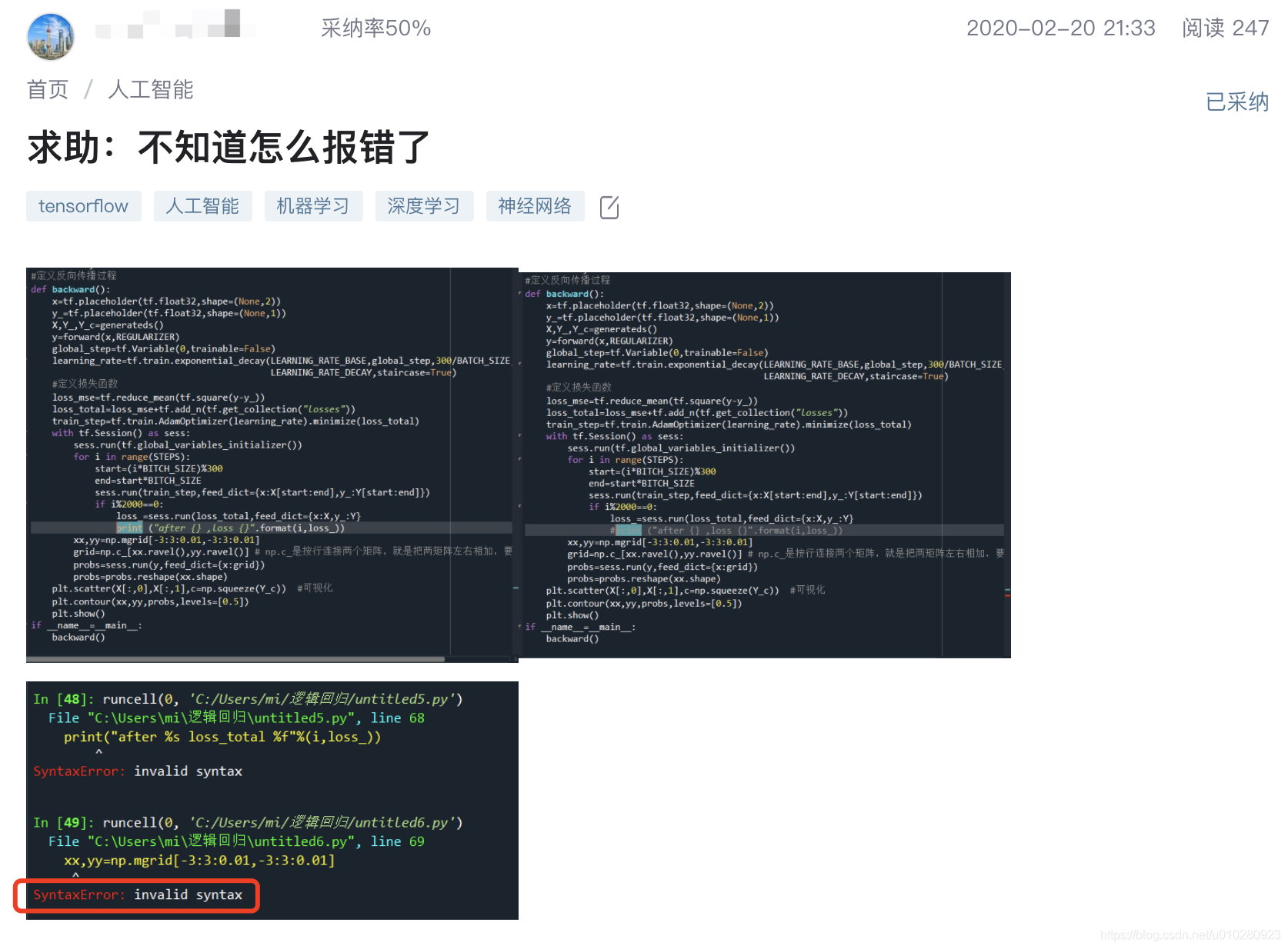
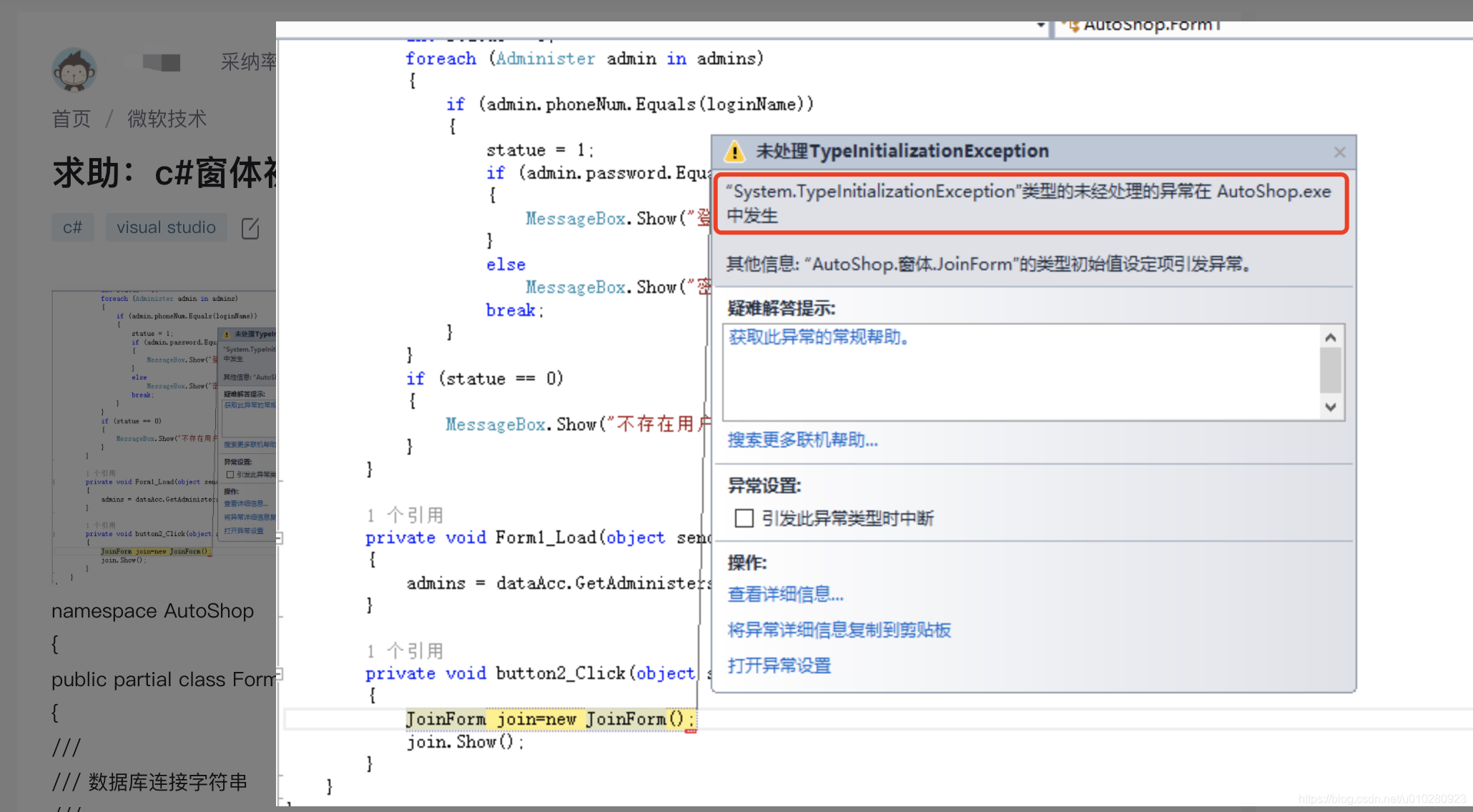
This article USES the paddle_ocr Picture to text module , Recognize the text information contained in the picture into text , Enter the rules module and Text_Rank Module identification .
Besides , because OCR More time-consuming , Therefore, it is necessary to ensure that as few calls as possible OCR modular , If using the existing information is enough to recommend a reasonable Title , Then don't call OCR Identify all pictures .
2.3 Rules module : promote Precision( Accuracy rate )
For some questions with distinctive characteristics , for example : Application error 、 Ask questions about exercises 、 And the inquiry of knowledge points , In this paper, a rule-based method is used for direct recall . The details are as follows :
2.2.1 Error information extraction module
Some users' questions , The text or picture contains obvious error information , Error reporting information is the key information of this kind of problem , Therefore, the error information can be directly extracted as the user's question Title .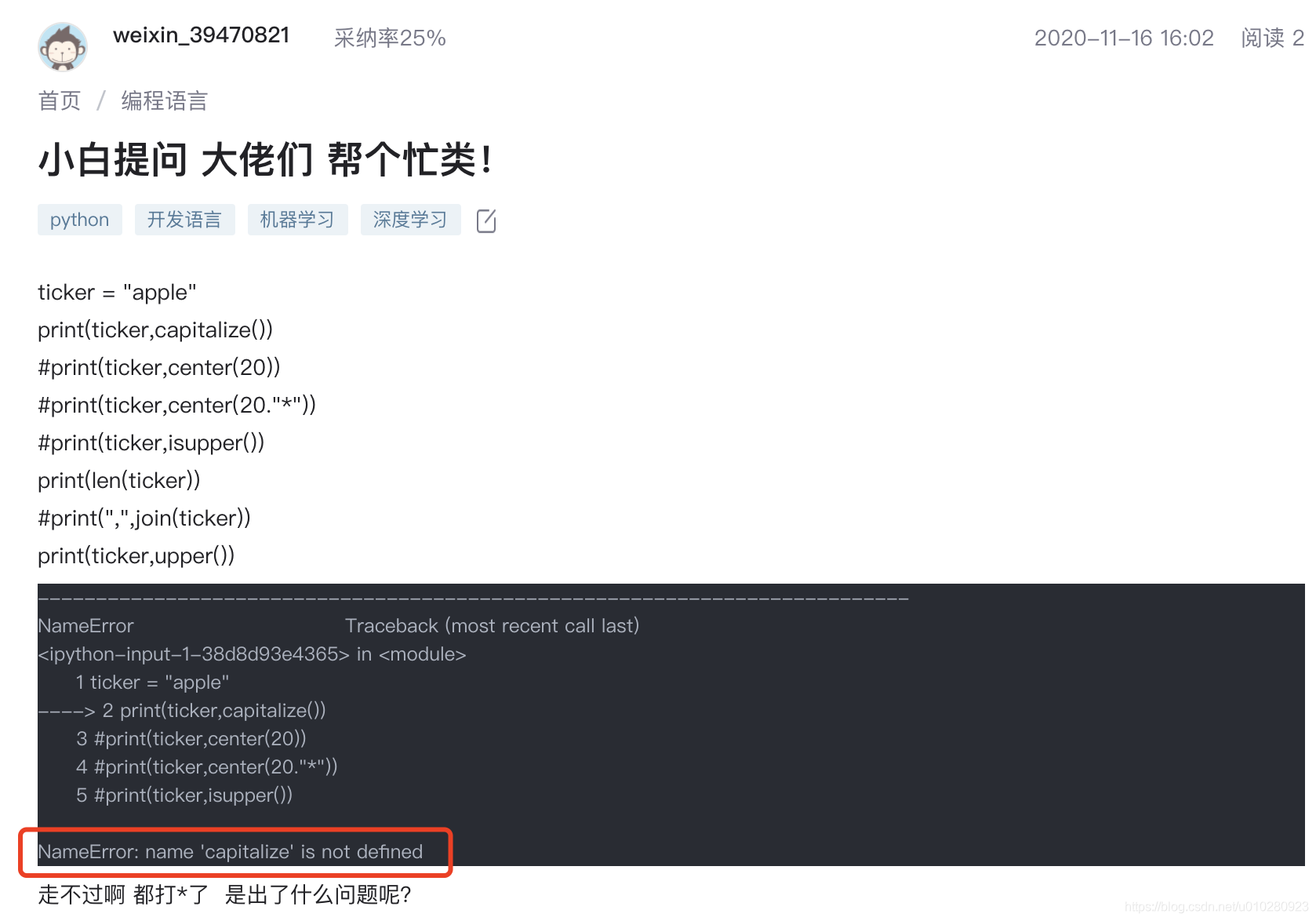
This article uses the regular expression method , Extract the error information . It includes forward rules and reverse rules , Forward rules are used to extract error information , Reverse rules are used to avoid accidental inhalation .
# Positive rule
error_word_pattern = re.compile(r'(exception|error\srequestid|errormessage|errorcode|errmsg|errcode|error|no .*?(detected|found)|unavailable|undefined| System not found | To scald | It doesn't contain [a-z_\.].*? The definition of | perform [a-z_\.].*? An error occurred when | Report errors )')
# Reverse rule
error_word_reverse_pattern = re.compile(r'((except|import|catch|throw)[a-z_ \.\(\)\:]{0,20}exception|([1-9]|logger|self)[\. ]error|error[\((]s[\))][0-9 \,]{1,5}warning[\((]s[\))]|error:function|exception.{1,3}details|onerror|conda config|(catch|throw)[a-z_ \.\(\)\:]{0,20}error)')
2.2.2 Exercise identification module
Some users' questions , It's about how to answer some of the exercises in the course , These questions also contain obvious information , For example, include keywords : Programming questions 、 Exercises etc. .
Here, the regular expression method is also used for matching , Including title based regularization and text based regularization , The regular expression is as follows :
# Title Based regularity
title_exercise_words_pattern = re.compile(r'( subject | Homework | Programming questions | Exercises | Write .*? Program )')
# Text based regularity
body_exercise_words_pattern = re.compile(r'(^(1|A)(、| |\.).{3,}?$|^(①|②|③|④|⑤)| Homework | problem [0-9]|[ one two three four five ] yes :| Title Description )')
2.2.3 Ask the knowledge point module
Some users' questions , Is to ask some very specific knowledge points , So we can extract knowledge points directly , As the title of the user's question .
Here, the regular expression method is also used for matching , Mainly match the information in the title , The details are as follows :
ask_words_pattern = re.compile(r'((?: For help | About )[\u4e00-\u9fa5a-zA-Z0-9_]*?(?: problem | stick )|[^,.?!;]+?(?: The understanding of the | The difference between | Characteristics of | doubts ))')
2.2.4 Add header
In order to further clarify the field of the problem , for example :python、c++、 Artificial intelligence, etc , Make the information contained in the title richer , This article uses the question itself tag Information , Add some templates , Generate a header . The rules are different 3 Rules , Also divided into 3 Template , Plus the title of rule extraction , The final title generated based on the rule is as follows :
- Error information extraction module : About #tag# The question of
Original title : Xiaobai's question bosses Do me a favor !
Recommended title : About # Deep learning # The question of :NameError: name ‘capitalize’ is not defined
- Exercise identification module : About #tag# The subject of
Original title : The great God who can script help ~~~
Recommended title : About #c Language # The subject of
- Ask the knowledge point module : inquiry #tag# Knowledge points of
Original title : Novices ask for advice , The problem of circulation .
Recommended title : inquiry #java# Knowledge points of : The problem of circulation
2.4 Text_Rank modular : promote Recall( Recall rate )
The rule module focuses on ensuring the high accuracy of Title Recommendation , Therefore, there will be a problem of low recall rate , The current recall rate is about 33.5%, So the rest 66.5% Need to use Text_Rank To recall .
Text_Rank It is an abstract text summarization model , Use strategies in Last article There is a brief introduction in , Give priority to questions . Besides , The extraction method has high requirements for the original input text , Therefore, we need to focus on text preprocessing , Remove some useless interference information for text extraction , It mainly includes Code segment 、 Conversion of some escape characters 、URL Information 、 Picture label link information 、 Useless HTML Tag information etc. . Besides , Words that do not contain any valid information will also be removed , for example : Boss, help me see 、 Xiaobai asks for guidance ……
After the above treatment , adopt Text_Rank The generated title will be more accurate and readable .
3. Summary and next step plan
Through the above rules + The strategy of the model , Current title recommendation effect Last article in baseline Of 47.92% Promoted to 86.0%, It has initially reached a usable state .
However, due to the highly colloquial and complex characteristics of user questions , Some details of the Title Recommendation task , Still need further optimization . Next steps include :
- Improve the coverage of rules and resources , Improve the recall rate of rules ;
- Further optimization Text_Rank The effect of the algorithm , Improve the quality of Title Extraction ;
- Text_Rank After all, it is a sentence extracted from the text , As a direct question title, there are some blunt , Next, consider using templates or generated methods , Improve the readability of the title and more in line with the style of questions .
P.S.
This series of articles will be continuously updated . hope NLP Colleagues in other fields 、 Teachers and experts can provide valuable advice , thank you !
边栏推荐
- MySQL combat optimization expert 02 in order to execute SQL statements, do you know what kind of architectural design MySQL uses?
- Emotional classification of 1.6 million comments on LSTM based on pytoch
- MySQL底层的逻辑架构
- MySQL combat optimization expert 10 production experience: how to deploy visual reporting system for database monitoring system?
- Global and Chinese market of operational amplifier 2022-2028: Research Report on technology, participants, trends, market size and share
- CSDN-NLP:基于技能树和弱监督学习的博文难度等级分类 (一)
- Baidu Encyclopedia data crawling and content classification and recognition
- Global and Chinese market of thermal mixers 2022-2028: Research Report on technology, participants, trends, market size and share
- Mysql25 index creation and design principles
- Valentine's Day is coming, are you still worried about eating dog food? Teach you to make a confession wall hand in hand. Express your love to the person you want
猜你喜欢
Emotional classification of 1.6 million comments on LSTM based on pytoch
MySQL 20 MySQL data directory

Super detailed steps to implement Wechat public number H5 Message push
UEditor国际化配置,支持中英文切换
Mysql26 use of performance analysis tools
MySQL25-索引的创建与设计原则
Record the first JDBC
What is the current situation of the game industry in the Internet world?

Bytetrack: multi object tracking by associating every detection box paper reading notes ()

Use xtrabackup for MySQL database physical backup
随机推荐
How to find the number of daffodils with simple and rough methods in C language
MySQL combat optimization expert 12 what does the memory data structure buffer pool look like?
MySQL combat optimization expert 07 production experience: how to conduct 360 degree dead angle pressure test on the database in the production environment?
Global and Chinese market of operational amplifier 2022-2028: Research Report on technology, participants, trends, market size and share
text 文本数据增强方法 data argumentation
MySQL18-MySQL8其它新特性
MySQL20-MySQL的数据目录
Kubesphere - deploy the actual combat with the deployment file (3)
How to change php INI file supports PDO abstraction layer
Discriminant model: a discriminant model creation framework log linear model
Pytorch LSTM实现流程(可视化版本)
[after reading the series of must know] one of how to realize app automation without programming (preparation)
Good blog good material record link
CSDN-NLP:基于技能树和弱监督学习的博文难度等级分类 (一)
Super detailed steps to implement Wechat public number H5 Message push
Use JUnit unit test & transaction usage
MySQL35-主从复制
API learning of OpenGL (2005) gl_ MAX_ TEXTURE_ UNITS GL_ MAX_ TEXTURE_ IMAGE_ UNITS_ ARB
Breadth first search rotten orange
Mysql21 - gestion des utilisateurs et des droits