当前位置:网站首页>Emotional classification of 1.6 million comments on LSTM based on pytoch
Emotional classification of 1.6 million comments on LSTM based on pytoch
2022-07-06 10:25:00 【How about a song without trace】
Data and code github Address
explain : Training speed use cpu It's going to be slow
# The goal is : Emotional categories
# Data sets Sentiment140, Twitter Content on contain 160 Ten thousand records ,0 : negative , 2 : Neutral , 4 : positive
# But there is no neutrality in the dataset
# 1、 Overall process :
# 2、 Import data
# 3、 View data information
# 4、 Data preprocessing :
# ( Proportion of statistical categories ( Positive and negative )
# Set labels and text
# Set the header
# Sample division ( Training and testing as well as validation are used to divide the data )
# Building a vocabulary
# Vocabulary size is inconsistent padding)
# 5、 model building
# 6、 model training
altogether 160 Million comments data , The data format is as follows :
"0","1467810369","Mon Apr 06 22:19:45 PDT 2009","NO_QUERY","_TheSpecialOne_","@switchfoot http://twitpic.com/2y1zl - Awww, that's a bummer. You shoulda got David Carr of Third Day to do it. ;D"
"0","1467810672","Mon Apr 06 22:19:49 PDT 2009","NO_QUERY","scotthamilton","is upset that he can't update his Facebook by texting it... and might cry as a result School today also. Blah!"
"0","1467810917","Mon Apr 06 22:19:53 PDT 2009","NO_QUERY","mattycus","@Kenichan I dived many times for the ball. Managed to save 50% The rest go out of bounds"
"0","1467811184","Mon Apr 06 22:19:57 PDT 2009","NO_QUERY","ElleCTF","my whole body feels itchy and like its on fire "
"0","1467811193","Mon Apr 06 22:19:57 PDT 2009","NO_QUERY","Karoli","@nationwideclass no, it's not behaving at all. i'm mad. why am i here? because I can't see you all over there. "
"0","1467811372","Mon Apr 06 22:20:00 PDT 2009","NO_QUERY","joy_wolf","@Kwesidei not the whole crew "# The goal is : Emotional categories
# Data sets Sentiment140, Twitter Content on contain 160 Ten thousand records ,0 : negative , 2 : Neutral , 4 : positive
# But there is no neutrality in the dataset
# 1、 Overall process :
# 2、 Import data
# 3、 View data information
# 4、 Data preprocessing :
# ( Proportion of statistical categories ( Positive and negative )
# Set labels and text
# Set the header
# Sample division ( Training and testing as well as validation are used to divide the data )
# Building a vocabulary
# Vocabulary size is inconsistent padding)
# 5、 model building
# 6、 model training
# Import data
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import matplotlib.pyplot as plt
# Reading data , engine The default is C
dataset = pd.read_csv("./data/training.1600000.processed.noemoticon.csv",encoding="ISO-8859-1",engine='python',header = None)
# View the... Of the data table shape
dataset.info() # View Datasheet information
dataset.describe() # Data sheet description
# dataset.colums # Name
dataset.head() # Before default 5 That's ok
dataset['sentiment_category'] = dataset[0].astype('category') # Type conversion -》 Categorical variables
dataset['sentiment_category'].value_counts() # Count the number of each category
dataset['sentiment'] = dataset['sentiment_category'].cat.codes # The classification variable value is converted to 0 and 1 Two categories
dataset.to_csv('./data/train-processed.csv',header = None, index = None) # Save the file
# Random selection 10000 Samples as a test set
dataset.sample(10000).to_csv("./data/test_sample.csv",header = None,index = None)
# Set labels and text
from torchtext.legacy import data
from torchtext.legacy.data import Field,TabularDataset,Iterator,BucketIterator
LABEL = data.LabelField() # label
CONTEXT = data.Field(lower = True) # Content and text
# Set the header
fields = [('score',None),('id',None),('data',None),('query',None),('name',None),
('context',CONTEXT),('category',None),('label',LABEL)
]
# Reading data
contextDataset = data.TabularDataset(
path = './data/train-processed.csv',
format = 'CSV',
fields = fields,
skip_header = False
)
# Separate train, test, val
train, test, val = contextDataset.split(split_ratio=[0.8, 0.1, 0.1], stratified=True, strata_field='label')
print(len(train))
print(len(test))
print(len(val))
# Show a sample
print(vars(train.examples[11]))
# Building a vocabulary
vocab_size = 20000
CONTEXT.build_vocab(train, max_size = vocab_size)
LABEL.build_vocab(train)
# Vocabulary size
print(len(CONTEXT.vocab)) # unk --> Unknown words ,pad --> fill
# Look at the most common words in the vocabulary
CONTEXT.vocab.freqs.most_common(10)
# Vocabulary size
print(CONTEXT.vocab.itos[:10]) # Index to words
print(CONTEXT.vocab.stoi) # Words to index
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu' # For setting CPU still gpu
# Text batch , That is, read data batch by batch
train_iter , val_iter, test_iter = data.BucketIterator.splits((train, val, test),
batch_size=32,
device = device,
sort_within_batch = True,
sort_key = lambda x: len(x.context)
)
"""
sort_within_batch = True, One batch The data in the will press sort_key In descending order ,
sort_key Is the rule of arrangement , Use here context The length of , That is, the number of words contained in each user comment .
"""
# model building
import torch.nn as nn
class simple_LSTM(nn.Module):
def __init__(self, hidden_size, embedding_dim, vocab_size, ):
super(simple_LSTM, self).__init__() # Call the constructor of the parent class
self.embedding = nn.Embedding(vocab_size, embedding_dim) # vocab_size Vocabulary size , embedding_dim Word embedding dimension
self.encoder = nn.LSTM(input_size=embedding_dim, hidden_size = hidden_size, num_layers=1)
self.predictor = nn.Linear(hidden_size,2) # Fully connected layer Make a two category
def forward(self,seq): #seq It's a comment
output,(hidden, cell) = self.encoder(self.embedding(seq)) # Embed the comment as a word
# output : torch.Size([24, 32, 100]) 24 How many words to comment on ,32 yes batch_size 100hidden Size
# hidden : torch.Size([1, 32, 100])
# cell : torch.Size([1, 32, 100])
preds = self.predictor(hidden.squeeze(0)) # because hidden yes 1 32 100 We don't need to 1, Just get 100 Is the input of hidden layer , So the 0 Dimension removal of
return preds
# Create model objects
lstm_model = simple_LSTM(hidden_size=100, embedding_dim=300, vocab_size=20002)
lstm_model.to(device) # Deploy to the running device
# model training
from torch import optim
# Optimizer
optimizer = optim.Adam(lstm_model.parameters(),lr=0.001)
# Loss function
criterion = nn.CrossEntropyLoss() # Many classification , ( negative , Neutral , positive )
loss_list = [] # preservation loss
accuracy_list = [] # preservation accuracy
iteration_list = [] # Number of save cycles
def train_val_test(model, optimizer, criterion, train_iter, val_iter, test_iter, epochs):
for epoch in range(1,epochs+1):
train_loss = 0.0 # Loss of training
val_loss = 0.0 # Verify the loss
model.train() # Declare to start training
for indices ,batch in enumerate(train_iter):
# Gradient set 0
optimizer.zero_grad()
outputs = model(batch.context) # Forecast output output
# batch.label
loss = criterion(outputs,batch.label) # Calculate the loss
loss.backward() # Back propagation
optimizer.step() # Update parameters
# batch.tweet shape : torch.Size([26, 32]) --> 26: Sequence length , 32: One batch_size Size
train_loss += loss.data.item() * batch.context.size(0) # Accumulated loss value of each batch
train_loss /= len(train_iter) # Calculate the average loss len(train_iter) : 40000
print("Epoch:{},Train Loss:{:.2f} ".format(epoch,train_loss))
model.eval() # Declare model validation
for indices, batch in enumerate(val_iter):
context = batch.context.to(device) # Deploy to device On
target = batch.label.to(device)
pred = model(context) # Model to predict
loss = criterion(pred,target)
val_loss /= loss.item() * context.size(0) # Accumulated loss value of each batch
val_loss /= len(val_iter) # Calculate the average loss
print("Epoch:{},Val Loss:{:.2f} ".format(epoch, val_loss))
model.eval() # Statement
correct = 0.0 # Calculate the accuracy
test_loss = 0.0 # Test loss
for idx, batch in enumerate(test_iter):
context = batch.context.to(device) # Deploy to device On
target = batch.label.to(device)
outputs = model(context) # Output
loss = criterion(outputs, target) # Calculate the loss
test_loss /= loss.item() * context.size(0) # Accumulated loss value of each batch
# Get the maximum predictive value index
preds = outputs.argmax(1)
# Cumulative correct number
correct += preds.eq(target.view_as(preds)).sum().item()
test_loss /= len(test_iter) # Calculate the average loss
# preservation accuracy, loss iteration
loss_list.append(test_loss)
accuracy_list.append(correct)
iteration_list.append(idx)
print("Epoch : {}, Test Loss : {:.2f}".format(epoch, test_loss))
print("Accuracy : {}".format(100 * correct / (len(test_iter) * batch.context.size(1))))
# visualization loss
plt.plot(iteration_list, loss_list)
plt.xlabel('Number of Iteration')
plt.ylabel('Loss')
plt.title('LSTM')
plt.show()
# visualization accuracy
plt.plot(iteration_list, accuracy_list, color='r')
plt.xlabel('Number of Iteration')
plt.ylabel('Accuracy')
plt.title('LSTM')
plt.savefig('LSTM_accuracy.png')
plt.show()
# Start training and verification
train_val_test(lstm_model, optimizer, criterion, train_iter, val_iter, test_iter, epochs=10)
边栏推荐
- MySQL实战优化高手07 生产经验:如何对生产环境中的数据库进行360度无死角压测?
- MySQL实战优化高手11 从数据的增删改开始讲起,回顾一下Buffer Pool在数据库里的地位
- Record the first JDBC
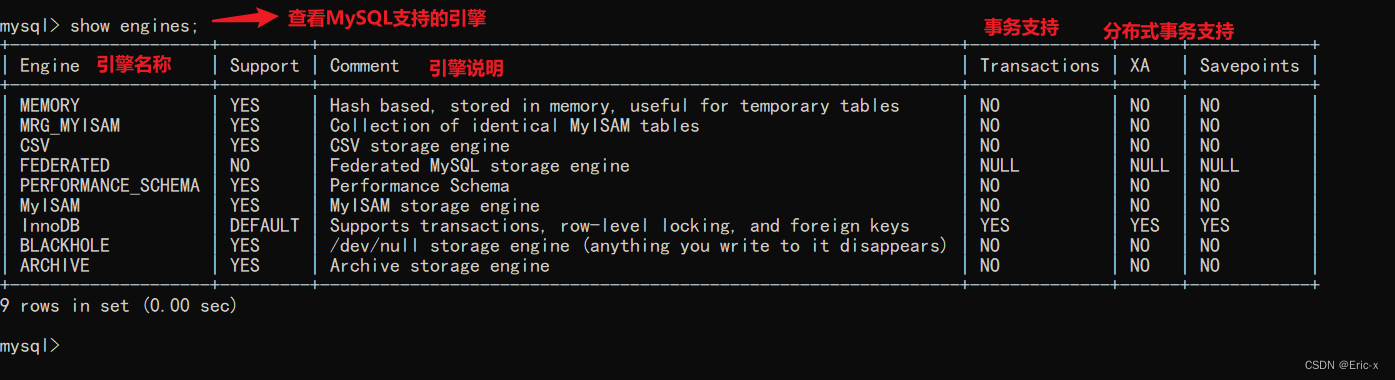
- MySQL storage engine
- The appearance is popular. Two JSON visualization tools are recommended for use with swagger. It's really fragrant
- Time in TCP state_ The role of wait?
- Vscode common instructions
- docker MySQL解决时区问题
- Sed text processing
- MySQL combat optimization expert 10 production experience: how to deploy visual reporting system for database monitoring system?
猜你喜欢
A necessary soft skill for Software Test Engineers: structured thinking
13 医疗挂号系统_【 微信登录】
高并发系统的限流方案研究,其实限流实现也不复杂
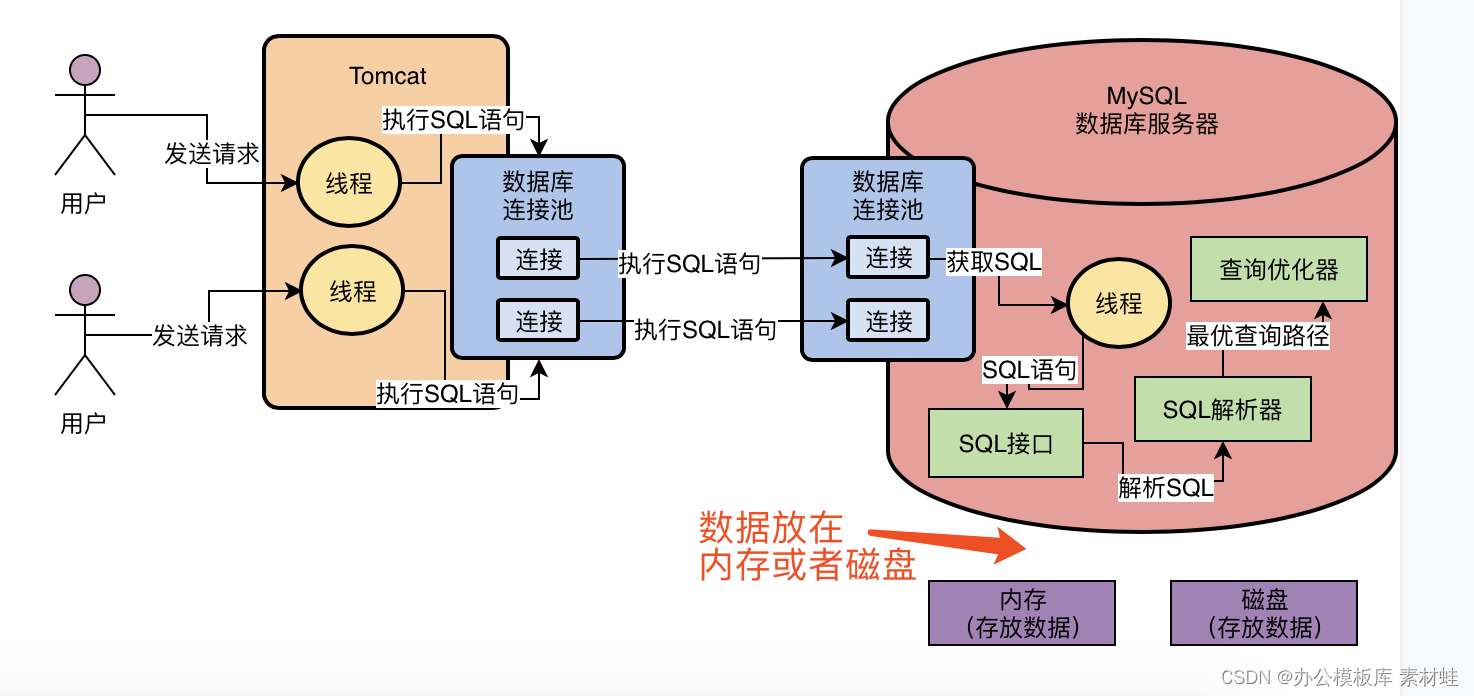
MySQL实战优化高手02 为了执行SQL语句,你知道MySQL用了什么样的架构设计吗?

C杂讲 文件 初讲
MySQL底层的逻辑架构
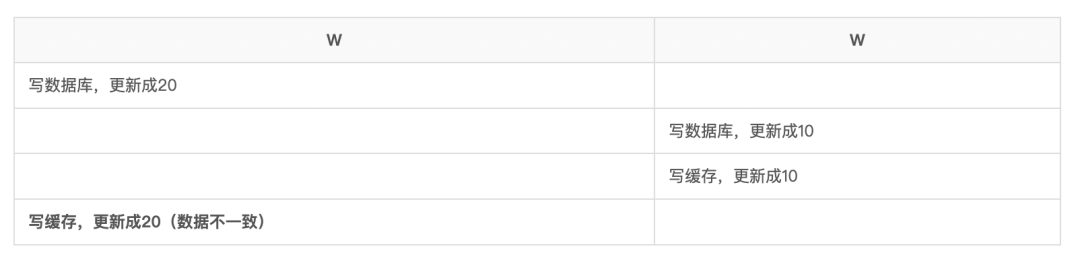
If someone asks you about the consistency of database cache, send this article directly to him

四川云教和双师模式
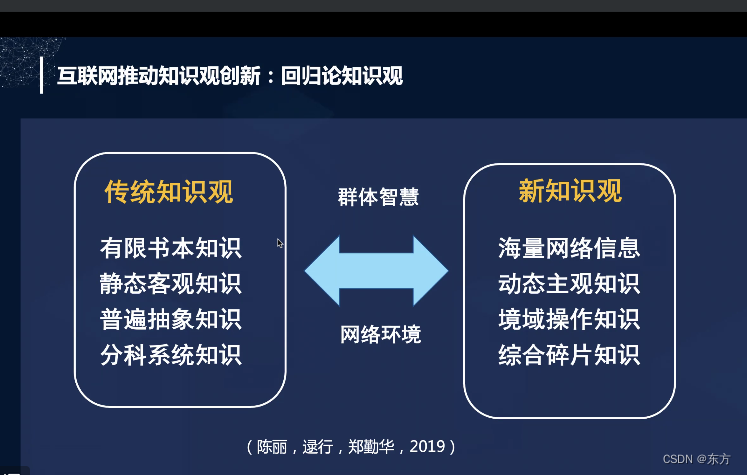
cmooc互联网+教育
Installation of pagoda and deployment of flask project
随机推荐
华南技术栈CNN+Bilstm+Attention
South China Technology stack cnn+bilstm+attention
Record the first JDBC
Chrome浏览器端跨域不能访问问题处理办法
The 32-year-old fitness coach turned to a programmer and got an offer of 760000 a year. The experience of this older coder caused heated discussion
C miscellaneous lecture continued
UEditor国际化配置,支持中英文切换
A necessary soft skill for Software Test Engineers: structured thinking
C杂讲 浅拷贝 与 深拷贝
MySQL combat optimization expert 02 in order to execute SQL statements, do you know what kind of architectural design MySQL uses?
[Julia] exit notes - Serial
Target detection -- yolov2 paper intensive reading
如何搭建接口自动化测试框架?
MySQL real battle optimization expert 11 starts with the addition, deletion and modification of data. Review the status of buffer pool in the database
Installation de la pagode et déploiement du projet flask
MySQL combat optimization expert 06 production experience: how does the production environment database of Internet companies conduct performance testing?
Jar runs with error no main manifest attribute
Notes of Dr. Carolyn ROS é's social networking speech
The governor of New Jersey signed seven bills to improve gun safety
Set shell script execution error to exit automatically