当前位置:网站首页>Pytorch LSTM实现流程(可视化版本)
Pytorch LSTM实现流程(可视化版本)
2022-07-06 09:11:00 【一曲无痕奈何】
# 模型1:Pytorch LSTM实现流程
# 加载数据集
# 使得数据集可迭代(每次读取一个Batch)
# 创建模型类
# 初始化模型类
# 初始化损失类
# 训练模型
# 1. 加载数据集
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 2、下载数据集
trainsets = datasets.MNIST(root = './data2',train = True,download = True,transform = transforms.ToTensor())
testsets = datasets.MNIST(root = './data2',train = False,transform=transforms.ToTensor())
class_names = trainsets.classes #查看类别标签
print(class_names)
# 3、查看数据集大小shape
print(trainsets.data.shape)
print(trainsets.targets.shape)
#4、定义超参数
BASH_SIZE = 32 #每批读取的数据大小
EPOCHS = 10 #训练十轮
# 创建数据集的可迭代对象,也就是说一个batch一个batch的读取数据
train_loader = torch.utils.data.DataLoader(dataset = trainsets, batch_size = BASH_SIZE,shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = testsets, batch_size = BASH_SIZE,shuffle = True)
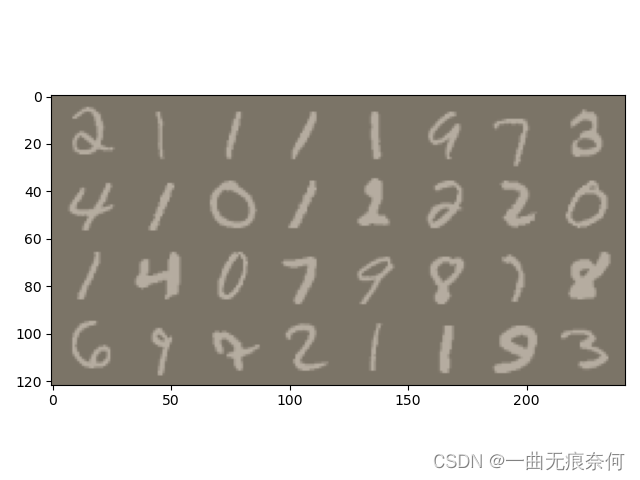
# 查看一批batch的数据
images, labels = next(iter(test_loader))
print(images.shape)
#6、定义函数,显示一批数据
def imshow(inp, title=None):
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406]) # 均值
std = np.array([0.229, 0.224, 0.225]) # 标准差
inp = std * inp + mean
inp = np.clip(inp, 0, 1) # 限速值限制在0-1之间
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
#网格显示
out = torchvision.utils.make_grid(images)
imshow(out)
# 7. 定义RNN模型
class LSTM_Model(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim):
super(LSTM_Model, self).__init__() # 初始化父类中的构造方法
self.hidden_dim = hidden_dim
self.layer_dim = layer_dim
#构建LSTM模型
self.lstm = nn.LSTM(input_dim, hidden_dim, layer_dim, batch_first = True)
#全连接层:
self.fc = nn.Linear(hidden_dim,output_dim)
def forward(self, x):
#初始化隐藏层装态全为0
# (layer_dim, batch_size, hidden_dim)
h0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).requires_grad_().to(device)
# 初始化cell state
c0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).requires_grad_().to(device)
# 分离隐藏状态,以免梯度爆炸
out, (hn, cn) = self.lstm(x, (h0.detach(), c0.detach()))
# 只需要最后一层隐层的状态
out = self.fc(out[:, -1, :])
return out
# 8. 初始化模型
input_dim = 28 #输入维度
hidden_dim = 100 #隐藏的维度
layer_dim = 1 # 1 层
output_dim = 10 #输出维度
#实例化模型传入参数
model = LSTM_Model(input_dim, hidden_dim, layer_dim,output_dim)
#判断是否有GPU
device = torch.device('cuda:()' if torch.cuda.is_available() else 'cpu')
#9、定义损失函数
criterion = nn.CrossEntropyLoss()
#10、定义优化函数
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
#11、输出模型参数
length = len(list(model.parameters()))
#12、循环打印模型参数
for i in range(length):
print('参数: %d' % (i+1))
print(list(model.parameters())[i].size())
# 13 、模型训练
sequence_dim = 28 #序列长度
loss_list = [] #保存loss
accuracy_list = [] #保存accuracy
iteration_list = [] #保存循环次数
iter = 0
for epoch in range(EPOCHS):
for i, (images, labels) in enumerate(train_loader):
model.train() #声明训练
#一个batch的数据转换为LSTM的输入维度
images = images.view(-1, sequence_dim, input_dim).requires_grad_().to(device)
labels = labels.to(device)
#梯度清零(否则会不断增加)
optimizer.zero_grad()
#前向传播
outputs = model(images)
#计算损失
loss = criterion(outputs, labels)
#反向传播
loss.backward()
#更新参数
optimizer.step()
#计数自动加一
iter += 1
#模型验证
if iter % 500 == 0:
model.eval() #声明
#计算验证的accuracy
correct = 0.0
total = 0.0
#迭代测试集、获取数据、预测
for images, labels in test_loader:
images = images.view(-1, sequence_dim, input_dim).to(device)
#模型预测
outputs = model(images)
#获取预测概率的最大值的下标
predict = torch.max(outputs.data,1)[1]
#统计测试集的大小
total += labels.size(0)
# 统计判断/预测正确的数量
if torch.cuda.is_available():
correct += (predict.gpu() == labels.gpu()).sum()
else:
correct += (predict == labels).sum()
#计算 accuracy
accuracy = (correct / total)/ 100 * 100
#保存accuracy, loss iteration
loss_list.append(loss.data)
accuracy_list.append(accuracy)
iteration_list.append(iter)
# 打印信息
print("epoch : {}, Loss : {}, Accuracy : {}".format(iter, loss.item(), accuracy))
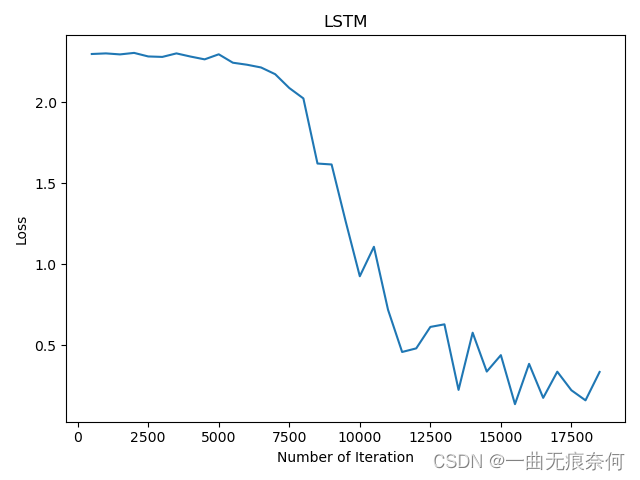
# 可视化 loss
plt.plot(iteration_list, loss_list)
plt.xlabel('Number of Iteration')
plt.ylabel('Loss')
plt.title('LSTM')
plt.show()
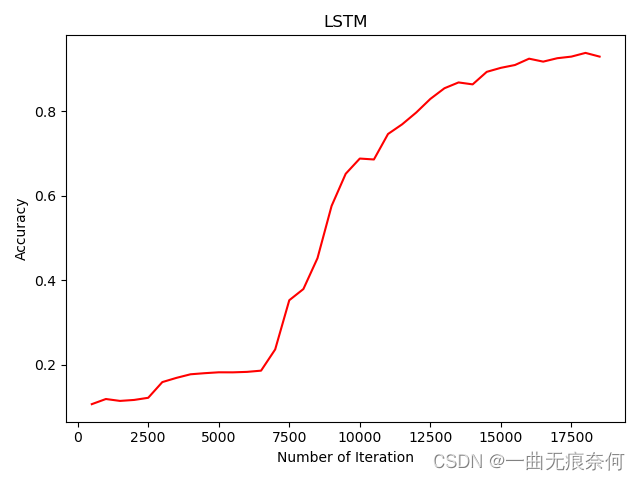
#可视化 accuracy
plt.plot(iteration_list, accuracy_list, color = 'r')
plt.xlabel('Number of Iteration')
plt.ylabel('Accuracy')
plt.title('LSTM')
plt.savefig('LSTM_accuracy.png')
plt.show()
边栏推荐
- [one click] it only takes 30s to build a blog with one click - QT graphical tool
- Retention policy of RMAN backup
- 14 medical registration system_ [Alibaba cloud OSS, user authentication and patient]
- Vh6501 Learning Series
- Mexican SQL manual injection vulnerability test (mongodb database) problem solution
- 美新泽西州州长签署七项提高枪支安全的法案
- [after reading the series of must know] one of how to realize app automation without programming (preparation)
- Notes of Dr. Carolyn ROS é's social networking speech
- MySQL real battle optimization expert 08 production experience: how to observe the machine performance 360 degrees without dead angle in the process of database pressure test?
- Write your own CPU Chapter 10 - learning notes
猜你喜欢
![17 medical registration system_ [wechat Payment]](/img/b4/f9abfa0fb0447d727078069d888b57.png)
17 medical registration system_ [wechat Payment]
Several silly built-in functions about relative path / absolute path operation in CAPL script
软件测试工程师必备之软技能:结构化思维
UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd0 in position 0成功解决
Installation de la pagode et déploiement du projet flask
华南技术栈CNN+Bilstm+Attention
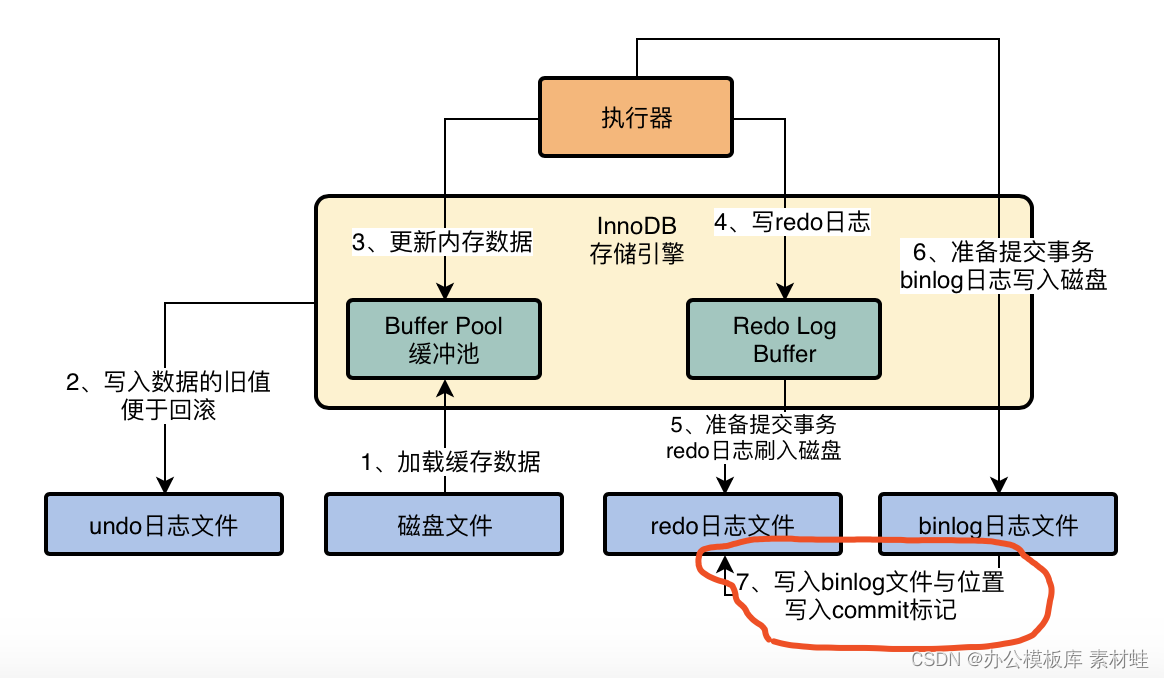
MySQL实战优化高手04 借着更新语句在InnoDB存储引擎中的执行流程,聊聊binlog是什么?

112 pages of mathematical knowledge sorting! Machine learning - a review of fundamentals of mathematics pptx
MySQL combat optimization expert 04 uses the execution process of update statements in the InnoDB storage engine to talk about what binlog is?
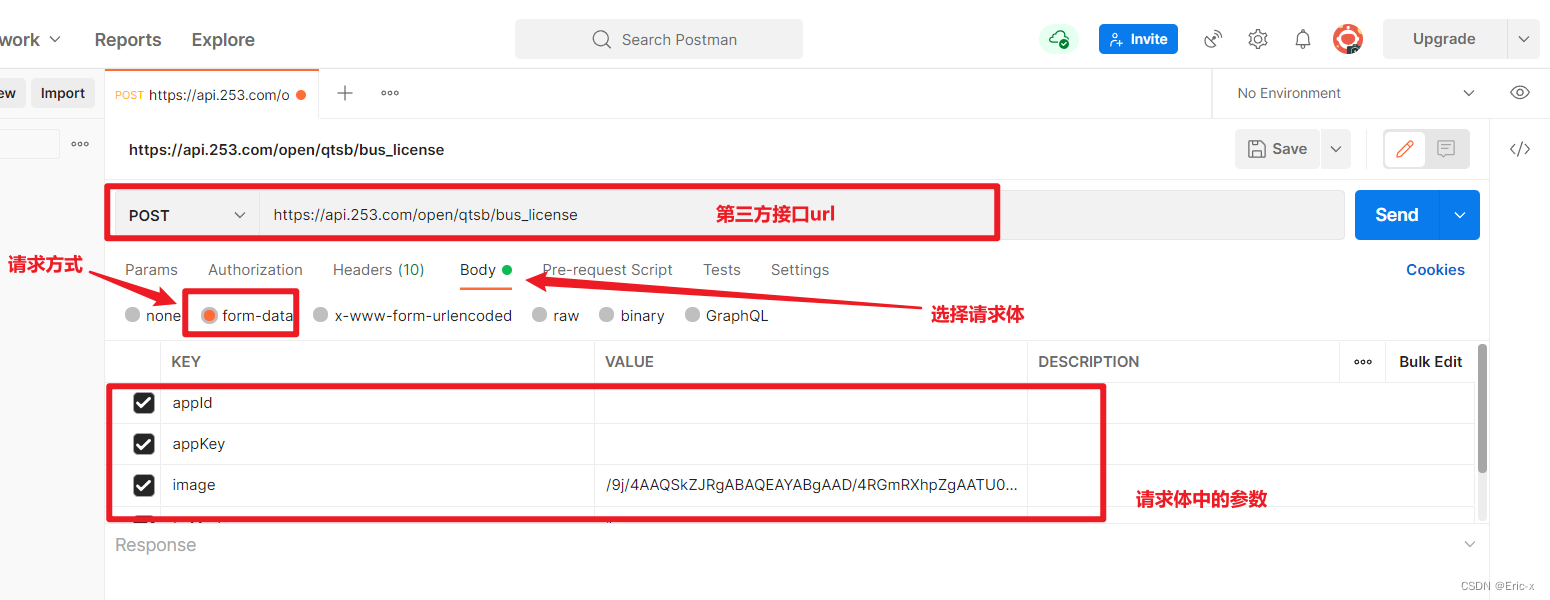
Implement sending post request with form data parameter
随机推荐
112 pages of mathematical knowledge sorting! Machine learning - a review of fundamentals of mathematics pptx
The underlying logical architecture of MySQL
Write your own CPU Chapter 10 - learning notes
CANoe CAPL文件操作目录合集
CAPL 脚本对.ini 配置文件的高阶操作
CANoe下载地址以及CAN Demo 16的下载与激活,并附录所有CANoe软件版本
UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd0 in position 0成功解决
MySQL的存储引擎
Several errors encountered when installing opencv
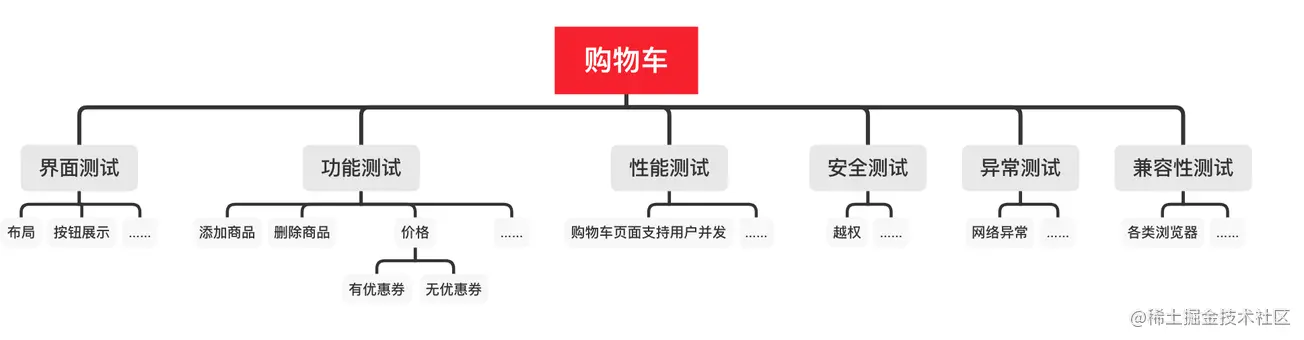
软件测试工程师必备之软技能:结构化思维
竞赛vscode配置指南
软件测试工程师发展规划路线
MySQL combat optimization expert 10 production experience: how to deploy visual reporting system for database monitoring system?
Some thoughts on the study of 51 single chip microcomputer
Good blog good material record link
使用OVF Tool工具从Esxi 6.7中导出虚拟机
The 32 year old programmer left and was admitted by pinduoduo and foreign enterprises. After drying out his annual salary, he sighed: it's hard to choose
UEditor国际化配置,支持中英文切换
MySQL real battle optimization expert 08 production experience: how to observe the machine performance 360 degrees without dead angle in the process of database pressure test?
实现以form-data参数发送post请求