当前位置:网站首页>[NLP] bert4vec: a sentence vector generation tool based on pre training
[NLP] bert4vec: a sentence vector generation tool based on pre training
2022-07-06 09:46:00 【Demeanor 78】
A sentence vector generation tool based on pre training bert4vec:
https://github.com/zejunwang1/bert4vec
Environmental Science
transformers>=4.6.0,<5.0.0
torch>=1.6.0
numpy
huggingface-hub
faiss (optional)
install
Mode one
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ bert4vecMode two
git clone https://github.com/zejunwang1/bert4vec
cd bert4vec/
python setup.py sdist
pip install dist/bert4vec-1.0.0.tar.gzFunction is introduced
At present, the sentence vector pre training models that support loading include SimBERT、RoFormer-Sim and paraphrase-multilingual-MiniLM-L12-v2, among SimBERT And RoFormer-Sim Open source Chinese sentence vector representation model for teacher Su Jianlin ,paraphrase-multilingual-MiniLM-L12-v2 by sentence-transformers Open multilingual pre training model , Support Chinese sentence vector generation .
Sentence vector generation
from bert4vec import Bert4Vec
# Four modes are supported :simbert-base/roformer-sim-base/roformer-sim-small/paraphrase-multilingual-minilm
model = Bert4Vec(mode='simbert-base')
sentences = [' What kind of girls do boys like to play basketball ', ' It snowed in Xi'an ? Is it very cold ?', ' How should parents behave when meeting their girlfriend for the first time ?', ' How about a little tadpole looking for his mother ',
' Recommend me a red car ', ' I like Beijing ']
vecs = model.encode(sentences, convert_to_numpy=True, normalize_to_unit=False)
# encode The default input parameters supported by the function are :batch_size=64, convert_to_numpy=False, normalize_to_unit=False
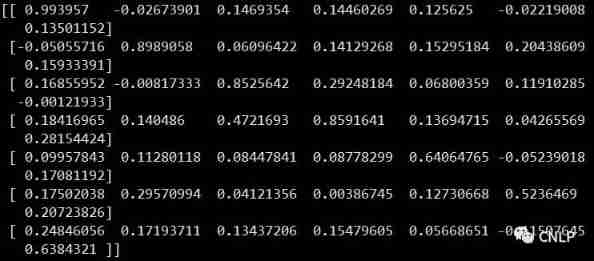
print(vecs.shape)
print(vecs)give the result as follows :

When you need to calculate the dense vector of English sentences , Need to set up mode='paraphrase-multilingual-minilm'.
Similarity calculation
from bert4vec import Bert4Vec
model = Bert4Vec(mode='paraphrase-multilingual-minilm')
sent1 = [' What kind of girls do boys like to play basketball ', ' It snowed in Xi'an ? Is it very cold ?', ' How should parents behave when meeting their girlfriend for the first time ?', ' How about a little tadpole looking for his mother ',
' Recommend me a red car ', ' I like Beijing ', 'That is a happy person']
sent2 = [' What kind of girls do boys like to play basketball ', ' What's the weather like in Xi'an ? Is it still snowing ?', ' What should I do when I see my parents for the first time ', ' Who drew the little tadpole looking for his mother ',
' Recommend me a black car ', ' I don't like Beijing ', 'That is a happy dog']
similarity = model.similarity(sent1, sent2, return_matrix=False)
# similarity The default input parameters supported by the function are :batch_size=64, return_matrix=False
print(similarity)give the result as follows :

hypothesis sent1 contain M A sentence ,sent2 contain N A sentence , When similarity Functional return_matrix Parameter set to False when , The function returns sent1 and sent2 Cosine similarity between two sentences in the same line , Demand at this time M=N, Otherwise, an error will be reported .
When similarity Functional return_matrix Parameter set to True when , The function returns a M*N Similarity matrix , The order of the matrix i Xing di j Column elements represent sent1 Of the i Two sentences and sent2 Of the j Cosine similarity between sentences .
similarity = model.similarity(sent1, sent2, return_matrix=True)
print(similarity)give the result as follows :
Semantic retrieval
bert4vec Support use faiss structure cpu/gpu Sentence vector index ,Bert4Vec Class build_index The function parameters are listed below :
def build_index(
self,
sentences_or_file_path: Union[str, List[str]],
ann_search: bool = False,
gpu_index: bool = False,
n_search: int = 64,
batch_size: int = 64
)sentences_or_file_path: The path of sentence file or sentence list to be indexed .
ann_search: Whether to perform approximate nearest neighbor search . if False, Then perform violent search calculation when searching , Returns the exact result .
gpu_index: Whether to build gpu Indexes .
n_search: The number of search categories for approximate nearest neighbor search , The larger the parameter , The more accurate the search results .
batch_size: The batch size of sentence vector calculation .
Use Chinese-STS-B Verification set (https://github.com/zejunwang1/CSTS) Index all sentences after removing duplicates , The example code for approximate nearest neighbor search is as follows :
from bert4vec import Bert4Vec
model = Bert4Vec(mode='roformer-sim-small')
sentences_path = "./sentences.txt" # examples Under the folder
model.build_index(sentences_path, ann_search=True, gpu_index=False, n_search=32)
results = model.search(queries=[' A man is playing the guitar .', ' A woman is cooking '], threshold=0.6, top_k=5)
# threshold Is the lowest similarity threshold ,top_k Is the number of nearest neighbors found
print(results)give the result as follows :

Bert4Vec Class supports using the following functions to save and load sentence vector index files :
def write_index(self, index_path: str)
def read_index(self, sentences_path: str, index_path: str, is_faiss_index: bool = True)sentences_path The path of sentence file for building sentence vector index ,index_path Store path for sentence vector index .
Model download
The author puts the original SimBERT and RoFormer-Sim Model weights are converted to support the use of Huggingface Transformers Format of the model to load :https://huggingface.co/WangZeJun
from bert4vec import Bert4Vec
model = Bert4Vec(mode='simbert-base', model_name_or_path='WangZeJun/simbert-base-chinese')
model = Bert4Vec(mode='roformer-sim-base', model_name_or_path='WangZeJun/roformer-sim-base-chinese')
model = Bert4Vec(mode='roformer-sim-small', model_name_or_path='WangZeJun/roformer-sim-small-chinese')
model = Bert4Vec(mode='paraphrase-multilingual-minilm', model_name_or_path='sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')mode And model_name_or_path The corresponding relationship is as follows :
| mode | model_name_or_path |
|---|---|
| simbert-base | WangZeJun/simbert-base-chinese |
| roformer-sim-base | WangZeJun/roformer-sim-base-chinese |
| roformer-sim-small | WangZeJun/roformer-sim-small-chinese |
| paraphrase-multilingual-minilm | sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 |
When mode After setting up , No need to set model_name_or_path, The code will start from https://huggingface.co/ Automatically download the corresponding pre training model weights and load .
link
https://github.com/ZhuiyiTechnology/simbert
https://github.com/ZhuiyiTechnology/roformer-sim
https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
Past highlights
It is suitable for beginners to download the route and materials of artificial intelligence ( Image & Text + video ) Introduction to machine learning series download Chinese University Courses 《 machine learning 》( Huang haiguang keynote speaker ) Print materials such as machine learning and in-depth learning notes 《 Statistical learning method 》 Code reproduction album
AI Basic download machine learning communication qq Group 955171419, Please scan the code to join wechat group :
边栏推荐
- 硬件工程师的真实前途我说出来可能你们不信
- Elk project monitoring platform deployment + deployment of detailed use (II)
- 面试突击62:group by 有哪些注意事项?
- 大学C语言入门到底怎么学才可以走捷径
- Global and Chinese market of bank smart cards 2022-2028: Research Report on technology, participants, trends, market size and share
- Mapreduce实例(十):ChainMapReduce
- Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"
- Some thoughts on the study of 51 single chip microcomputer
- Keep these four requirements in mind when learning single chip microcomputer with zero foundation and avoid detours
- MapReduce工作机制
猜你喜欢

A wave of open source notebooks is coming

单片机实现模块化编程:思维+实例+系统教程(实用程度令人发指)
![[deep learning] semantic segmentation: paper reading: (2021-12) mask2former](/img/dd/fe2bfa3563cf478afe431ac87a8cb7.png)
[deep learning] semantic segmentation: paper reading: (2021-12) mask2former
Why can't TN-C use 2p circuit breaker?

MapReduce instance (x): chainmapreduce
嵌入式開發中的防禦性C語言編程
Mapreduce实例(十):ChainMapReduce
Hero League rotation map automatic rotation
工作流—activiti7环境搭建

Regular expressions are actually very simple
随机推荐
Summary of May training - from a Guang
Mapreduce实例(九):Reduce端join
Popularization of security knowledge - twelve moves to protect mobile phones from network attacks
Oom happened. Do you know the reason and how to solve it?
Keep these four requirements in mind when learning single chip microcomputer with zero foundation and avoid detours
Mapreduce实例(五):二次排序
Yarn organizational structure
Detailed explanation of cookies and sessions
I2C summary (single host and multi host)
听哥一句劝,按这套嵌入式的课程内容和课程体系去学习
One article read, DDD landing database design practice
Hard core! One configuration center for 8 classes!
Activiti7工作流的使用
[Chongqing Guangdong education] reference materials for nine lectures on the essence of Marxist Philosophy in Wuhan University
【深度学习】语义分割:论文阅读:(2021-12)Mask2Former
Teach you how to write the first MCU program hand in hand
Mapreduce实例(八):Map端join
Listen to my advice and learn according to this embedded curriculum content and curriculum system
Day 5 of MySQL learning
May brush question 27 - figure