当前位置:网站首页>MapReduce instance (x): chainmapreduce
MapReduce instance (x): chainmapreduce
2022-07-06 09:33:00 【Laugh at Fengyun Road】
MR Realization Reduce End join
Hello everyone , I am Fengyun , Welcome to my blog perhaps WeChat official account 【 Laugh at Fengyun Road 】, In the days to come, let's learn about big data related technologies , Work hard together , Meet a better self !
Realization principle
Some complex tasks are difficult to use once MapReduce Processing is complete , Need more than once MapReduce To complete the task .
Chain treatment
Hadoop2.0 Start MapReduce Jobs support chain processing , Similar to the production line of a factory , Each stage has specific tasks to deal with , For example, provide original accessories ——> assemble ——> Print the date of manufacture , wait . Through this further division of labor , Thus, the production efficiency is improved , We Hadoop Chain in MapReduce So it is with , these Mapper It can be like water , Level by level backward processing , It's kind of like Linux The pipe . Previous Mapper The output result of can be directly used as the next Mapper The input of , Form an assembly line .
The chain MapReduce Implementation rules of : Whole Job There can only be one of them Reducer, stay Reducer There can be one or more in front Mapper, stay Reducer There can be 0 One or more Mapper.
Hadoop2.0 Chain processing supported MapReduce There are three kinds of homework :
(1) Sequential link MapReduce Homework
Be similar to Unix In the pipeline :mapreduce-1 | mapreduce-2 | mapreduce-3 …, Each stage creates one job, And set the current input path to the previous output . Delete the intermediate data generated on the chain in the final stage .
(2) With complex dependencies MapReduce link
if mapreduce-1 Process a data set , mapreduce-2 Process another data set , and mapreduce-3 Make internal links to the first two . This situation passes through Job and JobControl Class manages dependencies between nonlinear jobs . Such as x.addDependingJob(y) signify x stay y It will not start until it is finished .
(3) Links to pretreatment and post-processing
Generally, pretreatment and post-processing are written as Mapper Mission . You can link or use by yourself ChainMapper and ChainReducer class , The generation job expression is similar to :
MAP+ | REDUCE | MAP*
Such as the following work : Map1 | Map2 | Reduce | Map3 | Map4, hold Map2 and Reduce As MapReduce Homework core .Map1 As a pretreatment ,Map3, Map4 As a post-treatment .
ChainMapper Usage mode : Pretreatment job ,ChainReducer Usage mode : Set up Reducer And add post-processing Mapper
The third operation mode is used in this experiment : Links to pretreatment and post-processing , The generation job expression is similar to Map1 | Map2 | Reduce | Map3
Execute the process
mapreduce The general process of execution is shown in the figure below :
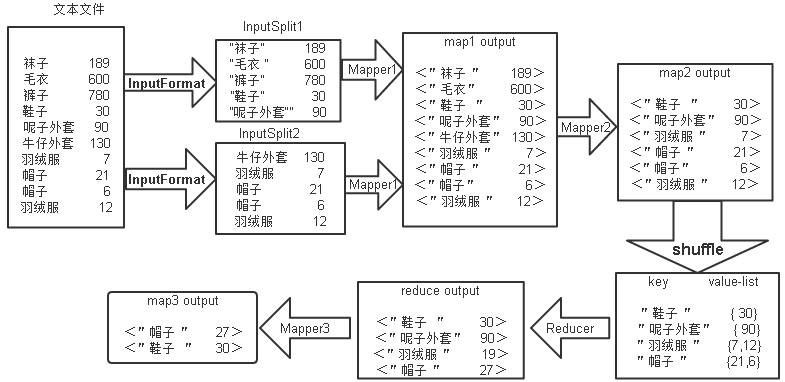
It can be seen from the above figure ,ChainMapReduce The execution process is :
① First, pass the data in the text file InputFormat The instance is cut into multiple small data sets InputSplit, And then through RecordReader The instance will be a small data set InputSplit It can be interpreted as <key,value> And submit to Mapper1;
②Mapper1 Inside map The function will input value For cutting , Take the product name segment as key value , Click the quantity field as value value , select value Value less than or equal to 600 Of <key,value>, take <key,value> Output to Mapper2;
③Mapper2 Inside map Function to filter out value Less than 100 Of <key,value>, And will <key,value> Output ;
④Mapper2 Output <key,value> Key value pairs go through shuffle, take key All with the same value value Put it in a collection , formation <key,value-list>, And then put all the <key,value-list> Input to Reducer;
⑤Reducer Inside reduce Function will value-list The elements in the set are accumulated and summed as new value, And will <key,value> Output to Mapper3;
⑥Mapper3 Inside map Function to filter out key Less than 3 A character <key,value>, And will <key,value> Output in text format to hdfs On . The ChainMapReduce Of Java The code is mainly divided into four parts , Respectively :FilterMapper1,FilterMapper2,SumReducer,FilterMapper3.
Code writing
FilterMapper1 Code
public static class FilterMapper1 extends Mapper<LongWritable, Text, Text, DoubleWritable> {
private Text outKey = new Text(); // Declare objects outKey
private DoubleWritable outValue = new DoubleWritable(); // Declare objects outValue
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context)
throws IOException,InterruptedException {
String line = value.toString();
if (line.length() > 0) {
String[] splits = line.split("\t"); // Segment content by line
double visit = Double.parseDouble(splits[1].trim());
if (visit <= 600) {
//if loop , Judge visit Less than or equal to 600
outKey.set(splits[0]);
outValue.set(visit);
context.write(outKey, outValue); // call context Of write Method
}
}
}
}
First define the output key and value The type of , And then in map Method to get the text line content , use Split(“\t”) Segment the line content , Convert the field containing hits into double Type and assign to visit, use if Judge , If visit Less than or equal to 600, Then set the commodity name field as key, Set the visit As value, use context Of write Method output <key,value>.
FilterMapper2 Code
public static class FilterMapper2 extends Mapper<Text, DoubleWritable, Text, DoubleWritable> {
@Override
protected void map(Text key, DoubleWritable value, Mapper<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException,InterruptedException {
if (value.get() < 100) {
context.write(key, value);
}
}
}
receive mapper1 Incoming data , adopt value.get() Get the input value value , Reuse if Judge if the input value Less than 100, Then input key Assigned to the output key, Input value Assigned to the output value, Output <key,value>.
SumReducer Code
public static class SumReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
private DoubleWritable outValue = new DoubleWritable();
@Override
protected void reduce(Text key, Iterable<DoubleWritable> values, Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
double sum = 0;
for (DoubleWritable val : values) {
sum += val.get();
}
outValue.set(sum);
context.write(key, outValue);
}
}
FilterMapper2 Output <key,value> Key value pairs go through shuffle, take key All with the same value value Put it in a collection , formation <key,value-list>, And then put all the <key,value-list> Input to SumReducer. stay reduce Function , Use enhanced version for Loop traversal value-list Medium element , Accumulate its value and assign it to sum, And then use outValue.set(sum) Method to sum Change the type of to DoubleWritable Type and sum Set to output value, Will input key Assigned to the output key, Last use context Of write() Method output <key,value>.
FilterMapper3 Code
public static class FilterMapper3 extends Mapper<Text, DoubleWritable, Text, DoubleWritable> {
@Override
protected void map(Text key, DoubleWritable value, Mapper<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
if (key.toString().length() < 3) {
//for loop , Judge key Is the value greater than 3
System.out.println(" The content written is :" + key.toString() +"++++"+ value.toString());
context.write(key, value);
}
}
}
receive reduce Incoming data , adopt key.toString().length() obtain key The character length of the value , Reuse if Determine if the key The character length of the value is less than 3, Then input key Assigned to the output key, Input value Assigned to the output value, Output <key,value>.
Complete code
package mapreduce;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.chain.ChainMapper;
import org.apache.hadoop.mapreduce.lib.chain.ChainReducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.DoubleWritable;
public class ChainMapReduce {
private static final String INPUTPATH = "hdfs://localhost:9000/mymapreduce10/in/goods_0";
private static final String OUTPUTPATH = "hdfs://localhost:9000/mymapreduce10/out";
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(OUTPUTPATH), conf);
if (fileSystem.exists(new Path(OUTPUTPATH))) {
fileSystem.delete(new Path(OUTPUTPATH), true);
}
Job job = new Job(conf, ChainMapReduce.class.getSimpleName());
FileInputFormat.addInputPath(job, new Path(INPUTPATH));
job.setInputFormatClass(TextInputFormat.class);
ChainMapper.addMapper(job, FilterMapper1.class, LongWritable.class, Text.class, Text.class, DoubleWritable.class, conf);
ChainMapper.addMapper(job, FilterMapper2.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, conf);
ChainReducer.setReducer(job, SumReducer.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, conf);
ChainReducer.addMapper(job, FilterMapper3.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, conf);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileOutputFormat.setOutputPath(job, new Path(OUTPUTPATH));
job.setOutputFormatClass(TextOutputFormat.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class FilterMapper1 extends Mapper<LongWritable, Text, Text, DoubleWritable> {
private Text outKey = new Text();
private DoubleWritable outValue = new DoubleWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context)
throws IOException,InterruptedException {
String line = value.toString();
if (line.length() > 0) {
String[] splits = line.split("\t");
double visit = Double.parseDouble(splits[1].trim());
if (visit <= 600) {
outKey.set(splits[0]);
outValue.set(visit);
context.write(outKey, outValue);
}
}
}
}
public static class FilterMapper2 extends Mapper<Text, DoubleWritable, Text, DoubleWritable> {
@Override
protected void map(Text key, DoubleWritable value, Mapper<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException,InterruptedException {
if (value.get() < 100) {
context.write(key, value);
}
}
}
public static class SumReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
private DoubleWritable outValue = new DoubleWritable();
@Override
protected void reduce(Text key, Iterable<DoubleWritable> values, Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
double sum = 0;
for (DoubleWritable val : values) {
sum += val.get();
}
outValue.set(sum);
context.write(key, outValue);
}
}
public static class FilterMapper3 extends Mapper<Text, DoubleWritable, Text, DoubleWritable> {
@Override
protected void map(Text key, DoubleWritable value, Mapper<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
if (key.toString().length() < 3) {
System.out.println(" The content written is :" + key.toString() +"++++"+ value.toString());
context.write(key, value);
}
}
}
}
-------------- end ----------------
WeChat official account : Below scan QR code or Search for Laugh at Fengyun Road Focus on 
边栏推荐
- Libuv thread
- Servlet learning diary 7 -- servlet forwarding and redirection
- Redis之主从复制
- 018.有效的回文
- [Yu Yue education] Wuhan University of science and technology securities investment reference
- 基于B/S的医院管理住院系统的研究与实现(附:源码 论文 sql文件)
- Mapreduce实例(六):倒排索引
- Once you change the test steps, write all the code. Why not try yaml to realize data-driven?
- IDS' deletion policy
- Withdrawal of wechat applet (enterprise payment to change)
猜你喜欢
数据建模有哪些模型

Different data-driven code executes the same test scenario
![[deep learning] semantic segmentation - source code summary](/img/2c/50eaef4a11fe2ee9c53a5cebdd69ce.png)
[deep learning] semantic segmentation - source code summary
Segmentation sémantique de l'apprentissage profond - résumé du code source
DCDC power ripple test
Use of activiti7 workflow
![[deep learning] semantic segmentation: paper reading: (CVPR 2022) mpvit (cnn+transformer): multipath visual transformer for dense prediction](/img/f1/6f22f00843072fa4ad83dc0ef2fad8.png)
[deep learning] semantic segmentation: paper reading: (CVPR 2022) mpvit (cnn+transformer): multipath visual transformer for dense prediction
Publish and subscribe to redis
![[three storage methods of graph] just use adjacency matrix to go out](/img/79/337ee452d12ad477e6b7cb6b359027.png)
[three storage methods of graph] just use adjacency matrix to go out
【图的三大存储方式】只会用邻接矩阵就out了
随机推荐
【深度学习】语义分割:论文阅读:(2021-12)Mask2Former
[shell script] use menu commands to build scripts for creating folders in the cluster
The carousel component of ant design calls prev and next methods in TS (typescript) environment
Nacos installation and service registration
Leetcode problem solving 2.1.1
QML control type: menu
Global and Chinese markets for modular storage area network (SAN) solutions 2022-2028: Research Report on technology, participants, trends, market size and share
Oom happened. Do you know the reason and how to solve it?
Pytest parameterization some tips you don't know / pytest you don't know
小白带你重游Spark生态圈!
Blue Bridge Cup_ Single chip microcomputer_ PWM output
Redis之核心配置
MapReduce instance (IV): natural sorting
LeetCode41——First Missing Positive——hashing in place & swap
Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"
[Yu Yue education] reference materials of power electronics technology of Jiangxi University of science and technology
Kratos战神微服务框架(三)
Redis之持久化实操(Linux版)
Redis之Bitmap
【shell脚本】——归档文件脚本