当前位置:网站首页>What should the redis cluster solution do? What are the plans?
What should the redis cluster solution do? What are the plans?
2022-07-06 10:01:00 【Kaka's Java architecture notes】
Use codis programme : Currently used cluster solutions , Basic and twemproxy Consistent effect , But it supports changing the number of nodes , Old node data can be recovered to new hash node .
Redis cluster3.0 A cluster of its own : The characteristic is that his distributed algorithm is not consistent hash, It is hash The concept of slot , As well as its own support node setting slave nodes .
In the business code layer : There are several unrelated Redis example , At the code level key Conduct hash Calculation , Then go to the corresponding Redis Instance operation data . This way is right hash High requirements for layer code , The consideration includes , Alternative algorithm after node failure , Automatic script recovery after data concussion , Instance monitoring and so on .
Redis When will the cluster scheme cause the whole cluster to be unavailable ?
if there be A,B,C Three node cluster , Without copying the model , If node B failed , Then the whole cluster will think that it lacks 5501-11000 This range of slots is not available .

Add picture comments , No more than 140 word ( Optional )
Redis What is the master-slave replication model of a cluster ?
In order to make the cluster available even if some nodes fail or most nodes cannot communicate , So the cluster uses the master-slave replication model , Each node will have N-1 A replica .
Redis Are there any write operations lost in the cluster ? Why? ?
Redis There is no guarantee of strong data consistency , This means that in practice, the cluster may lose write operations under certain conditions .
Redis How are clusters replicated ?
Redis Clusters are replicated asynchronously .
Redis What is the maximum number of nodes in the cluster ?
16384 individual .
Redis How do clusters choose databases ?
Redis At present, the cluster is unable to make database selection , Default in 0 database .
Redis Persistence scheme
Redis What is the persistence of ?
RDB Persistence : This mechanism can generate point in time snapshot of data set in specified time interval (point-in-time snapshot).
AOF Persistence : Record all write commands executed by the server , And when the server starts , Restore the dataset by reexecuting these commands .
AOF All commands in the file are as follows Redis The format of the agreement to save , The new command is appended to the end of the file .Redis just so so Backstage to AOF File rewriting (rewrite), bring AOF The size of the file does not exceed the actual size required to save the dataset state .
AOF and RDB Simultaneous application of : When Redis Restart time , It will give priority to AOF File to restore the dataset , because AOF Number of files saved Data sets are usually better than RDB The data set saved by the file is more complete .
RDB Advantages and disadvantages ?
advantage :RDB It's a very compact (compact) The file of , It has been saved. Redis Data set at a certain point in time . This kind of file is very suitable for backup : For example, you can be near 24 Within hours , Back up every hour RDB file , And every day of every month , Also back up one RDB file . In this case , Even if you encounter problems, you can restore the dataset to a different version at any time .
RDB Ideal for disaster recovery (disaster recovery): It has only one file , And the content is very compact , Sure ( After encryption ) Send it to another data center , Or Amazon S3 in .
RDB Can be maximized Redis Performance of : The parent process is saving RDB The only thing to do when you file is fork Make a sub process , Then this subprocess will handle all the subsequent saving work , The parent process does not need to execute any disks I/O operation .RDB Speed ratio when recovering large data sets AOF It's faster to recover .
shortcoming : If you need to try to avoid losing data in the event of a server failure , that RDB Not for you. . although Redis Allows you to set different savepoints (save point) To control the preservation RDB File frequency , however , because RDB The file needs to save the state of the entire dataset , So it's not an easy operation . So you may at least 5 Minutes to save RDB file .
under these circumstances , In the event of a breakdown stop , You could lose a few minutes of data . Every time you save RDB When ,Redis Both fork() Make a sub process , And it's up to the subprocesses to do the actual persistence work .
When the data set is large ,fork() It can be very time consuming , Cause the server to stop processing the client in a millisecond ; If the data set is very large , also CPU Time is very tight Words , So this kind of stop time may even be as long as a whole second .
AOF Advantages and disadvantages ?
advantage : Use AOF Persistence makes Redis Become very durable (much more durable): You can set different fsync Strategy , Like none fsync, Once per second fsync, Or every time a write command is executed fsync.
AOF The default policy for is per second fsync once , In this configuration ,Redis Still maintain good performance , And even in the event of a breakdown , It will only lose one second of data (fsync Will execute in the background thread , So the main thread can continue to work hard on command requests ).
AOF The file is an append only file Log files for operations (append onlylog), So right. AOF Writing files does not need to be done seek, Even if the log for some reason It contains incomplete commands ( For example, the disk is full when writing , Write stoppages and so on ),redis-check-aof Tools can also easily fix this problem .
Redis Can be in AOF When the file size becomes too large , Automatically in the background AOF Rewrite : The rewritten new AOF The file contains a collection of small commands required to restore the current dataset .
The whole rewrite operation is absolutely safe , because Redis Creating a new AOF Documentation process in , Will continue to append the command to the existing AOF In the document , Even if there is a outage during the rewrite , The existing AOF The files won't be lost loss .
And once it's new AOF File creation complete ,Redis From the old AOF File switch to new AOF file , And start on the new AOF File to append .
shortcoming : For the same dataset ,AOF The volume of the file is usually larger than RDB Volume of file . According to the fsync Strategy ,AOF May be slower than RDB.
In general , Per second fsync Performance is still very high , Shut down fsync It can make AOF Speed and RDB As fast as , Even under high load . But when dealing with large write loads ,RDB More guaranteed maximum delay time (latency).
AOF This has happened in the past bug: Because of individual orders , Lead to AOF When the file is reloaded , Unable to save dataset Restore as it was when it was saved .

Add picture comments , No more than 140 word ( Optional )
How to choose the right way to persist ?
(1) Generally speaking , If you want to achieve enough PostgreSQL Data security of , You should use both persistence functions at the same time .
under these circumstances , When Redis It will be loaded prior to restart AOF File to restore the original data , Because in general AOF Document protection Save more data sets than RDB The data set of the file should be complete .
(2) If you are very concerned about your data , But it can still withstand data loss within a few minutes , Then you can only use RDB Persistence .
(3) Many users only use AOF Persistence , But it's not recommended , Because of timing generation RDB snapshot (snapshot) very Convenient for database backup , also RDB Data set recovery is also faster than AOF Fast recovery , besides , Use RDB You can also avoid AOF programmatic bug.
(4) If you only want your data to exist when the server is running , You can also do it without any persistence .
Redis How to increase the capacity of persistent data and cache ?
(1) If Redis Used as a cache , Use consistent hashes to achieve dynamic capacity expansion .
(2) If Redis Used as a persistent store , Fixed... Must be used keys-to-nodes The mapping relationship , Once the number of nodes is determined, it cannot be changed .
Otherwise ( namely Redis Nodes need to change dynamically ), You must use a system that rebalances data at runtime , At present, there is only Redis Clusters can do this .
Redis What are the memory retirement strategies of ?
Redis The memory knockout strategy in Redis When you run out of memory for caching , How to deal with the need for new writes and the need to apply for additional space The data of .
Global key space selective removal
noeviction: When the memory is not enough to hold the newly written data , Error will be reported in new write operation .
allkeys-lru: When the memory is not enough to hold the newly written data , In key space , Remove the recently used key.
allkeys-random: When the memory is not enough to hold the newly written data , In key space , Randomly remove a key.
Set expiration time for key space selective removal
volatile-lru: When the memory is not enough to hold the newly written data , And set the expiration time in the key space , Remove recently used Of key.
volatile-random: When the memory is not enough to hold the newly written data , In key space with expiration time set , Randomly remove a individual key.
volatile-ttl: When the memory is not enough to hold the newly written data , In key space with expiration time set , With an earlier expiration time key Remove first .Briefly describe Redis Threading model
Redis be based on Reactor The pattern develops a network event handler , This processor is called the file event handler (file event handler).
It's made up of 4 part : Multiple sockets 、IO Multiplexing program 、 File event dispatcher 、 Event handler .
Because the consumption of the file event dispatcher queue is single threaded , therefore Redis It's called the single thread model .
The file event handler uses I/O Multiplexing (multiplexing) Program to listen to multiple sockets at the same time , And according to the socket To associate different event handlers for the socket .
When the listening socket is ready to perform the connection answer (accept)、 Read (read)、 write in (write)、 close (close) When waiting for operation , The file event corresponding to the operation will generate , At this time, the file event handler will call the event handler associated with the socket to handle these events .
Although the file event handler runs in a single thread , But by using I/O Multiplexer to listen for multiple sockets , The file event processor has realized the high performance network communication model , It can also be very good with Redis Other modules in the server also run in a single thread mode for docking , This keeps Redis The simplicity of internal single thread design .
Redis Other implementations of transactions ?
(1) be based on Lua Script ,Redis It can ensure that the commands in the script are one-time 、 To execute in order , It also does not provide rollback of transaction running errors , If some commands run incorrectly during execution , The rest of the command will continue to run .
(2) Based on the middle marker variable , Another flag variable is used to identify whether the transaction is completed , When reading data, read the marked variable first Determine whether the transaction execution is complete . But this will require additional code implementation , More complicated .

Add picture comments , No more than 140 word ( Optional )
Redis Cache avalanche and cache breakdown
Simply talk about cache avalanche and Its Solutions
Cache avalanche can be simply understood as : Due to the original cache failure , Period before new cache ( for example : We set up the cache with the same expiration time , Large cache expiration occurs at the same time ), All should have visited Query the database for all cached requests , And for databases CPU And memory , Serious will cause database downtime . Thus a series of chain reactions are formed , Cause the whole system to crash .)
terms of settlement : Most system designers consider locking ( Use multiple solutions ) Or the way of queue ensures that there will not be a large number of threads reading and writing to the database at one time , So as to avoid a large number of concurrent requests falling on the underlying storage system in case of failure . Another simple solution is to set the cache expiration time to disperse .
How cache penetration leads to ?
Send a query in the high and key Nonexistent data , Will go through the cache to query the database . This leads to excessive pressure on the database and downtime .
resolvent :
1. The query result is also cached if it is empty , Cache time (ttl) Set it short , Or should key Corresponding data insert Clean up the cache after . shortcoming : Caching too many null values takes up more space .
2. Using the bloon filter . Add a layer of bloon filter before caching , In the query, first go to the bloom filter to query key Whether there is , If it doesn't exist, go straight back , There is a re search cache and DB.
Principle of bloon filter : When an element is added to a collection , Pass this element through n Time Hash The result of the function is mapped to... In an array n A little bit , Set them as 1. Search time , We just need to see if these points are all 1 Just ( about ) Know if it's in the collection , If any of these points 0, The inspected element must not be in ; If it's all 1, Then the inspected element is likely to be . In short, the bloom filter is a large binary bit group , There is only... In the array 0 and 1.
Cache breakdown has occurred in the project , Simply tell me what's going on ?
When the cache expires at a certain point in time , Right at this point in time Key There are a lot of concurrent requests coming , These requests find that the cache expires, and generally load data from the database and set it back to the cache , At this time, a large number of concurrent requests may instantly put the back end DB Overwhelmed .
Solution :
1. Controlling access threads with distributed locks , Use redis Of setnx The mutex is judged first , So the other threads are waiting , Ensure that there will be no large concurrent operations to operate the database .
2. No timeout , use volatile-lru Elimination strategy shortcoming : Will cause write consistency problems , When the database data is updated , The data in the cache will not be updated in time , This will cause inconsistency between the data in the database and the data in the cache , The application will read dirty data from the cache . Delay double deletion strategy can be adopted to deal with .
Redis Cache consistency and contention
Encountered cache consistency problem , How did you solve it ?
Because the cache and database do not belong to the same data source , Essentially non atomic operation , So there is no guarantee of strong consistency , Only to achieve final consistency .
Solution :
Delay double delete : First update the database and delete the cache , etc. 2 Delete the cache again in seconds , Wait until it is read before writing back to the cache .
utilize an instrument (canal) The binlog Log collection sent to MQ in , And then through ACK Mechanism confirmation processing delete cache .
Why use Redis without map/guava Do the cache ?
Cache is divided into local cache and distributed cache : With Java For example , Use native map perhaps guava The implementation is local cache , The main features are lightweight and fast , The life cycle follows jvm The destruction of , And in the case of multiple instances , Each instance needs to save a cache , Cache is not consistent .
Use Redis or MemoryCache It's called distributed caching , In the case of multiple instances , Each instance shares a cache data , The cache is consistent .
The disadvantage is that you need to keep redis or memcached High availability of services , The whole program structure is more complex .
How to solve Redis The concurrent competition of Key problem ?
So-called Redis The concurrent competition of Key The problem is that multiple systems work on one at the same time key To operate , But the order of post execution is different from what we expect , This leads to different results .
Recommend a solution : Distributed lock (zookeeper and redis Distributed locks can be implemented ). If it doesn't exist Redis Concurrent race dispute Key problem , Don't use distributed locks , This will affect performance .
be based on zookeeper Distributed locks that temporary ordered nodes can implement .
The general idea is : When each client locks a method , stay zookeeper Under the directory of the specified node corresponding to the method , Generate a unique instantaneous ordered node .
The way to determine whether to acquire a lock is simple , Only one of the ordered nodes with a small sequence number needs to be judged . When the lock is released , Just delete the instantaneous node . meanwhile , It can avoid the lock cannot be released due to service downtime , And the deadlock problem . After completing the business process , Delete the corresponding child node to release the lock .
In practice , Of course, it depends on reliability , So first Zookeeper.
What is? RedLock?
Redis The official station put forward an authority based on Redis The way to implement distributed locks is called Redlock, This way is better than the original single section The point method is safer .
It guarantees the following characteristics :
Safety features : Exclusive access , That is, there will always be only one client Can get the lock
Avoid deadlock : Final client You can get the lock , There will be no deadlock , Even if a resource is locked in client crash Or network partition
Fault tolerance : As long as most Redis If the node survives, it can provide services normally When cache degradation is needed ?
When the number of visitors soars 、 There's a problem with the service ( If response time is slow or unresponsive ) Or when non core services affect the performance of core processes , still You need to ensure that the service is still available , Even if it's damaging service .
The system can automatically degrade according to some key data , You can also configure on Close to realize manual degradation .
The ultimate purpose of cache degradation is to ensure the availability of core services , Even if it's damaging .
And some services can't be downgraded ( If you join the shopping vehicle 、 Settlement ).
Sort out the system before degradation , Let's see if the system can lose the guard ; So as to sort out what must be protected by oath , What can be degraded ; For example, you can refer to the log level to set the plan :
commonly : For example, some services sometimes time out due to network jitter or service being online , Can be degraded automatically ;
Warning : Some services have varying success rates over time ( If in 95~100% Between ), Can be degraded automatically or manually , And send an alarm ;
error : For example, the availability rate is lower than 90%, Or the database connection pool is destroyed , Or the number of visits suddenly soars to what the system can bear Large threshold , At this time, it can be degraded automatically or manually according to the situation ;
Serious mistakes : For example, the data is wrong for special reasons , At this time, it needs to be degraded manually . The purpose of service degradation , To prevent Redis Service failure , Cause the database to avalanche .
therefore , Not important for Cache data , Service degradation strategy can be adopted , For example, a common practice is ,Redis Problems arise , Don't go to the database Inquiry , Instead, it directly returns the default value to the user .How to ensure the cache and database double write data consistency ?
You just use cache , It may involve both cache and database storage and write , All you have to do is double write , There must be data consistency , So how do you solve the consistency problem ?
Generally speaking , That is, if your system is not strict with caching + If the database must be consistent , Cache can be slightly inconsistent with database occasionally , Do not do this plan , Serialization of read and write requests , String to a memory queue , This will ensure that there will be no inconsistency .
After serialization , The throughput of the system will be greatly reduced , To support a request on a line with several times more machines than normal .
Another way is that there may be a temporary inconsistency , But the chances of it happening are very small , Just update the database first , And then again Delete cache .
The liver is over , Thank you for your support !
边栏推荐
- Hugo blog graphical writing tool -- QT practice
- I2C summary (single host and multi host)
- [NLP] bert4vec: a sentence vector generation tool based on pre training
- Function description of shell command parser
- Canoe CAPL file operation directory collection
- What are the models of data modeling
- Learning SCM is of great help to society
- 13 医疗挂号系统_【 微信登录】
- CAPL脚本中关于相对路径/绝对路径操作的几个傻傻分不清的内置函数
- NLP routes and resources
猜你喜欢



随机推荐
Competition vscode Configuration Guide
Defensive C language programming in embedded development
简单解决phpjm加密问题 免费phpjm解密工具
CANoe CAPL文件操作目录合集
机械工程师和电气工程师方向哪个前景比较好?
[untitled]
vscode 常用的指令
oracle sys_ Context() function
CDC: the outbreak of Listeria monocytogenes in the United States is related to ice cream products
Cooperative development in embedded -- function pointer
[CV] target detection: derivation of common terms and map evaluation indicators
大学C语言入门到底怎么学才可以走捷径
History of object recognition
Combined search /dfs solution - leetcode daily question - number of 1020 enclaves
CAPL 脚本对.ini 配置文件的高阶操作
14 医疗挂号系统_【阿里云OSS、用户认证与就诊人】
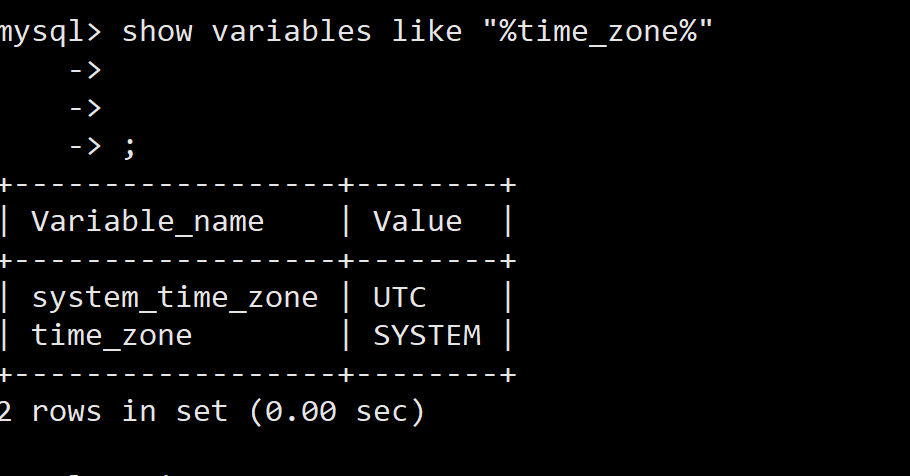
Docker MySQL solves time zone problems
Listen to my advice and learn according to this embedded curriculum content and curriculum system
安装OpenCV时遇到的几种错误
Bugku web guide