当前位置:网站首页>Mysql25 index creation and design principles
Mysql25 index creation and design principles
2022-07-06 10:33:00 【Protect our party a Yao】
One . Declaration and use of index
1.1. Classification of indexes
MySQL The index of includes the general index 、 Uniqueness index 、 Full-text index 、 Single index 、 Multi column index, spatial index, etc .
- from Functional logic Say above , The index mainly includes 4 Kind of , They are ordinary indexes 、 unique index 、 primary key 、 Full-text index .
- according to Physical implementation , The index can be divided into 2 Kind of : Clustered index and non clustered index .
- according to Number of action fields division , Divided into single column index and joint index .
Summary : Different storage engines support different index types InnoDB : Support B-tree、Full-text Wait for the index , I won't support it Hash Indexes ; MyISAM : Support B-tree、Full-text Wait for the index , I won't support it Hash Indexes ; Memory : Support B-tree、Hash Wait for the index , I won't support it Full-text Indexes ; NDB : Support Hash Indexes , I won't support it B-tree、Full-text Wait for the index ; Archive : I won't support it B-tree、Hash、Full-text Wait for the index ;
1.2. Create index
1.2.1. Create indexes when creating tables
give an example :
CREATE TABLE dept(
dept_id INT PRIMARY KEY AUTO_INCREMENT,#int type , Self increasing
dept_name VARCHAR(20)
);
CREATE TABLE IF NOT EXISTS emp(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(20) UNIQUE,
dept_id INT,
CONSTRAINT emp_dept_id_fk FOREIGN KEY(dept_id) REFERENCES dept(dept_id)
)


however , If you create an index when explicitly creating a table , The basic syntax is as follows :
CREATE TABLE table_name [col_name data_type]
[UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name [length]) [ASC |
DESC]
- UNIQUE 、 FULLTEXT and SPATIAL Is an optional parameter , Each represents a unique index 、 Full text index and spatial index ;
- INDEX And KEY For synonyms , The two have the same effect , Used to specify index creation ;
- index_name Specify the name of the index , Is an optional parameter , If you don't specify , that MySQL Default col_name For index name ;
- col_name For the field columns that need to be indexed , The column must be selected from multiple columns defined in the data table ;
- length Is an optional parameter , Indicates the length of the index , Only fields of string type can specify index length ;
- ASC or DESC Specifies the index value store in ascending or descending order .
1.2.2. Create a normal index
stay book In the table year_publication Field ,SQL The statement is as follows :
CREATE TABLE IF NOT EXISTS book(
book_id INT,
book_name VARCHAR(100),
`authors` VARCHAR(100),
info VARCHAR(100),
COMMENT VARCHAR(100),
year_publication YEAR,
INDEX(year_publication)
);
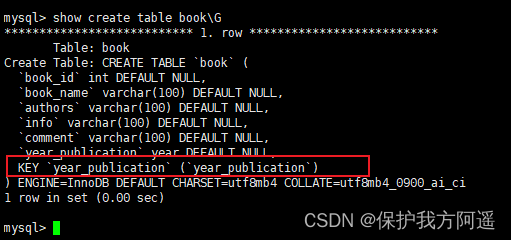
1.2.3. Create unique index
CREATE TABLE IF NOT EXISTS test1(
id INT NOT NULL,
`name` VARCHAR(30) NOT NULL,
UNIQUE INDEX uk_idx_id(id)
)
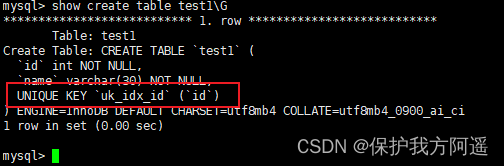
1.2.4. primary key
After setting it as the primary key, the database will automatically create an index ,innodb Index for clustering , grammar :
- Index with table :
CREATE TABLE IF NOT EXISTS student(
id INT(10) UNSIGNED AUTO_INCREMENT,
student_no VARCHAR(200),
student_name VARCHAR(200),
PRIMARY KEY(id)
);
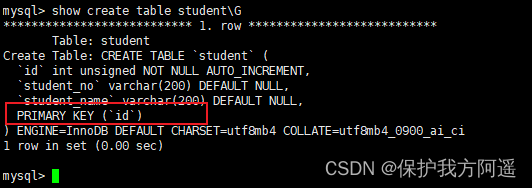
- Delete primary key index :
ALTER TABLE student
drop PRIMARY KEY ;
- Modify the primary key index : You must delete (drop) The original index , New again (add) Indexes .
1.2.5. Create a single column index
CREATE TABLE IF NOT EXISTS test2(
id INT NOT NULL,
`name` CHAR(50) NULL,
INDEX single_idx_name(`name`(20))
);
After the statement is executed , Use SHOW CREATE TABLE View table structure :
SHOW INDEX FROM test2 \G
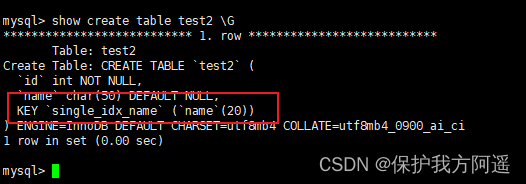
1.2.6. Create a composite index
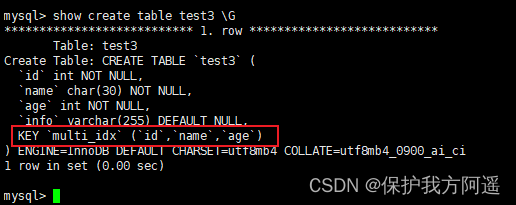
give an example : Create table test3, In the table id、name and age Build a composite index on the field ,SQL The statement is as follows :
CREATE TABLE IF NOT EXISTS test3(
id INT(11) NOT NULL,
NAME CHAR(30) NOT NULL,
age INT(3) NOT NULL,
info VARCHAR(255),
INDEX multi_idx(id,NAME,age)
);
1.2.7. Create full text index
give an example 1: Create table test4, In the table info Create a full-text index on the field ,SQL The statement is as follows :
CREATE TABLE IF NOT EXISTS test4(
id INT(11) NOT NULL,
NAME CHAR(30) NOT NULL,
age INT(3) NOT NULL,
info VARCHAR(255),
FULLTEXT INDEX (info)
) ENGINE=MYISAM;
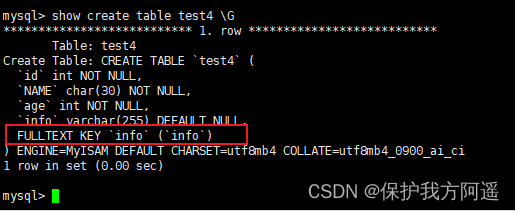
notes : stay MySQL5.7 And later versions may not specify the last ENGINE 了 , Because in this version InnoDB Full text index support .
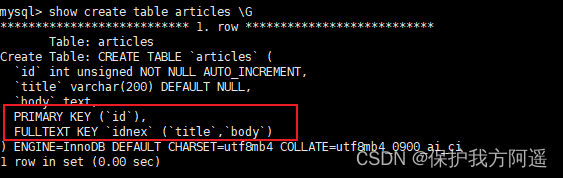
give an example 2:
# Created a for title and body Fields to add full-text indexed tables .
CREATE TABLE IF NOT EXISTS articles(
id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(200),
`body` TEXT,
FULLTEXT idnex(title,`body`)
)
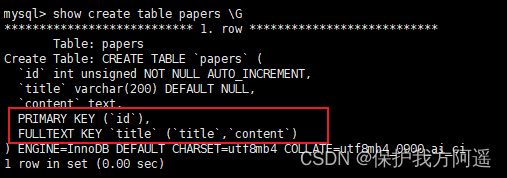
give an example 3:
CREATE TABLE IF NOT EXISTS papers(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
title VARCHAR(200) DEFAULT NULL,
content TEXT,
PRIMARY KEY (id),
FULLTEXT KEY title(title,content)
);
differ like Way of query :
SELECT * FROM papers WHERE content LIKE ‘% Query string %’;
Full text citation match+against Mode query :
SELECT * FROM papers WHERE MATCH(title,content) AGAINST (‘ Query string ’);
Be careful
- Before using full-text indexing , Find out the version support ;
- Full text index ratio like + % fast N times , But there may be precision problems ;
- If you need a large amount of data for full-text indexing , It is recommended to add data first , Then create the index .
1.2.8. Create spatial index
The spatial index is being created , The required field of space type must be Non empty .
give an example : Create table test5, The space type is GEOMETRY Create a spatial index on the field of ,SQL The statement is as follows :
CREATE TABLE IF NOT EXISTS test5(
geo GEOMETRY NOT NULL,
SPATIAL INDEX spa_inx_geo(geo)
)
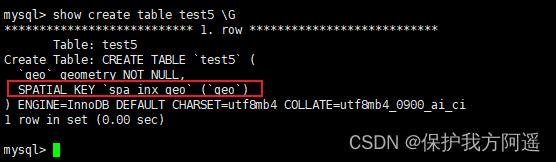
1.2.9. Create an index on an existing table
To create an index in an existing table, you can use ALTER TABLE Statements or CREATE INDEX sentence .
- Use ALTER TABLE Statement to create an index ALTER TABLE The basic syntax of creating an index with statement is as follows :
ALTER TABLE table_name ADD [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY]
[index_name] (col_name[length],...) [ASC | DESC]
- Use CREATE INDEX Create index CREATE INDEX Statement can add an index to an existing table , stay MySQL in ,CREATE INDEX Mapped to a ALTER TABLE On statement , The basic grammatical structure is :
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name
ON table_name (col_name[length],...) [ASC | DESC]
1.3. Delete index
- Use ALTER TABLE Delete index ALTER TABLE The basic syntax for deleting an index is as follows :
ALTER TABLE table_name DROP INDEX index_name;
- Use DROP INDEX Statement to delete the index DROP INDEX The basic syntax for deleting an index is as follows :
DROP INDEX index_name ON table_name;
Tips : When deleting columns in a table , If the column to be deleted is part of the index , The column is also removed from the index . If all the columns that make up the index are deleted , Then the entire index will be deleted .
Two . MySQL8.0 Index new features
2.1. Support descending index
give an example : Respectively in MySQL 5.7 Version and MySQL 8.0 Create data table in version ts1, give the result as follows :
CREATE TABLE ts1(
a INT,
b INT,
INDEX idx_a_b(a,b DESC));
stay MySQL 5.7 View data table in version ts1 Structure , give the result as follows :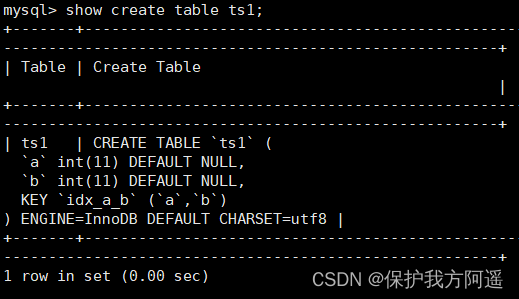
It can be seen from the results , The index is still the default ascending order .
stay MySQL 8.0 View data table in version ts1 Structure , give the result as follows :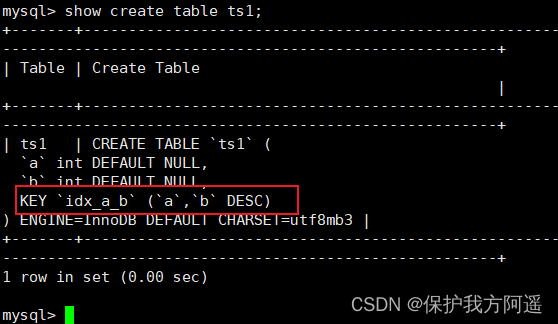 It can be seen from the results , The index is already in descending order . Next, continue to test the performance of the descending index in the execution plan .
It can be seen from the results , The index is already in descending order . Next, continue to test the performance of the descending index in the execution plan .
Respectively in MySQL 5.7 Version and MySQL 8.0 Version of the data sheet ts1 Insert 800 Random data , The execution statement is as follows :
DELIMITER $
CREATE PROCEDURE ts_insert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<800
DO
INSERT INTO ts1 SELECT RAND()*80000,RAND()*80000;
SET i = i+1;
END WHILE;
COMMIT;
END $
DELIMITER ;
call :
CALL ts_insert();
stay MySQL 5.7 View data table in version ts1 Implementation plan of , give the result as follows :
EXPLAIN SELECT * FROM ts1 ORDER BY a,b DESC LIMIT 5;

It can be seen from the results , The number of scans in the execution plan is 799, And used Using filesort.
Tips Using filesort yes MySQL A slow external sort in , It's best to avoid . Most of the time , Administrators
You can optimize the index to avoid Using filesort, So as to improve the execution speed of the database .
stay MySQL 8.0 View data table in version ts1 Implementation plan of . It can be seen from the results , The number of scans in the execution plan is 5, And it didn't use Using filesort.
Be careful A descending index is only valid for a specific sort order in the query , If not used properly , On the contrary, the query efficiency is lower . for example , Above
Change the query sorting criteria to order by a desc, b desc,MySQL 5.7 The implementation plan of is obviously better than MySQL 8.0.
Change the sorting condition to order by a desc, b desc after , Let's compare the effect of execution plan in different versions . stay MySQL 5.7 edition
View data table in ts1 Implementation plan of , give the result as follows : stay MySQL 8.0 View data table in version ts1 Implementation plan of , give the result as follows :
stay MySQL 8.0 View data table in version ts1 Implementation plan of , give the result as follows :
It can be seen from the results , After modification MySQL 5.7 The implementation plan of is obviously better than MySQL 8.0.
2.2. Hide index
stay MySQL 5.7 Version and before , The index can only be dropped explicitly . here , If you find an error after deleting the index , The deleted index can only be created back by explicitly creating the index . If the amount of data in the data table is very large , Or the data sheet itself is relatively large , This operation will consume too many resources of the system , The operating cost is very high .
from MySQL 8.x Start supporting Hide index (invisible indexes) , You only need to set the index to be deleted as a hidden index , Make the query optimizer no longer use this index ( Even using force index( Force index ), The optimizer will not use the index either ), After confirming that the index is set as hidden index, the system will not receive any response , You can completely delete the index . This is done by first setting the index to a hidden index , The way to delete the index again is to soft delete .
- Create directly when creating a table stay MySQL Create a hidden index in SQL sentence INVISIBLE To achieve , Its grammatical form is as follows :
CREATE TABLE tablename(
propname1 type1[CONSTRAINT1],
propname2 type2[CONSTRAINT2],
......
propnamen typen,
INDEX [indexname](propname1 [(length)]) INVISIBLE
);
The above statement has one more keyword than the ordinary index INVISIBLE, Used to mark the index as invisible .
- Create... On an existing table
You can set hidden indexes for existing tables , Its grammatical form is as follows :
CREATE INDEX indexname
ON tablename(propname[(length)]) INVISIBLE;
- adopt ALTER TABLE Sentence creation
The grammatical form is as follows :
ALTER TABLE tablename
ADD INDEX indexname (propname [(length)]) INVISIBLE;
- Toggles the visible state of the index The existing index can be switched to the visible state by the following statement :
ALTER TABLE tablename ALTER INDEX index_name INVISIBLE; # Switch to hide index
ALTER TABLE tablename ALTER INDEX index_name VISIBLE; # Switch to non hidden index
If you will index_cname The index is switched to the visible state , adopt explain View execution plan , It was found that the optimizer chose index_cname Indexes .
Be careful When the index is hidden , Its contents are still updated in real time just like normal indexes . If an index needs to be hidden for a long time
hidden , Then you can delete it , Because the existence of the index will affect the insertion 、 Update and delete performance .
- By setting the visibility of the hidden index, you can see the help of the index to tuning .
Make the hidden index visible to the query optimizer stay MySQL 8.x In the version , It provides a new test method for index , You can query a switch of the optimizer (use_invisible_indexes) To open a setting , Make the hidden index visible to the query optimizer . Such as use_invisible_indexes Set to off( Default ), The optimizer ignores hidden indexes . If set to on, Even if the hidden index is not visible , The optimizer will still consider using hidden indexes when generating execution plans .
(1) stay MySQL The command line executes the following command to view the switch settings of the query optimizer .
select @@optimizer_switch \G
Find the following attribute configuration in the output result information .
use_invisible_indexes=off
The configuration value of this property is off, Description the hidden index is not visible to the query optimizer by default .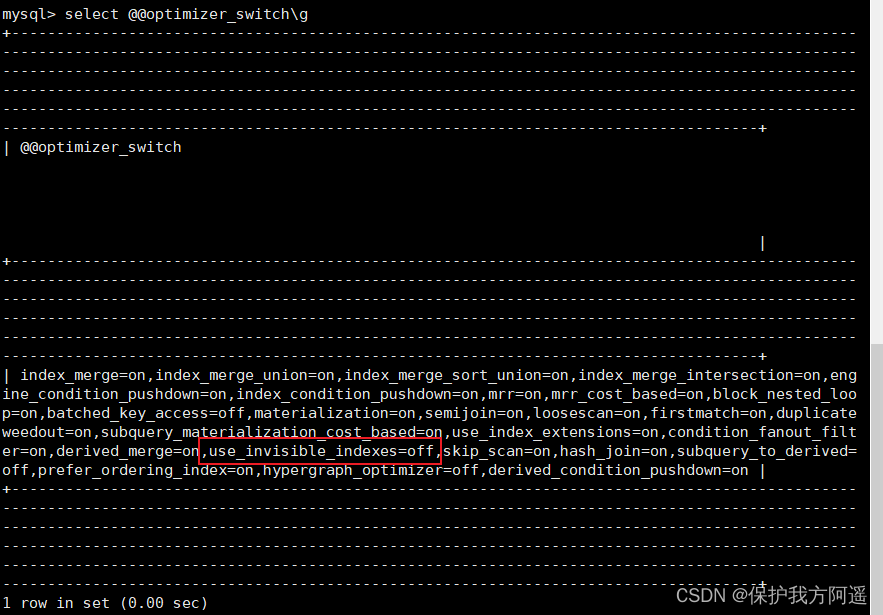
(2) Make the hidden index visible to the query optimizer , Need to be in MySQL The command line executes the following commands :
set session optimizer_switch="use_invisible_indexes=on";
SQL Statement executed successfully , Check the switch settings of the query optimizer again .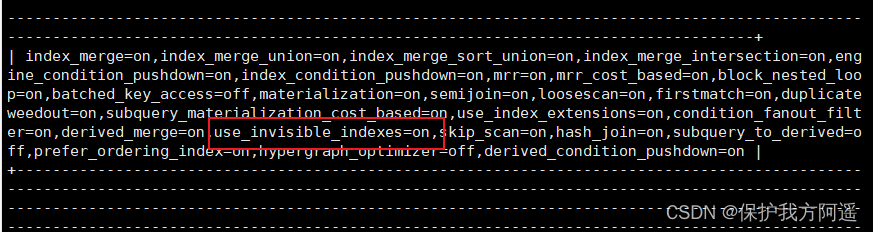
here , In the output result, you can see the following attribute configuration .
use_invisible_indexes=on
use_invisible_indexes The value of the property is on, Note that the hidden index is visible to the query optimizer at this time .
(3) If you need to make the hidden index invisible to the query optimizer , Then you only need to execute the following commands .
set session optimizer_switch="use_invisible_indexes=off";
here ,use_invisible_indexes The value of the property has been set to “off”.
3、 ... and . The design principle of index
3.1. Data preparation
The first 1 Step : Create database 、 Create table
CREATE DATABASE IF NOT EXISTS dbtest2;
USE dbtest2;
#1. Create student and course schedules
CREATE TABLE `student_info` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`student_id` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`course_id` INT NOT NULL ,
`class_id` INT(11) DEFAULT NULL,
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
CREATE TABLE `course` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`course_id` INT NOT NULL ,
`course_name` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
The first 2 Step : Create storage functions necessary for analog data
# function 1: Create a randomly generated string function
DELIMITER $
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXY';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i< n DO
SET return_str = CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i+1;
END WHILE;
RETURN return_str;
END $
DELIMITER ;
# function 2: Create a random number function
DELIMITER $
CREATE FUNCTION rand_num(from_num INT,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num+RAND()*(to_num-from_num+1));
RETURN i;
END $
DELIMITER;
Create a function , If it's wrong :
This function has none of DETERMINISTIC......
Due to opening too slow query log bin-log, We have to be for our function Specify a parameter .
Master slave copy , The host will record the write operation in bin-log In the log . Read from machine bin-log journal , Execute statements to synchronize data . If you use functions to manipulate data , The operation time of slave and primary key will be inconsistent . therefore , By default ,mysql Do not turn on create function settings .
- see mysql Whether to allow the creation of functions :
show variables like 'log_bin_trust_function_creators';
- Command on : Allows you to create function settings :
set global log_bin_trust_function_creators=1; # No addition global Only the current window is valid .
- mysqld restart , The above parameters will disappear again . Permanent method :
- windows Next :my.ini[mysqld] add :
og_bin_trust_function_creators=1
- linux Next :/etc/my.cnf Next my.cnf[mysqld] add :
log_bin_trust_function_creators=1
The first 3 Step : Create a stored procedure that inserts analog data
# stored procedure 1: Create and insert a course schedule stored procedure
DELIMITER $
CREATE PROCEDURE inset_course(max_num INT)
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;# Set up manual commit transactions
REPEAT
SET i = i+1;# assignment
INSERT INTO course (course_id,course_name) VALUES
(rand_num(1000,10100),rand_string(6));
UNTIL i = max_num
END REPEAT;
COMMIT ; # Commit transaction
END $
DELIMITER ;
# stored procedure 2: Create a stored procedure to insert student information table
DELIMITER //
CREATE PROCEDURE insert_stu( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; # Set up manual commit transactions
REPEAT # loop
SET i = i + 1; # assignment
INSERT INTO student_info (course_id, class_id ,student_id ,NAME ) VALUES
(rand_num(10000,10100),rand_num(10000,10200),rand_num(1,200000),rand_string(6));
UNTIL i = max_num
END REPEAT;
COMMIT; # Commit transaction
END //
DELIMITER ;
The first 4 Step : Calling stored procedure
CALL inset_course(100);
CALL insert_stu(1000000);
3.2. Which situations are suitable for creating indexes
3.2.1. There is a limit to the uniqueness of field values
Fields with unique characteristics on the business , Even the combined fields , You have to build a unique index .( source :Alibaba)
explain : Don't think the only index affects insert Speed , This speed loss can be ignored , But it's obvious to improve the speed of searching .
3.2.2. Frequent act WHERE The field of the query condition
A field is in SELECT Of the statement WHERE Conditions are often used in , Then you need to create an index for this field . Especially when there is a large amount of data , Creating an ordinary index can greatly improve the efficiency of data query .
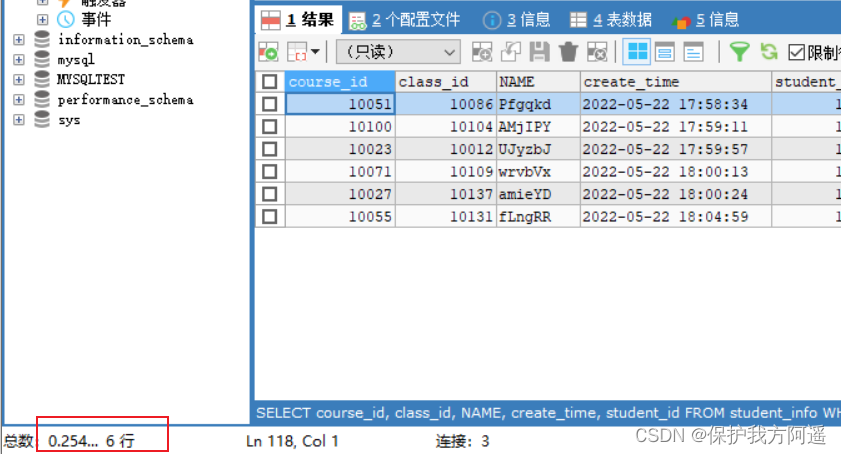
such as student_info Data sheet ( contain 100 Ten thousand data ), Suppose we want to query student_id=123110 User information for .
View the current stduent_info The index in the table
SHOW INDEX FROM student_info;
 student_id There is no index on the field :
student_id There is no index on the field :
SELECT course_id, class_id, NAME, create_time, student_id
FROM student_info
WHERE student_id = 123110;
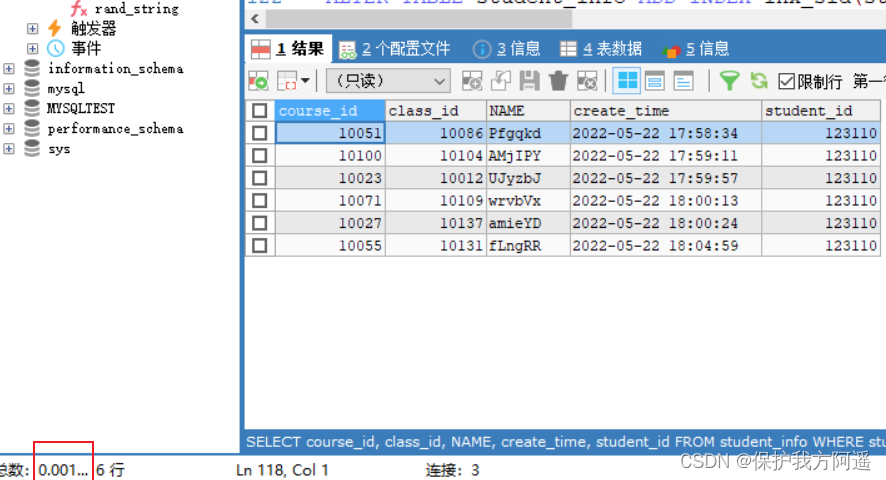
# to student_id Add index to field :
ALTER TABLE student_info ADD INDEX inx_sid(student_id);
SELECT course_id, class_id, NAME, create_time, student_id
FROM student_info
WHERE student_id = 123110;
3.2.3. often GROUP BY and ORDER BY The column of
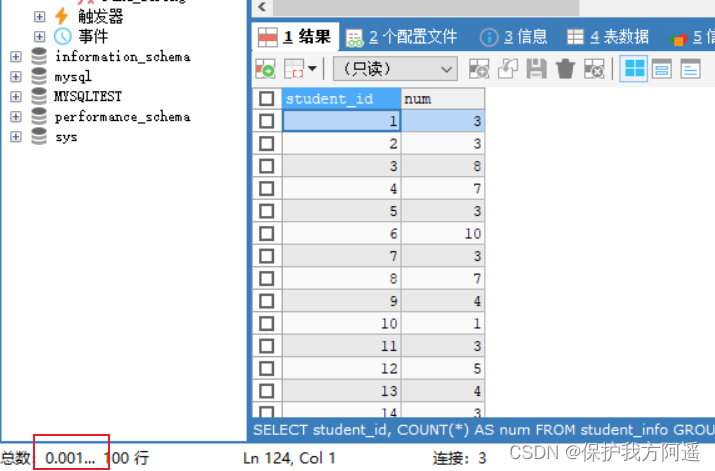
Index is to store or retrieve data in a certain order , So when we use GROUP BY Group and query the data , Or use ORDER BY When sorting data , Need Index grouped or sorted fields . If there are more than one column to sort , Then you can create... On these columns Composite index .
student_id Field with index :
SELECT student_id, COUNT(*) AS num
FROM student_info
GROUP BY student_id LIMIT 100;
# Delete inx_sid Indexes
ALTER TABLE student_info DROP INDEX inx_sid;
SELECT student_id, COUNT(*) AS num
FROM student_info
GROUP BY student_id LIMIT 100;
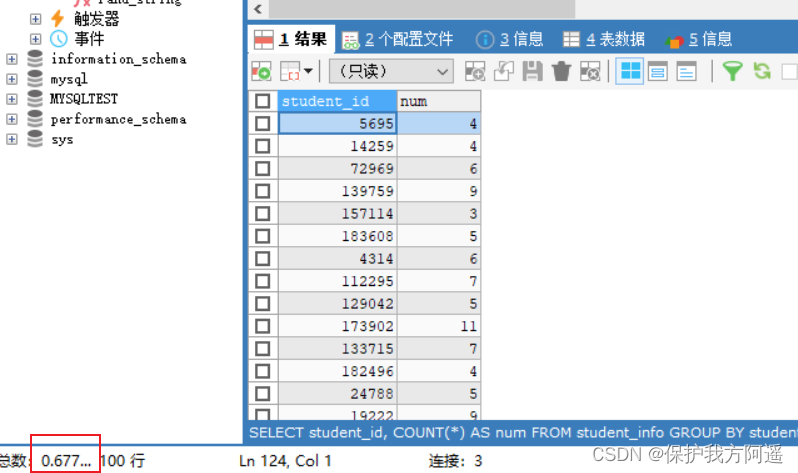
ORDER BY So it is with , No more testing .
3.2.4. UPDATE、DELETE Of WHERE Conditional column
Query the data according to a certain condition before UPDATE or DELETE The operation of , If the WHERE Field created index , Can greatly improve efficiency . The principle is that we need to base on WHERE The condition column retrieves the record , Then update or delete it . If you update , The updated field is a non indexed field , The improved efficiency will be more obvious , This is because non indexed field updates do not require maintenance of the index .
3.2.5. DISTINCT Fields need to be indexed
Sometimes we need to de duplicate a field , Use DISTINCT, Then create an index on this field , It will also improve query efficiency . such as , We want to check the different in the curriculum student_id What are the , If we're not right student_id Create index , perform SQL sentence :
SELECT DISTINCT(student_id) FROM `student_info`;
Running results (600637 Bar record , The elapsed time 0.683s ):
If we're right student_id Create index , Re execution SQL sentence :
SELECT DISTINCT(student_id) FROM `student_info`;
Running results (600637 Bar record , The elapsed time 0.010s ):
Can see SQL Query efficiency has been improved , At the same time student_id Or in accordance with Increasing order On display . This is because the index sorts the data in a certain order , Therefore, it will be much faster to remove the weight .
3.2.6. Multiple tables JOIN Connection operation , Precautions for index creation
First , Try not to exceed the number of join tables 3 Zhang , Because every additional table is equivalent to adding a nested loop , The order of magnitude will grow very fast , Seriously affect the efficiency of the query .
secondly , Yes WHERE Conditional index creation , because WHERE Is the filtering of data conditions . If the amount of data is very large , No, WHERE Conditional filtering is terrible .
Last , Index the fields used for the join , And the field is in multiple tables The type must be the same . such as course_id stay student_info Table and course All in the table are int(11) type , Not one for int For another varchar type .
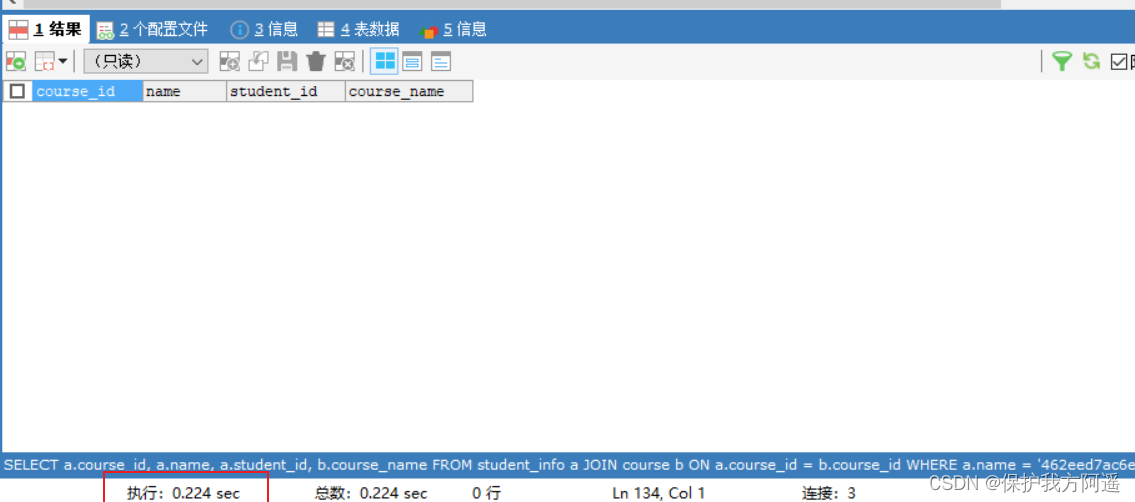
for instance , If we're only right about student_id Create index , perform SQL sentence :
SELECT course_id, name, student_info.student_id, course_name
FROM student_info JOIN course
ON student_info.course_id = course.course_id
WHERE name = '462eed7ac6e791292a79';
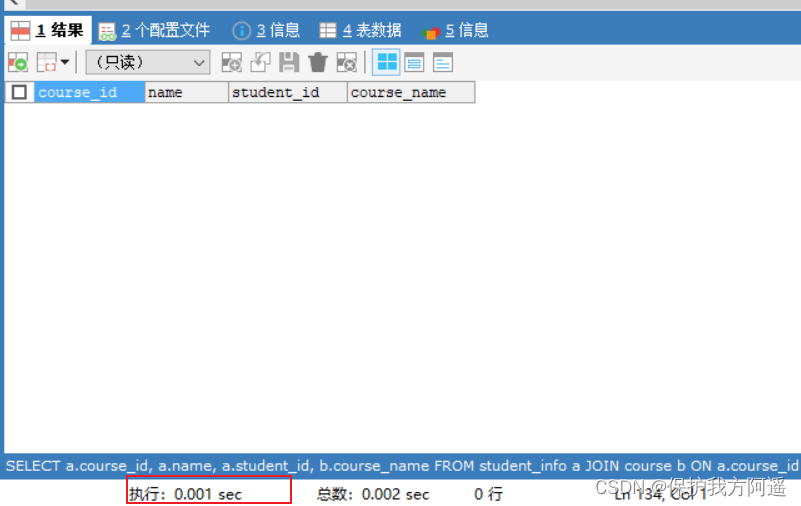
Here we are right name Create index , Then execute the above SQL sentence
ALTER TABLE student_info ADD INDEX idx_name(NAME);
SELECT a.course_id, a.name, a.student_id, b.course_name
FROM student_info a JOIN course b
ON a.course_id = b.course_id
WHERE a.name = '462eed7ac6e791292a79';
3.2.7. Use the type of column to create a small index
3.2.8. Create an index with a string prefix
Create a merchant table , Because the address field is long , Build prefix index on address field
create table shop(address varchar(120) not null);
alter table shop add index(address(12));
The problem is , How much is it intercepted ? A lot of interception , Can't save index storage space ; Less interception , Too much repetition , Hash of fields ( selectivity ) It will reduce . How to calculate the selectivity of different lengths ?
First, let's look at the selectivity of the field in the whole data :
SELECT COUNT(DISTINCT address) / COUNT(*) FROM shop;
Calculate... By different lengths , The selective comparison with the whole table :
The formula :
count(distinct left( Name , Index length ))/count(*);
for example :
select count(distinct left(address,10)) / count(*) as sub10, -- Before interception 10 Choice of characters
count(distinct left(address,15)) / count(*) as sub11, -- Before interception 15 Choice of characters
count(distinct left(address,20)) / count(*) as sub12, -- Before interception 20 Choice of characters
count(distinct left(address,25)) / count(*) as sub13 -- Before interception 25 Choice of characters
from shop;
Extend another question : The influence of index column prefix on sorting
expand :Alibaba《Java Development Manual 》:
【 mandatory 】 stay varchar When indexing on a field , Index length must be specified , There's no need to index all fields , According to the actual text
The discrimination determines the index length .
explain : Index length and differentiation are a pair of contradictions , Generally for string type data , The length is 20 The index of , The degree of discrimination will the height is 90% above , have access to count(distinct left( Name , Index length ))/count(*) To determine .
3.2.9. High discrimination ( High hashability ) The column of is suitable as an index
3.2.10. The most frequently used columns are placed on the left side of the federated index
In this way, you can also build fewer indexes . meanwhile , because " Leftmost prefix principle ", You can increase the usage of Federated indexes .
3.2.11. When multiple fields need to be indexed , Joint index is better than single value index
3.3. Which situations are not suitable for index creation
3.3.1. stay where Fields not used in , Don't set the index
3.3.2. It is better not to use index for tables with small data volume
give an example : Create table 1:
CREATE TABLE t_without_index(
a INT PRIMARY KEY AUTO_INCREMENT,
b INT
);
Provide stored procedures 1:
# Create stored procedure
DELIMITER //
CREATE PROCEDURE t_wout_insert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 900
DO
INSERT INTO t_without_index(b) SELECT RAND()*10000;
SET i = i + 1;
END WHILE;
COMMIT;
END //
DELIMITER ;
# call
CALL t_wout_insert();
Create table 2:
CREATE TABLE t_with_index(
a INT PRIMARY KEY AUTO_INCREMENT,
b INT,
INDEX idx_b(b)
);
Create stored procedure 2:
# Create stored procedure
DELIMITER //
CREATE PROCEDURE t_with_insert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 900
DO
INSERT INTO t_with_index(b) SELECT RAND()*10000;
SET i = i + 1;
END WHILE;
COMMIT;
END //
DELIMITER ;
# call
CALL t_with_insert();
Query comparison :
select * from t_without_index where b = 9879;
select * from t_with_index where b = 9879;
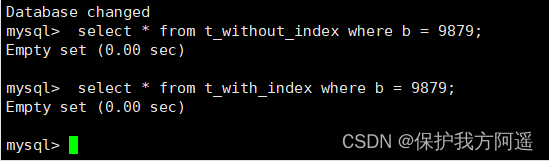
See that the running results are the same , But when the amount of data is small , The index won't work .
Conclusion : When the number of data rows in the data table is relatively small , For example, less than 1000 That's ok , There is no need to create an index .
3.3.3. Don't build indexes on columns with a lot of duplicate data
give an example 1: To be in 100 Look for... In 10000 rows of data 50 Line ten thousand ( For example, data on men's gender ), Once the index is created , You need to visit 50 Ten thousand index , And then visit again 50 10000 times data sheet , This may add up to more overhead than not using indexes .
Conclusion : When the data is repetitive , such as higher than 10% When , You don't need to index this field either .
3.3.4. Avoid creating too many indexes on frequently updated tables
3.3.5. Unordered values are not recommended as indexes
For example, ID card 、UUID( In index comparison, it needs to be converted to ASCII, And the insertion may cause page splitting )、MD5、HASH、 Unordered long strings, etc .
3.3.6. Delete indexes that are no longer or rarely used
3.3.7. Do not define redundant or duplicate indexes
① Redundant index :
give an example : Build the predicative sentence as follows
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number),
KEY idx_name (name(10))
);
We know , adopt idx_name_birthday_phone_number Index can be used to name Column for quick search , Create another one specifically for name The index of a column is a Redundant index , Maintaining this index will only increase the cost of maintenance , It won't be good for search .
② Duplicate index
Another situation , We may be on a column Duplicate indexing , Like this :
CREATE TABLE repeat_index_demo (
col1 INT PRIMARY KEY,
col2 INT,
UNIQUE uk_idx_c1 (col1),
INDEX idx_c1 (col1)
);
col1 It's a primary key 、 And define it as a unique index , It also defines a common index , However, the primary key itself will generate cluster index , Therefore, the defined unique index and ordinary index are duplicate , This situation should be avoided .
边栏推荐
- Pytoch LSTM implementation process (visual version)
- 保姆级手把手教你用C语言写三子棋
- 好博客好资料记录链接
- 评估方法的优缺点
- Several errors encountered when installing opencv
- 安装OpenCV时遇到的几种错误
- Flash operation and maintenance script (running for a long time)
- text 文本数据增强方法 data argumentation
- MySQL实战优化高手03 用一次数据更新流程,初步了解InnoDB存储引擎的架构设计
- MySQL ERROR 1040: Too many connections
猜你喜欢
MySQL34-其他数据库日志
Security design verification of API interface: ticket, signature, timestamp
Redis集群方案应该怎么做?都有哪些方案?
Ueeditor internationalization configuration, supporting Chinese and English switching

Use xtrabackup for MySQL database physical backup
C miscellaneous shallow copy and deep copy
How to build an interface automation testing framework?
MySQL 29 other database tuning strategies
MySQL29-数据库其它调优策略
MySQL32-锁
随机推荐
Emotional classification of 1.6 million comments on LSTM based on pytoch
Notes of Dr. Carolyn ROS é's social networking speech
MySQL learning diary (II)
MySQL28-数据库的设计规范
Export virtual machines from esxi 6.7 using OVF tool
Security design verification of API interface: ticket, signature, timestamp
使用OVF Tool工具从Esxi 6.7中导出虚拟机
Sed text processing
Mysql30 transaction Basics
MySQL32-锁
MySQL27-索引优化与查询优化
[paper reading notes] - cryptographic analysis of short RSA secret exponents
How to make shell script executable
In fact, the implementation of current limiting is not complicated
Not registered via @enableconfigurationproperties, marked (@configurationproperties use)
软件测试工程师必备之软技能:结构化思维
百度百科数据爬取及内容分类识别
Pytorch LSTM实现流程(可视化版本)
jar运行报错no main manifest attribute
The appearance is popular. Two JSON visualization tools are recommended for use with swagger. It's really fragrant