当前位置:网站首页>百度百科数据爬取及内容分类识别
百度百科数据爬取及内容分类识别
2022-07-06 09:11:00 【CHQIUU】
前言
最近在学习知识图谱相关内容,需要爬取一些结构化的数据。下面介绍如何爬取百度百科的数据并提取出有效数据代码实现。
一、分析页面结构
页面可以分为5个区域,如下图标注所示(聚丙烯介绍的页面结构)。
https://baike.baidu.com/wikitag/taglist?tagId=76613
二、使用步骤
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
边栏推荐
- MySQL combat optimization expert 07 production experience: how to conduct 360 degree dead angle pressure test on the database in the production environment?
- MySQL實戰優化高手08 生產經驗:在數據庫的壓測過程中,如何360度無死角觀察機器性能?
- Sed text processing
- Super detailed steps to implement Wechat public number H5 Message push
- The 32-year-old fitness coach turned to a programmer and got an offer of 760000 a year. The experience of this older coder caused heated discussion
- MySQL实战优化高手03 用一次数据更新流程,初步了解InnoDB存储引擎的架构设计
- MySQL combat optimization expert 06 production experience: how does the production environment database of Internet companies conduct performance testing?
- MySQL底层的逻辑架构
- Tianmu MVC audit I
- MySQL实战优化高手04 借着更新语句在InnoDB存储引擎中的执行流程,聊聊binlog是什么?
猜你喜欢

四川云教和双师模式

Can I learn PLC at the age of 33

14 医疗挂号系统_【阿里云OSS、用户认证与就诊人】
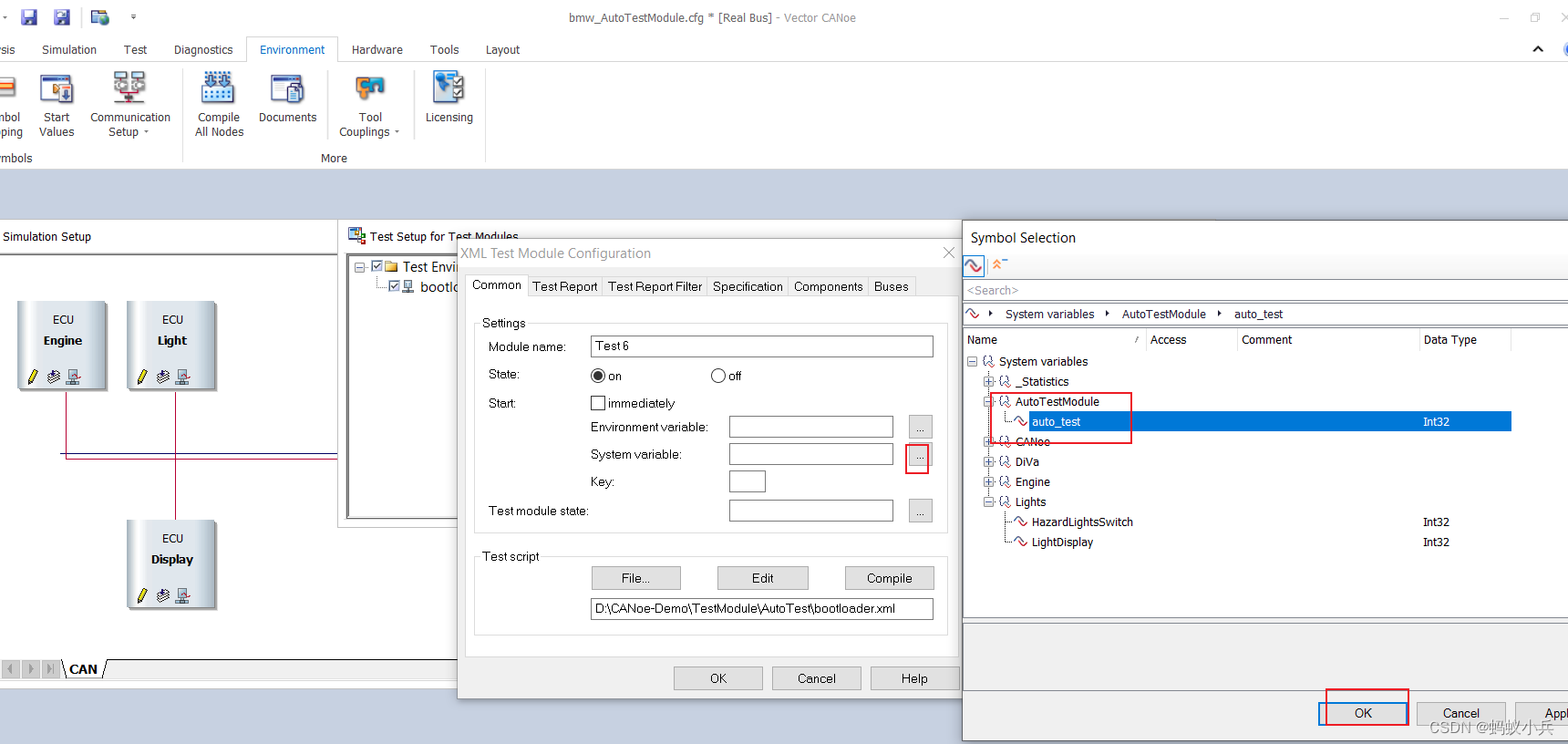
在CANoe中通过Panel面板控制Test Module 运行(初级)
Carolyn Rosé博士的社交互通演讲记录

Preliminary introduction to C miscellaneous lecture document
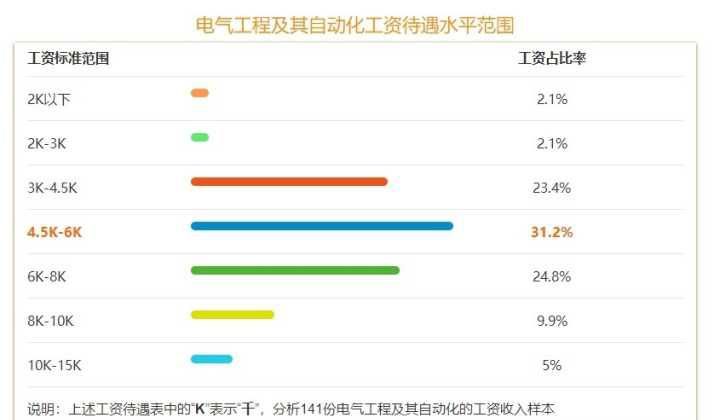
Which is the better prospect for mechanical engineer or Electrical Engineer?
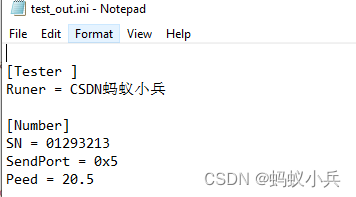
CAPL 脚本对.ini 配置文件的高阶操作
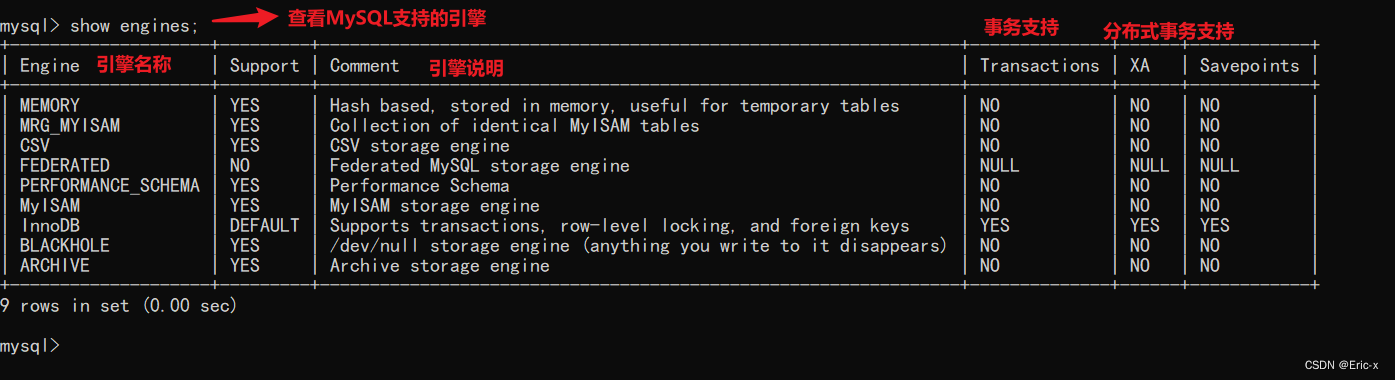
MySQL storage engine
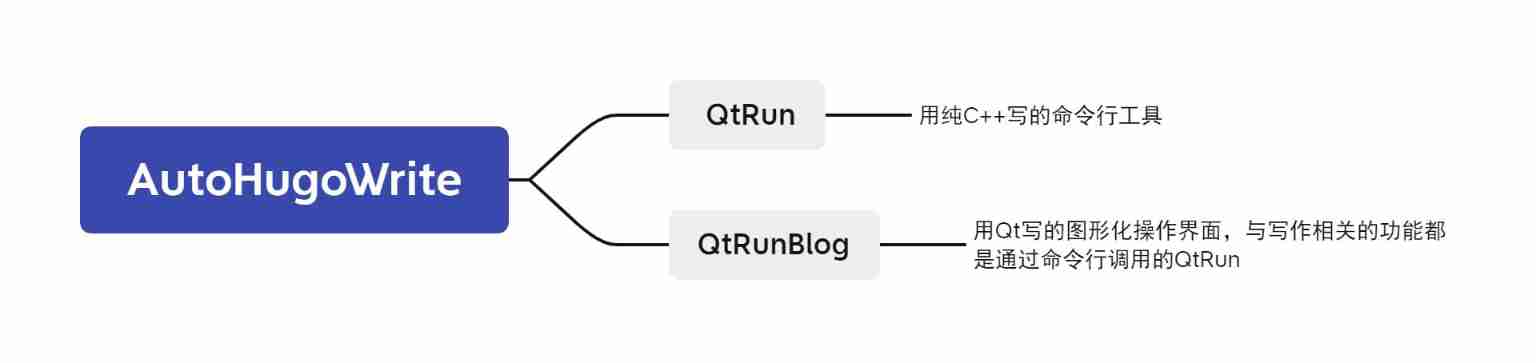
Hugo blog graphical writing tool -- QT practice
随机推荐
What should the redis cluster solution do? What are the plans?
vscode 常用的指令
Retention policy of RMAN backup
Contest3145 - the 37th game of 2021 freshman individual training match_ B: Password
Contrôle de l'exécution du module d'essai par panneau dans Canoe (primaire)
Zsh configuration file
MySQL combat optimization expert 09 production experience: how to deploy a monitoring system for a database in a production environment?
Bugku web guide
Canoe CAPL file operation directory collection
Release of the sample chapter of "uncover the secrets of asp.net core 6 framework" [200 pages /5 chapters]
14 医疗挂号系统_【阿里云OSS、用户认证与就诊人】
13 medical registration system_ [wechat login]
If a university wants to choose to study automation, what books can it read in advance?
jar运行报错no main manifest attribute
Software test engineer development planning route
美新泽西州州长签署七项提高枪支安全的法案
Learning SCM is of great help to society
Carolyn Rosé博士的社交互通演讲记录
[flask] crud addition and query operation of data
C杂讲 文件 续讲