当前位置:网站首页>MySQL27-索引优化与查询优化
MySQL27-索引优化与查询优化
2022-07-06 09:11:00 【保护我方阿遥】
一. 数据准备
学员表 插 50万 条, 班级表 插 1万 条。
1.1. 建表
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
1.2. 设置参数
命令开启:允许创建函数设置:
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
1.3. 创建函数
保证每条数据都不同。
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#假如要删除
#drop function rand_string;
随机产生班级编号
#用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
#假如要删除
#drop function rand_num;
1.4. 创建存储过程
创建往class表中插入数据的存储过程
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES
(rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_class;
1.5. 调用存储过程
class
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
stu
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
1.6. 删除某表上的索引
创建存储过程
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM
information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND
seq_in_index=1 AND index_name <>'PRIMARY' ;
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
执行存储过程
CALL proc_drop_index("dbname","tablename");
二. 索引失效案例
2.1. 全值匹配
2.2. 最佳左前缀法则
拓展:Alibaba《Java开发手册》
索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
2.3. 主键插入顺序

如果此时再插入一条主键值为 9 的记录,那它插入的位置就如下图: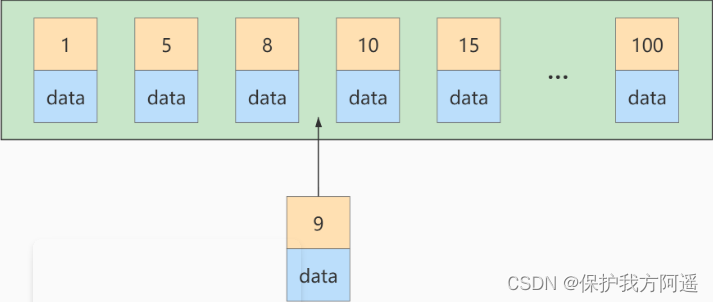
可这个数据页已经满了,再插进来咋办呢?我们需要把当前 页面分裂 成两个页面,把本页中的一些记录移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着: 性能损耗 !所以如果我们想尽量避免这样无谓的性能损耗,最好让插入的记录的 主键值依次递增 ,这样就不会发生这样的性能损耗了。所以我们建议:让主键具有 AUTO_INCREMENT ,让存储引擎自己为表生成主键,而不是我们手动插入 ,比如: person_info 表:
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
);
我们自定义的主键列 id 拥有 AUTO_INCREMENT 属性,在插入记录时存储引擎会自动为我们填入自增的主键值。这样的主键占用空间小,顺序写入,减少页分裂。
2.4. 计算、函数、类型转换(自动或手动)导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
创建索引
CREATE INDEX idx_name ON student(NAME);
第一种:索引优化生效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';

第二种:索引优化失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';

type为“ALL”,表示没有使用到索引。
再举例:
- student表的字段stuno上设置有索引。
CREATE INDEX idx_sno ON student(stuno);
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;

- 索引优化生效
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;

再举例:
3. student表的字段name上设置有索引
CREATE INDEX idx_name ON student(NAME);
EXPLAIN SELECT id, stuno, name FROM student WHERE SUBSTRING(name, 1,3)='abc';

EXPLAIN SELECT id, stuno, NAME FROM student WHERE NAME LIKE 'abc%';

2.5. 类型转换导致索引失效
下列哪个sql语句可以用到索引。(假设name字段上设置有索引)
name=123发生类型转换,索引失效。
未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
# 使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';
2.6. 范围条件右边的列索引失效
ALTER TABLE student DROP INDEX idx_name;
ALTER TABLE student DROP INDEX idx_age;
ALTER TABLE student DROP INDEX idx_age_classid;
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ;
create index idx_age_name_classid on student(age,name,classid);
- 将范围查询条件放置语句最后:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name =
'abc' AND student.classId>20 ;

2.7. 不等于(!= 或者<>)索引失效
2.8. is null可以使用索引,is not null无法使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
2.9. like以通配符%开头索引失效
拓展:Alibaba《Java开发手册》
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
2.10. OR 前后存在非索引的列,索引失效
# 未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
#使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR name = 'Abel';
2.11. 数据库和表的字符集统一使用utf8mb4
统一使用utf8mb4( 5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。不同的 字符集 进行比较前需要进行 转换 会造成索引失效。
三. 关联查询优化
3.1. 准备数据
#分类
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
#图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
#向分类表中添加20条记录
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
#向图书表中添加20条记录
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
3.2. 采用左外连接
下面开始 EXPLAIN 分析
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
 结论:type 有All
结论:type 有All
添加索引优化
ALTER TABLE book ADD INDEX Y ( card); #【被驱动表】,可以避免全表扫描
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
 可以看到第二行的 type 变为了 ref,rows 也变成了优化比较明显。这是由左连接特性决定的。LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以 右边是我们的关键点,一定需要建立索引。
可以看到第二行的 type 变为了 ref,rows 也变成了优化比较明显。这是由左连接特性决定的。LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以 右边是我们的关键点,一定需要建立索引。
ALTER TABLE `type` ADD INDEX X (card); #【驱动表】,无法避免全表扫描
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

接着:
DROP INDEX Y ON book;
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

3.3. 采用内连接
drop index X on type;
drop index Y on book;(如果已经删除了可以不用再执行该操作)
换成 inner join(MySQL自动选择驱动表)
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
 添加索引优化
添加索引优化
ALTER TABLE book ADD INDEX Y ( card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;

ALTER TABLE type ADD INDEX X (card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
 接着:
接着:
DROP INDEX X ON `type`;
EXPLAIN SELECT SQL_NO_CACHE * FROM TYPE INNER JOIN book ON type.card=book.card;
 接着:
接着:
ALTER TABLE `type` ADD INDEX X (card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;

3.4. join语句原理
Index Nested-Loop Join
CREATE TABLE `t2` (
`id` INT(11) NOT NULL,
`a` INT(11) DEFAULT NULL,
`b` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
INDEX `a` (`a`)
) ENGINE=INNODB;
DELIMITER //
CREATE PROCEDURE idata()
BEGIN
DECLARE i INT;
SET i=1;
WHILE(i<=1000)DO
INSERT INTO t2 VALUES(i, i, i);
SET i=i+1;
END WHILE;
END //
DELIMITER ;
CALL idata();
#创建t1表并复制t1表中前100条数据
CREATE TABLE t1
AS
SELECT * FROM t2
WHERE id <= 100;
#测试表数据
SELECT COUNT(*) FROM t1;
SELECT COUNT(*) FROM t2;
#查看索引
SHOW INDEX FROM t2;
SHOW INDEX FROM t1;
我们来看一下这个语句:
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.a);
如果直接使用join语句,MySQL优化器可能会选择表t1或t2作为驱动表,这样会影响我们分析SQL语句的执行过程。所以,为了便于分析执行过程中的性能问题,我改用 straight_join 让MySQL使用固定的连接方式执行查询,这样优化器只会按照我们指定的方式去join。在这个语句里,t1 是驱动表,t2是被驱动表。
可以看到,在这条语句里,被驱动表t2的字段a上有索引,join过程用上了这个索引,因此这个语句的执行流程是这样的:
- 从表t1中读入一行数据 R;
- 从数据行R中,取出a字段到表t2里去查找;
- 取出表t2中满足条件的行,跟R组成一行,作为结果集的一部分;
- 重复执行步骤1到3,直到表t1的末尾循环结束。
这个过程是先遍历表t1,然后根据从表t1中取出的每行数据中的a值,去表t2中查找满足条件的记录。在形式上,这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以我们称之为“Index Nested-Loop Join”,简称NLJ。
它对应的流程图如下所示: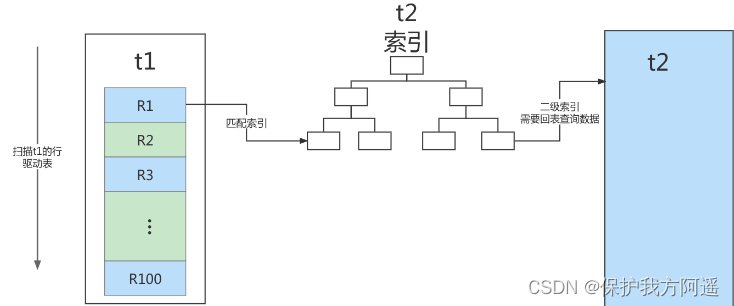
在这个流程里: - 对驱动表t1做了全表扫描,这个过程需要扫描100行;
- 而对于每一行R,根据a字段去表t2查找,走的是树搜索过程。由于我们构造的数据都是一一对应的,因此每次的搜索过程都只扫描一行,也是总共扫描100行;
- 所以,整个执行流程,总扫描行数是200。
3.5. 小结
- 保证被驱动表的JOIN字段已经创建了索引。
- 需要JOIN 的字段,数据类型保持绝对一致。
- LEFT JOIN 时,选择小表作为驱动表, 大表作为被驱动表 。减少外层循环的次数。
- INNER JOIN 时,MySQL会自动将 小结果集的表选为驱动表 。选择相信MySQL优化策略。
- 能够直接多表关联的尽量直接关联,不用子查询。(减少查询的趟数)。
- 不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用 JOIN 来代替子查询。
- 衍生表建不了索引
四. 子查询优化
MySQL从4.1版本开始支持子查询,使用子查询可以进行SELECT语句的嵌套查询,即一个SELECT查询的结果作为另一个SELECT语句的条件。 子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作 。
子查询是 MySQL 的一项重要的功能,可以帮助我们通过一个 SQL 语句实现比较复杂的查询。但是,子查询的执行效率不高。原因:
① 执行子查询时,MySQL需要为内层查询语句的查询结果 建立一个临时表 ,然后外层查询语句从临时表中查询记录。查询完毕后,再 撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
② 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都 不会存在索引 ,所以查询性能会受到一定的影响。
③ 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
在MySQL中,可以使用连接(JOIN)查询来替代子查询。连接查询 不需要建立临时表 ,其 速度比子查询要快 ,如果查询中使用索引的话,性能就会更好。
结论:尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代
五. 排序优化
5.1. 排序优化
问题:在 WHERE 条件字段上加索引,但是为什么在 ORDER BY 字段上还要加索引呢?
优化建议:
- SQL 中,可以在 WHERE 子句和 ORDER BY 子句中使用索引,目的是在 WHERE 子句中 避免全表扫描 ,在 ORDER BY 子句 避免使用 FileSort 排序 。当然,某些情况下全表扫描,或者 FileSort 排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。
- 尽量使用 Index 完成 ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列;如果不同就使用联合索引。
- 无法使用 Index 时,需要对 FileSort 方式进行调优。
INDEX a_b_c(a,b,c)
order by 能使用索引最左前缀
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC,b DESC,c DESC
如果WHERE使用索引的最左前缀定义为常量,则order by 能使用索引
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b = const ORDER BY c
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b > const ORDER BY b,c
不能使用索引进行排序
- ORDER BY a ASC,b DESC,c DESC /* 排序不一致 */
- WHERE g = const ORDER BY b,c /*丢失a索引*/
- WHERE a = const ORDER BY c /*丢失b索引*/
- WHERE a = const ORDER BY a,d /*d不是索引的一部分*/
- WHERE a in (...) ORDER BY b,c /*对于排序来说,多个相等条件也是范围查询*/
5.2. 案例实战
ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序。
执行案例前先清除student上的索引,只留主键:
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid_stuno ON student;
DROP INDEX idx_age_classid_name ON student;
#或者
call proc_drop_index('INDEXTEST','student');
场景:查询年龄为30岁的,且学生编号小于101000的学生,按用户名称排序
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY
NAME ;

结论:type 是 ALL,即最坏的情况。Extra 里还出现了 Using filesort,也是最坏的情况。优化是必须的。
优化思路:
方案一: 为了去掉filesort我们可以把索引建成
#创建新索引
CREATE INDEX idx_age_name ON student(age,NAME);
方案二: 尽量让where的过滤条件和排序使用上索引
建一个三个字段的组合索引:
DROP INDEX idx_age_name ON student;
CREATE INDEX idx_age_stuno_name ON student (age,stuno,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY
NAME ;
结果竟然有 filesort的 sql 运行速度, 超过了已经优化掉 filesort的 sql ,而且快了很多,几乎一瞬间就出现了结果。
结论:
1. 两个索引同时存在,mysql自动选择最优的方案。(对于这个例子,mysql选择
idx_age_stuno_name)。但是, 随着数据量的变化,选择的索引也会随之变化的 。
2. 当【范围条件】和【group by 或者 order by】的字段出现二选一时,优先观察条件字段的过
滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段
上。反之,亦然。
5.3. filesort算法:双路排序和单路排序
5.3.1. 双路排序 (慢)
- MySQL 4.1之前是使用双路排序 ,字面意思就是两次扫描磁盘,最终得到数据, 读取行指针和order by列 ,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出。
- 从磁盘取排序字段,在buffer进行排序,再从 磁盘取其他字段 。
取一批数据,要对磁盘进行两次扫描,众所周知,IO是很耗时的,所以在mysql4.1之后,出现了第二种改进的算法,就是单路排序。
5.3.2. 单路排序 (快)
从磁盘读取查询需要的 所有列 ,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输出, 它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空间, 因为它把每一行都保存在内存中了。
5.3.3. 优化策略
- 尝试提高 sort_buffer_size。
- 尝试提高 max_length_for_sort_data。
- Order by 时select * 是一个大忌。最好只Query需要的字段。
六. GROUP BY优化
- group by 使用索引的原则几乎跟order by一致 ,group by 即使没有过滤条件用到索引,也可以直接使用索引。
- group by 先排序再分组,遵照索引建的最佳左前缀法则。
- 当无法使用索引列,增大 max_length_for_sort_data 和 sort_buffer_size 参数的设置。
- where效率高于having,能写在where限定的条件就不要写在having中了。
- 减少使用order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。Order by、groupby、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。
- 包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
七. 优化分页查询
优化思路一:
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10)
a
WHERE t.id = a.id;

优化思路二:
该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询 。
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;

八. 优先考虑覆盖索引
8.1. 什么是覆盖索引?
理解方式一:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了满足查询结果的数据就叫做覆盖索引。
理解方式二:非聚簇复合索引的一种形式,它包括在查询里的SELECT、JOIN和WHERE子句用到的所有列(即建索引的字段正好是覆盖查询条件中所涉及的字段)。
简单说就是, 索引列+主键 包含 SELECT 到 FROM之间查询的列 。
8.2. 覆盖索引的利弊
好处:
- 避免Innodb表进行索引的二次查询(回表)。
- 可以把随机IO变成顺序IO加快查询效率。
弊端:
索引字段的维护 总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了。这是业务DBA,或者称为业务数据架构师的工作。
九. 如何给字符串添加索引
有一张教师表,表定义如下:
create table teacher(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=innodb;
讲师要使用邮箱登录,所以业务代码中一定会出现类似于这样的语句:
select col1, col2 from teacher where email='xxx';
如果email这个字段上没有索引,那么这个语句就只能做 全表扫描 。
9.1. 前缀索引
MySQL是支持前缀索引的。默认地,如果你创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
alter table teacher add index index1(email)
#或
alter table teacher add index index2(email(6));
这两种不同的定义在数据结构和存储上有什么区别呢?下图就是这两个索引的示意图。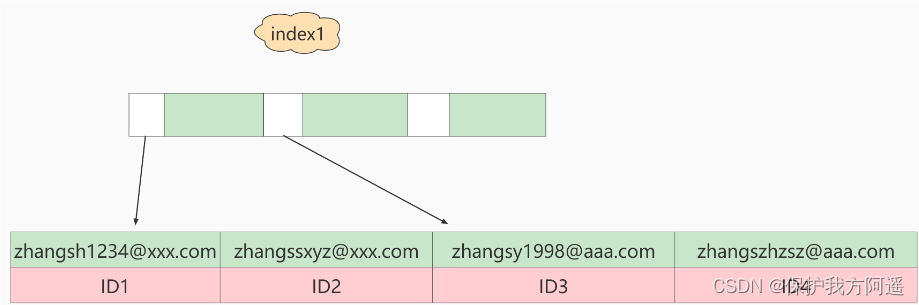 以及:
以及: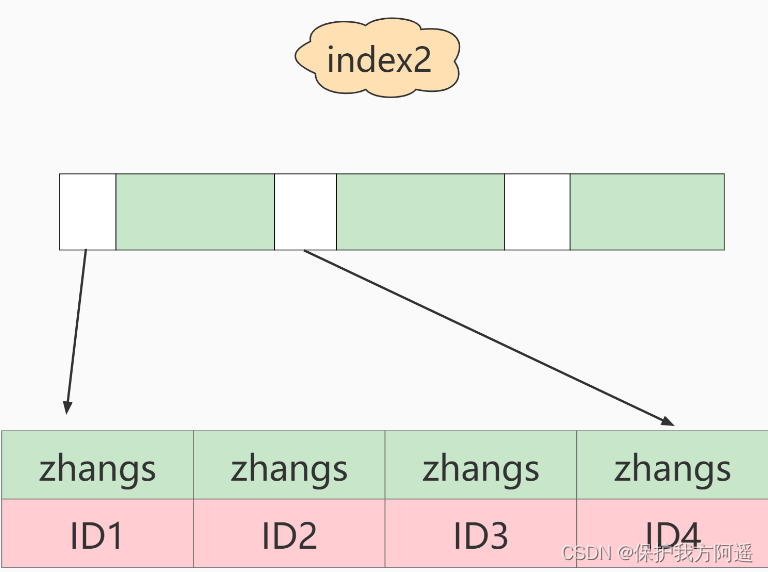
如果使用的是index1(即email整个字符串的索引结构),执行顺序是这样的:
- 从index1索引树找到满足索引值是’ [email protected] ’的这条记录,取得ID2的值;
- 到主键上查到主键值是ID2的行,判断email的值是正确的,将这行记录加入结果集;
- 取index1索引树上刚刚查到的位置的下一条记录,发现已经不满足email=’ [email protected] ’的条件了,循环结束。
这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
如果使用的是index2(即email(6)索引结构),执行顺序是这样的: - 从index2索引树找到满足索引值是’zhangs’的记录,找到的第一个是ID1;
- 到主键上查到主键值是ID1的行,判断出email的值不是’ [email protected] ’,这行记录丢弃;
- 取index2上刚刚查到的位置的下一条记录,发现仍然是’zhangs’,取出ID2,再到ID索引上取整行然后判断,这次值对了,将这行记录加入结果集;
- 重复上一步,直到在idxe2上取到的值不是’zhangs’时,循环结束。
也就是说使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。前面已经讲过区分度,区分度越高越好。因为区分度越高,意味着重复的键值越少。
9.2. 前缀索引对覆盖索引的影响
结论:
使用前缀索引就用不上覆盖索引对查询性能的优化了,这也是你在选择是否使用前缀索引时需要考虑的一个因素。
十. 索引下推
Index Condition Pushdown(ICP)是MySQL 5.6中新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式。ICP可以减少存储引擎访问基表的次数以及MySQL服务器访问存储引擎的次数。
10.1. 使用前后的扫描过程
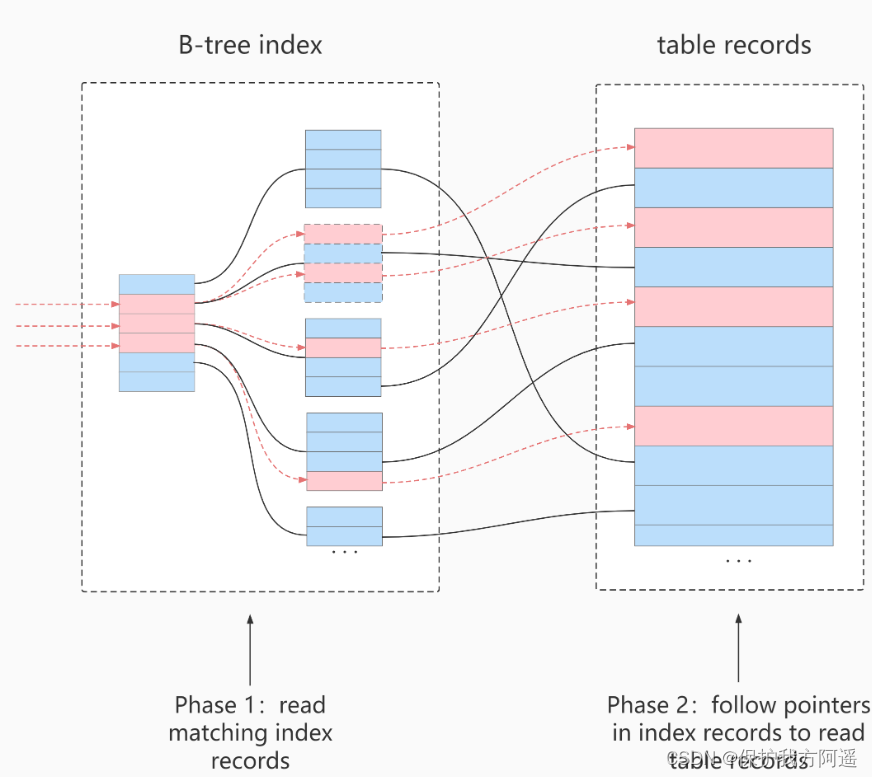
在不使用ICP索引扫描的过程:
storage层:只将满足index key条件的索引记录对应的整行记录取出,返回给server层。
server 层:对返回的数据,使用后面的where条件过滤,直至返回最后一行。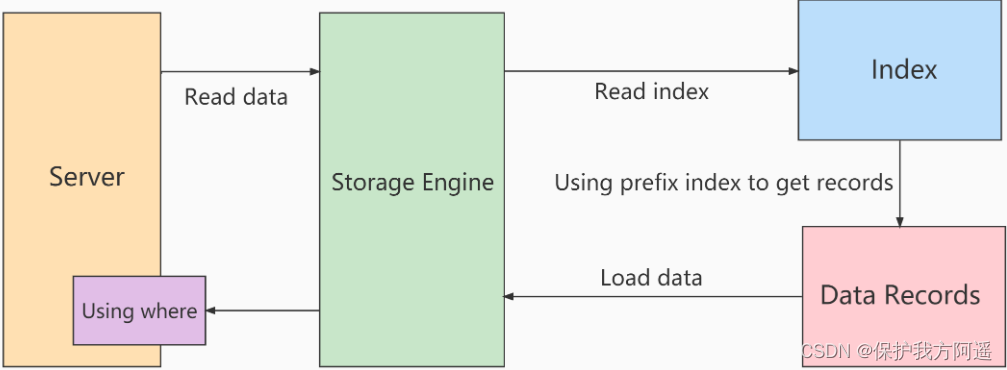
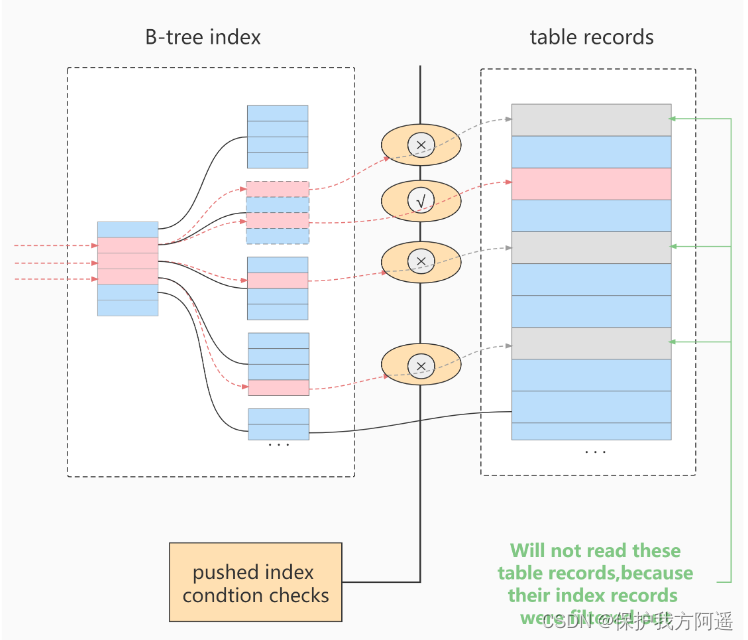
使用ICP扫描的过程:
- storage层:
首先将index key条件满足的索引记录区间确定,然后在索引上使用index filter进行过滤。将满足的indexfilter条件的索引记录才去回表取出整行记录返回server层。不满足index filter条件的索引记录丢弃,不回表、也不会返回server层。 - server 层:
对返回的数据,使用table filter条件做最后的过滤。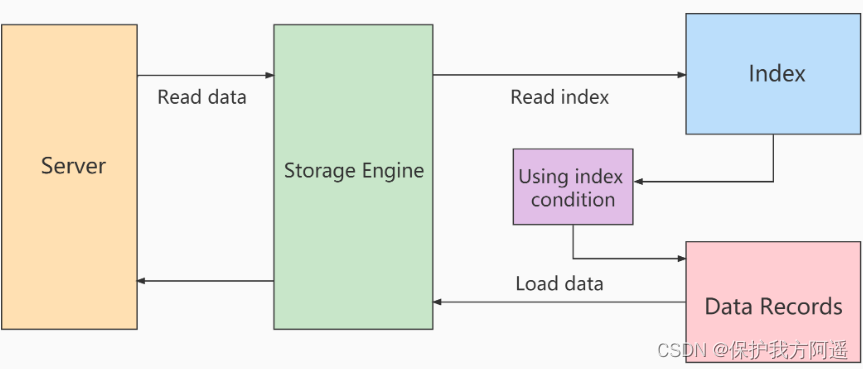
 使用前后的成本差别
使用前后的成本差别
- 使用前,存储层多返回了需要被index filter过滤掉的整行记录
- 使用ICP后,直接就去掉了不满足index filter条件的记录,省去了他们回表和传递到server层的成本。
- ICP的 加速效果 取决于在存储引擎内通过 ICP筛选 掉的数据的比例。
10.2. ICP的使用条件
ICP的使用条件:
① 只能用于二级索引(secondary index)
②explain显示的执行计划中type值(join 类型)为 range 、 ref 、 eq_ref 或者 ref_or_null 。
③ 并非全部where条件都可以用ICP筛选,如果where条件的字段不在索引列中,还是要读取整表的记录
到server端做where过滤。
④ ICP可以用于MyISAM和InnnoDB存储引擎
⑤ MySQL 5.6版本的不支持分区表的ICP功能,5.7版本的开始支持。
⑥ 当SQL使用覆盖索引时,不支持ICP优化方法。
10.3. ICP使用案例
案例1:
SELECT * FROM tuser
WHERE NAME LIKE '张%'
AND age = 10
AND ismale = 1;
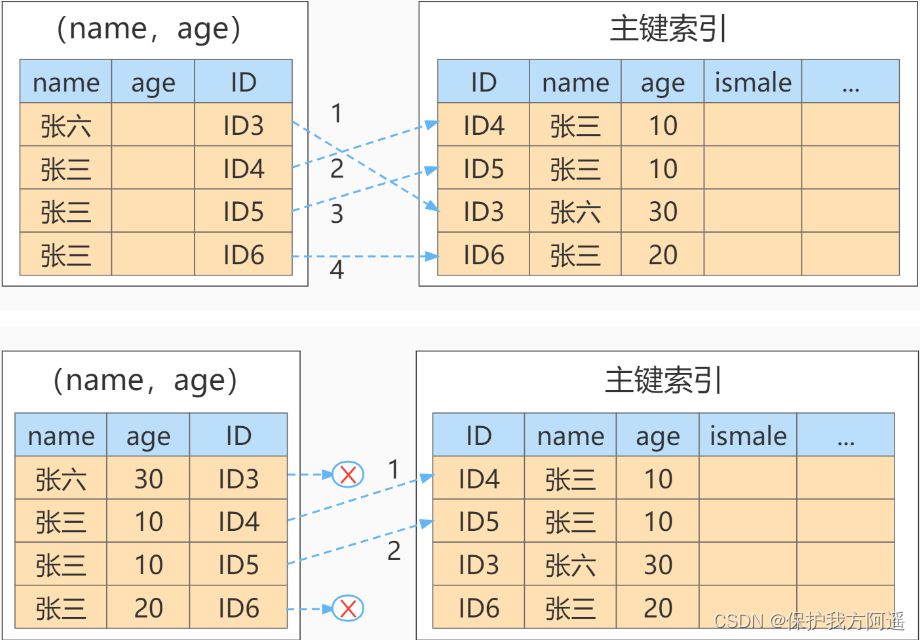 案例2:
案例2:
十一. 普通索引 vs 唯一索引
从性能的角度考虑,选择唯一索引还是普通索引呢?选择的依据是什么呢?
假设,我们有一个主键列为ID的表,表中有字段k,并且在k上有索引,假设字段 k 上的值都不重复。
这个表的建表语句是:
reate table test(
id int primary key,
k int not null,
name varchar(16),
index (k)
)engine=InnoDB;
11.1. 查询过程
假设,执行查询的语句是 select id from test where k=5。
- 对于普通索引来说,查找到满足条件的第一个记录(5,500)后,需要查找下一个记录,直到碰到第一个不满足k=5条件的记录。
- 对于唯一索引来说,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索。
那么,这个不同带来的性能差距会有多少呢?答案是, 微乎其微 。
11.2. 更新过程
为了说明普通索引和唯一索引对更新语句性能的影响这个问题,介绍一下change buffer。
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下, InooDB会将这些更新操作缓存在change buffer中 ,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
将change buffer中的操作应用到原数据页,得到最新结果的过程称为 merge 。除了 访问这个数据页 会触发merge外,系统有 后台线程会定期 merge。在 数据库正常关闭(shutdown) 的过程中,也会执行merge操作。
如果能够将更新操作先记录在change buffer, 减少读磁盘 ,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用 buffer pool 的,所以这种方式还能够 避免占用内存 ,提高内存利用率。
唯一索引的更新就不能使用change buffer ,实际上也只有普通索引可以使用。
如果要在这张表中插入一个新记录(4,400)的话,InnoDB的处理流程是怎样的?
11.3. change buffer的使用场景
- 普通索引和唯一索引应该怎么选择?其实,这两类索引在查询能力上是没差别的,主要考虑的是对更新性能 的影响。所以,建议尽量选择普通索引 。
- 在实际使用中会发现, 普通索引 和 change buffer 的配合使用,对于 数据量大 的表的更新优化还是很明显的。
- 如果所有的更新后面,都马上 伴随着对这个记录的查询 ,那么你应该 关闭change buffer 。而在其他情况下,change buffer都能提升更新性能。
- 由于唯一索引用不上change buffer的优化机制,因此如果 业务可以接受 ,从性能角度出发建议优先考虑非唯一索引。但是如果"业务可能无法确保"的情况下,怎么处理呢?
- 首先, 业务正确性优先 。我们的前提是“业务代码已经保证不会写入重复数据”的情况下,讨论性能问题。如果业务不能保证,或者业务就是要求数据库来做约束,那么没得选,必须创建唯一索引。这种情况下,本节的意义在于,如果碰上了大量插入数据慢、内存命中率低的时候,给你多提供一个排查思路。
- 然后,在一些“ 归档库 ”的场景,你是可以考虑使用唯一索引的。比如,线上数据只需要保留半年,然后历史数据保存在归档库。这时候,归档数据已经是确保没有唯一键冲突了。要提高归档效率,可以考虑把表里面的唯一索引改成普通索引。
十二. 其它查询优化策略
12.1. 关于SELECT(*)
在表查询中,建议明确字段,不要使用 * 作为查询的字段列表,推荐使用SELECT <字段列表> 查询。原因:
① MySQL 在解析的过程中,会通过 查询数据字典 将"*"按序转换成所有列名,这会大大的耗费资源和时间。
② 无法使用 覆盖索引。
12.2. LIMIT 1 对优化的影响
针对的是会扫描全表的 SQL 语句,如果你可以确定结果集只有一条,那么加上 LIMIT 1 的时候,当找到一条结果的时候就不会继续扫描了,这样会加快查询速度。
如果数据表已经对字段建立了唯一索引,那么可以通过索引进行查询,不会全表扫描的话,就不需要加上 LIMIT 1 了。
12.3. 多使用COMMIT
只要有可能,在程序中尽量多使用 COMMIT,这样程序的性能得到提高,需求也会因为 COMMIT 所释放的资源而减少。
COMMIT 所释放的资源:
- 回滚段上用于恢复数据的信息。
- 被程序语句获得的锁。
- redo / undo log buffer 中的空间。
- 管理上述 3 种资源中的内部花费。
边栏推荐
- Not registered via @EnableConfigurationProperties, marked(@ConfigurationProperties的使用)
- MySQL ERROR 1040: Too many connections
- 17 medical registration system_ [wechat Payment]
- Google login prompt error code 12501
- Security design verification of API interface: ticket, signature, timestamp
- Pytorch LSTM实现流程(可视化版本)
- MySQL36-数据库备份与恢复
- Solve the problem of remote connection to MySQL under Linux in Windows
- Several errors encountered when installing opencv
- In fact, the implementation of current limiting is not complicated
猜你喜欢
If someone asks you about the consistency of database cache, send this article directly to him
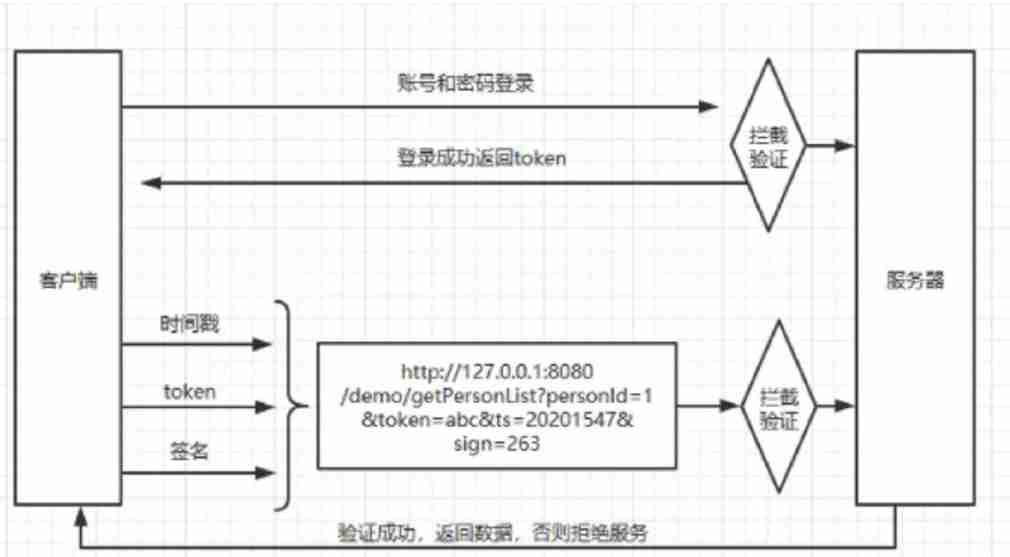
Security design verification of API interface: ticket, signature, timestamp
【C语言】深度剖析数据存储的底层原理
A necessary soft skill for Software Test Engineers: structured thinking
Notes of Dr. Carolyn ROS é's social networking speech
数据库中间件_Mycat总结
Download and installation of QT Creator
Mexican SQL manual injection vulnerability test (mongodb database) problem solution
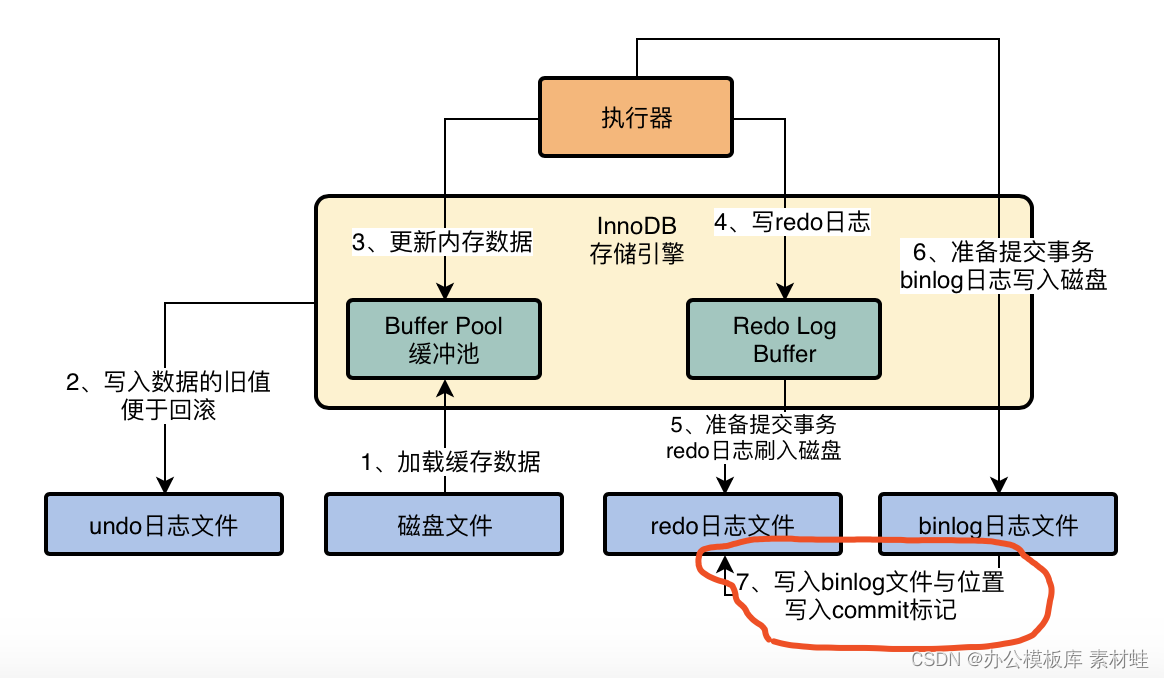
MySQL Real Time Optimization Master 04 discute de ce qu'est binlog en mettant à jour le processus d'exécution des déclarations dans le moteur de stockage InnoDB.
Routes and resources of AI
随机推荐
A necessary soft skill for Software Test Engineers: structured thinking
ByteTrack: Multi-Object Tracking by Associating Every Detection Box 论文阅读笔记()
基于Pytorch肺部感染识别案例(采用ResNet网络结构)
用于实时端到端文本识别的自适应Bezier曲线网络
Super detailed steps to implement Wechat public number H5 Message push
Time in TCP state_ The role of wait?
MySQL实战优化高手11 从数据的增删改开始讲起,回顾一下Buffer Pool在数据库里的地位
CDC: the outbreak of Listeria monocytogenes in the United States is related to ice cream products
13 医疗挂号系统_【 微信登录】
The underlying logical architecture of MySQL
实现微信公众号H5消息推送的超级详细步骤
MySQL ERROR 1040: Too many connections
MySQL实战优化高手07 生产经验:如何对生产环境中的数据库进行360度无死角压测?
MySQL34-其他数据库日志
MySQL36-数据库备份与恢复
What is the difference between TCP and UDP?
MySQL实战优化高手03 用一次数据更新流程,初步了解InnoDB存储引擎的架构设计
MySQL Real Time Optimization Master 04 discute de ce qu'est binlog en mettant à jour le processus d'exécution des déclarations dans le moteur de stockage InnoDB.
MySQL combat optimization expert 10 production experience: how to deploy visual reporting system for database monitoring system?
docker MySQL解决时区问题