当前位置:网站首页>Why is MySQL still slow to query when indexing is used?
Why is MySQL still slow to query when indexing is used?
2022-07-06 10:43:00 【popofzk】
Preface
During my internship in Huawei in recent months , There is a scenario of data retrieval , For one sn The inquiry of No. took several minutes , Batch check dozens sn when , It takes ten or twenty minutes sql Query time , Therefore, it is specially to sort out and think about this problem .
First , This database exists HIVE On , After communicating with some predecessors , I learned that databases in enterprises are mainly divided into two kinds :OLTP(on-line transaction processing) transactional 、OLAP(On-Line Analytical Processing) Analytical .
- OLTP Is the main application of traditional relational database , Basically 、 Routine business , For example, bank transactions .
- OLAP Is the main application of data warehouse system , Support complex analysis operations , Focus on decision support , And provide intuitive and easy to understand query results .
- that , Transactional databases OLTP Mainly small transactions and small queries , When evaluating its system , It's generally seen that it's executed every second Transaction as well as Execute SQL The number of . In such a system , A single database processes Transaction Often more than a few hundred , Or thousands of them ,Select The execution amount of statements is thousands or even tens of thousands per second .OLTP The most common bottleneck in the system is CPU And disk subsystem .
- OLAP, It's also called online analytical processing (Online Analytical Processing) System , Sometimes it's called DSS Decision support system , That's what we call data warehouse . In such a system , The execution amount of the statement is not the evaluation standard , Because the execution time of a statement may be very long , There's also a lot of data to read . therefore , In such a system , The evaluation standard is often the throughput of the disk subsystem ( bandwidth ), If so, how much MB/s Of traffic . The throughput of disk subsystem often depends on the number of disks , This is the time ,Cache Basically, it has no effect , The reading and writing types of the database are basically db file scattered read And direct path read/write. Try to use a large number of disks and a large bandwidth , Such as 4Gb Optical fiber interface .
stay OLAP In the system , Partition technology is often used 、 Parallel technology .
Factors affecting query speed
Back to the point , Why did I use the index , The query speed is still very slow ? What problems will happen , And how to solve ? This article explores one or two .
Give a conclusion first :MySQL The index used is not necessarily related to the length of execution time , What determines the efficiency of query execution is “ Number of scanning lines ” And “ Number of times to return to the meter ”.
- Number of scanning lines
- Number of times to return to the meter
In practice sql In the process of optimization , Also try to optimize these two influencing factors .
give an example
Illustrate with examples :
CREATE TABLE t
id int(11)NOT NULL
a varchar(64)DEFAULT NULL,
b int(11)DEFAULT NULL,
PRIMARY KEY (id)
KEY a(a) ENGINE-InnoDB
Query OK, O rows affected(0.02 sec)
Build a watch first ,InnoDB There must be a primary key index , Here to id Primary key , Second, there is a、b Two fields , Give again a Field ( Name field ) A common index , At present, there are primary key indexes and a Index tree structure , As shown in the figure below :
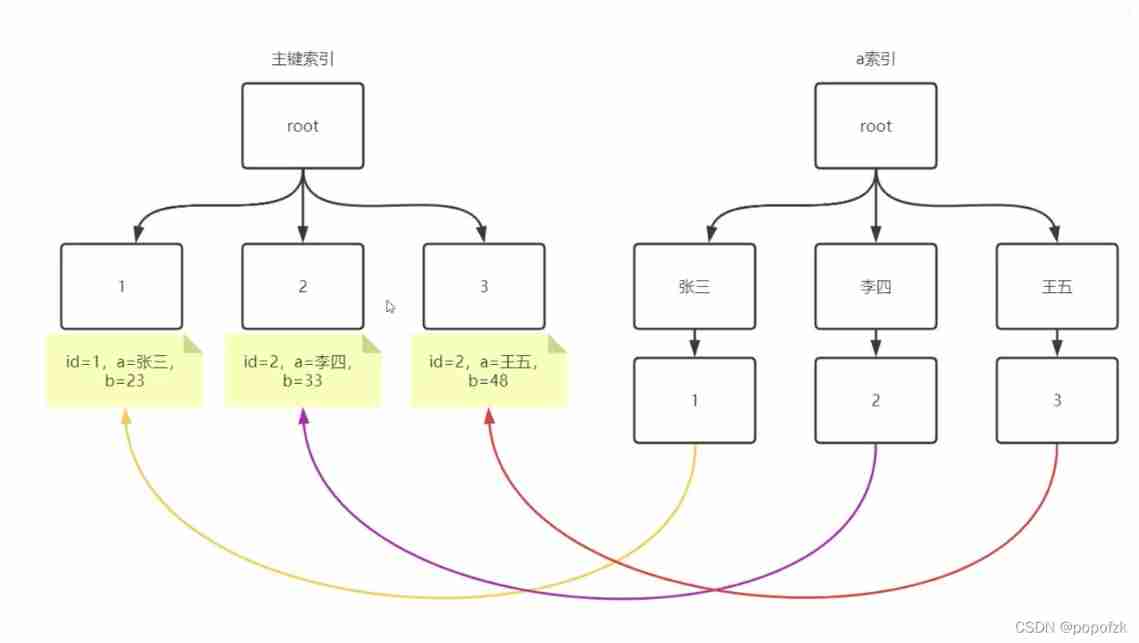
Let's go back to ,InnoDB There is a primary key index by default , It stores the primary key id1、2、3…, It's using B+ tree Clustering index of , All data is stored in leaf nodes , And ordinary index a The data of only contains the corresponding id, There is no whole row of data , So if you find someone through a common index id, need select Other fields , You also need to go back to the table to find the value of the whole row of data in the primary key index !
The slow query :
sq The medium slow query threshold is ong_ query time=10s
When sq Greater than 10s Will be recorded as slow sq Records
General suggestions are reduced to 1s, Generally speaking, when a certain item in a concurrent system sql The query time is longer than 1s 了 , The performance of the overall system will be greatly affected .
situation 1:
select * from t # Full table scan 
among ,type=ALL Means to scan all lines , The speed is the slowest , Scan from beginning to end .
situation 2:
select * from where id = 2 # Primary key index fast filtering 
According to primary key id Index to query , At this time key That's the index , Speed is the fastest , Don't go back to the table
situation 3:
select a from t # Index overlay , There is no need to return the form 
Index coverage , The query speed is also very fast , Because you don't have to go back to the table , The index adopted is a, It's the same thing a Field , It is also one step in place .
stay MySQL In the process of large paging, the index coverage method is also used to optimize
situation 4:
select * from t where id>0 # be based on id Scan the whole table , And generate a large number of back tables , Slow speed 
use * Or multiple fields may need full table scanning .
Generally speaking, the amount of data queried should be the whole table 25% within , The database will judge the value of indexing , You can't just look here key There is primary I think the index will be soon after I leave , But also depends on row How many lines were scanned in , In this case row The number of rows in is equal to the total number of rows in the table , The query speed is not fast , It's a full table scan !
situation 5:
create index t on(a, b)
hypothesis t Table has 1 Hundreds of millions of people , among 600 the masses “ Zhang ”
select* from t where a= Zhang San and b=23
Index selectivity is very good
select from t where a like 5k%' and b =23
Poor index selectivity , But the index will still be used
As a joint index , According to the leftmost prefix rule mentioned in the previous blog , We have to where According to the order of joint index , Check the right index based on the left index , So the first sentence is sql It is relatively fast , You can directly find Zhang San in the joint index tree ; The second sentence uses fuzzy query , If the number of people surnamed Zhang exceeds the total 10%、15%,MySQL You will think that such selectivity is too poor , You won't use indexes !( There is no value in using indexes !) Instead, I went to scan the whole table . The design here is 1 Of the 100 million people 600 Ten thousand surnames “ Zhang ”, So although the index selectivity is relatively poor , however MySQL I think we can still use index .
MySQL5.6 And then the optimization :index condition pushdown, Optimized the order of magnitude of the back table
- mysq5.6 before , Based on the left column pair 600 Ten thousand return forms screening 23 Age data , Relatively slow
- mysq5.6 in the future , Based on the left column of the union index a Screening “ Zhang " Then screen “23 year ”, Speak again
Qualified id Back to table extraction , The number of returns has been greatly reduced
This new feature is called " index condition pushdown”
Several tuning methods :
- Add multiple indexes of different specifications to improve index selectivity (5~6 Group )
- Space for time , Regular task increase times 、 daily 、 Make an appointment and wait for intermediate results
- Edge operation data compression : Internet of things tricks
4 Hardware tuning : increase innodb buffer pool Make more use of memory , Reduce hard disk back to the table
explain :
2. Every hour Calculate every minute , Make a summary , Instead of a full summary , In this way, the amount of data is much smaller
3. Edge operation : For example, millions of base stations upload data to the server every second , Then the pressure of the server must be great , If there is no abnormality in the data in the past hour , You can use an expression to compress an hour of data status records into one record , Realize data compression , Report it up again , The pressure is greatly reduced
4. Optimize from the perspective of hardware , Increase the memory !
边栏推荐
- CSDN博文摘要(一) —— 一个简单的初版实现
- [paper reading notes] - cryptographic analysis of short RSA secret exponents
- 保姆级手把手教你用C语言写三子棋
- Global and Chinese markets of static transfer switches (STS) 2022-2028: Research Report on technology, participants, trends, market size and share
- C language string function summary
- Moteur de stockage mysql23
- Isn't there anyone who doesn't know how to write mine sweeping games in C language
- Mysql22 logical architecture
- Windchill configure remote Oracle database connection
- Discriminant model: a discriminant model creation framework log linear model
猜你喜欢

Super detailed steps for pushing wechat official account H5 messages
MySQL26-性能分析工具的使用

API learning of OpenGL (2003) gl_ TEXTURE_ WRAP_ S GL_ TEXTURE_ WRAP_ T
Super detailed steps to implement Wechat public number H5 Message push
C language advanced pointer Full Version (array pointer, pointer array discrimination, function pointer)
MySQL 29 other database tuning strategies
实现以form-data参数发送post请求
Mysql28 database design specification
MySQL29-数据库其它调优策略
IDEA 导入导出 settings 设置文件
随机推荐
Isn't there anyone who doesn't know how to write mine sweeping games in C language
Pytoch LSTM implementation process (visual version)
Database middleware_ MYCAT summary
Timestamp with implicit default value is deprecated error in MySQL 5.6
Ueeditor internationalization configuration, supporting Chinese and English switching
API learning of OpenGL (2002) smooth flat of glsl
Mysql36 database backup and recovery
保姆级手把手教你用C语言写三子棋
MySQL31-MySQL事务日志
MySQL 20 MySQL data directory
Texttext data enhancement method data argument
Global and Chinese markets of static transfer switches (STS) 2022-2028: Research Report on technology, participants, trends, market size and share
Not registered via @enableconfigurationproperties, marked (@configurationproperties use)
First blog
[C language] deeply analyze the underlying principle of data storage
Advantages and disadvantages of evaluation methods
Const decorated member function problem
[Li Kou 387] the first unique character in the string
Copy constructor template and copy assignment operator template
MySQL transaction log