当前位置:网站首页>Mysql27 index optimization and query optimization
Mysql27 index optimization and query optimization
2022-07-06 10:29:00 【Protect our party a Yao】
One . Data preparation
Student table insert 50 ten thousand strip , Class table insert 1 ten thousand strip .
1.1. Build table
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
1.2. Set parameters
Command on : Allows you to create function settings :
set global log_bin_trust_function_creators=1; # No addition global Only the current window is valid .
1.3. Create a function
Make sure every data is different .
# Randomly generate strings
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
# If you want to delete
#drop function rand_string;
Randomly generate class number
# Used to randomly generate number to number
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
# If you want to delete
#drop function rand_num;
1.4. Create stored procedure
To create class A stored procedure that inserts data into a table
# Execute stored procedures , Go to class Add random data to table
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES
(rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
# If you want to delete
#drop PROCEDURE insert_class;
1.5. Calling stored procedure
class
# Execute stored procedures , Go to class Table to add 1 Ten thousand data
CALL insert_class(10000);
stu
# Execute stored procedures , Go to stu Table to add 50 Ten thousand data
CALL insert_stu(100000,500000);
1.6. Delete an index on a table
Create stored procedure
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM
information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND
seq_in_index=1 AND index_name <>'PRIMARY' ;
# Each cursor must use a different declare continue handler for not found set done=1 To control the end of the cursor
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
# If no data is returned , The program continues , And change the done Set to 2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
Execute stored procedures
CALL proc_drop_index("dbname","tablename");
Two . Index failure cases
2.1. Full match
2.2. The best left prefix rule
expand :Alibaba《Java Development Manual 》
Index file has B-Tree The leftmost prefix matching property of , If the value on the left is not determined , Then you can't use this index .
2.3. Primary key insertion order

If another primary key is inserted at this time, the value is 9 The record of , The insertion position is shown as follows :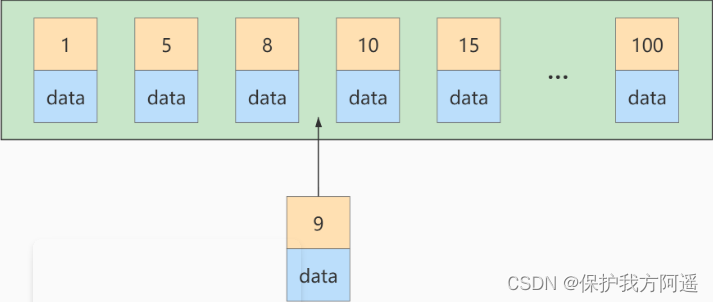
But this data page is full , What if you plug in again ? We need to put the current Page splitting In two pages , Move some records in this page to the newly created page . What does page splitting and record shifting mean ? signify : Performance loss ! So if we want to avoid this kind of unnecessary performance loss , It's best to let the inserted record The primary key values are incremented , In this way, there will be no such performance loss . So we suggest : Let the primary key have AUTO_INCREMENT , Let the storage engine generate the primary key for the table itself , Instead of manually inserting , such as : person_info surface :
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
);
Our custom primary key column id Have AUTO_INCREMENT attribute , When inserting records, the storage engine will automatically fill in the self increasing primary key value for us . Such a primary key takes up less space , Write in sequence , Reduce page splits .
2.4. Calculation 、 function 、 Type conversion ( Automatic or manual ) Cause index to fail
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
Create index
CREATE INDEX idx_name ON student(NAME);
The first one is : Index optimization takes effect
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';

The second kind : Index optimization failure
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';

type by “ALL”, Indicates that the index is not used .
Another example :
- student Table fields stuno There is an index on the .
CREATE INDEX idx_sno ON student(stuno);
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;

- Index optimization takes effect
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;

Another example :
3. student Table fields name There is an index on the
CREATE INDEX idx_name ON student(NAME);
EXPLAIN SELECT id, stuno, name FROM student WHERE SUBSTRING(name, 1,3)='abc';

EXPLAIN SELECT id, stuno, NAME FROM student WHERE NAME LIKE 'abc%';

2.5. Index invalidation due to type conversion
Which of the following sql Statement can be used with index .( hypothesis name The field is set with an index )
name=123 Type conversion occurs , Index failure .
Index not used
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
# Use to index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';
2.6. The column index to the right of the range condition fails
ALTER TABLE student DROP INDEX idx_name;
ALTER TABLE student DROP INDEX idx_age;
ALTER TABLE student DROP INDEX idx_age_classid;
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ;
create index idx_age_name_classid on student(age,name,classid);
- Place the range query condition at the end of the statement :
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name =
'abc' AND student.classId>20 ;

2.7. It's not equal to (!= perhaps <>) Index failure
2.8. is null You can use index ,is not null Index not available
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
2.9. like Use wildcards % Invalid start index
expand :Alibaba《Java Development Manual 》
【 mandatory 】 Page search must not be left blurred or full blurred , If you need to go to search engine to solve .
2.10. OR There are non indexed columns before and after , Index failure
# Index not used
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
# Use to index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR name = 'Abel';
2.11. Database and table character sets are used uniformly utf8mb4
Unified use utf8mb4( 5.5.3 Version above supports ) Better compatibility , The unified character set can avoid the chaos caused by character set conversion . Different Character set Before comparison transformation Will cause index invalidation .
3、 ... and . Association query optimization
3.1. Prepare the data
# classification
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
# The book
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
# Add... To the classification table 20 Bar record
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
# Add... To the book table 20 Bar record
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
3.2. Use left outer connection
Let's start with EXPLAIN analysis
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
 Conclusion :type Yes All
Conclusion :type Yes All
Add index optimization
ALTER TABLE book ADD INDEX Y ( card); #【 Was the driver table 】, It can avoid full scan
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
 You can see the second line type Change into ref,rows The optimization is obvious . This is determined by the left join feature .LEFT JOIN Criteria are used to determine how rows are searched from the right table , There must be... On the left , therefore On the right is our key point , There must be an index .
You can see the second line type Change into ref,rows The optimization is obvious . This is determined by the left join feature .LEFT JOIN Criteria are used to determine how rows are searched from the right table , There must be... On the left , therefore On the right is our key point , There must be an index .
ALTER TABLE `type` ADD INDEX X (card); #【 The driver table 】, Cannot avoid full table scanning
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

next :
DROP INDEX Y ON book;
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

3.3. Internal connection is adopted
drop index X on type;
drop index Y on book;( If it has been deleted, you can no longer perform this operation )
Switch to inner join(MySQL Auto select drive table )
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
 Add index optimization
Add index optimization
ALTER TABLE book ADD INDEX Y ( card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;

ALTER TABLE type ADD INDEX X (card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
 next :
next :
DROP INDEX X ON `type`;
EXPLAIN SELECT SQL_NO_CACHE * FROM TYPE INNER JOIN book ON type.card=book.card;
 next :
next :
ALTER TABLE `type` ADD INDEX X (card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;

3.4. join Statement principle
Index Nested-Loop Join
CREATE TABLE `t2` (
`id` INT(11) NOT NULL,
`a` INT(11) DEFAULT NULL,
`b` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
INDEX `a` (`a`)
) ENGINE=INNODB;
DELIMITER //
CREATE PROCEDURE idata()
BEGIN
DECLARE i INT;
SET i=1;
WHILE(i<=1000)DO
INSERT INTO t2 VALUES(i, i, i);
SET i=i+1;
END WHILE;
END //
DELIMITER ;
CALL idata();
# establish t1 Table and copy t1 Front of table 100 Data
CREATE TABLE t1
AS
SELECT * FROM t2
WHERE id <= 100;
# Test table data
SELECT COUNT(*) FROM t1;
SELECT COUNT(*) FROM t2;
# Look at the index
SHOW INDEX FROM t2;
SHOW INDEX FROM t1;
Let's take a look at this sentence :
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.a);
If used directly join sentence ,MySQL The optimizer may select tables t1 or t2 As a driving table , This will affect our analysis SQL Statement execution . therefore , In order to analyze the performance problems in the execution process , I switch to straight_join Give Way MySQL Perform queries using fixed joins , In this way, the optimizer will only follow the way we specify join. In this statement ,t1 It's the drive meter ,t2 It's driven watch .
You can see , In this sentence , Was the driver table t2 Field of a There's an index on ,join The process uses this index , Therefore, the execution process of this statement is as follows :
- From the table t1 Read in a row of data R;
- From the data line R in , Take out a Field to table t2 Go to find ;
- Take out the watch t2 The line that satisfies the condition in , Follow R Form a line , As part of the result set ;
- Repeat steps 1 To 3, Until the watch t1 At the end of the loop .
This process is to traverse the table first t1, Then according to the table t1 In each row of data taken from a value , Go to the table t2 Find the records that meet the conditions in . In form , This process is similar to the nested query when we write a program , And you can use the index of the driven table , So we call it “Index Nested-Loop Join”, abbreviation NLJ.
Its corresponding flow chart is shown below :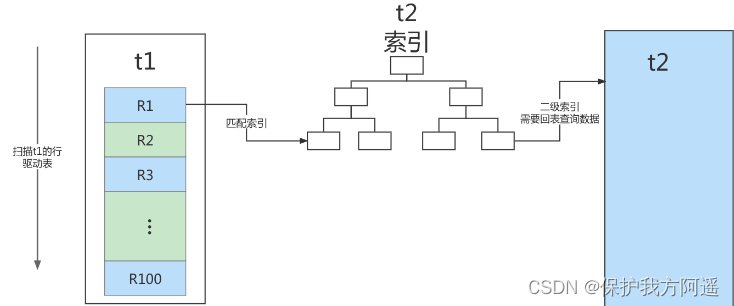
In this process : - On the drive table t1 Did a full scan , This process requires scanning 100 That's ok ;
- And for every line R, according to a Field to table t2 lookup , It's a tree search process . Because the data we construct are one-to-one correspondence , So every search process only scans one line , It's a total scan 100 That's ok ;
- therefore , The whole execution process , The total number of scan lines is 200.
3.5. Summary
- Make sure that the driven meter JOIN The field has been indexed .
- need JOIN Field of , Data types are absolutely consistent .
- LEFT JOIN when , Choose a small watch as the driving watch , Big watch as driven watch . Reduce the number of outer cycles .
- INNER JOIN when ,MySQL Will automatically The table of the small result set is selected as the driving table . Choose to believe MySQL Optimization strategy .
- If you can directly associate multiple tables, try to associate directly , No sub query .( Reduce the number of queries ).
- Subqueries are not recommended , It is suggested that sub query SQL Open the combination program many times , Or use JOIN Instead of subquery .
- Derivative tables cannot be indexed
Four . Sub query optimization
MySQL from 4.1 The version begins to support subqueries , Using subqueries, you can SELECT Nested query of statement , That is, a SELECT The result of the query is used as another SELECT The condition of the statement . Subqueries can be done at one time, which logically requires multiple steps SQL operation .
The subquery is MySQL An important function of , Can help us through a SQL Statement to realize more complex query . however , The execution efficiency of sub query is not high . reason :
① When executing a subquery ,MySQL The query result of the inner query statement Create a temporary table , Then the outer query statement queries the record from the temporary table . When the query is finished , Again Undo these temporary tables . This will consume too much CPU and IO resources , Generate a lot of slow queries .
② The temporary table stored in the result set of the subquery , Neither memory temporary table nor disk temporary table can be used There will be no index , So query performance is affected .
③ For subqueries that return large result sets , The greater the impact on query performance .
stay MySQL in , You can use connections (JOIN) Query instead of subquery . Link query There is no need to create a temporary table , Its Faster than subqueries , If an index is used in the query , The performance will be better .
Conclusion : Try not to use NOT IN perhaps NOT EXISTS, use LEFT JOIN xxx ON xx WHERE xx IS NULL replace
5、 ... and . Sort optimization
5.1. Sort optimization
problem : stay WHERE Add an index to the condition field , But why ORDER BY There are more references on the field ?
Optimization Suggestions :
- SQL in , Can be in WHERE Clause and ORDER BY Use index in clause , Aimed at WHERE clause Avoid full table scanning , stay ORDER BY Clause Avoid using FileSort Sort . Of course , In some cases, full table scanning , perhaps FileSort Sorting is not necessarily slower than indexing . But on the whole , We still have to avoid , To improve query efficiency .
- Use as much as possible Index complete ORDER BY Sort . If WHERE and ORDER BY After the same column, use the single index column ; If different, use a federated index .
- Can't use Index when , Need to be right FileSort Way to tune .
INDEX a_b_c(a,b,c)
order by Can use index leftmost prefix
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC,b DESC,c DESC
If WHERE The leftmost prefix of the index is defined as a constant , be order by Can use index
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b = const ORDER BY c
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b > const ORDER BY b,c
Can't use index to sort
- ORDER BY a ASC,b DESC,c DESC /* The order is inconsistent */
- WHERE g = const ORDER BY b,c /* The loss of a Indexes */
- WHERE a = const ORDER BY c /* The loss of b Indexes */
- WHERE a = const ORDER BY a,d /*d Not part of the index */
- WHERE a in (...) ORDER BY b,c /* For sorting , Multiple equality conditions are also range queries */
5.2. Case actual combat
ORDER BY Clause , Use as much as possible Index Sort by , Avoid using FileSort Sort by .
Clear the case before executing student Index on , Leave only the primary key :
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid_stuno ON student;
DROP INDEX idx_age_classid_name ON student;
# perhaps
call proc_drop_index('INDEXTEST','student');
scene : Query age is 30 Year old , And the student number is less than 101000 Of the students , Sort by user name
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY
NAME ;

Conclusion :type yes ALL, In the worst case .Extra There is also Using filesort, It's also the worst case . Optimization is necessary .
Optimization idea :
Scheme 1 : To get rid of it filesort We can build the index
# Create a new index
CREATE INDEX idx_age_name ON student(age,NAME);
Option two : Try to make where The filter conditions and sorting of use the upper index
Build a combined index of three fields :
DROP INDEX idx_age_name ON student;
CREATE INDEX idx_age_stuno_name ON student (age,stuno,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY
NAME ;
It turned out to be filesort Of sql Running speed , Beyond what has been optimized filesort Of sql , And much faster , The result appeared almost instantly .
Conclusion :
1. Two indexes exist at the same time ,mysql Automatically select the best scheme .( For this example ,mysql choice
idx_age_stuno_name). however , As the amount of data changes , The selected index will also change .
2. When 【 Range conditions 】 and 【group by perhaps order by】 One of two fields appears , The priority observation condition field is too
Filter quantity , If enough data is filtered , When there is not much data to sort , Put the index first in the range field
On . conversely , also .
5.3. filesort Algorithm : Two way sorting and single way sorting
5.3.1. Two way sorting ( slow )
- MySQL 4.1 It used to be two-way sorting , Literally, two scans of the disk , And finally get the data , Read the line pointer and order by Column , Sort them out , Then scan the sorted list , Re read the corresponding data output from the list according to the value in the list .
- Take sort field from disk , stay buffer Sort , Again from Take other fields from the disk .
Take a batch of data , To scan the disk twice , as everyone knows ,IO It's time consuming , So in mysql4.1 after , There is a second improved algorithm , It's one-way sorting .
5.3.2. One way sorting ( fast )
To read the query from disk All columns , according to order by Listed in buffer Sort them out , Then scan the sorted list for output , It's more efficient , Avoid reading data for the second time . And put random IO It becomes a sequence IO, But it will use more space , Because it keeps every line in memory .
5.3.3. Optimization strategy
- Try to improve sort_buffer_size.
- Try to improve max_length_for_sort_data.
- Order by when select * It's a big taboo . Better just Query Required fields .
6、 ... and . GROUP BY Optimize
- group by The principle of using indexes is almost the same as order by Agreement ,group by Even if no filter conditions are used, the index , You can also use the index directly .
- group by Sort first and then group , Follow the best left prefix rule for indexing .
- When index columns cannot be used , increase max_length_for_sort_data and sort_buffer_size Parameter settings .
- where Efficiency is higher than having, It can be written in where Don't write the limited conditions in having It's in .
- Reduce use order by, Communication with business can not be sorted , Or put the sorting on the program side .Order by、groupby、distinct These statements are more expensive CPU, Database CPU Resources are extremely valuable .
- Contains order by、group by、distinct Statements for these queries ,where Please keep the result set filtered by the condition in 1000 Within the line , otherwise SQL It's going to be slow .
7、 ... and . Optimize paging queries
Optimization idea 1 :
Complete sort paging operation on Index , Finally, according to the primary key Association, return to the original table to query other column contents .
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10)
a
WHERE t.id = a.id;

Optimization idea II :
This scheme is applicable to tables with self increasing primary key , You can put Limit The query is converted to a query in a certain location .
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;

8、 ... and . Override index first
8.1. What is an overlay index ?
Way of understanding one : Indexing is an efficient way to find rows , But the general database can also use the index to find the data of a column , So it doesn't have to read the entire line . After all, index leaf nodes store the data they index ; When you can get the desired data by reading the index , Then there's no need to read lines . An index that contains data that meets the query results is called an overlay index .
Two ways of understanding : A form of non clustered composite index , It's included in the query SELECT、JOIN and WHERE All columns used in clause ( That is, the fields to be indexed are exactly the fields involved in the overwrite query criteria ).
In short, it is , Index columns + Primary key contain SELECT To FROM Columns queried between .
8.2. Advantages and disadvantages of overwriting indexes
benefits :
- avoid Innodb The table makes a secondary query for the index ( Back to the table ).
- You can take the random IO Into order IO Speed up query efficiency .
disadvantages :
Maintenance of index fields There is always a price . therefore , A trade-off is needed when building redundant indexes to support coverage indexes . This is business DBA, Or the work of a business data architect .
Nine . How to add an index to a string
There is a teacher list , The table is defined as follows :
create table teacher(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=innodb;
Instructor to log in using email , So there must be statements like this in the business code :
select col1, col2 from teacher where email='xxx';
If email There is no index on this field , Then this statement can only do Full table scan .
9.1. Prefix index
MySQL Prefix index is supported . By default , If you create an index statement without specifying the prefix length , Then the index will contain the entire string .
alter table teacher add index index1(email)
# or
alter table teacher add index index2(email(6));
What are the differences between these two definitions in data structure and storage ? The following figure is the schematic diagram of these two indexes .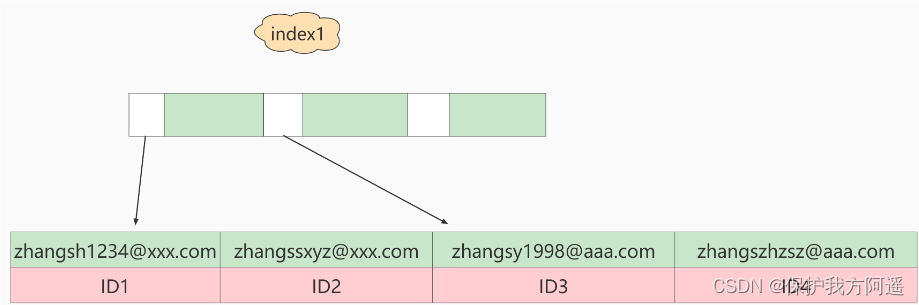 as well as :
as well as :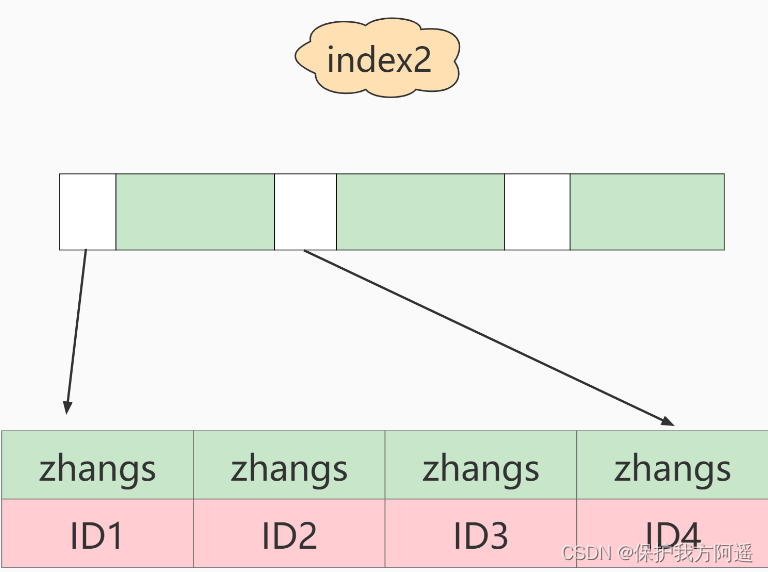
If you are using index1( namely email The index structure of the entire string ), This is the order of execution :
- from index1 The index tree is found to satisfy the index value ’ [email protected] ’ This record of , obtain ID2 Value ;
- The primary key value is found on the primary key ID2 The line of , Judge email The value of is correct , Add this line of record to the result set ;
- take index1 The next record of the location just found in the index tree , The discovery is not satisfied email=’ [email protected] ’ The condition of the , The loop ends .
In the process , You only need to retrieve data from the primary key index once , So the system thinks it only scanned one line .
If you are using index2( namely email(6) Index structure ), This is the order of execution : - from index2 The index tree is found to satisfy the index value ’zhangs’ The record of , The first one we found was ID1;
- The primary key value is found on the primary key ID1 The line of , Determine the email The value is not ’ [email protected] ’, This record is discarded ;
- take index2 The next record on the location just found , The discovery is still ’zhangs’, Take out ID2, Until then ID Round the row on the index and judge , This time it was right , Add this line of record to the result set ;
- Repeat the previous step , Until idxe2 The value taken up is not ’zhangs’ when , The loop ends .
In other words, prefix index is used , Define the length , You can save space , There is no need to add too much query cost . As mentioned earlier, discrimination , The higher the discrimination, the better . Because the higher the discrimination , Means fewer duplicate key values .
9.2. The influence of prefix index on overlay index
Conclusion :
Using prefix index can't optimize query performance with covering index , This is also a factor to consider when choosing whether to use prefix index or not .
Ten . Index push down
Index Condition Pushdown(ICP) yes MySQL 5.6 China new features , It's an optimized way to use indexes to filter data in the storage engine layer .ICP It can reduce the number of times the storage engine accesses the base table and MySQL The number of times the server has access to the storage engine .
10.1. Scanning process before and after use
Without using ICP The process of index scanning :
storage layer : Will only satisfy index key Retrieve the entire row of records corresponding to the index record of the condition , Return to server layer .
server layer : For the returned data , Use the following where filter , Until you return to the last line .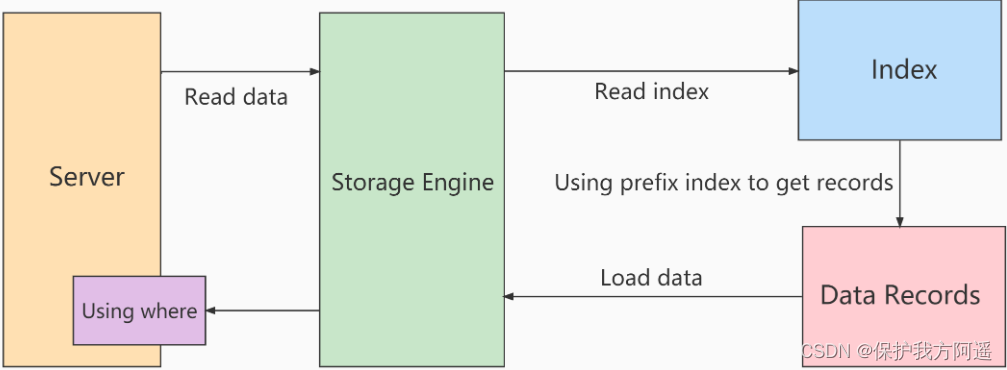
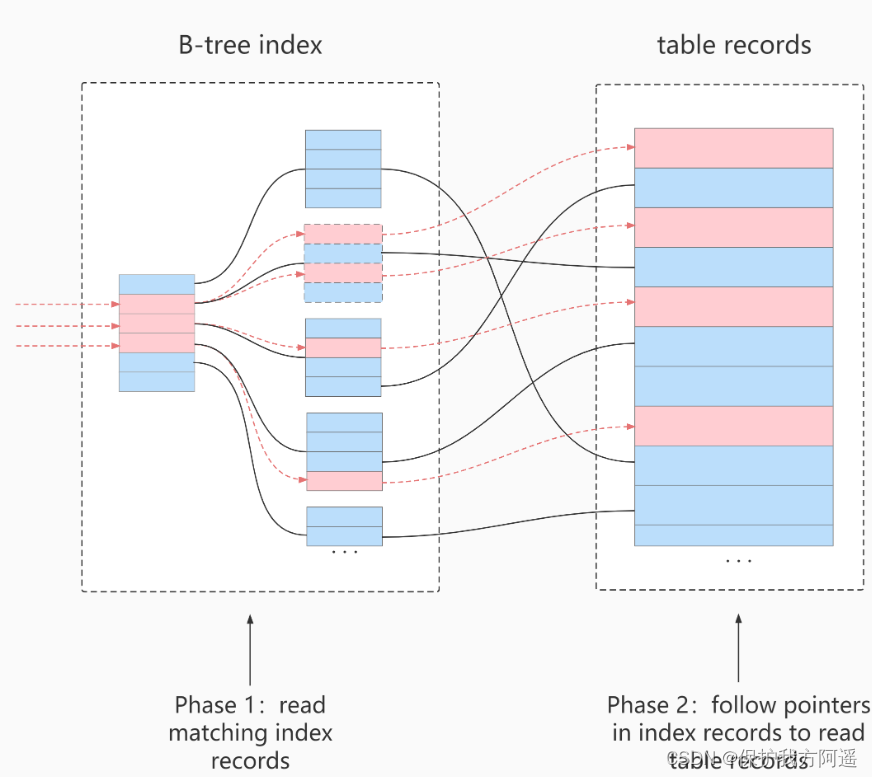
Use ICP The process of scanning :
- storage layer :
First of all, will index key Determination of index record interval satisfying conditions , Then use... On the index index filter To filter . Will satisfy indexfilter The conditional index records go back to the table, take out the whole row of records, and return server layer . dissatisfaction index filter The index record of the condition is discarded , Don't return the form 、 And will not return server layer . - server layer :
For the returned data , Use table filter Condition for final filtering .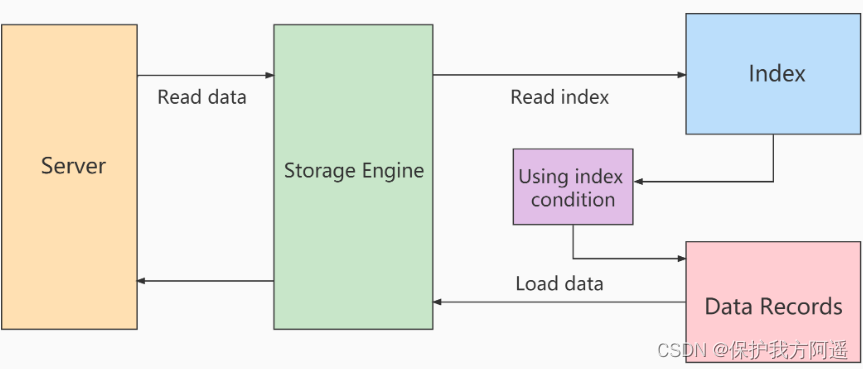
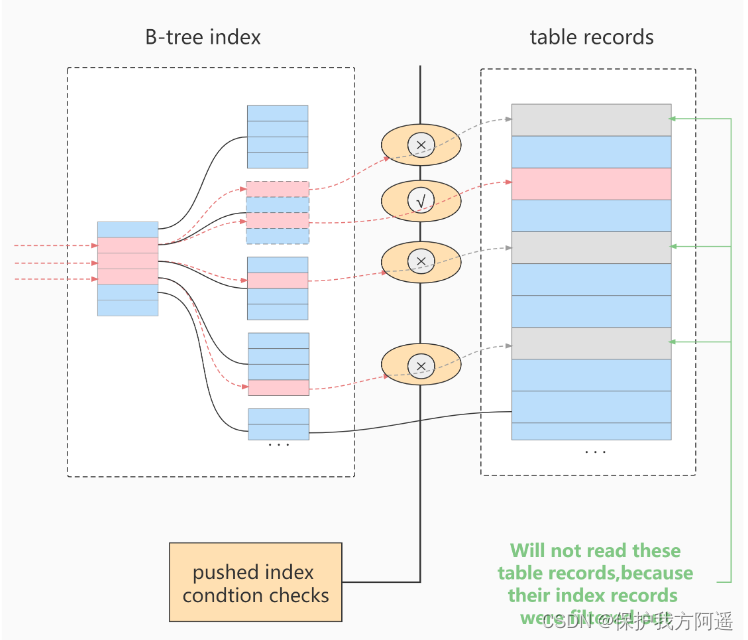 Cost difference before and after use
Cost difference before and after use
- Before using , The storage layer returns more information that needs to be index filter Filtered out entire line of records
- Use ICP after , Directly get rid of dissatisfaction index filter Record of conditions , It saves them from going back to the table and passing it to server The cost of the layer .
- ICP Of Acceleration effect Depends on passing through the storage engine ICP Screening The proportion of data dropped .
10.2. ICP Conditions of use
ICP Conditions of use :
① Can only be used for secondary index (secondary index)
②explain In the displayed execution plan type value (join type ) by range 、 ref 、 eq_ref perhaps ref_or_null .
③ Not all of them where All conditions can be used ICP Screening , If where The field of the condition is not in the index column , Or read the records of the whole table
To server End to do where Filter .
④ ICP It can be used for MyISAM and InnnoDB Storage engine
⑤ MySQL 5.6 The version of does not support partition tables ICP function ,5.7 The beginning of the version supports .
⑥ When SQL When using the overlay index , I won't support it ICP An optimization method .
10.3. ICP Use cases
Case study 1:
SELECT * FROM tuser
WHERE NAME LIKE ' Zhang %'
AND age = 10
AND ismale = 1;
 Case study 2:
Case study 2:
11、 ... and . General index vs unique index
In terms of performance , Choose a unique index or a normal index ? What is the basis of the choice ?
hypothesis , We have a primary key listed as ID Table of , There are fields in the table k, And in k There's an index on , Hypothetical field k The values on do not repeat .
The table creation statement of this table is :
reate table test(
id int primary key,
k int not null,
name varchar(16),
index (k)
)engine=InnoDB;
11.1. The query process
hypothesis , The statement to execute the query is select id from test where k=5.
- For a normal index , Find the first record that meets the criteria (5,500) after , Need to find the next record , Until I met the first one who was not satisfied k=5 Record of conditions .
- For a unique index , Because the index defines uniqueness , After finding the first record that meets the conditions , Will stop retrieving .
that , How much performance gap will this difference bring ? The answer is , very little .
11.2. The update process
To illustrate the impact of common index and unique index on the performance of update statements , Introduce to you change buffer.
When you need to update a data page , If the data page is in memory, update it directly , And if the data page is not in memory , Without affecting data consistency , InooDB These updates will be cached in change buffer in , So you don't need to read this data page from disk . The next time the query needs to access this data page , Read data pages into memory , And then execute change buffer Operations related to this page in . In this way, we can guarantee the correctness of the data logic .
take change buffer The operations in apply to the original data page , The process of getting the latest results is called merge . except Access this data page Will trigger merge Outside , The system has The background thread periodically merge. stay The database is closed normally (shutdown) In the process of , Will perform merge operation .
If the update operation can be recorded in change buffer, Reduce read disk , Statement execution speed will be significantly improved . and , Data read into memory is required to occupy buffer pool Of , So this way can also Avoid using memory , Improve memory utilization .
Only index updates are not available change buffer , In fact, only ordinary indexes can be used .
If you want to insert a new record in this table (4,400) Words ,InnoDB What is the processing flow of ?
11.3. change buffer Usage scenarios of
- How to choose between normal index and unique index ? Actually , There is no difference in query capability between these two types of indexes , The main consideration is the update performance Influence . therefore , It is recommended that you choose the normal index as much as possible .
- In practical use, we will find , General index and change buffer In combination with , about Large amount of data The update optimization of the table is obvious .
- If all the updates follow , Right away With the query of this record , Then you should close change buffer . And in other cases ,change buffer Can improve the update performance .
- Because the unique index cannot be referenced change buffer The optimization mechanism of , So if Business is acceptable , From the perspective of performance, it is recommended to give priority to non unique indexes . But if " Business may not be able to ensure " Under the circumstances , How to deal with it ?
- First , Business correctness first . Our premise is “ The business code has been guaranteed not to write duplicate data ” Under the circumstances , Discuss performance issues . If the business cannot guarantee , Or the business is to require the database to do constraints , So there's no choice , You must create a unique index . In this case , The meaning of this section is , If you encounter a large number of data insertion slow 、 When memory hit rate is low , Provide you with an additional troubleshooting idea .
- then , In some “ Archive ” Scene , You can consider using a unique index . such as , Online data only needs to be retained for half a year , The historical data is then stored in the archive . Now , Archiving data is already ensuring that there are no unique key conflicts . To improve the efficiency of archiving , Consider changing the unique index in the table to a normal index .
Twelve . Other query optimization strategies
12.1. About SELECT(*)
In table query , It is recommended to specify the field , Do not use * List of fields as query , Recommended SELECT < Field list > Inquire about . reason :
① MySQL In the process of parsing , Will pass Look up the data dictionary take "*" Convert to all column names in order , This will greatly consume resources and time .
② Can't use Overlay index .
12.2. LIMIT 1 Impact on Optimization
For those who will scan the whole table SQL sentence , If you can be sure that there is only one result set , So add LIMIT 1 When , When a result is found, the scan will not continue , This will speed up the query .
If the data table has a unique index on the field , Then you can query through the index , If you don't scan the whole table , You don't need to add LIMIT 1 了 .
12.3. More use COMMIT
Whenever possible , Use as much as possible in the program COMMIT, In this way, the performance of the program is improved , Demand can also be caused by COMMIT Less resources are released .
COMMIT The resources released :
- Information used to recover data on the rollback segment .
- A lock obtained by a program statement .
- redo / undo log buffer In the space .
- Manage the above 3 Internal costs in resources .
边栏推荐
- Emotional classification of 1.6 million comments on LSTM based on pytoch
- 西南大学:胡航-关于学习行为和学习效果分析
- 解决在window中远程连接Linux下的MySQL
- PyTorch RNN 实战案例_MNIST手写字体识别
- Carolyn Rosé博士的社交互通演讲记录
- Southwest University: Hu hang - Analysis on learning behavior and learning effect
- 高并发系统的限流方案研究,其实限流实现也不复杂
- Introduction tutorial of typescript (dark horse programmer of station B)
- text 文本数据增强方法 data argumentation
- Record the first JDBC
猜你喜欢
MySQL29-数据库其它调优策略

Super detailed steps to implement Wechat public number H5 Message push
15 医疗挂号系统_【预约挂号】
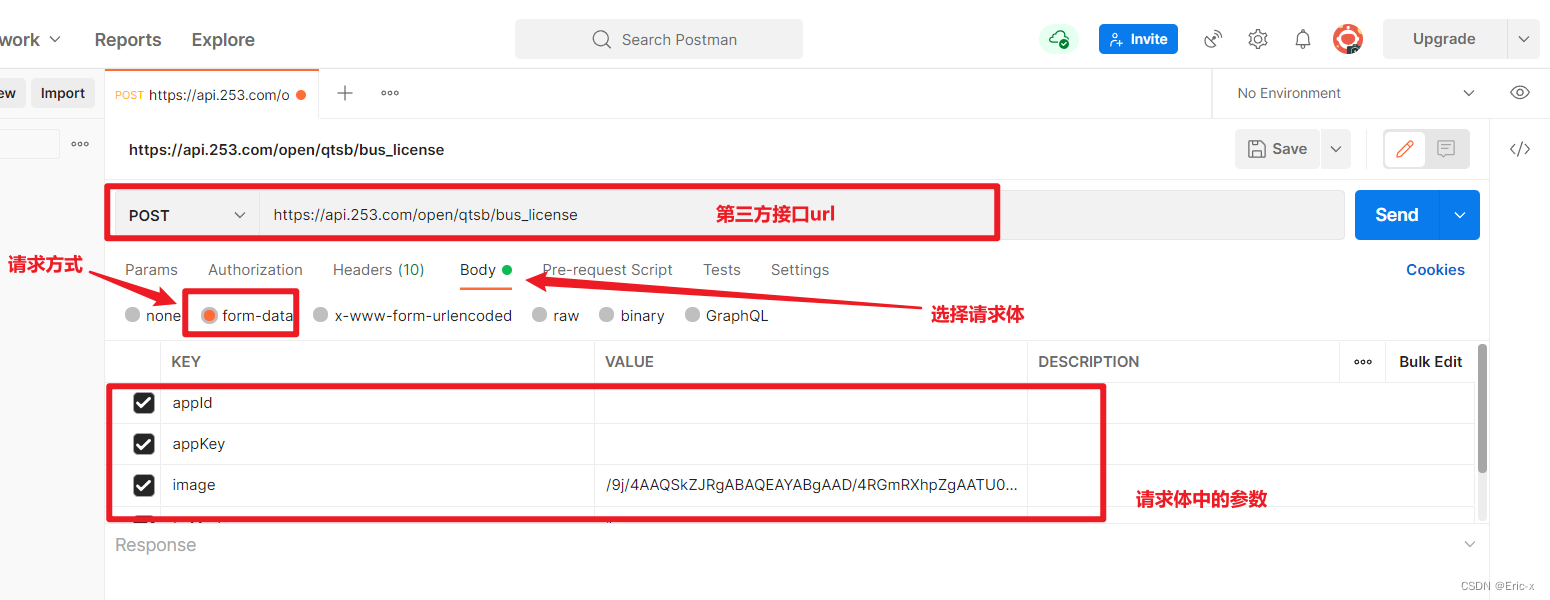
Implement sending post request with form data parameter
MySQL底层的逻辑架构
软件测试工程师必备之软技能:结构化思维
![[unity] simulate jelly effect (with collision) -- tutorial on using jellysprites plug-in](/img/1f/93a6c6150ec2b002f667a882569b7b.jpg)
[unity] simulate jelly effect (with collision) -- tutorial on using jellysprites plug-in
![14 medical registration system_ [Alibaba cloud OSS, user authentication and patient]](/img/c4/81f00c8b7037b5fb4c5df4d2aa7571.png)
14 medical registration system_ [Alibaba cloud OSS, user authentication and patient]
docker MySQL解决时区问题

Typescript入门教程(B站黑马程序员)
随机推荐
Southwest University: Hu hang - Analysis on learning behavior and learning effect
C miscellaneous two-way circular linked list
Ueeditor internationalization configuration, supporting Chinese and English switching
Not registered via @EnableConfigurationProperties, marked(@ConfigurationProperties的使用)
Not registered via @enableconfigurationproperties, marked (@configurationproperties use)
16 医疗挂号系统_【预约下单】
15 医疗挂号系统_【预约挂号】
MySQL ERROR 1040: Too many connections
The appearance is popular. Two JSON visualization tools are recommended for use with swagger. It's really fragrant
South China Technology stack cnn+bilstm+attention
PyTorch RNN 实战案例_MNIST手写字体识别
MySQL Real Time Optimization Master 04 discute de ce qu'est binlog en mettant à jour le processus d'exécution des déclarations dans le moteur de stockage InnoDB.
Pytorch LSTM实现流程(可视化版本)
A necessary soft skill for Software Test Engineers: structured thinking
用于实时端到端文本识别的自适应Bezier曲线网络
MySQL实战优化高手02 为了执行SQL语句,你知道MySQL用了什么样的架构设计吗?
Implement sending post request with form data parameter
MySQL实战优化高手06 生产经验:互联网公司的生产环境数据库是如何进行性能测试的?
Security design verification of API interface: ticket, signature, timestamp
[paper reading notes] - cryptographic analysis of short RSA secret exponents