当前位置:网站首页>CSDN问答模块标题推荐任务(二) —— 效果优化
CSDN问答模块标题推荐任务(二) —— 效果优化
2022-07-06 09:11:00 【Alexxinlu】
目录
系列文章
团队博客: CSDN AI小组
1. 问题背景
本篇文章承接上一篇文章《CSDN问答模块标题推荐任务(一) —— 基本框架的搭建》。简而言之,是对CSDN问答模块用户提问的标题进行效果优化,推荐给用户更为合理且信息量更大的标题。具体任务北京可参考上一篇文章,本篇文章主要介绍该任务的效果优化策略。
2. 效果优化方法论
效果优化的依据主要基于上一篇文章2.3节分析错误数据得到的问题,此外也结合了其他人的意见和建议,进行了更合理的改进。具体优化方法论如下。
2.1 无效标题的检测
在上一篇文章中,对所有的用户提问标题都进行了推荐,但很多情况下都是有效的标题(占比约91%),且小部分推荐后的标题可能会比原先的有效标题更差。故为了提升标题推荐的效率,以及避免原先已有标题推荐后效果更差,需要首先检测出所有的无效标题,在进一步进行标题推荐。
无效标题检测主要包含一下两种策略:
2.1.1 关键词匹配策略
大部分无效标题都包含了一些关键词,例如以下标题,包含了大佬、救救、急!、感谢,这些词构成的标题无法表达问题本身的意思。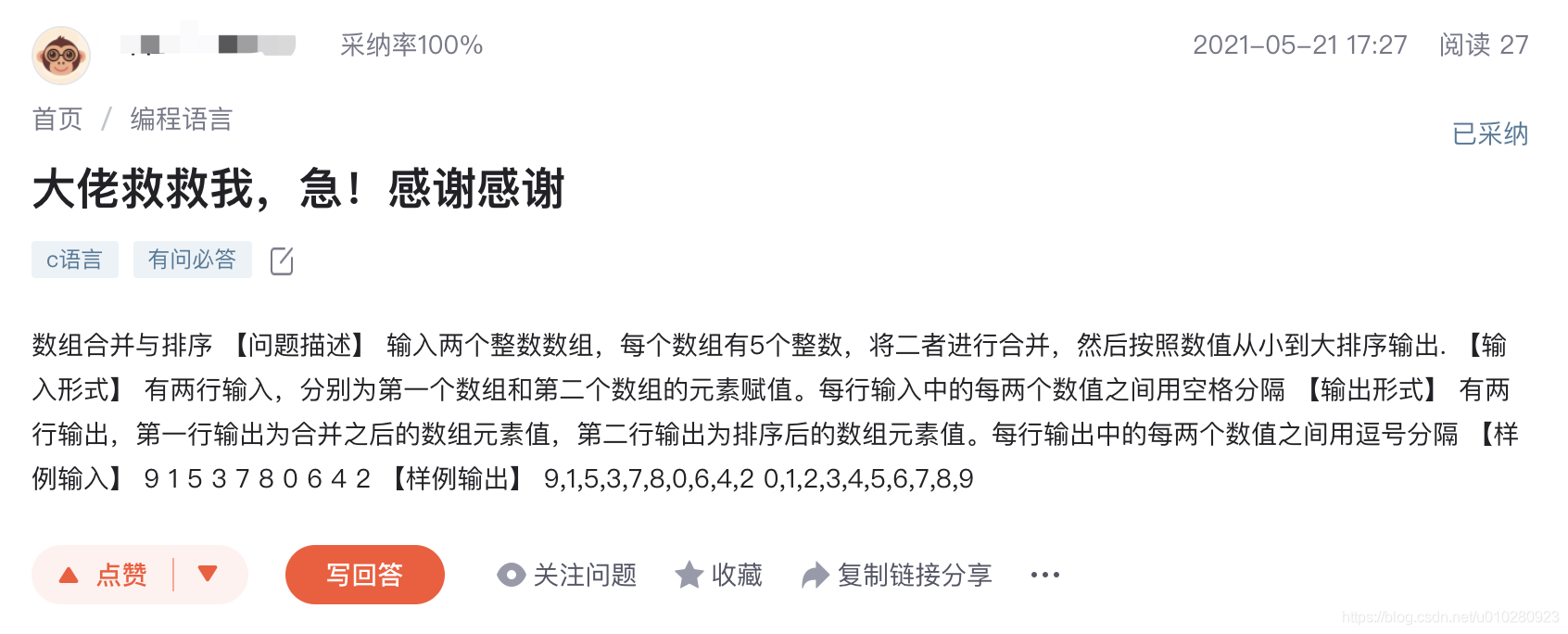
本文通过人工搜集的方法,整理出64个关键词,并通过字符串匹配的方法判断标题是否无效。下面列出所有整理的关键词:
急!
急求
救救
舅舅
救急
救命
求求
球球
求助
求教
跪求
大神
大佬
指教
指点
解答
小白
萌新
孩子
帮忙
帮帮
哥哥
姐姐
妹妹
小妹
小弟
大哥
新手
新人
菜狗
菜鸟
菜鸡
兄弟
高手
初学
自学
谢谢
感谢
仁兄
作业
疯了
老师
牛人
这题
题目
源码
做题
啊啊啊
在线等
太难了
家人们
兄弟们
小老弟
这道题
这个题
考试题
一道题
源代码
编程题
题怎么写
题怎么做
求源代码
haha
课程设计
随机抽取2000条数据测试当前无效标题识别的覆盖率为98.32%。
2.1.1 去停用词策略
有些无效标题中没有明显的关键词,但是整个标题也没有任何信息量,对于这类标题,本文基于停用此表,对标题进行去停用词的操作,最后判断标题是否为空,如果为空则表示标题是无效的。
例如以下标题,全是问号: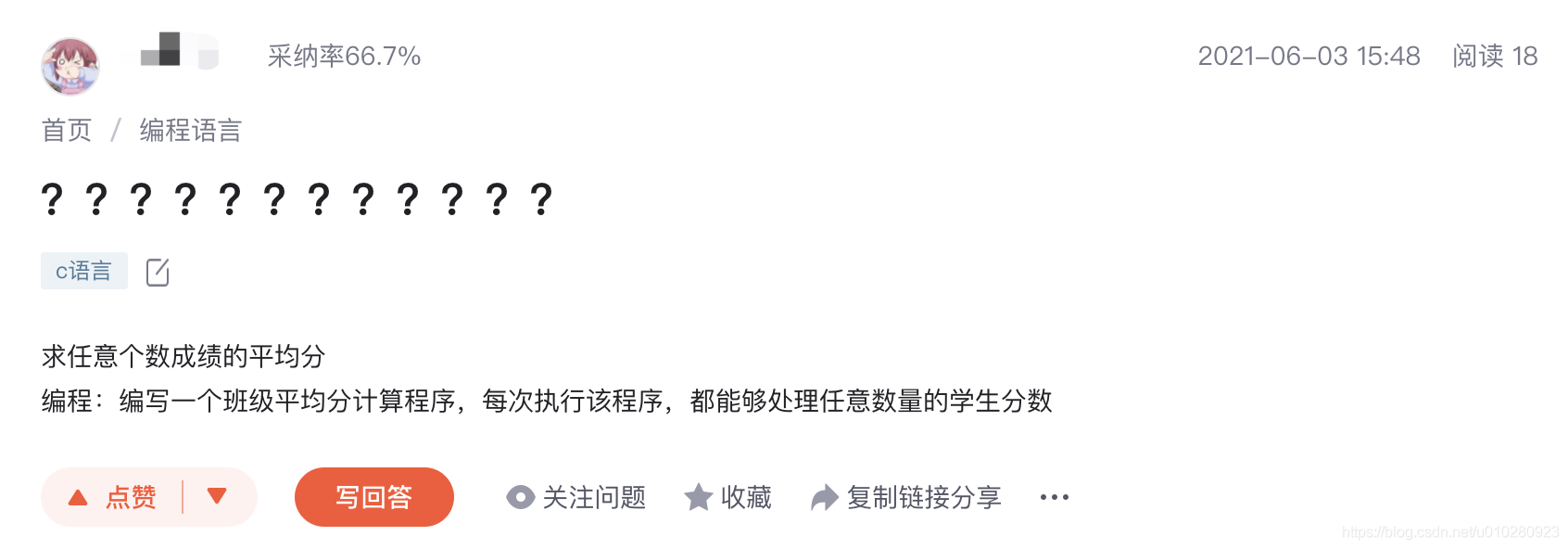
再例如以下标题,标题都是一些无任何有用信息的词:
2.2 OCR模块:保证信息的完整性
在用户的一些提问中,关键信息可以包含上传的图片中,或者说用户的正文描述中只有若干张图片,而没有任何文字描述,例如: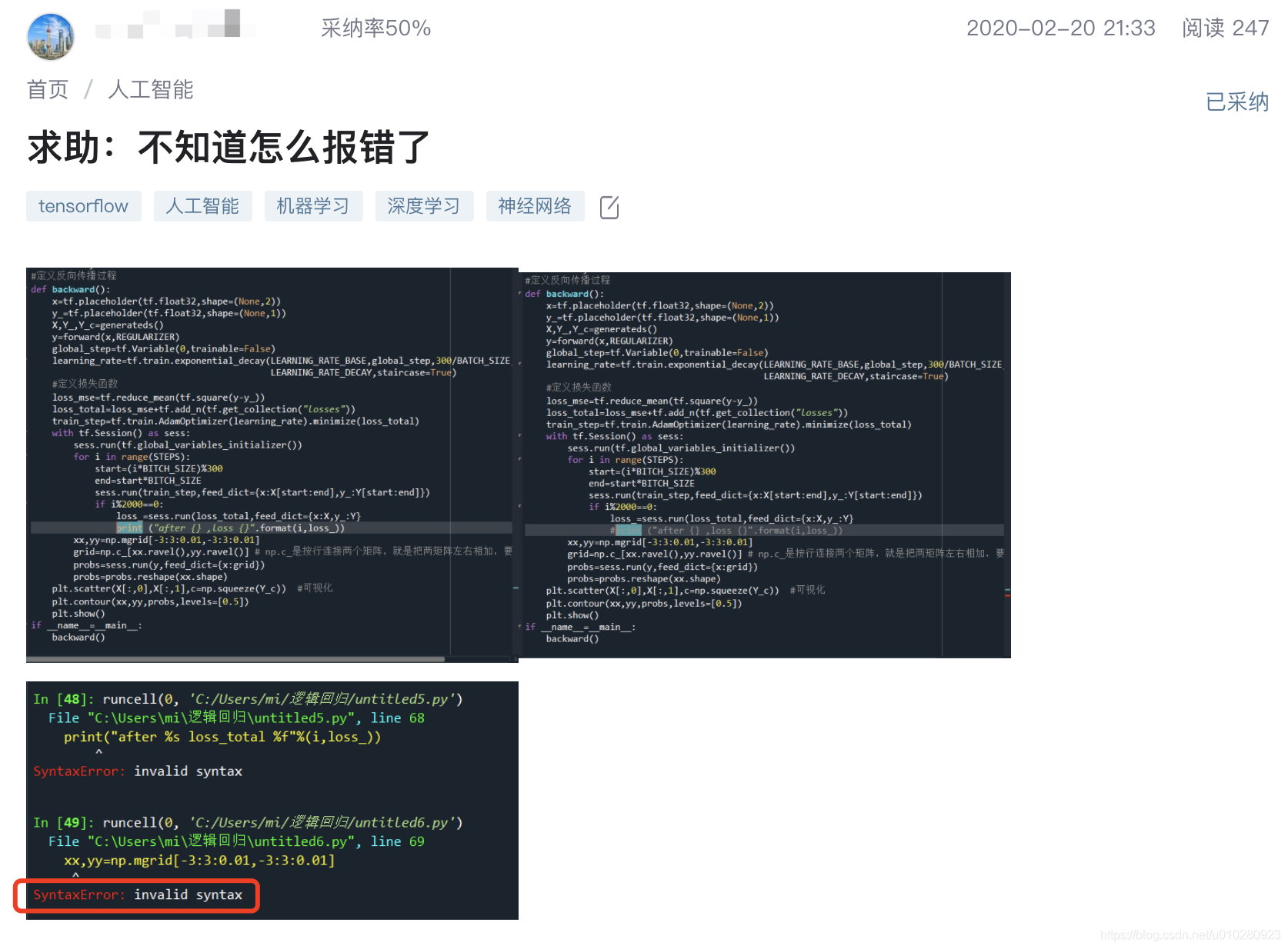
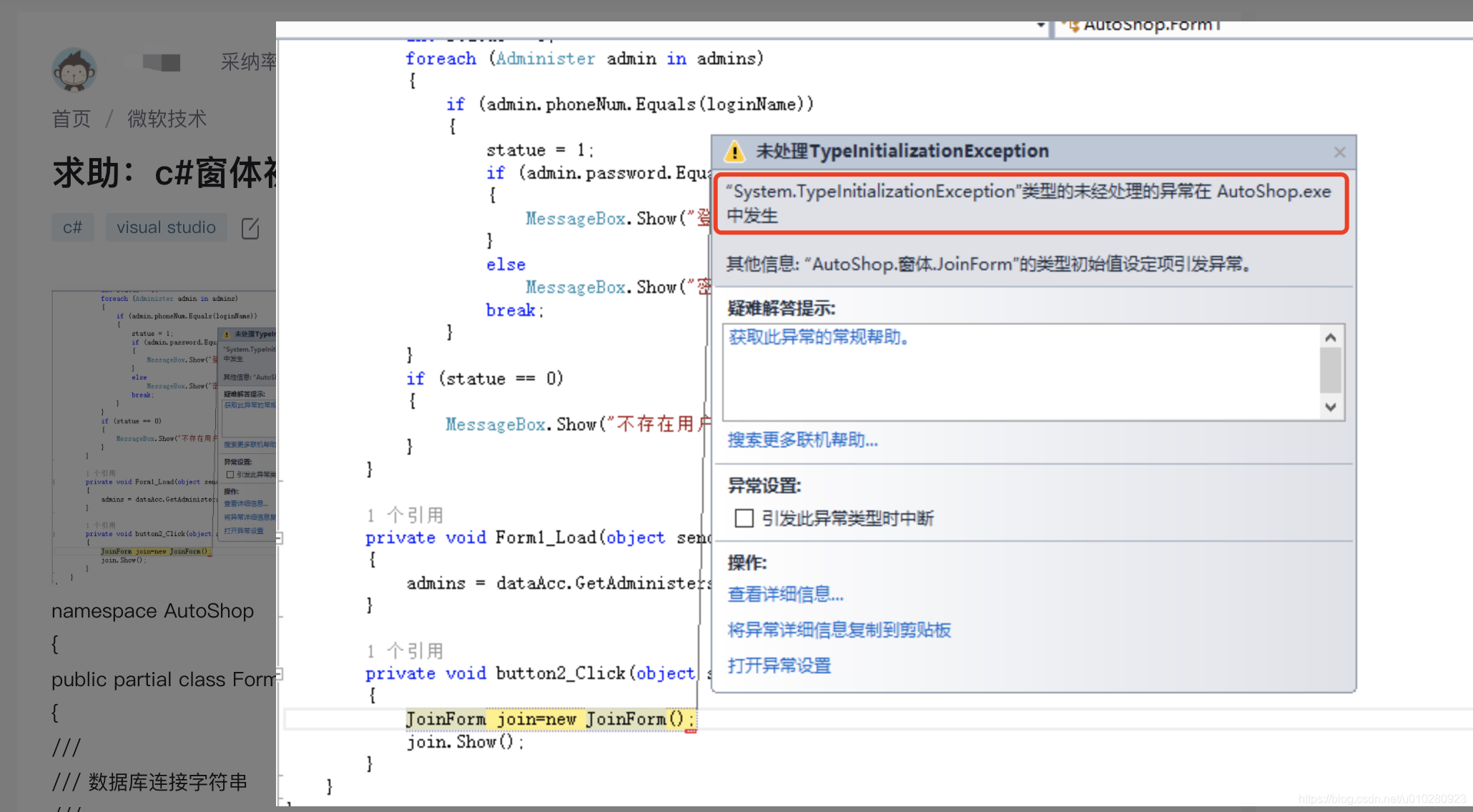
本文使用paddle_ocr的图片转文本模块,将图片中包含的文字信息识别成文本,进入规则模块和Text_Rank模块的识别。
此外,由于OCR比较耗时,故需要保证尽量少调用OCR模块,如果利用已有信息已经足够推荐出标题一个合理的标题,那就不去调用OCR识别所有图片。
2.3 规则模块:提升Precision(准确率)
对于一些特征比较鲜明的提问,例如:程序报错、练习题的询问、以及知识点的询问,本文采用规则的方法进行直接召回。具体细节如下:
2.2.1 报错信息提取模块
有些用户的提问中,正文或者图片中包含了明显的报错信息,报错信息是这类问题的关键信息,故可以直接将报错信息抽取出来作为用户的提问标题。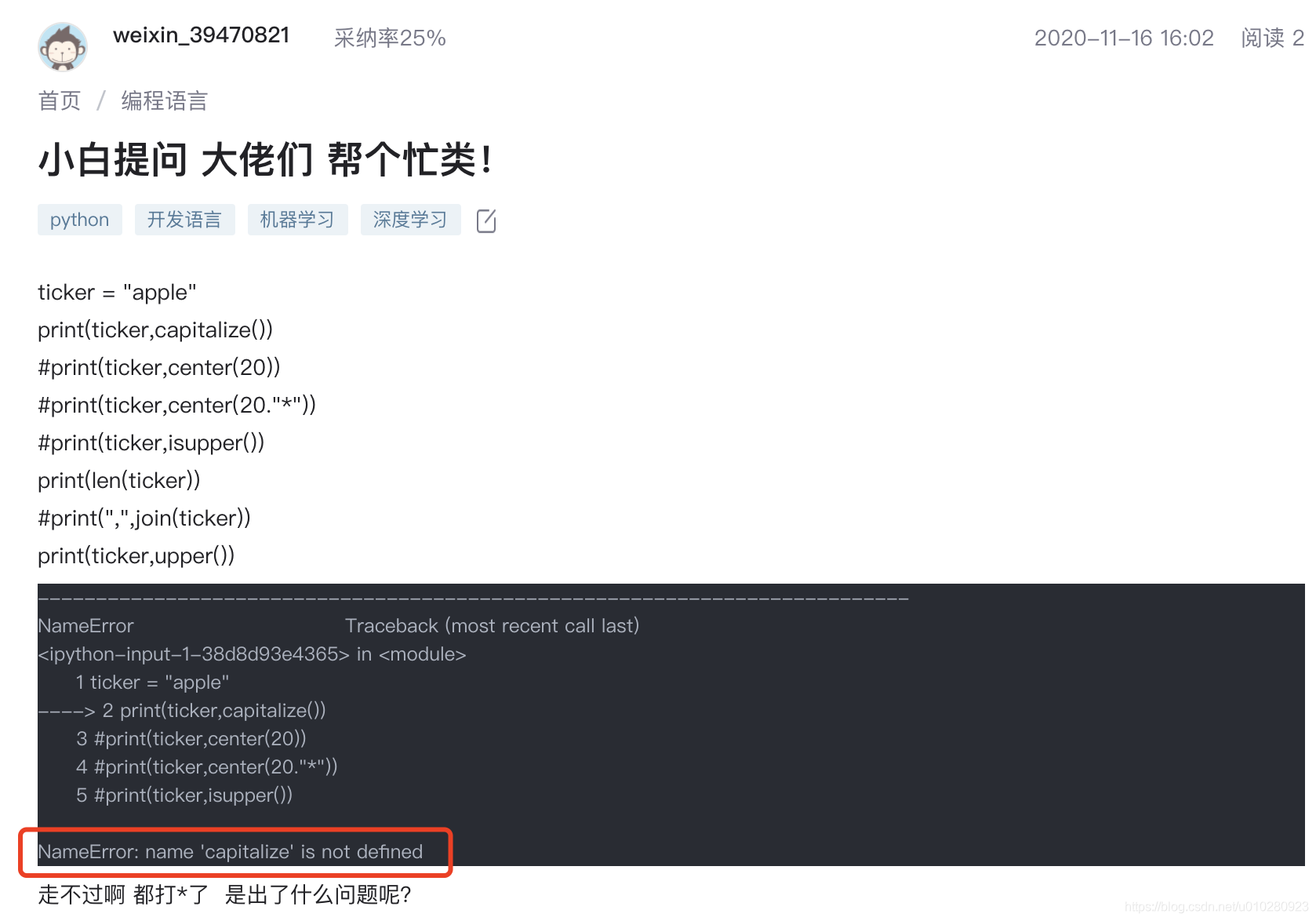
本文使用正则表达式的方法,提取报错信息。其中包含正向规则和反向规则,正向规则用于提取报错信息,反向规则用于避免误吸的情况。
# 正向规则
error_word_pattern = re.compile(r'(exception|error\srequestid|errormessage|errorcode|errmsg|errcode|error|no .*?(detected|found)|unavailable|undefined|系统找不到|烫烫烫|不包含[a-z_\.].*?的定义|执行[a-z_\.].*?时出错|报错)')
# 反向规则
error_word_reverse_pattern = re.compile(r'((except|import|catch|throw)[a-z_ \.\(\)\:]{0,20}exception|([1-9]|logger|self)[\. ]error|error[\((]s[\))][0-9 \,]{1,5}warning[\((]s[\))]|error:function|exception.{1,3}details|onerror|conda config|(catch|throw)[a-z_ \.\(\)\:]{0,20}error)')
2.2.2 练习题识别模块
有些用户的提问中,问的是一些课程的练习题如何解答的问题,这些提问也包含了较明显的信息,例如包含关键词:编程题、练习题等。
此处也是用正则表达式的方法进行匹配,包括基于标题的正则和基于正文的正则,正则表达式如下所示:
# 基于标题的正则
title_exercise_words_pattern = re.compile(r'(题目|作业|编程题|练习题|写.*?程序)')
# 基于正文的正则
body_exercise_words_pattern = re.compile(r'(^(1|A)(、| |\.).{3,}?$|^(①|②|③|④|⑤)|作业|问题[0-9]|[一二三四五]是:|题目描述)')
2.2.3 询问知识点模块
有些用户的提问中,是询问一些很具体的知识点,所以可以直接将知识点提取做来,作为用户提问的标题。
此处也是用正则表达式的方法进行匹配,主要匹配标题中的信息,具体如下所示:
ask_words_pattern = re.compile(r'((?:求助|关于)[\u4e00-\u9fa5a-zA-Z0-9_]*?(?:问题|贴)|[^,。?!;]+?(?:的理解|的区别|的特性|的疑惑))')
2.2.4 添加标题头
为了进一步明确问题所属的领域,例如:python、c++、人工智能等,使标题中包含的信息更加丰富,本文利用提问本身的tag信息,再加上一些模版,生成一个标题头。规则不同的3种规则,也分为3种模版,再加上规则抽取的标题,最终基于规则生成的标题如下所示:
- 报错信息提取模块:关于 #tag# 的疑问
原始标题:小白提问 大佬们 帮个忙类!
推荐标题:关于#深度学习#的疑问:NameError: name ‘capitalize’ is not defined
- 练习题识别模块:关于 #tag# 的题目
原始标题:会脚本的大神帮个忙~~~
推荐标题:关于#c语言#的题目
- 询问知识点模块:询问 #tag# 的知识点
原始标题:新手求教,关于循坏的问题。
推荐标题:询问#java#的知识点:关于循坏的问题
2.4 Text_Rank模块:提升Recall(召回率)
规则模块重点保证标题推荐的高准确率,所以会存在召回率低的问题,当前召回率约33.5%,故剩下的66.5%需要使用Text_Rank进行召回。
Text_Rank是一种抽取式的文本摘要模型,使用策略在上一篇文章中有过简单的介绍,优先考虑问句。此外,抽取式的方法对原始输入文本的要求很高,故需要重点对文本进行预处理,去掉一些对文本抽取无用的干扰信息,主要包括代码段、一些转义字符的转换、URL信息、图片标签链接信息、无用的HTML标签信息等。此外,也会去除不包含任何有效信息的字句,例如:大佬帮忙看看、小白求指导……
经过以上的处理之后,通过Text_Rank生成的标题会更加准确且可读性更强。
3. 总结与下一步计划
通过以上规则+模型的策略,当前的标题推荐效果上一篇文章中baseline的47.92%提升到了86.0%,初步达到了可用的状态。
但是由于用户提问具有高度口语化以及复杂多样的特点,标题推荐任务中的某些细节部分,还是需要进一步优化。下一步计划包括:
- 提升规则以及资源的覆盖度,提升规则的召回率;
- 进一步优化Text_Rank算法的效果,提升标题抽取的质量;
- Text_Rank毕竟是从正文中抽取的句子,直接作为提问标题还有一些生硬,下一步考虑使用模版或生成的方法,提升标题的可读性以及更符合问句的风格。
P.S.
该系列文章会持续进行更新。希望NLP等领域的同仁、老师和专家能够提供宝贵的建议,谢谢!
边栏推荐
- Global and Chinese market of operational amplifier 2022-2028: Research Report on technology, participants, trends, market size and share
- Mysql32 lock
- Win10: how to modify the priority of dual network cards?
- MySQL22-逻辑架构
- MySQL底层的逻辑架构
- Mysql33 multi version concurrency control
- Record the first JDBC
- MySQL combat optimization expert 06 production experience: how does the production environment database of Internet companies conduct performance testing?
- 如何搭建接口自动化测试框架?
- Solution to the problem of cross domain inaccessibility of Chrome browser
猜你喜欢
Mysql23 storage engine
保姆级手把手教你用C语言写三子棋
Just remember Balabala

Super detailed steps to implement Wechat public number H5 Message push
In fact, the implementation of current limiting is not complicated

API learning of OpenGL (2003) gl_ TEXTURE_ WRAP_ S GL_ TEXTURE_ WRAP_ T
Mysql28 database design specification
MySQL 20 MySQL data directory
Mysql32 lock
Isn't there anyone who doesn't know how to write mine sweeping games in C language
随机推荐
[C language] deeply analyze the underlying principle of data storage
February 13, 2022 - Maximum subarray and
Const decorated member function problem
百度百科数据爬取及内容分类识别
A necessary soft skill for Software Test Engineers: structured thinking
Global and Chinese market of wafer processing robots 2022-2028: Research Report on technology, participants, trends, market size and share
① BOKE
Advantages and disadvantages of evaluation methods
MySQL18-MySQL8其它新特性
解决在window中远程连接Linux下的MySQL
Mysql34 other database logs
MySQL combat optimization expert 02 in order to execute SQL statements, do you know what kind of architectural design MySQL uses?
MySQL 29 other database tuning strategies
A necessary soft skill for Software Test Engineers: structured thinking
Super detailed steps to implement Wechat public number H5 Message push
MySQL底层的逻辑架构
Typescript入门教程(B站黑马程序员)
Mysql28 database design specification
Global and Chinese markets for aprotic solvents 2022-2028: Research Report on technology, participants, trends, market size and share
Time in TCP state_ The role of wait?